
在时下互联网信息的浪潮下,信息的传播速度远超我们的想象,一些非理性负面的评论会激发人们的负面感,甚至影响到人民群众对政府的认同。一个高效的全网舆情分析系统,可帮助实时的观测舆情,帮助提前识别负面信息并采取正确的应对措施,避免造成难以估计的损失。舆情系统的全网观测、实时分析存储都对舆情分析系统的数据库提出了重大挑战。
背景信息
- 舆情的影响力诊断:从传播量级和扩散趋势来做预测,确定是否最终形成舆情。
- 传播路径分析:分析舆情传播的关键路径。
- 情感分析:分析新闻或者评价是正面还是负面。情感分类后进行统计聚合。
- 预警设置:支持舆情讨论量阈值设置,达到阈值后通知推送业务方,避免错过舆情的黄金参与时间。
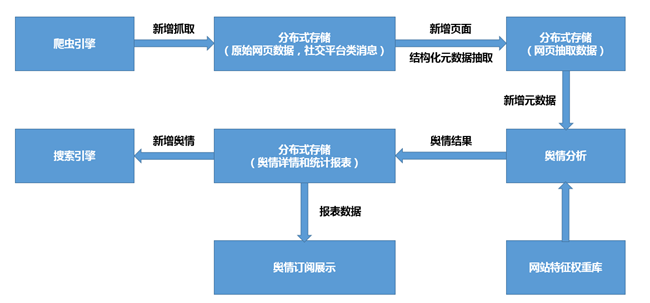
- 全新抓取:
对于一个舆情系统,首先需要一个爬虫引擎,去采集各大主流门户(购物网站、社区论坛原始页面内容、微博、朋友圈)的各类消息信息,采集到的海量网页消息数据(百亿级别)需要实时存储下来。
- 增量去重:
新爬取的页面需根据网站URL判断是否是之前获取过的页面,避免不必要的重复爬取。
- 舆情分析:
采集网页后我们需要对网页进行萃取,去除不必要的标签,提取标题、摘要、正文内容、评论等。 萃取后的内容进入存储系统方便后续查询。
- 搜索与展示:
舆情分析结果需推送至计算平台进行统计分析并输出呈现报表,或者后续提供舆情检索等功能。
数据库选型要求
- 海量并发:
可以支撑海量数据存储(TB/PB级别),高并发访问(十万TPS~千万TPS),访问延时低。
- 弹性伸缩:
业务随着采集订阅的网页源调整,采集量会动态调整。同时一天内,不同时间段爬虫爬下来的网页数也会有明显波峰波谷,所以数据库需要可以弹性扩展,缩容。
- 表结构自由:
自由的表属性结构,普通网页和社交类平台页面的信息我们需要关注的属性可能会有较大区别。灵活的schema会方便做扩展。
- 分层存储:
对老数据可以选择自动过期或者分层存储。因为舆情数据往往关注近期热点,老的数据访问频率较低。
- 增量通道:
需要有较好的增量通道,可以定期把新增的数据导出至计算平台,增量舆情数据需要可以实时同步至对应的计算平台做舆情分析,计算后的结果再写入对应的存储引擎。如果数据库引擎本身就支持增量,则可以很大程度简化架构。
阿里云电子政务云舆情分析系统架构
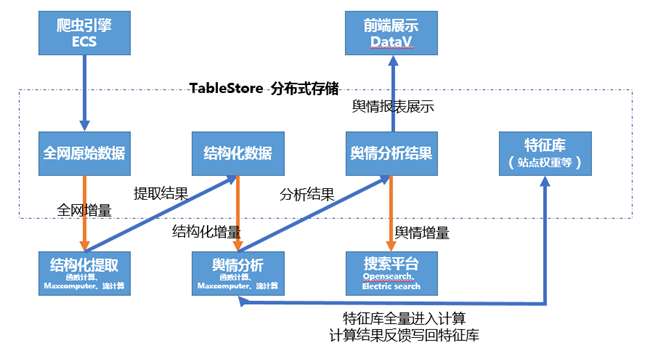 架构说明:
架构说明:
- 云服务器ECS:
爬虫引擎可部署于阿里云ECS,可以根据爬取量决定使用ECS的机器资源数,在每天波峰的时候可临时扩容资源进行网页爬取。原始网页爬取下来后,原始网页地址、网页内容写入存储系统。同时如果想避免重复爬取,爬虫引擎抓取之前要根据URL列表进行去重。
- 表格存储(TableStore):
TableStore支持:
- 低延时的随机访问查询,确定当前URL是否已经存在,如果存在则无需重复抓取。
- 增量内容推送至计算平台。
之前的架构往往需要做应用层的双写,即原始网页数据、增量数据、舆情分析结果数据需同时写入存储库和计算平台,这样的架构需维护两套写入逻辑。每一个数据源的双写需要感知到下游的存在,或者使用消息服务,通过双写消息来做解耦。
传统数据库例如MySQL支持订阅增量日志binlog,如果分布式存储产品在可以支撑较大访问,存储量的同时也可以提供增量订阅就可以很好的简化我们的架构。
- 实时计算(Blink)和大数据计算服务 · MaxCompute:
网页数据采集入库后,增量采集数据的计算机元数据抽取可以选用Blink和MaxCompute。当有新增页面需要提取时触发Blink进行网页元数据抽取。抽取后的结果进入TableStore存储后,同时推送至MaxCompute进行舆情分析,例如情感分析,文本聚类等。
- 开放搜索(Opensearch)或Elasticsearch:
舆情分析产生的舆情报表数据、用户情感数据统计等结果,会写入TableStore和搜索引擎(OpenSearch或ElasticSearch),部分报表、阈值报警会被推送给订阅方。搜索引擎的数据提供给在线舆情检索系统使用。
- DataV:
舆情分析产生的爆表数据、用户情感数据等统计结果是非常庞杂的数据,要快速掌握其动态发展需要有图形化的展现,阿里云DataV可以简单快速的进行业务监控、风险预警、舆情信息分析,满足多种业务的展示需求。