
本文以GitHub公开事件数据为例,为您介绍使用Flink、Hologres构建实时数仓,并通过Hologres对接BI分析工具(本文以DataV为例),实现海量数据实时分析的通用架构与核心步骤。
示例架构
搭建实时数仓时,Flink可对待处理数据进行实时清洗,完成后Hologres可直接读取Flink中的数据,并对接BI分析工具将数据实时展示在大屏中,示例架构如图所示。
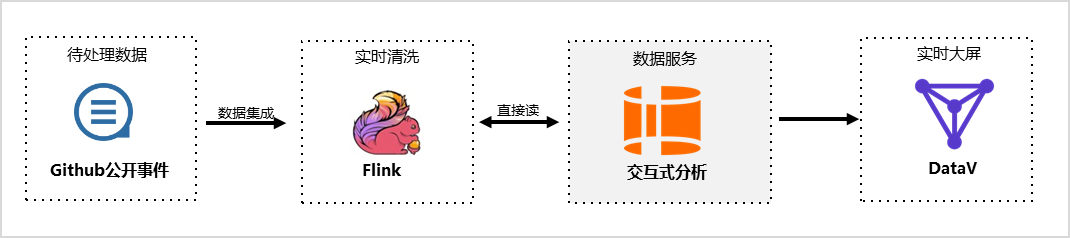
其中:
待处理数据:
本实践使用GitHub公开事件作为示例数据,更多关于数据集的介绍请参见业务与数据认知。
实时清洗:
Flink是流式计算引擎。Flink与Hologres原生深度集成,支持高吞吐、低延时、有模型、高质量的实时数仓开发。
数据服务:
Hologres是兼容PostgreSQL协议的实时数仓引擎,支持海量数据实时写入与更新、实时数据写入即可查。
实时大屏:
本实践以DataV为例,为您展示搭建实时大屏后查看并分析数据的效果。
实践步骤
准备工作
本实践使用已存储在Flink中的Github公共事件作为示例数据,因此您无需操作数据集成步骤,可使用Hologres直接读取Flink中的示例数据。本实践需准备的环境如下所示。
创建Hologres内部表
您需要先创建一个Hologres内部表并创建相应的索引,用于后续数据实时写入。本实践以实时写入Github公开事件中今日最活跃项目数据为例,需提前创建的内部表示例代码如下。
-- 新建schema用于创建内表并导入数据
CREATE SCHEMA IF NOT EXISTS hologres_dataset_github_event;
DROP TABLE IF EXISTS hologres_dataset_github_event.hologres_github_event;
BEGIN;
CREATE TABLE hologres_dataset_github_event.hologres_github_event (
id text,
created_at_bigint bigint,
created_at timestamp with time zone NOT NULL,
type text,
actor_id text,
actor_login text,
repo_id text,
repo_name text,
org text,
org_login text
);
CALL set_table_property ('hologres_dataset_github_event.hologres_github_event', 'distribution_key', 'id');
CALL set_table_property ('hologres_dataset_github_event.hologres_github_event', 'event_time_column', 'created_at');
CALL set_table_property ('hologres_dataset_github_event.hologres_github_event', 'clustering_key', 'created_at');
COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.id IS '事件ID';
COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.created_at_bigint IS '事件发生时间戳';
COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.created_at IS '事件发生时间';
COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.type IS '事件类型';
COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.actor_id IS '事件发起人ID';
COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.actor_login IS '事件发起人登录名';
COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.repo_id IS 'repoID';
COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.repo_name IS 'repo名称';
COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.org IS 'repo所属组织ID';
COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.org_login IS 'repo所属组织名称';
COMMIT;通过Flink实时写入数据至Hologres
如果您申请了免费试用版的Flink,可参见教程文档使用内置公开数据集快速体验实时计算Flink版进入Flink SQL作业编辑运行页面。本实践的Flink SQL作业示例代码如下,其中SLS的project、endpoint、logstore等参数值请参见教程文档使用内置公开数据集快速体验实时计算Flink版,填入对应Region的固定值。
CREATE TEMPORARY TABLE sls_input (
id STRING, -- 每个事件的唯一ID。
created_at BIGINT, -- 事件时间,单位秒。
created_at_ts as TO_TIMESTAMP(created_at * 1000), -- 事件时间戳(当前会话时区下的时间戳,如:Asia/Shanghai)。
type STRING, -- Github事件类型,如:ForkEvent, WatchEvent, IssuesEvent, CommitCommentEvent等。
actor_id STRING, -- Github用户ID。
actor_login STRING, -- Github用户名。
repo_id STRING, -- Github仓库ID。
repo_name STRING, -- Github仓库名,如:apache/flink, apache/spark, alibaba/fastjson等。
org STRING, -- Github组织ID。
org_login STRING -- Github组织名,如: apache,google,alibaba等。
)
WITH (
'connector' = 'sls', -- 实时采集的Github事件存放在阿里云SLS中。
'project' = '<yourSlsProject>', -- 存放公开数据的SLS项目。例如'github-events-hangzhou'。
'endPoint' = '<yourSlsEndpoint>', -- 公开数据仅限VVP通过私网地址访问。例如'https://cn-hangzhou-intranet.log.aliyuncs.com'。
'logStore' = 'realtime-github-events', -- 存放公开数据的SLS logStore。
'accessId' = '****', -- 仅有内置数据集只读权限的AK,参见Flink教程。
'accessKey' = '****', -- 仅有内置数据集只读权限的SK,参见Flink教程。
'batchGetSize' = '500' -- 批量读取数据,每批最多拉取500条。
);
CREATE TEMPORARY TABLE hologres_sink (
id STRING,
created_at_bigint BIGINT,
created_at TIMESTAMP,
type STRING,
actor_id STRING,
actor_login STRING,
repo_id STRING,
repo_name STRING,
org STRING,
org_login STRING
)
WITH (
'connector' = 'hologres',
'dbname' = 'holo db name', --Hologres的数据库名称
'tablename' = 'schema_name.table_name', --Hologres用于接收数据的表名称
'username' = 'access id', --当前阿里云账号的AccessKey ID
'password' = 'access key', --当前阿里云账号的AccessKey Secret
'endpoint' = 'holo vpc endpoint', --当前Hologres实例VPC网络的Endpoint
'jdbcretrycount' = '1', --连接故障时的重试次数
'partitionrouter' = 'true', --是否写入分区表
'createparttable' = 'true', --是否自动创建分区
'mutatetype' = 'insertorignore' --数据写入模式
);
INSERT INTO hologres_sink
SELECT
*
FROM
sls_input
WHERE
id IS NOT NULL
AND created_at_ts IS NOT NULL
AND created_at_ts >= date_add(CURRENT_DATE, - 1);查询实时数据
在Hologres中通过内部表查询今日最活跃项目。
SELECT
repo_name,
COUNT(*) AS events
FROM
hologres_dataset_github_event.hologres_github_event
WHERE
created_at >= CURRENT_DATE
GROUP BY
repo_name
ORDER BY
events DESC
LIMIT 5;(可选)通过DataV搭建实时大屏
您可以通过DataV的数据大屏模板,基于Hologres数据源来快速搭建GitHub事件数据实时大屏。
创建Hologres数据源。
将数据所在的Hologres实例和数据库创建为DataV的数据源,详情请参见DataV。
创建可视化应用。
登录DataV控制台。
在工作台页面,单击创建PC端看板。
选择使用Hologres实时分析GitHub事件数据模板。
修改模板中相关组件的数据源。
以左上角的今日公开事件总数为例:
单击今日公开事件总数对应的数字框,点击右侧数据源,选择数据源类型为实时数仓Hologres。
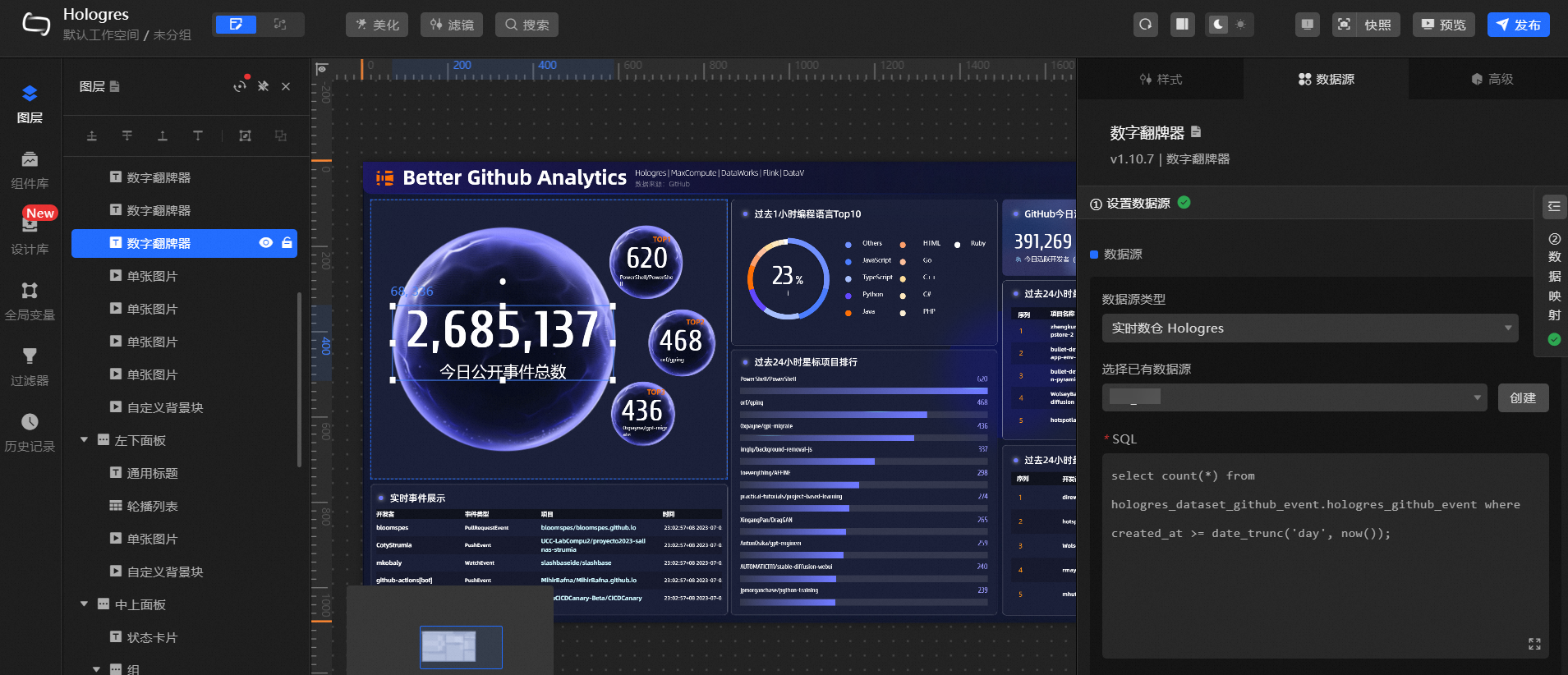
选择已有数据源为您已创建的数据源。
如果您在Hologres中的表名和Schema与本实践相同,则不需修改SQL。
修改完成后,数据响应结果刷新,大屏中成功展示实时数据。
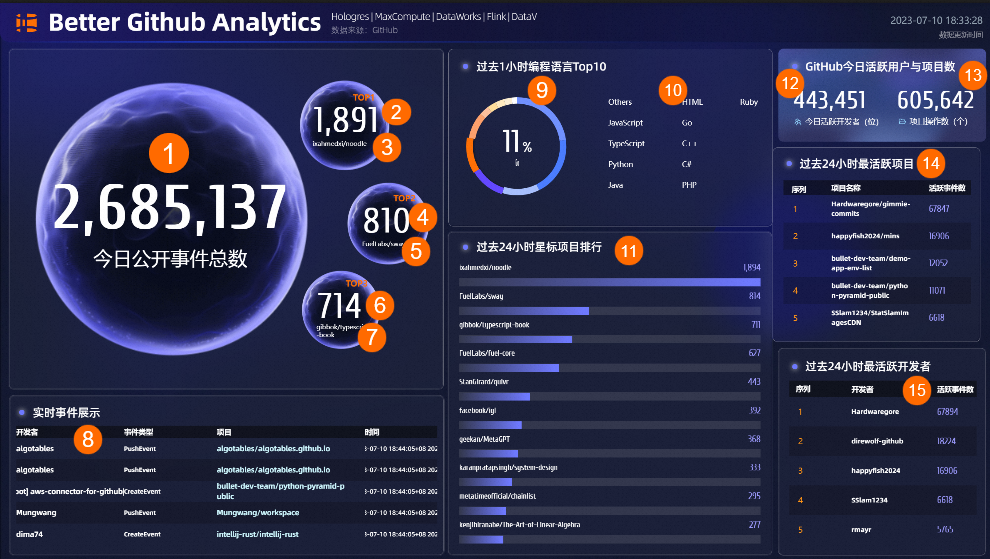
按照示例更新大屏中的数据源和表名,需更新组件及更新后效果如下图所示。
单击右上角发布,完成大屏搭建。
您也可以单击预览,预览实时更新的数据大屏。