
本文为您介绍如何基于GitHub实时事件数据通过MaxCompute构建离线数仓、通过Flink和Hologres构建实时数仓,然后通过Hologres和MaxCompute分别进行实时与离线数据分析,从而实现实时离线一体化解决方案。
背景信息
随着社会数字化发展,企业对数据时效性的需求越来越强烈。除传统的面向海量数据加工场景设计的离线场景外,大量业务需要解决面向实时加工、实时存储、实时分析的实时场景问题,为了应对这样的情形,提出了离线实时一体化的概念。
实时离线一体化是指将实时数据和离线数据在同一平台上管理和处理的技术。它能够实现实时数据处理和离线数据分析的无缝衔接,从而提高数据分析效率和精度。其优势在于:
提高数据处理效率:将实时数据和离线数据整合在同一平台上,大大提高了数据处理效率,降低数据传输和转换成本。
提高数据分析精度:将实时数据和离线数据进行混合分析,从而提高数据分析精度和准确性。
降低系统复杂度:减少数据管理和处理的复杂度,使数据管理和处理更加简单和高效。
提高数据应用价值:更加充分地发挥数据的应用价值,为企业提供更好的决策支持。
阿里云在此方向上进行了诸多方案设计,推出了化繁为简的实时离线一体化数仓,通过大数据计算服务MaxCompute和实时数仓Hologres分别对应上述的离线与实时场景,同时匹配Flink的实时加工能力,共同构成阿里云一体化数仓的核心引擎组件。
方案架构
使用MaxCompute和Hologres对GitHub公开事件数据集进行实时离线一体化实践的完整链路图如下所示。
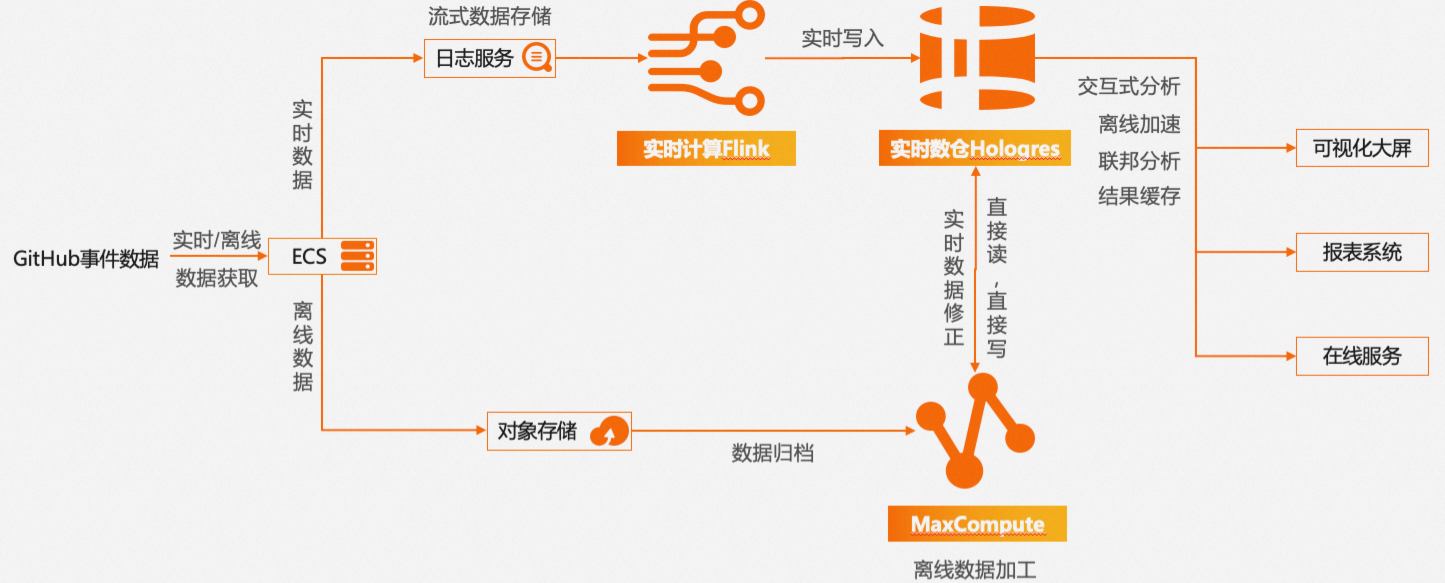
其中ECS将GitHub实时与离线事件数据收集汇总后作为数据源,分别进入实时链路与离线链路,最后两条链路数据汇总到Hologres,统一对外提供服务。
实时链路:通过Flink对日志服务中的数据实时加工并写入Hologres。Flink是强大的流式计算引擎,Hologres支持数据实时写入与更新、写入即可查,二者原生集成,支持高吞吐、低延时、有模型、高质量的实时数仓开发,最终满足业务洞察实时性需求,如最新事件提取、热点事件分析等场景。
离线链路:通过MaxCompute对海量离线数据进行处理并归档。阿里云OSS(Object Storage Service)是阿里云提供的云存储服务,可以用于存储各类数据,本次实践引用的原始数据是JSON格式,OSS可以提供方便、安全、低成本、可靠的存储能力。MaxCompute是适用于数据分析场景的企业级SaaS(Software as a Service)模式云数据仓库,可以直接通过外表的方式读取并解析OSS中的半结构化数据,将高价值可用数据集成至MaxCompute内部存储,然后结合DataWorks进行数据开发,生成离线数据仓库。
Hologres与MaxCompute底层无缝打通,因此可以通过Hologres对MaxCompute海量历史数据进行加速查询分析,满足业务对历史数据的低频高性能查询需求。还可以轻松实现通过离线链路对实时数据的修正,解决实时链路中可能出现的数据遗漏等问题。
该方案优势如下:
离线链路稳定高效:支持数据小时级写入更新,可以批量处理大规模数据,进行复杂的计算和分析,降低计算成本,提高数据处理效率。
实时链路成熟:支持实时写入、实时事件计算、实时分析,实时链路简化,数据秒级响应。
统一存储与服务:均由Hologres对外提供服务,数据集中存储,对外接口一致(OLAP、KeyValue统一为SQL接口)。
实时离线融合:数据冗余少、移动少,数据可修正。
通过一站式开发,最终实现数据秒级响应,全链路状态可见,架构组件少、依赖少,运维成本、人工成本均有效降低。
业务与数据认知
大量开发人员在GitHub上进行开源项目的开发工作,并在项目的开发过程中产生海量事件。GitHub会记录每次事件的类型及详情、开发者、代码仓库等信息,并开放其中的公开事件,包括加星标、提交代码等,具体事件类型请参见Webhook events and payloads。
GitHub通过OpenAPI公布其公开事件,API仅开放5分钟前的实时事件,详情请参见Events。该API可用于获取实时数据。
GH Archive项目则是将GitHub公开事件按小时进行汇总,并允许开发人员访问,项目具体信息请参见GH Archive。该项目可用于获取离线数据。
GitHub业务认知
Github的业务核心为管理代码与互动交流,主要涉及三个一级实体对象:开发者(Developer)、代码仓库(Repository)和组织(Organization)。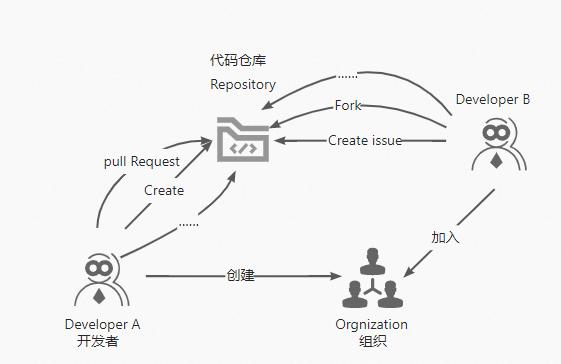
在本次Github公开事件数据分析中,事件作为一个实体对象被存储和记录下来。
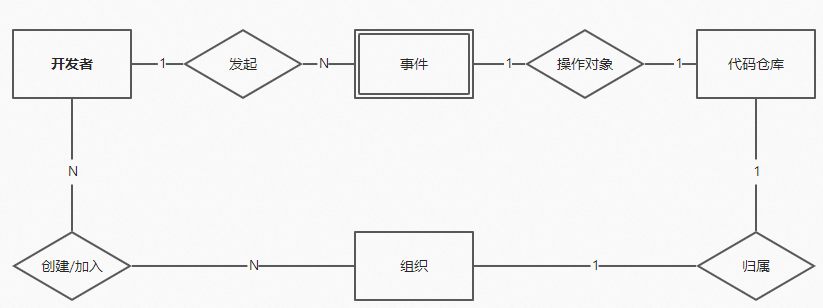
原始公开事件数据认知
某原始事件JSON编码数据示例如下:
{
"id": "19541192931",
"type": "WatchEvent",
"actor":
{
"id": 23286640,
"login": "herekeo",
"display_login": "herekeo",
"gravatar_id": "",
"url": "https://api.github.com/users/herekeo",
"avatar_url": "https://avatars.githubusercontent.com/u/23286640?"
},
"repo":
{
"id": 52760178,
"name": "crazyguitar/pysheeet",
"url": "https://api.github.com/repos/crazyguitar/pysheeet"
},
"payload":
{
"action": "started"
},
"public": true,
"created_at": "2022-01-01T00:03:04Z"
}本分析实践涉及15类公开事件(不包含未出现及不再记录的事件),详细的事件类型及描述请参见Github公开事件类型。
前提条件
已创建云服务器ECS实例并绑定弹性公网IP,用于提取GitHub API中的实时事件数据,详情请参见创建方式导航和绑定和解绑弹性公网IP。
已开通对象存储OSS并在ECS中安装ossutil工具,用于存储GH Archive提供的JSON数据文件,详情请参见开通OSS服务和安装ossutil。
已开通大数据计算服务MaxCompute并创建Project,详情请参见创建MaxCompute项目。
已开通大数据开发治理平台DataWorks并创建工作空间,用于创建离线调度任务,详情请参见创建工作空间。
已开通日志服务SLS并创建Project和Logstore,用于将ECS提取到的数据作为日志进行收集,详情请参见快速入门。
已开通实时计算Flink实例,用于将SLS收集的日志数据实时写入Hologres,详情请参见开通实时计算Flink版。
已开通实时数仓Hologres,详情请参见购买Hologres。
离线数据仓库建设(小时级更新)
通过ECS下载原始数据文件并上传至OSS
ECS用例用于下载GH Archive提供的JSON数据文件。
对于历史数据可通过
wget命令下载,例如wget https://data.gharchive.org/{2012..2022}-{01..12}-{01..31}-{0..23}.json.gz下载2012年到2022年每个小时的数据。对于未来每小时产生的新数据,可以通过如下步骤设置小时级定时任务下载。
说明请确保已在ECS中安装ossutil工具,详情请参见安装ossutil。建议您直接下载ossutil安装包上传ECS实例,通过
yum install unzip安装unzip解压软件,直接解压ossutil,移动至/usr/bin/目录下即可。请确保已在ECS相同地域下创建OSS Bucket,您可以使用自定义OSS Bucket名称。本示例对应的OSS Bucket名称为
githubevents。本示例ECS文件下载目录为
/opt/hourlydata/gh_data,您可以自定义其他目录。
使用如下命令在
/opt/hourlydata目录下,新建名称为download_code.sh的文件。cd /opt/hourlydata vim download_code.sh在文件内输入
i后进入编辑模式,添加如下示例脚本命令。d=$(TZ=UTC date --date='1 hour ago' '+%Y-%m-%d-%-H') h=$(TZ=UTC date --date='1 hour ago' '+%Y-%m-%d-%H') url=https://data.gharchive.org/${d}.json.gz echo ${url} #将数据下载至./gh_data/目录下,您可以自定义其他目录。 wget ${url} -P ./gh_data/ #切换至gh_data目录下 cd gh_data #解压下载数据为json文件 gzip -d ${d}.json echo ${d}.json #切换根目录。 cd /root #使用ossutil工具上传数据至OSS #在名称为githubevents的OSS Bucket下创建hr=${h}的目录 ossutil mkdir oss://githubevents/hr=${h} #将/hourlydata/gh_data(文件存储目录可以自定义其他地方)目录下的数据上传至OSS。 ossutil cp -r /opt/hourlydata/gh_data oss://githubevents/hr=${h} -u echo oss uploaded successfully! rm -rf /opt/hourlydata/gh_data/${d}.json echo ecs deleted!按键盘Esc键,输入
:wq并回车以保存并关闭文件。使用如下命令设置每小时的第10分钟执行
download_code.sh脚本文件。#1 执行以下指令,按键盘I键进入编辑状态。 crontab -e #2 添加以下指令,完成后按键盘Esc键,输入:wq退出。 10 * * * * cd /opt/hourlydata && sh download_code.sh > download.log执行后每个小时的第10分钟会下载前一个小时的JSON文件,在ECS解压后上传至OSS中(路径为
oss://githubevents)。为了之后每次只读取前一个小时的文件,在上传文件时对每个文件建立一个名称为‘hr=%Y-%M-%D-%H’的目录作为分区,之后每次写入数据只读取最新分区下的文件。
通过外部表将OSS数据导入MaxCompute
请在MaxCompute客户端或DataWorks中的ODPS SQL节点执行如下命令,详情请参见使用本地客户端(odpscmd)连接或开发ODPS SQL任务。
创建用于转换OSS中存储的JSON文件的外部表
githubevents:CREATE EXTERNAL TABLE IF NOT EXISTS githubevents ( col STRING ) PARTITIONED BY ( hr STRING ) STORED AS textfile LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/githubevents/' ;MaxCompute中创建OSS外部表详情请参见创建OSS外部表。
创建用于存储数据的事实表
dwd_github_events_odps,其DDL如下:CREATE TABLE IF NOT EXISTS dwd_github_events_odps ( id BIGINT COMMENT '事件ID' ,actor_id BIGINT COMMENT '事件发起人ID' ,actor_login STRING COMMENT '事件发起人登录名' ,repo_id BIGINT COMMENT 'repoID' ,repo_name STRING COMMENT 'repo全名:owner/Repository_name' ,org_id BIGINT COMMENT 'repo所属组织ID' ,org_login STRING COMMENT 'repo所属组织名称' ,`type` STRING COMMENT '事件类型' ,created_at DATETIME COMMENT '事件发生时间' ,action STRING COMMENT '事件行为' ,iss_or_pr_id BIGINT COMMENT 'issue/pull_request ID' ,number BIGINT COMMENT 'issue/pull_request 序号' ,comment_id BIGINT COMMENT 'comment(评论) ID' ,commit_id STRING COMMENT 'commit(提交记录) ID' ,member_id BIGINT COMMENT '成员ID' ,rev_or_push_or_rel_id BIGINT COMMENT 'review/push/release ID' ,ref STRING COMMENT '创建/删除的资源名称' ,ref_type STRING COMMENT '创建/删除的资源类型' ,state STRING COMMENT 'issue/pull_request/pull_request_review的状态' ,author_association STRING COMMENT 'actor与repo之间的关系' ,language STRING COMMENT '请求合并代码的语言' ,merged BOOLEAN COMMENT '是否接受合并' ,merged_at DATETIME COMMENT '代码合并时间' ,additions BIGINT COMMENT '代码增加行数' ,deletions BIGINT COMMENT '代码减少行数' ,changed_files BIGINT COMMENT 'pull request 改变文件数量' ,push_size BIGINT COMMENT '提交数量' ,push_distinct_size BIGINT COMMENT '不同的提交数量' ,hr STRING COMMENT '事件发生所在小时,如00点23分,hr=00' ,`month` STRING COMMENT '事件发生所在月,如2015年10月,month=2015-10' ,`year` STRING COMMENT '事件发生所在年,如2015年,year=2015' ) PARTITIONED BY ( ds STRING COMMENT '事件发生所在日,ds=yyyy-mm-dd' );将JSON数据解析写入事实表。
使用如下命令引入分区并进行JSON解析写入
dwd_github_events_odps表中:msck repair table githubevents add partitions; set odps.sql.hive.compatible = true; set odps.sql.split.hive.bridge = true; INSERT into TABLE dwd_github_events_odps PARTITION(ds) SELECT CAST(GET_JSON_OBJECT(col,'$.id') AS BIGINT ) AS id ,CAST(GET_JSON_OBJECT(col,'$.actor.id')AS BIGINT) AS actor_id ,GET_JSON_OBJECT(col,'$.actor.login') AS actor_login ,CAST(GET_JSON_OBJECT(col,'$.repo.id')AS BIGINT) AS repo_id ,GET_JSON_OBJECT(col,'$.repo.name') AS repo_name ,CAST(GET_JSON_OBJECT(col,'$.org.id')AS BIGINT) AS org_id ,GET_JSON_OBJECT(col,'$.org.login') AS org_login ,GET_JSON_OBJECT(col,'$.type') as type ,to_date(GET_JSON_OBJECT(col,'$.created_at'), 'yyyy-mm-ddThh:mi:ssZ') AS created_at ,GET_JSON_OBJECT(col,'$.payload.action') AS action ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.id')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.issue.id')AS BIGINT) END AS iss_or_pr_id ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.number')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.issue.number')AS BIGINT) ELSE CAST(GET_JSON_OBJECT(col,'$.payload.number')AS BIGINT) END AS number ,CAST(GET_JSON_OBJECT(col,'$.payload.comment.id')AS BIGINT) AS comment_id ,GET_JSON_OBJECT(col,'$.payload.comment.commit_id') AS commit_id ,CAST(GET_JSON_OBJECT(col,'$.payload.member.id')AS BIGINT) AS member_id ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestReviewEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.review.id')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="PushEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.push_id')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="ReleaseEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.release.id')AS BIGINT) END AS rev_or_push_or_rel_id ,GET_JSON_OBJECT(col,'$.payload.ref') AS ref ,GET_JSON_OBJECT(col,'$.payload.ref_type') AS ref_type ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN GET_JSON_OBJECT(col,'$.payload.pull_request.state') WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN GET_JSON_OBJECT(col,'$.payload.issue.state') WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestReviewEvent" THEN GET_JSON_OBJECT(col,'$.payload.review.state') END AS state ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN GET_JSON_OBJECT(col,'$.payload.pull_request.author_association') WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN GET_JSON_OBJECT(col,'$.payload.issue.author_association') WHEN GET_JSON_OBJECT(col,'$.type')="IssueCommentEvent" THEN GET_JSON_OBJECT(col,'$.payload.comment.author_association') WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestReviewEvent" THEN GET_JSON_OBJECT(col,'$.payload.review.author_association') END AS author_association ,GET_JSON_OBJECT(col,'$.payload.pull_request.base.repo.language') AS language ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.merged') AS BOOLEAN) AS merged ,to_date(GET_JSON_OBJECT(col,'$.payload.pull_request.merged_at'), 'yyyy-mm-ddThh:mi:ssZ') AS merged_at ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.additions')AS BIGINT) AS additions ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.deletions')AS BIGINT) AS deletions ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.changed_files')AS BIGINT) AS changed_files ,CAST(GET_JSON_OBJECT(col,'$.payload.size')AS BIGINT) AS push_size ,CAST(GET_JSON_OBJECT(col,'$.payload.distinct_size')AS BIGINT) AS push_distinct_size ,SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),12,2) as hr ,REPLACE(SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),1,7),'/','-') as month ,SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),1,4) as year ,REPLACE(SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),1,10),'/','-') as ds from githubevents where hr = cast(to_char(dateadd(getdate(),-9,'hh'), 'yyyy-mm-dd-hh') as string);查询数据。
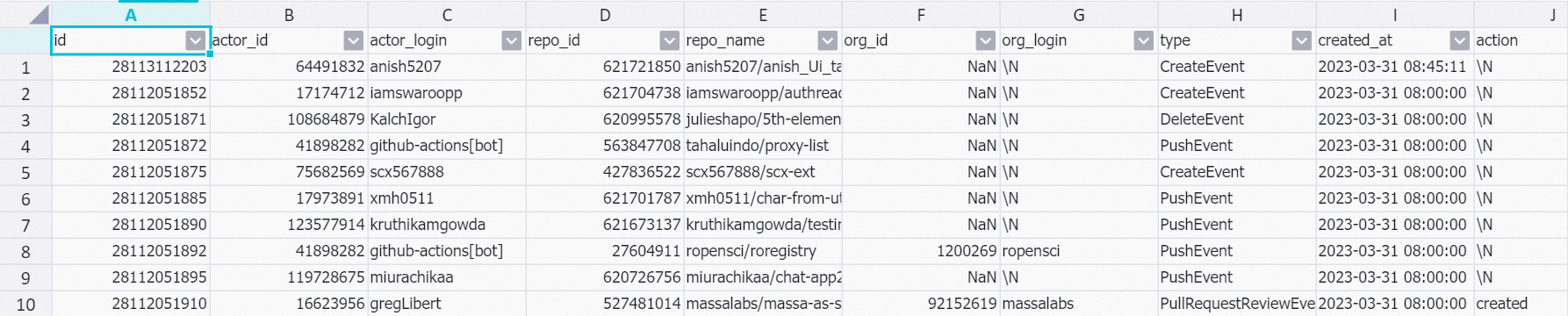
使用如下命令查询
dwd_github_events_odps表数据:SET odps.sql.allow.fullscan=true; SELECT * FROM dwd_github_events_odps where ds = '2023-03-31' limit 10;示例返回结果如下:
实时数据仓库建设
通过ECS获取实时数据
ECS实例用于从GitHub API中提取实时事件数据。本文仅以如下脚本为例,展示一种通过GitHub API采集实时数据的方法。
该脚本每次运行会执行1分钟,采集这段时间内API提供的实时事件数据,并以JSON格式存储每个事件数据。
该脚本不保证采集到全部的实时事件数据。
持续从GitHub API中采集数据需要提供Accept和Authorization。其中Accept为固定值,Authorization需要填写从GitHub中申请的访问令牌。访问令牌的创建方法请参见此处。
使用如下命令在
/opt/realtime目录下新建名称为download_realtime_data.py的文件。cd /opt/realtime vim download_realtime_data.py在文件内输入
i后进入编辑模式,添加如下示例内容。#!python import requests import json import sys import time # 获取API URL def get_next_link(resp): resp_link = resp.headers['link'] link = '' for l in resp_link.split(', '): link = l.split('; ')[0][1:-1] rel = l.split('; ')[1] if rel == 'rel="next"': return link return None # 采集API中一页的数据 def download(link, fname): # 定义GitHub API的Accept和Authorization headers = {"Accept": "application/vnd.github+json","Authorization": "<Bearer> <github_api_token>"} resp = requests.get(link, headers=headers) if int(resp.status_code) != 200: return None with open(fname, 'a') as f: for j in resp.json(): f.write(json.dumps(j)) f.write('\n') print('downloaded {} events to {}'.format(len(resp.json()), fname)) return resp # 采集API中多页的数据 def download_all_data(fname): link = 'https://api.github.com/events?per_page=100&page=1' while True: resp = download(link, fname) if resp is None: break link = get_next_link(resp) if link is None: break # 定义当前时间 def get_current_ms(): return round(time.time()*1000) # 定义脚本每次执行时长1分钟 def main(fname): current_ms = get_current_ms() while get_current_ms() - current_ms < 60*1000: download_all_data(fname) time.sleep(0.1) # 执行脚本 if __name__ == '__main__': if len(sys.argv) < 2: print('usage: python {} <log_file>'.format(sys.argv[0])) exit(0) main(sys.argv[1])按Esc键,输入
:wq并回车以保存并关闭文件。创建
run_py.sh文件用于执行download_realtime_data.py并将每次执行采集到的数据分别存储,内容如下。python /opt/realtime/download_realtime_data.py /opt/realtime/gh_realtime_data/$(date '+%Y-%m-%d-%H:%M:%S').json创建
delete_log.sh文件用于删除历史数据,内容如下。d=$(TZ=UTC date --date='2 day ago' '+%Y-%m-%d') rm -f /opt/realtime/gh_realtime_data/*${d}*.json使用如下命令每分钟采集一次GitHub数据,每天删除一次历史数据。
#1 执行以下指令,按键盘I键进入编辑状态。 crontab -e #2 添加以下指令,完成后按键盘Esc键,输入:wq退出。 * * * * * bash /opt/realtime/run_py.sh 1 1 * * * bash /opt/realtime/delete_log.sh
通过SLS采集ECS数据
SLS用于将ECS中提取到的实时事件数据作为日志进行收集。
SLS支持通过Logtail采集ECS上的日志。由于本文涉及的数据为JSON格式,因此可以使用Logtail的JSON模式快速采集ECS中的增量JSON日志,采集方法请参见使用JSON模式采集日志。其中本文定义SLS对原始数据的顶层键值对进行解析。
Logtail配置的日志路径参数本示例设置为/opt/realtime/gh_realtime_data/**/*.json。
配置完成后,SLS即可持续完成对ECS中增量事件数据的采集。采集到的数据情况示例如下图。
通过Flink实时写入SLS数据至Hologres
Flink用于将SLS采集的日志数据实时写入Hologres。通过在Flink中使用SLS源表、Hologres结果表,即可实现数据从SLS到Hologres的实时写入,详情请参见从SLS日志服务导入。
创建Hologres内部表。
本文创建的内部表中只保留了原始JSON数据的部分键值,并将事件
id、日期ds设为主键,将事件id设为Distribution Key,将日期ds设为分区键,将事件发生时间created_at设为event_time_column。您可以根据实际查询需求,为其他字段创建索引,以提升查询效率。索引介绍请参见CREATE TABLE。本次示例建表DDL如下。DROP TABLE IF EXISTS gh_realtime_data; BEGIN; CREATE TABLE gh_realtime_data ( id bigint, actor_id bigint, actor_login text, repo_id bigint, repo_name text, org_id bigint, org_login text, type text, created_at timestamp with time zone NOT NULL, action text, iss_or_pr_id bigint, number bigint, comment_id bigint, commit_id text, member_id bigint, rev_or_push_or_rel_id bigint, ref text, ref_type text, state text, author_association text, language text, merged boolean, merged_at timestamp with time zone, additions bigint, deletions bigint, changed_files bigint, push_size bigint, push_distinct_size bigint, hr text, month text, year text, ds text, PRIMARY KEY (id,ds) ) PARTITION BY LIST (ds); CALL set_table_property('public.gh_realtime_data', 'distribution_key', 'id'); CALL set_table_property('public.gh_realtime_data', 'event_time_column', 'created_at'); CALL set_table_property('public.gh_realtime_data', 'clustering_key', 'created_at'); COMMENT ON COLUMN public.gh_realtime_data.id IS '事件ID'; COMMENT ON COLUMN public.gh_realtime_data.actor_id IS '事件发起人ID'; COMMENT ON COLUMN public.gh_realtime_data.actor_login IS '事件发起人登录名'; COMMENT ON COLUMN public.gh_realtime_data.repo_id IS 'repoID'; COMMENT ON COLUMN public.gh_realtime_data.repo_name IS 'repo名称'; COMMENT ON COLUMN public.gh_realtime_data.org_id IS 'repo所属组织ID'; COMMENT ON COLUMN public.gh_realtime_data.org_login IS 'repo所属组织名称'; COMMENT ON COLUMN public.gh_realtime_data.type IS '事件类型'; COMMENT ON COLUMN public.gh_realtime_data.created_at IS '事件发生时间'; COMMENT ON COLUMN public.gh_realtime_data.action IS '事件行为'; COMMENT ON COLUMN public.gh_realtime_data.iss_or_pr_id IS 'issue/pull_request ID'; COMMENT ON COLUMN public.gh_realtime_data.number IS 'issue/pull_request 序号'; COMMENT ON COLUMN public.gh_realtime_data.comment_id IS 'comment(评论)ID'; COMMENT ON COLUMN public.gh_realtime_data.commit_id IS '提交记录ID'; COMMENT ON COLUMN public.gh_realtime_data.member_id IS '成员ID'; COMMENT ON COLUMN public.gh_realtime_data.rev_or_push_or_rel_id IS 'review/push/release ID'; COMMENT ON COLUMN public.gh_realtime_data.ref IS '创建/删除的资源名称'; COMMENT ON COLUMN public.gh_realtime_data.ref_type IS '创建/删除的资源类型'; COMMENT ON COLUMN public.gh_realtime_data.state IS 'issue/pull_request/pull_request_review的状态'; COMMENT ON COLUMN public.gh_realtime_data.author_association IS 'actor与repo之间的关系'; COMMENT ON COLUMN public.gh_realtime_data.language IS '编程语言'; COMMENT ON COLUMN public.gh_realtime_data.merged IS '是否接受合并'; COMMENT ON COLUMN public.gh_realtime_data.merged_at IS '代码合并时间'; COMMENT ON COLUMN public.gh_realtime_data.additions IS '代码增加行数'; COMMENT ON COLUMN public.gh_realtime_data.deletions IS '代码减少行数'; COMMENT ON COLUMN public.gh_realtime_data.changed_files IS 'pull request 改变文件数量'; COMMENT ON COLUMN public.gh_realtime_data.push_size IS '提交数量'; COMMENT ON COLUMN public.gh_realtime_data.push_distinct_size IS '不同的提交数量'; COMMENT ON COLUMN public.gh_realtime_data.hr IS '事件发生所在小时,如00点23分,hr=00'; COMMENT ON COLUMN public.gh_realtime_data.month IS '事件发生所在月,如2015年10月,month=2015-10'; COMMENT ON COLUMN public.gh_realtime_data.year IS '事件发生所在年,如2015年,year=2015'; COMMENT ON COLUMN public.gh_realtime_data.ds IS '事件发生所在日,ds=yyyy-mm-dd'; COMMIT;通过Flink实时写入数据。
通过Flink对SLS的数据进一步解析并实时写入到Hologres中。在Flink中使用如下语句对写入的数据进行过滤,丢弃事件ID、事件发生时间(
created_at)为空的脏数据,并且只保留近期发生的事件数据。CREATE TEMPORARY TABLE sls_input ( actor varchar, created_at varchar, id bigint, org varchar, payload varchar, public varchar, repo varchar, type varchar ) WITH ( 'connector' = 'sls', 'endpoint' = '<endpoint>',--sls私域endpoint 'accessid' = '<accesskey id>',--账号access id 'accesskey' = '<accesskey secret>',--账号access key 'project' = '<project name>',--sls的project名 'logstore' = '<logstore name>'--sls的LogStore名称 'starttime' = '2023-04-06 00:00:00',--sls数据采集开始时间 ); CREATE TEMPORARY TABLE hologres_sink ( id bigint, actor_id bigint, actor_login string, repo_id bigint, repo_name string, org_id bigint, org_login string, type string, created_at timestamp, action string, iss_or_pr_id bigint, number bigint, comment_id bigint, commit_id string, member_id bigint, rev_or_push_or_rel_id bigint, `ref` string, ref_type string, state string, author_association string, `language` string, merged boolean, merged_at timestamp, additions bigint, deletions bigint, changed_files bigint, push_size bigint, push_distinct_size bigint, hr string, `month` string, `year` string, ds string ) WITH ( 'connector' = 'hologres', 'dbname' = '<hologres dbname>', --Hologres的数据库名称 'tablename' = '<hologres tablename>', --Hologres用于接收数据的表名称 'username' = '<accesskey id>', --当前阿里云账号的AccessKey ID 'password' = '<accesskey secret>', --当前阿里云账号的AccessKey Secret 'endpoint' = '<endpoint>', --当前Hologres实例VPC网络的Endpoint 'jdbcretrycount' = '1', --连接故障时的重试次数 'partitionrouter' = 'true', --是否写入分区表 'createparttable' = 'true', --是否自动创建分区 'mutatetype' = 'insertorignore' --数据写入模式 ); INSERT INTO hologres_sink SELECT id ,CAST(JSON_VALUE(actor, '$.id') AS bigint) AS actor_id ,JSON_VALUE(actor, '$.login') AS actor_login ,CAST(JSON_VALUE(repo, '$.id') AS bigint) AS repo_id ,JSON_VALUE(repo, '$.name') AS repo_name ,CAST(JSON_VALUE(org, '$.id') AS bigint) AS org_id ,JSON_VALUE(org, '$.login') AS org_login ,type ,TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC') AS created_at ,JSON_VALUE(payload, '$.action') AS action ,CASE WHEN type='PullRequestEvent' THEN CAST(JSON_VALUE(payload, '$.pull_request.id') AS bigint) WHEN type='IssuesEvent' THEN CAST(JSON_VALUE(payload, '$.issue.id') AS bigint) END AS iss_or_pr_id ,CASE WHEN type='PullRequestEvent' THEN CAST(JSON_VALUE(payload, '$.pull_request.number') AS bigint) WHEN type='IssuesEvent' THEN CAST(JSON_VALUE(payload, '$.issue.number') AS bigint) ELSE CAST(JSON_VALUE(payload, '$.number') AS bigint) END AS number ,CAST(JSON_VALUE(payload, '$.comment.id') AS bigint) AS comment_id ,JSON_VALUE(payload, '$.comment.commit_id') AS commit_id ,CAST(JSON_VALUE(payload, '$.member.id') AS bigint) AS member_id ,CASE WHEN type='PullRequestReviewEvent' THEN CAST(JSON_VALUE(payload, '$.review.id') AS bigint) WHEN type='PushEvent' THEN CAST(JSON_VALUE(payload, '$.push_id') AS bigint) WHEN type='ReleaseEvent' THEN CAST(JSON_VALUE(payload, '$.release.id') AS bigint) END AS rev_or_push_or_rel_id ,JSON_VALUE(payload, '$.ref') AS `ref` ,JSON_VALUE(payload, '$.ref_type') AS ref_type ,CASE WHEN type='PullRequestEvent' THEN JSON_VALUE(payload, '$.pull_request.state') WHEN type='IssuesEvent' THEN JSON_VALUE(payload, '$.issue.state') WHEN type='PullRequestReviewEvent' THEN JSON_VALUE(payload, '$.review.state') END AS state ,CASE WHEN type='PullRequestEvent' THEN JSON_VALUE(payload, '$.pull_request.author_association') WHEN type='IssuesEvent' THEN JSON_VALUE(payload, '$.issue.author_association') WHEN type='IssueCommentEvent' THEN JSON_VALUE(payload, '$.comment.author_association') WHEN type='PullRequestReviewEvent' THEN JSON_VALUE(payload, '$.review.author_association') END AS author_association ,JSON_VALUE(payload, '$.pull_request.base.repo.language') AS `language` ,CAST(JSON_VALUE(payload, '$.pull_request.merged') AS boolean) AS merged ,TO_TIMESTAMP_TZ(replace(JSON_VALUE(payload, '$.pull_request.merged_at'),'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC') AS merged_at ,CAST(JSON_VALUE(payload, '$.pull_request.additions') AS bigint) AS additions ,CAST(JSON_VALUE(payload, '$.pull_request.deletions') AS bigint) AS deletions ,CAST(JSON_VALUE(payload, '$.pull_request.changed_files') AS bigint) AS changed_files ,CAST(JSON_VALUE(payload, '$.size') AS bigint) AS push_size ,CAST(JSON_VALUE(payload, '$.distinct_size') AS bigint) AS push_distinct_size ,SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),12,2) as hr ,REPLACE(SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),1,7),'/','-') as `month` ,SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),1,4) as `year` ,SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),1,10) as ds FROM sls_input WHERE id IS NOT NULL AND created_at IS NOT NULL AND to_date(replace(created_at,'T',' ')) >= date_add(CURRENT_DATE, -1);参数说明请参见日志服务SLS源表和实时数仓Hologres结果表。
说明由于GitHub原始事件数据采用的时区为UTC、原始数据不带有时区属性,Hologres的默认时区为东八区,因此需要在Flink实时写入Hologres过程中对数据时区进行调整:需要在Flink SQL中对源表数据赋予UTC时区属性,并在启动作业时在作业启动配置页面的Flink配置区域添加
table.local-time-zone:Asia/Shanghai语句将Flink系统时区定义为Asia/Shanghai。查询数据。
在Hologres中查询通过Flink写入Hologres中的SLS数据,后续您可以根据业务需求进行数据开发。
SELECT * FROM public.gh_realtime_data limit 10;结果示例如下:

使用离线数据修正实时数据
在本文的场景中,实时数据存在遗漏的可能,因此可以使用离线数据对实时数据进行修正。通过如下步骤可以完成对前一日实时数据的修正,您可以根据自身业务需要,调整数据修正的周期。
在Hologres中创建外部表,获取MaxCompute离线数据。
IMPORT FOREIGN SCHEMA <maxcompute_project_name> LIMIT to ( <foreign_table_name> ) FROM SERVER odps_server INTO public OPTIONS(if_table_exist 'update',if_unsupported_type 'error');参数说明请参见IMPORT FOREIGN SCHEMA。
通过创建临时表实现离线数据修正前一日实时数据。
说明Hologres从V2.1.17版本起支持Serverless Computing能力,针对大数据量离线导入、大型ETL作业、外表大数据量查询等场景,使用Serverless Computing执行该类任务可以直接使用额外的Serverless资源,避免使用实例自身资源,无需为实例预留额外的计算资源,显著提升实例稳定性、减少OOM概率,且仅需为任务单独付费。Serverless Computing详情请参见Serverless Computing概述,Serverless Computing使用方法请参见Serverless Computing使用指南。
-- 清理潜在的临时表 DROP TABLE IF EXISTS gh_realtime_data_tmp; -- 创建临时表 SET hg_experimental_enable_create_table_like_properties = ON; CALL HG_CREATE_TABLE_LIKE ('gh_realtime_data_tmp', 'select * from gh_realtime_data'); -- (可选)推荐使用Serverless Computing执行大数据量离线导入和ETL作业 SET hg_computing_resource = 'serverless'; -- 向临时表插入数据并更新统计信息 INSERT INTO gh_realtime_data_tmp SELECT * FROM <foreign_table_name> WHERE ds = current_date - interval '1 day' ON CONFLICT (id, ds) DO NOTHING; ANALYZE gh_realtime_data_tmp; -- 重置配置,保证非必要的SQL不会使用serverless资源。 RESET hg_computing_resource; -- 已有临时子表替换原子表 BEGIN; DROP TABLE IF EXISTS "gh_realtime_data_<yesterday_date>"; ALTER TABLE gh_realtime_data_tmp RENAME TO "gh_realtime_data_<yesterday_date>"; ALTER TABLE gh_realtime_data ATTACH PARTITION "gh_realtime_data_<yesterday_date>" FOR VALUES IN ('<yesterday_date>'); COMMIT;
数据分析
针对已获取到的海量数据,可以进行丰富的数据分析。您可以结合自身业务需要分析的时间范围,对数据仓库进行进一步分层设计,以满足实时数据分析、离线数据分析、实时离线一体化分析等多方面诉求。
如下示例针对上文获取到的实时数据进行分析,您也可以针对具体代码仓库或开发者进行数据分析。
查询今日公开事件总数。
SELECT count(*) FROM gh_realtime_data WHERE created_at >= date_trunc('day', now());返回结果示例如下:
count ------ 1006查询过去1天最活跃(事件数最多)的几个项目。
SELECT repo_name, COUNT(*) AS events FROM gh_realtime_data WHERE created_at >= now() - interval '1 day' GROUP BY repo_name ORDER BY events DESC LIMIT 5;返回结果示例如下:
repo_name events ----------------------------------------+------ leo424y/heysiri.ml 29 arm-on/plan 10 Christoffel-T/fiverr-pat-20230331 9 mate-academy/react_dynamic-list-of-goods 9 openvinotoolkit/openvino 7查询过去1天最活跃(事件数最多)的几位开发者。
SELECT actor_login, COUNT(*) AS events FROM gh_realtime_data WHERE created_at >= now() - interval '1 day' AND actor_login NOT LIKE '%[bot]' GROUP BY actor_login ORDER BY events DESC LIMIT 5;返回结果示例如下:
actor_login events ------------------+------ direwolf-github 13 arm-on 10 sergii-nosachenko 9 Christoffel-T 9 yangwang201911 7查询过去1小时最火编程语言排行。
SELECT language, count(*) total FROM gh_realtime_data WHERE created_at > now() - interval '1 hour' AND language IS NOT NULL GROUP BY language ORDER BY total DESC LIMIT 10;返回结果示例如下:
language total -----------+---- JavaScript 25 C++ 15 Python 14 TypeScript 13 Java 8 PHP 8查询过去1天项目加星数排行。
说明本示例并未考虑用户取消星标等情况。
SELECT repo_id, repo_name, COUNT(actor_login) total FROM gh_realtime_data WHERE type = 'WatchEvent' AND created_at > now() - interval '1 day' GROUP BY repo_id, repo_name ORDER BY total DESC LIMIT 10;返回结果示例如下:
repo_id repo_name total ---------+----------------------------------+----- 618058471 facebookresearch/segment-anything 4 619959033 nomic-ai/gpt4all 1 97249406 denysdovhan/wtfjs 1 9791525 digininja/DVWA 1 168118422 aylei/interview 1 343520006 joehillen/sysz 1 162279822 agalwood/Motrix 1 577723410 huggingface/swift-coreml-diffusers 1 609539715 e2b-dev/e2b 1 254839429 maniackk/KKCallStack 1查询今日用户和项目日活。
SELECT uniq (actor_id) actor_num, uniq (repo_id) repo_num FROM gh_realtime_data WHERE created_at > date_trunc('day', now());返回结果示例如下:
actor_num repo_num ---------+-------- 743 816