
本文为您介绍Hologres的产品架构以及每个组件的作用。
架构优势
在传统的分布式系统中,常用的存储计算架构有如下三种。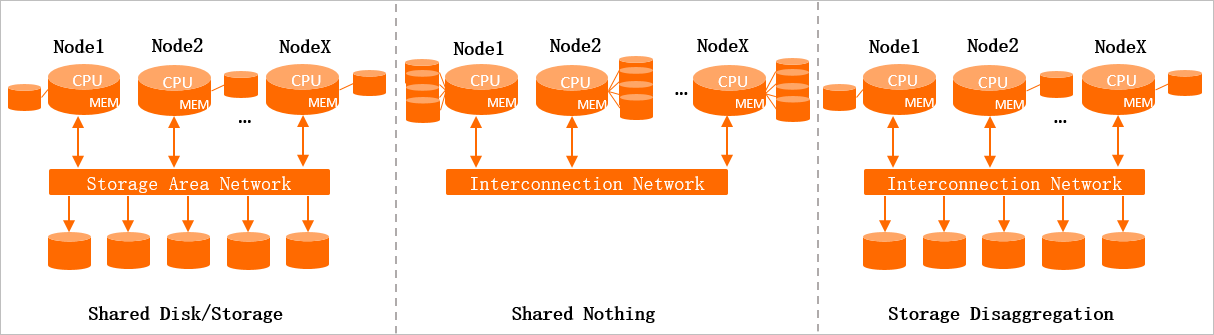
Shared Disk/Storage (共享存储)
有一个分布式的存储集群,每个计算节点像访问单机数据一样访问这个共享存储上的数据。这种架构的存储层可以比较方便的扩展,但是计算节点需要引入分布式协调机制保证数据同步和一致性,因此计算节点的可扩展性有一个上限。
Shared Nothing
每个计算节点自己挂载存储,一个节点只能处理一个分片的数据,节点之间可以通信,最终有一个汇总节点对数据进行汇总。这种架构能比较方便的扩展,但是它的缺点是节点Failover需要等待数据加载完成之后才能提供服务;并且存储和计算需要同时扩容,不够灵活,扩容后,有漫长的数据Rebalance过程。
Storage Disaggregation(存储计算分离架构)
存储和Shared Storage类似,有一个分布式的共享存储集群,计算层处理数据的模式和Shared Nothing类似,数据是分片的,每个Shard只处理自己所在分片的数据,每个计算节点还可以有本地缓存。
存储计算分离的架构存在以下优势。
一致性问题处理简单:计算层只需要保证同一时刻有一个计算节点写入同一分片的数据。
扩展更灵活:计算和存储可以分开扩展,计算不够扩计算节点,存储不够扩存储节点。这样在大促等场景上会非常灵活。计算资源不够了,马上扩容计算就好了,不需要像Shared Nothing那样做耗时耗力的数据Rebalance;也不会像Shared Storage那样,出现单机的存储容量瓶颈。
计算节点故障恢复快:计算节点发生Failover之后,数据可以按需从分布式的共享存储异步拉取。因此Failover的速度非常快。
Hologres采用的是第三种存储计算分离架构,Hologres的存储使用的是阿里自研的Pangu分布式文件系统(类似HDFS)。用户可以根据业务需求进行弹性扩缩容,轻松应对在线系统不同的流量峰值。
架构组件介绍
Hologres架构图如下所示。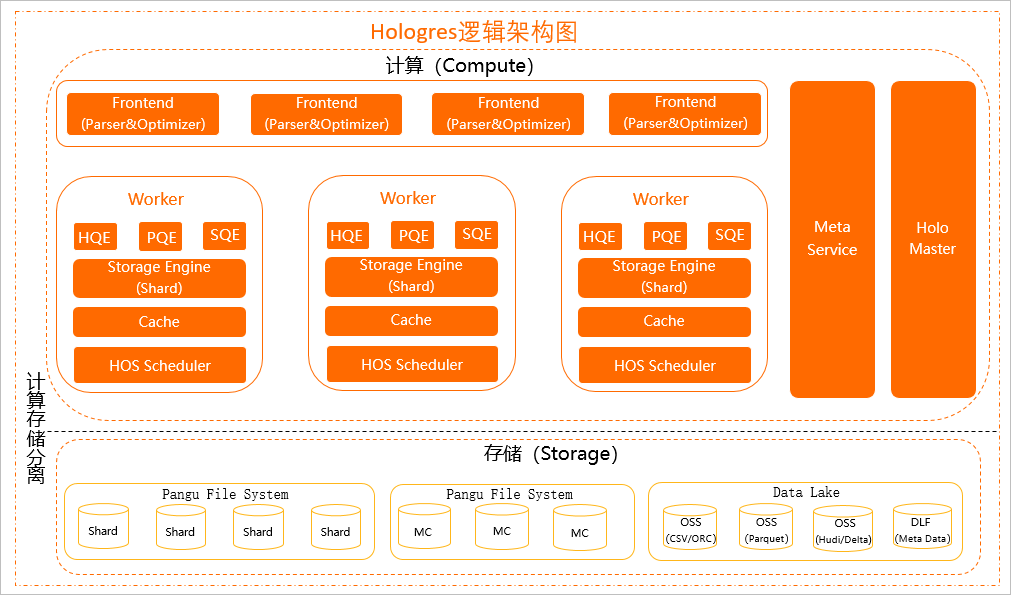
整个架构从上往下分为如下组件。
计算层
接入节点(Frontend,FE)
Hologres接入节点,主要用于SQL的认证、解析、优化,一个实例有多个FE接入节点。在生态上兼容Postgres 11,因此用户可以使用Postgres标准语法进行开发,也可以用Postgres兼容的开发工具和BI工具直接连接Hologres。
计算HoloWorker
HoloWorker分为执行引擎、存储引擎、调度等组件,主要负责用户任务的计算、调度。
其中执行引擎(Query Engine,QE)主要有三个,执行引擎的技术原理请参见Hologres执行引擎技术揭秘。
HQE(Hologres Query Engine)
Hologres自研执行引擎,采用可扩展的MPP架构全并行计算,向量化算子发挥CPU极致算力,从而实现极致的查询性能。(QE主要由HQE组成)。
PQE(Postgres Query Engine)
用于兼容Postgres提供扩展能力,支持PG生态的各种扩展组件,如PostGIS,UDF(PL/JAVA,PL/SQL,PL/Python)等。部分HQE还没有支持的函数和算子,会通过PQE执行,每个版本都在持续优化中,最终目标是去掉PQE。
SQE(Seahawks Query Engine)
无缝对接MaxCompute(ODPS)的执行引擎,实现对MaxCompute的本地访问,无需迁移和导入数据,就可以高性能和全兼容的访问各种MaxCompute文件格式,以及Hash/Range clustered table等复杂表,实现对PB级离线数据的交互式分析,技术原理请参见Hologres加速查询MaxCompute技术揭秘。
存储引擎Storage Engine(SE)
主要用于管理和处理数据, 包括创建、查询、更新和删除(简称 CRUD)数据等,关于存储引擎详细的技术原理请参见Hologres存储引擎技术揭秘。
Cache(缓存)
主要是结果缓存,提高查询性能。
HOS Scheduler
轻量级调度。
Meta Service
主要用于管理元数据Meta信息(包括表结构信息以及数据在Storage Engine节点上的分布情况),并将Meta信息提供给FE节点。
Holo Master
Hologres原生部署在K8s上,当某个Worker出现故障时,由K8s进行快速拉起创建一个新的Worker,保障Worker级别的可用性。在Worker内部,每个组件的可用性则由Holo Master负责,当组件出现状态不正常时,Holo Master则会快速重新拉起组件,从而恢复服务,高可用技术原理请参见Hologres高可用技术揭秘。
存储层
数据直接存储在Pangu File System。
与MaxCompute在存储层打通,能直接访问MaxCompute存储在盘古的数据,实现高效相互访问。
支持直接访问OSS、DLF数据,类型包含CSV、ORC、Parquet、Hudi、Delta、Meta Data等,加速数据湖探索,也可以将数据回流至OSS,降低存储成本。