本文为您介绍在Hologres中对内部表性能进行调优的最佳实践。
更新统计信息
统计信息决定是否能够生成正确的执行计划。例如,Hologres需要收集数据的采样统计信息,包括数据的分布和特征、表的统计信息、列的统计信息、行数、列数、字段宽度、基数、频度、最大值、最小值、长键值、分桶分布特征等信息。这些信息将为优化器更新算子执行预估COST、搜索空间裁剪、估算最优Join Order、估算内存开销、估算并行度,从而生成更优的执行计划。关于统计信息更多的介绍,请参见Using Explain。
统计信息的收集也存在一定局限,主要是针对非实时、手动触发或者周期性触发,不一定反映最准确的数据特征。您需要先检查explain的信息,查看explain中包含的统计信息是否正确。统计信息中每个算子的rows和width表示该算子的行数和宽度。
查看统计信息是否正确
通过查看执行计划:
未及时同步统计信息导致生成较差的执行计划,示例如下:
tmp1表的数据量为1000万行,tmp表的数据量为1000行。 Hologres默认统计信息中的行数为1000行,通过执行explainSQL语句,如下展示结果所示,tmp1表的行数与实际的行数不符,该展示结果表明未及时更新统计信息。
Seq Scan on tmp1 (cost=0.00..5.01 rows=1000 width=1)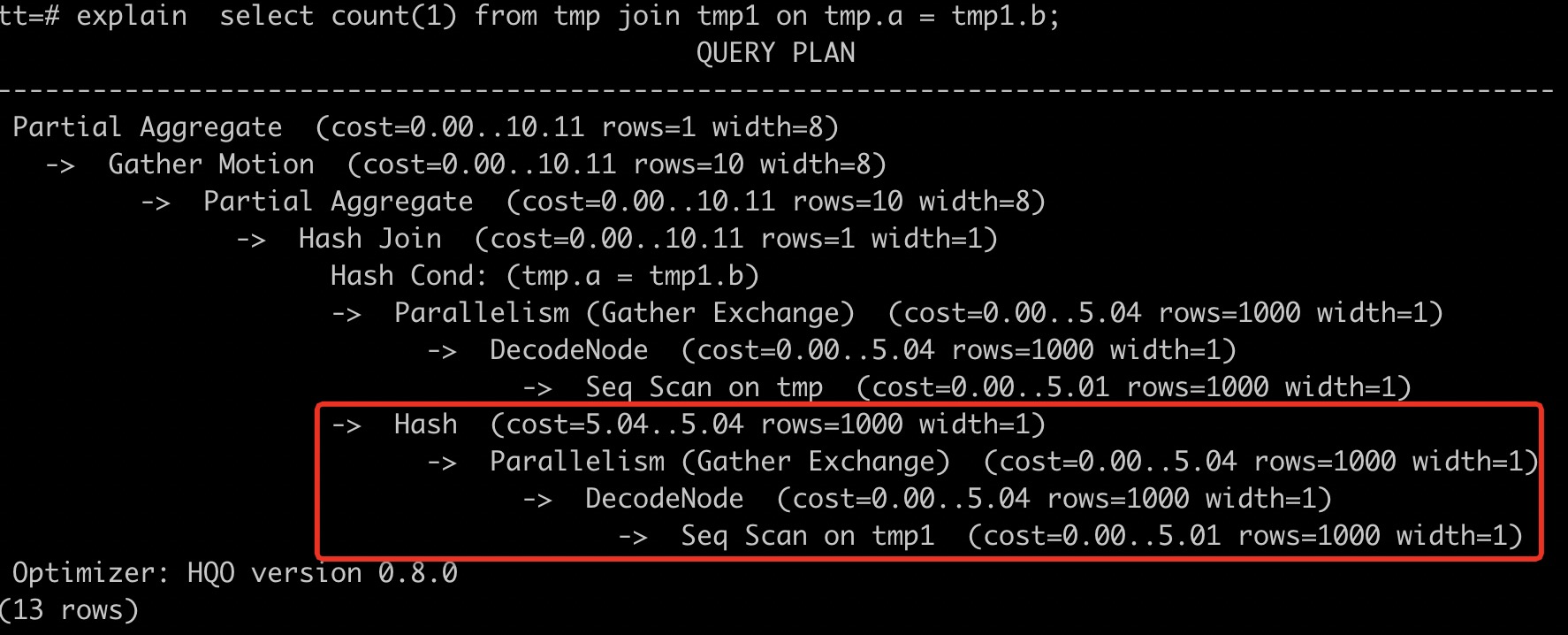
更新统计信息
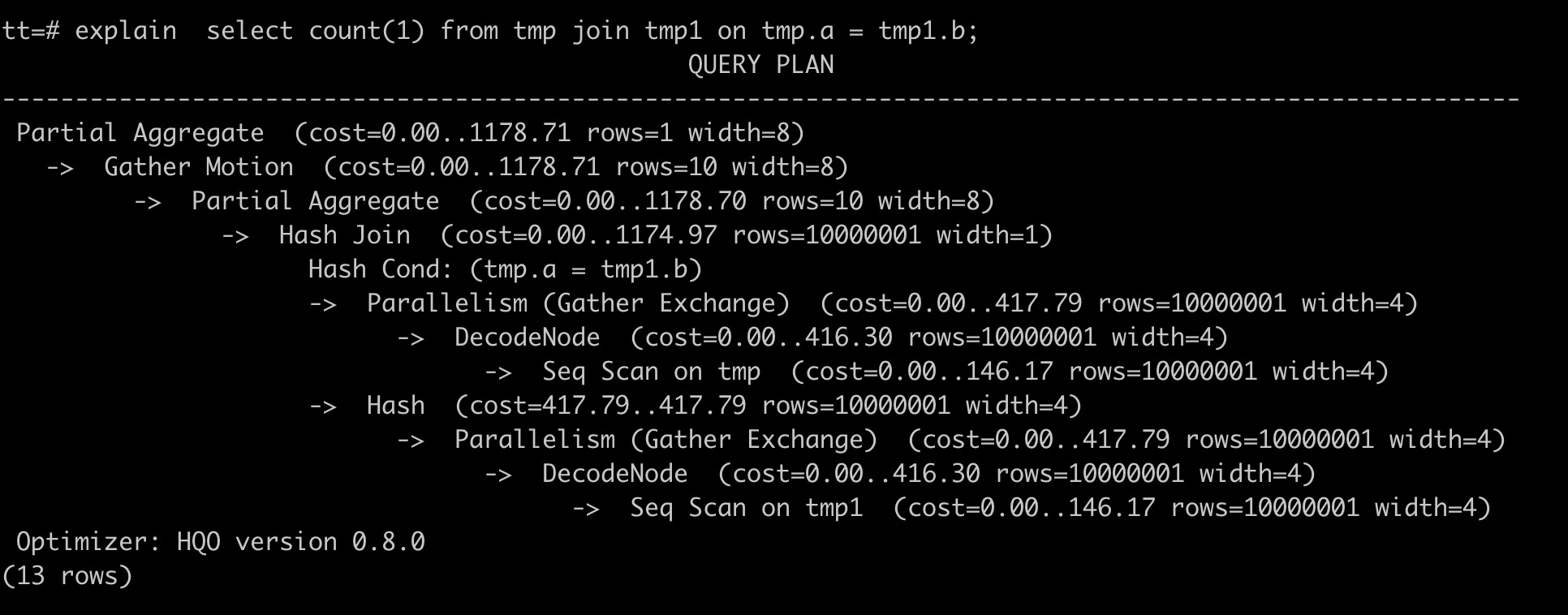
tmp1和tmp表Join时,正确的explain信息展示为数据量大的表tmp1在数据量小的表tmp上方,Hash Join应该采用数据量小的tmp表。因为tmp1表未及时更新统计信息,导致Hologres选择tmp1表创建Hash表进行Hash Join,效率较低,并且可能造成OOM(Out Of Memory,内存溢出)。因此,需要参与Join的两张表均执行analyze收集统计信息,语句如下。
analyze tmp;
analyze tmp1;执行analyze命令后,Join的顺序正确。数据量大的表tmp1在数据量小的表tmp上方,使用数据量小的表tmp做Hash表,如下图所示。并且tmp1表展示的行数为1000万行,表明统计信息已经更新。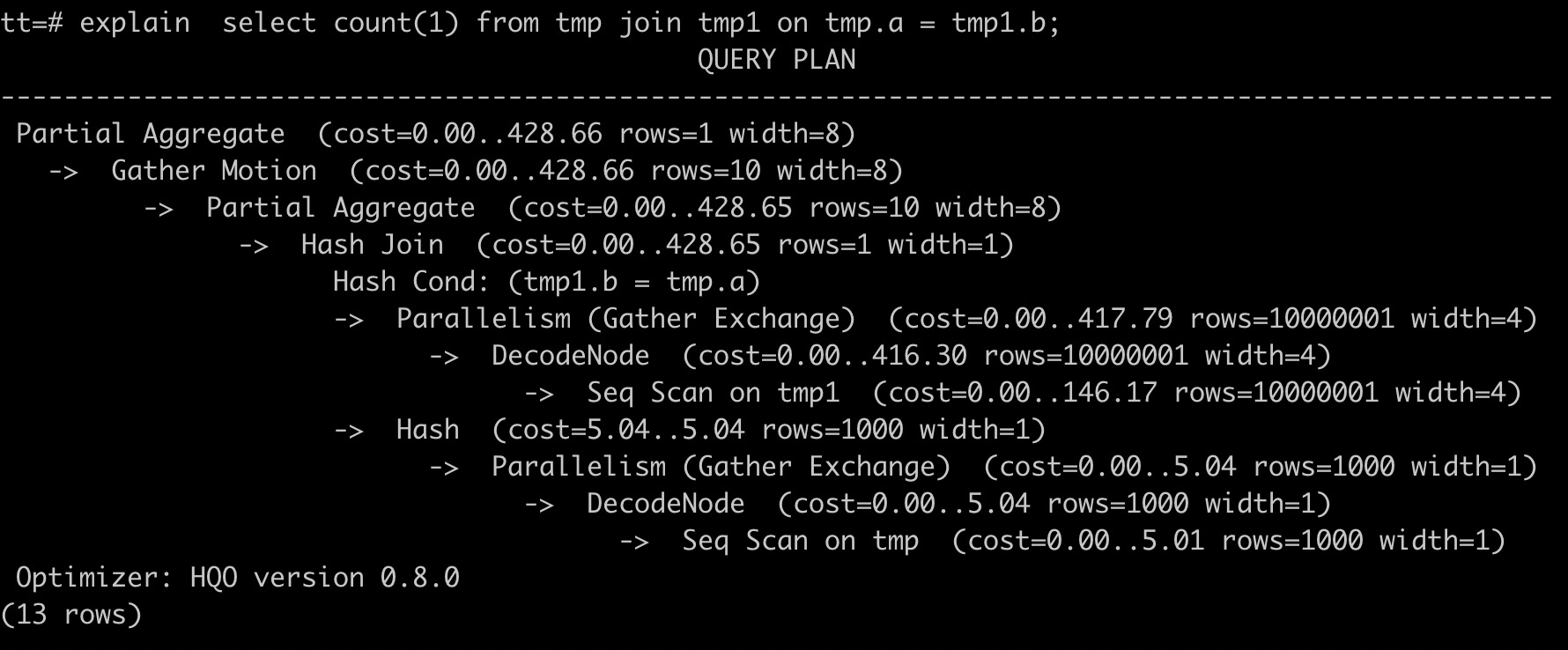
当发现explain返回结果中rows=1000,说明缺少统计信息。一般性能不好时,其原因通常是优化器缺少统计信息,需要通过及时更新统计信息,执行analyze <tablename>,可以简单快捷优化查询性能。
推荐更新统计信息的场景
推荐在以下情况下运行analyze <tablename>命令。
导入数据之后。
大量的INSERT、UPDATE以及DELETE操作之后。
内部表、外部表均需要ANALYZE。
分区表针对父表做ANALYZE。
如果遇到以下问题,您需要先执行
analyze <tablename>,再运行导入任务,可以系统地优化效率。多表JOIN超出内存OOM。
通常会产生
Query executor exceeded total memory limitation xxxxx: yyyy bytes used报错。导入效率较低。
在Hologres查询或导入数据时,效率较低,运行的任务长时间不结束。
设置适合的Shard数
Shard数代表查询执行的并行度。Shard个数对查询性能影响至关重要,Shard数设置少,会导致并行度不足。Shard数设置过多,也会引起查询启动开销大,降低查询效率,同时引起小文件过多,占用内存更多的元数据管理空间。设置与实例规格匹配的Shard数,可以改善查询效率,降低内存开销。
Hologres为每个实例设置了默认的Shard数,Shard数约等于实例中用于核心查询的Core数。这里的core数,略小于实际购买的Core数(实际购买的Core会被分配给不同的节点,包括查询节点、接入节点、控制节点和调度节点等)。不同规格实例默认的Shard数,请参见实例管理。当实例扩容后,扩容之前旧的DB对应的默认Shard数不会自动修改,需要根据实际情况修改Shard数,扩容后新建DB的Shard数为当前规格的默认数量。默认的Shard数是已经考虑扩容的场景,在资源扩容5倍以上的场景中,建议考虑重新设置Shard数,小于5倍的场景,无需修改也能带来执行效率的提升。具体操作请参见Table Group设置最佳实践。
如下场景需要修改Shard数:
扩容后,因业务需要,原有业务有规模增长,需要提高原有业务的查询效率。此时,您需要创建新的Table Group,并为其设置更大的Shard数。原有的表和数据仍然在旧的Table Group中,您需要将数据重新导入新的Table Group中,完成Resharding的过程。
扩容后,需要上线新业务,但已有业务并不变化。此时,建议您创建新的Table Group,并为其设置适合的Shard数,并不调整原有表的结构。
一个DB内可以创建多个Table Group,但所有Table Group的Shard总数之和不应超过Hologres推荐的默认Shard数,这是对CPU资源的最有效利用。
JOIN场景优化
当有两表或多表JOIN时,为了提高JOIN的性能,有如下几种优化方式。
更新统计信息
如上述查看统计信息中,参与Join的表如果未及时更新统计信息,可能会导致数据量大的表做了Hash表,从而导致Join效率变低。因此可以通过更新表的统计信息,提升SQL性能。
analyze <tablename>;选择合适的分布列(Distribution Key)
分布列(Distribution Key)用于将数据划分到多个Shard,划分均衡可以避免数据倾斜。多个相关的表设计为相同的Distribution Key,可以起到Local Join的加速效果。创建表时,您可以通过如下原则选择合适的分布列:
Distribution Key设置建议
选择Join查询时的连接条件列作为分布列。
选择Group By频繁的列作为分布列。
选择数据分布均匀离散的列作为分布列。
更多关于Distribution Key的原理和使用详情请参见分布键Distribution Key。
设置Distribution Key场景示例
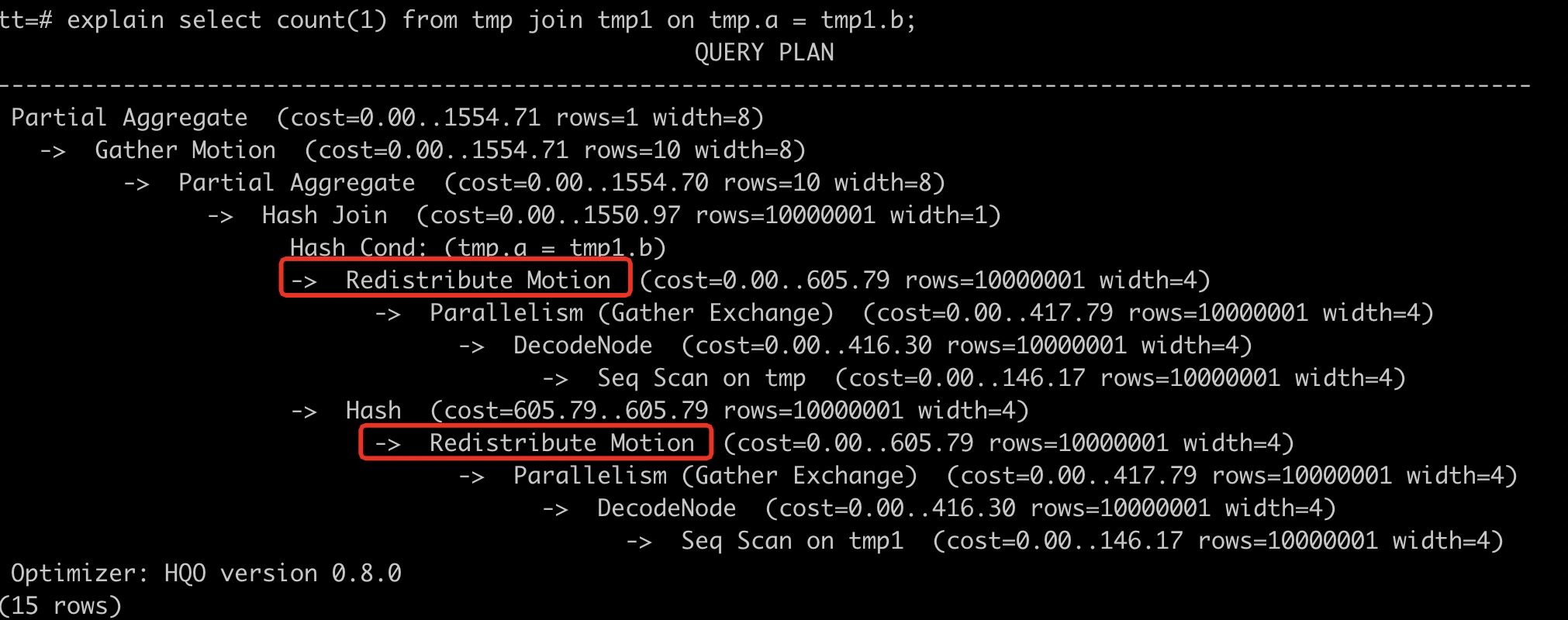
例如设置Distribution Key,表tmp和tmp1做Join,通过执行explain SQL语句看到执行计划中有Redistribution Motion,说明数据有重分布,没有Local Join,导致查询效率比较低。您需要重新建表并同时设置Join Key为Distribution Key,避免多表连接时数据重分布带来的额外开销。
 重新建表后两个表的DDL示例语句如下。
重新建表后两个表的DDL示例语句如下。begin; create table tmp(a int, b int, c int); call set_table_property('tmp', 'distribution_key', 'a'); commit; begin; create table tmp1(a int, b int, c int); call set_table_property('tmp1', 'distribution_key', 'b'); commit; -- 设置分布列为Join Key。 select count(1) from tmp join tmp1 on tmp.a = tmp1.b ;通过重新设置表的Distribution Key,再次执行explain SQL语句,可以看到执行计划中,红框内的算子被优化掉了,数据按照相同的Hash Key分布于Shard中。因为数据分布相同,Motion算子被优化(上图中红框内的算子),表明数据不会重新分布,从而避免了冗余的网络开销。
使用Runtime Filter
从V2.0版本开始,Hologres开始支持Runtime Filter,通常应用在多表Join(至少2张表),尤其是大表Join小表的场景中,无需手动设置,优化器和执行引擎会在查询时自动优化Join过程的过滤行为,使得扫描更少的数据量,从而降低IO开销,以此提升Join的查询性能,详情请参见Runtime Filter。
优化Join Order算法
当SQL Join关系比较复杂时,或者Join的表多时,优化器(QO)消耗在连接关系最优选择上的时间会更多,调整Join Order策略,在一定场景下会减少Query Optimization的耗时,设置优化器Join Order算法语法如下。
set optimizer_join_order = '<value>';参数说明
参数
说明
value
优化器Join Order算法,有如下几种。
exhaustive2(V2.2及以上版本默认值):升级优化的动态规划算法。
exhaustive(早期版本默认值):通过动态规划算法进行Join Order转换,会生成最优的执行计划,但优化器开销最高。
query:不进行Join Order转换,按照SQL书写的连接顺序执行,优化器开销最低。
greedy:通过贪心算法进行Join Order的探索,优化器开销适中。
补充说明
使用默认的exhaustive2算法可以全局探索最优的执行计划,但对于很多表的Join(例如表数量大于10),优化耗时可能较高。使用query或者greedy算法可以减少优化器耗时,但无法生成最优的执行计划。
优化Broadcast等Motion算子
目前Hologres包含四种Motion Node,分别对应四种数据重分布场景,如下表所示。
类型 | 描述 |
Redistribute Motion | 数据通过哈希分布或随机分布,Shuffle到一个或多个Shard。 |
Broadcast Motion | 复制数据至所有Shard。 仅在Shard数量与广播的表的数量均较少时,Broadcast Motion的优势较大。 |
Gather Motion | 汇总数据至一个Shard。 |
Forward Motion | 用于联邦查询场景。外部数据源或执行引擎与Hologres执行引擎进行数据传输。 |
结合explain SQL语句执行结果您可以注意如下事项:
如果Motion算子耗时较高,则您可以重新设计分布列。
如果统计信息错误,导致生成Gather Motion或Broadcast Motion,则您可以通过
analyze <tablename>命令将其修改为更高效的Redistribute Motion分布方式。Broadcast Motion只有在Shard数较少,且广播表的数量较少的场景下有优势。所以如果是小表Broadcast的场景,建议您将表的Shard数量减少(尽量保持Shard Count与Worker数量成比例关系),从而提高查询效率。Shard Count详情请参见Shard Count。
关闭Dictionary Encoding
对于字符类型(包括Text/Char/Varchar)的相关查询,Dictionary Encoding或Decoding会减少比较字符串的耗时,但是会带来大量的Decode或Encode开销。
Hologres默认对所有的字符类型列建立Dictionary Encoding,您可以设置dictionary_encoding_columns为空,或关闭部分列的自动Dictionary Encoding功能。注意,修改Dictionary Encoding设置,会引起数据文件重新编码存储,会在一段时间内消耗一部分CPU和内存资源,建议在业务低峰期执行变更。
当Decode算子的耗时较高时,请关闭Decode。关闭Dictionary Encoding功能可以改善性能。
当表的字符类型字段较多时,按需选择,可以不用将所有的字符类型都加入dictionary_encoding_columns。示例语句如下:
begin;
create table tbl (a int not null, b text not null, c int not null, d int);
call set_table_property('tbl', 'dictionary_encoding_columns', '');
commit;常见的性能调优手段
可以通过优化相应的SQL来提高查询效率。
采用Fixed Plan
Fixed Plan适用于高吞吐场景,通过简化的执行路径,实现数倍性能和吞吐的提升,配置方式和使用方法请参考Fixed Plan加速SQL执行。
PQE算子改写
Hologres底层有原生引擎HQE(Hologres Query Engine,向量引擎)和PQE(Postgres Query Engine,分布式Postgres引擎)等多个执行引擎,如果SQL语句中包含HQE不支持的算子,则系统会将该算子发送至PQE执行。此时查询的性能未能足够优化,需要修改相关查询语句。
通过执行计划(explain SQL)查询,若执行计划中出现External SQL(Postgres)则说明这部分的SQL是在PQE中执行的。
具体示例如下:HQE不支持not in,则会将not in操作转到外部查询引擎PQE执行。建议将not in重写为not exists。优化前的SQL语句如下。
explain select * from tmp where a not in (select a from tmp1);External算子代表该部分SQL语句是在外部引擎Postgres中执行的。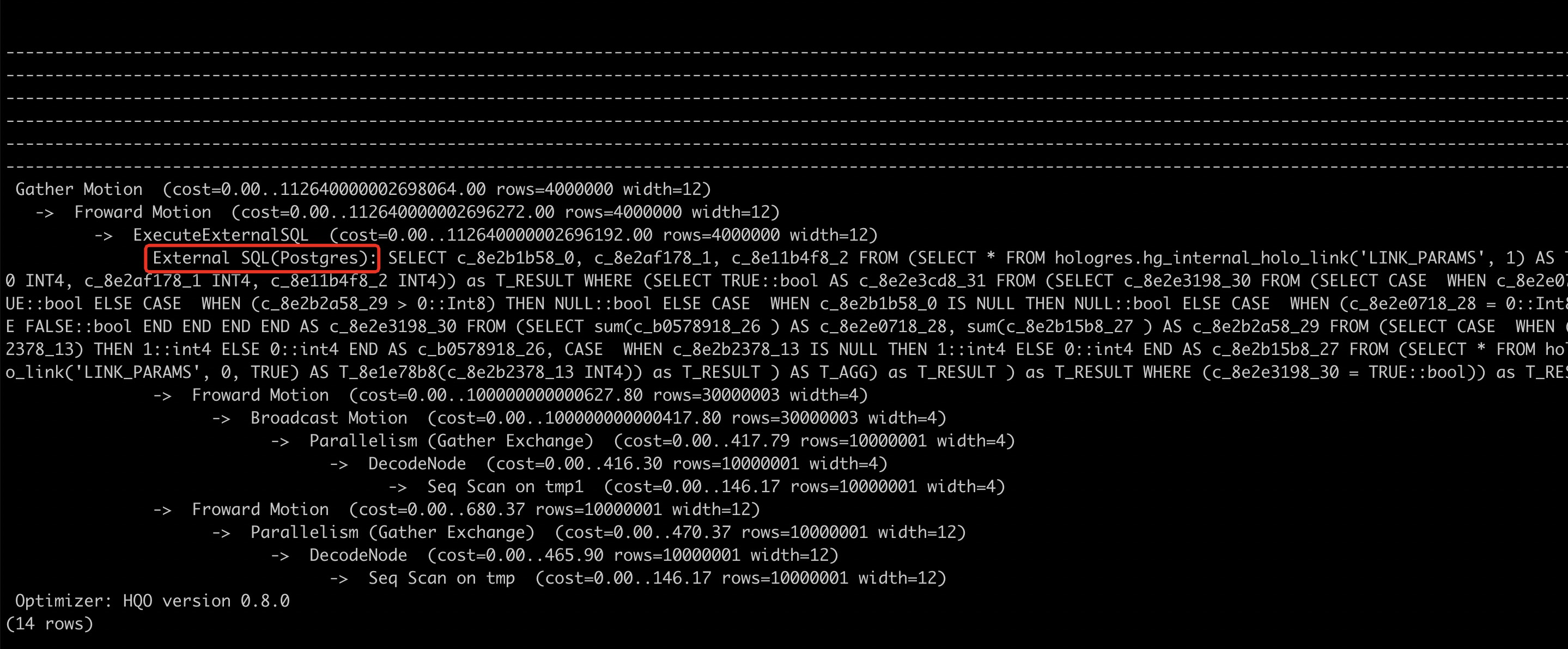
优化后的SQL语句如下,不再使用外部查询引擎。
explain select * from tmp where not exists (select a from tmp1 where a = tmp.a);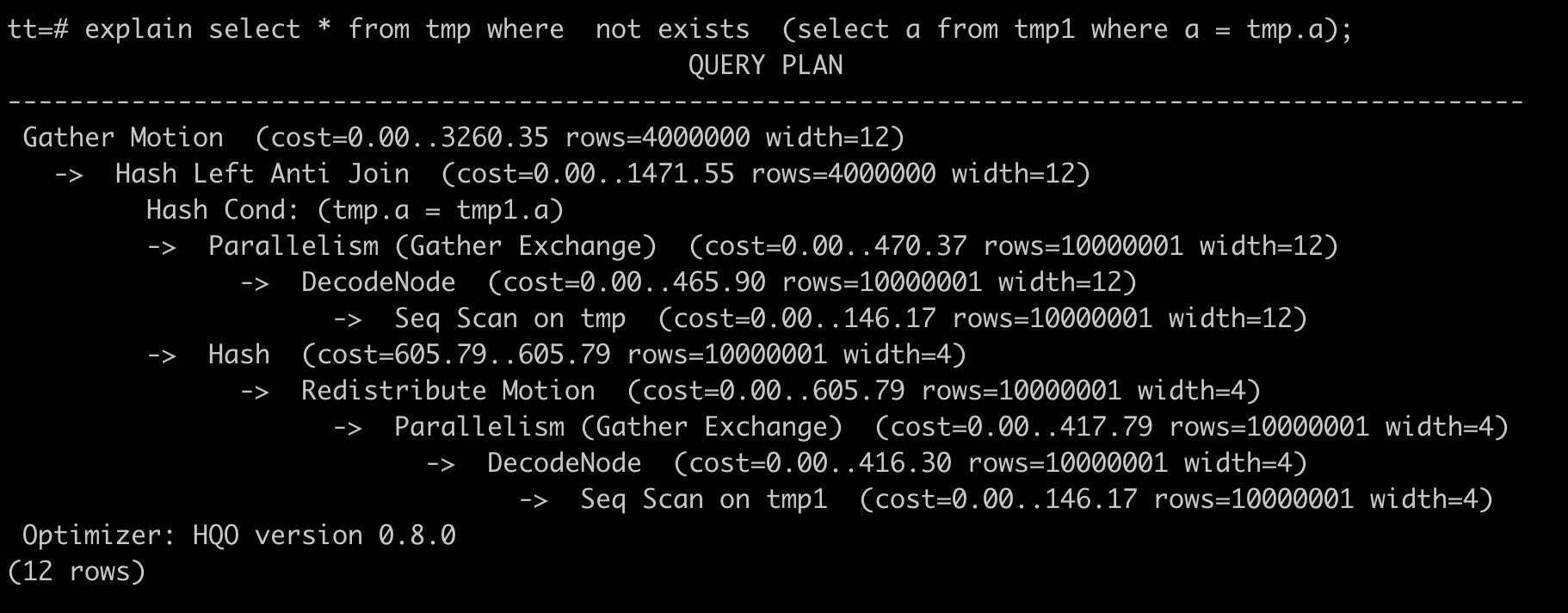
通过改写函数,将算子运行在HQE引擎中,以下为函数改写建议。同时Hologres每个版本都在不断迭代PQE函数,以将更多函数下推至HQE。如果是HQE已经支持的函数,则可以通过升级版本来解决,详情请参见函数功能发布记录。
Hologres原生引擎(HQE)不支持的函数 | 建议改写的函数 | 样例 | 备注 |
not in | not exists | | 不涉及。 |
regexp_split_to_table(string text, pattern text) | unnest(string_to_array) | | regexp_split_to_table支持正则表达式。 Hologres V2.0.4版本起HQE支持regexp_split_to_table,需要使用如下命令开启GUC:set hg_experimental_enable_hqe_table_function = on; |
substring | extract(hour from to_timestamp(c1, 'YYYYMMDD HH24:MI:SS')) | 改写为: | Hologres部分V0.10版本及更早版本不支持substring。V1.3版本及以上版本中,HQE已支持substring函数的非正则表达式入参。 |
regexp_replace | replace | 改写为: | replace不支持正则表达式。 |
at time zone 'utc' | 删除at time zone 'utc' | 改写为: | 不涉及。 |
cast(text as timestamp) | to_timestamp | 改写为: | Hologres V2.0版本起HQE支持。 |
timestamp::text | to_char | 改写为: | Hologres V2.0版本起HQE支持。 |
避免模糊查询
模糊查询(Like操作)不会建立索引。
结果缓存对查询的影响
Hologres会默认对相同的查询或子查询结果进行缓存,重复执行会命中缓存结果。您可以使用如下命令关闭缓存对性能测试的影响:
set hg_experimental_enable_result_cache = off;OOM的优化手段
当实例计算内存不足时通常会出现OOM,常见的报错如下。产生OOM的原因有多种,比如计算复杂、并发量高等,可以根据不同的原因进行针对性优化,从而减少OOM。详情请参见OOM常见问题排查指南。
Total memory used by all existing queries exceeded memory limitation.
memory usage for existing queries=(2031xxxx,184yy)(2021yyyy,85yy)(1021121xxxx,6yy)(2021xxx,18yy)(202xxxx,14yy); Used/Limit: xy1/xy2 quota/sum_quota: zz/100Order By Limit场景优化
在Hologres V1.3之前版本,对Order By Limit场景不支持Merge Sort算子,生成执行计划时,在最后输出时还会做一次排序,导致性能相对较差。从1.3版本开始,引擎通过对Order By Limit场景优化,支持Merge Sort算子,实现多路归并排序,无需再进行额外的排序,提升了查询性能。
优化示例如下。
建表DDL
begin;
create table test_use_sort_1
(
uuid text not null,
gpackagename text not null,
recv_timestamp text not null
);
call set_table_property('test_use_sort_1', 'orientation', 'column');
call set_table_property('test_use_sort_1', 'distribution_key', 'uuid');
call set_table_property('test_use_sort_1', 'clustering_key', 'uuid:asc,gpackagename:asc,recv_timestamp:desc');
commit;
--插入数据
insert into test_use_sort_1 select i::text, i::text, '20210814' from generate_series(1, 10000) as s(i);
--更新统计信息
analyze test_use_sort_1;查询命令
set hg_experimental_enable_reserve_gather_exchange_order =on
set hg_experimental_enable_reserve_gather_motion_order =on
select uuid from test_use_sort_1 order by uuid limit 5;执行计划对比
Hologres V1.3之前版本(V1.1)的执行计划如下。

Hologres V1.3版本的执行计划如下。

从执行计划对比中可以看出,Hologres V1.3版本在最后输出会少一个排序,直接多路归并,提升了查询性能。
Count Distinct优化
改写为APPROX_COUNT_DISTINCT
Count Distinct是精确去重,需要把相同key的记录shuffle到同一个节点去重,比较耗费资源。Hologres实现了扩展函数APPROX_COUNT_DISTINCT,采用HyperLogLog基数估计的方式进行非精确的COUNT DISTINCT计算,提升查询性能。误差率平均可以控制在0.1%-1%以内,可以根据业务情况适当改写,详情请参见APPROX_COUNT_DISTINCT。
使用UNIQ函数
Hologres从 V1.3版本开始,支持UNIQ精确去重函数,在GROUP BY KEY的KEY基数较高时,比Count Distinct性能更好,更节省内存。当使用Count Distinct出现OOM时,可以使用UNIQ做替换,详情请参见UNIQ。
设置合适的Distribution Key
当有多个Count Distinct且是key是同一个并且数据离散均匀分布,建议将Count Distinct的key设置成Distribution Key,这样相同的数据可以分布相同的Shard,避免数据Shuffle。
Count Distinct优化
Hologres从V2.1版本开始,针对Count Distinct场景做了非常多的性能优化(包括单个Count Distinct、多个Count Distinct、数据倾斜、SQL没有Group By字段等场景),无需手动改写成UNIQ,即可实现更好的性能。如果想要提升Count Distinct性能,建议您将Hologres实例升级至V2.1及以上版本。
Group By 优化
Group By Key会导致数据在计算时按照分组列的Key重新分布数据,如果Group By耗时较高,您可以将Group By的列设置为分布列。
-- 数据如果按照a列的值进行分布,将减少数据运行时重分布,充分利用shard的并行计算能力。
select a, count(1) from t1 group by a; 从 4.0 版本开始,提供了合并优化,即如果 GROUP BY 多个相同列的情况下减少合并的能力。例如当出现类似 GROUP BY COL_A, ((COL_A + 1)), ((COL_A + 2)) 场景时,会被改写成等价的 GROUP BY COL_A。考虑到探查的消耗,最多只会搜索5层。例如:
CREATE TABLE tbl (
a int,
b int,
c int
);
-- 查询
SELECT
a,
a + 1 as a1,
a + 2 as a2,
sum(b)
FROM tbl
GROUP BY
a,
a1,
a2;执行计划如下图所示,可以看到进行了查询改写,仅GROUP BY了 A 列。
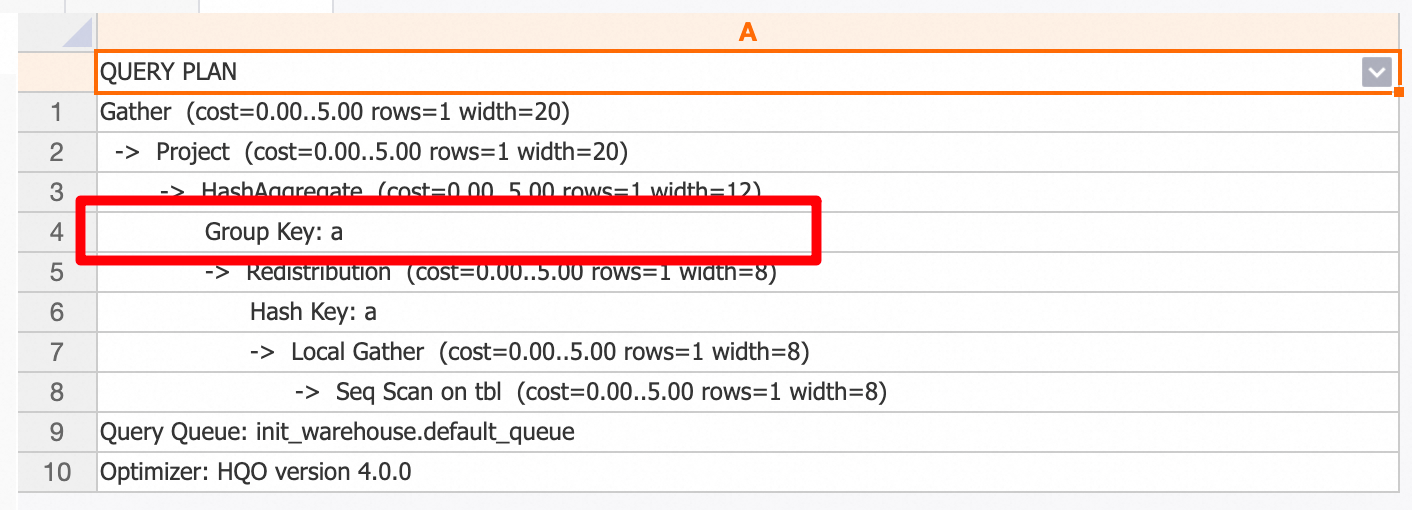
该功能可以通过以下GUC关闭:
-- SESSION 级别关闭
SET hg_experimental_remove_related_group_by_key = off;
-- 数据库级别关闭
ALTER DATABASE <database_name> SET hg_experimental_remove_related_group_by_key = off; 数据倾斜处理
数据在多个Shard上分布不均匀会导致查询速度较慢,您可以通过如下语句判断数据分布是否存在倾斜。详情请参见查看Worker倾斜关系。
-- hg_shard_id是每个表的内置隐藏列,描述对应行数据所在shard
select hg_shard_id, count(1) from t1 group by hg_shard_id;如果数据存在显著倾斜,则需要更改distribution_key,选择数据分布均匀离散的列作为分布列。
说明更改distribution_key需要重新创建表并导入数据。
如果数据本身存在倾斜(与distribution_key无关时),建议从业务角度对数据进行优化,避免倾斜。
With表达式优化(Beta)
Hologres兼容PostgreSQL ,支持CTE(Common Table Expression),常用在with递归查询,其实现原理同PostgreSQL,都是基于Inlining展开的,所以当有多次使用CTE时会造成重复计算。在HologresV1.3版本中,可以通过如下GUC参数支持CTE Reuse(复用),这样CTE只需计算一次而被多次引用,用以节省计算资源,提升查询性能。若您的Hologres实例版本低于 V1.3,请升级实例。
set optimizer_cte_inlining=off;该功能当前还处于Beta阶段,默认没有开启(默认会将CTE全部Inline展开,重复计算),可手动设置GUC后开启使用。
CTE Reuse开启后,依赖Shuffle阶段的Spill功能,因为下游用户消费CTE的进度是不同步的,所以数据量大的时候会影响性能。
示例
create table cte_reuse_test_t ( a integer not null, b text, primary key (a) ); insert into cte_reuse_test_t values(1, 'a'),(2, 'b'), (3, 'c'), (4, 'b'), (5, 'c'), (6, ''), (7, null); set optimizer_cte_inlining=off; explain with c as (select b, max(a) as a from cte_reuse_test_t group by b) select a1.a,a2.a,a1.b, a2.b from c a1, c a2 where a1.b = a2.b order by a1.b limit 100;执行计划对比
Hologres V1.3之前版本(V1.1)的执行计划如下。

Hologres V1.3版本的执行计划如下。

从执行计划的对比中可以看出Hologres V1.3之前版本会有多个AGG计算(HashAggregate),Hologres V1.3版本只需计算一次就被结果复用,提升了性能。
单阶段Agg优化为多阶段Agg
如果Agg算子耗时过高,您可以检查是否没有做Local Shard级别的预聚合。
通过在单个Shard内先进行本地的Agg操作,可以减少最终聚合操作的数据量,提升性能。具体如下:
三阶段聚合:数据先进行文件级别的聚合计算,再聚合单个Shard内的数据,最后汇总所有Shard的结果。
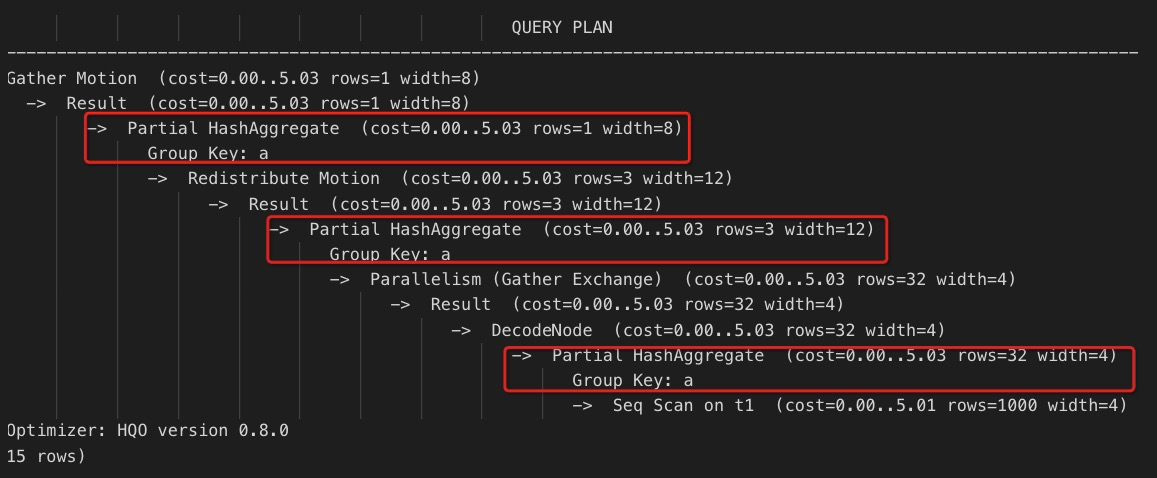
两阶段聚合:数据先在单个Shard内进行聚合计算,再汇总所有Shard的结果。
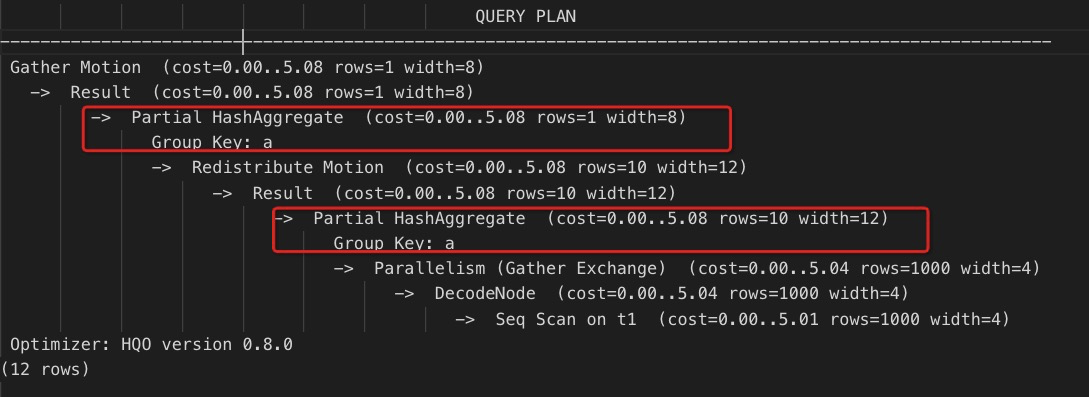
您可以强制Hologres进行多阶段聚合操作,语句如下。
set optimizer_force_multistage_agg = on;多同名聚合函数优化
生产场景中,可能会存在一个 SQL 中有多个相同的聚合函数且对于同一个列进行聚合。从 4.0 开始,支持等价改写,可以减少计算次数,提升查询性能。使用示例如下:
准备数据
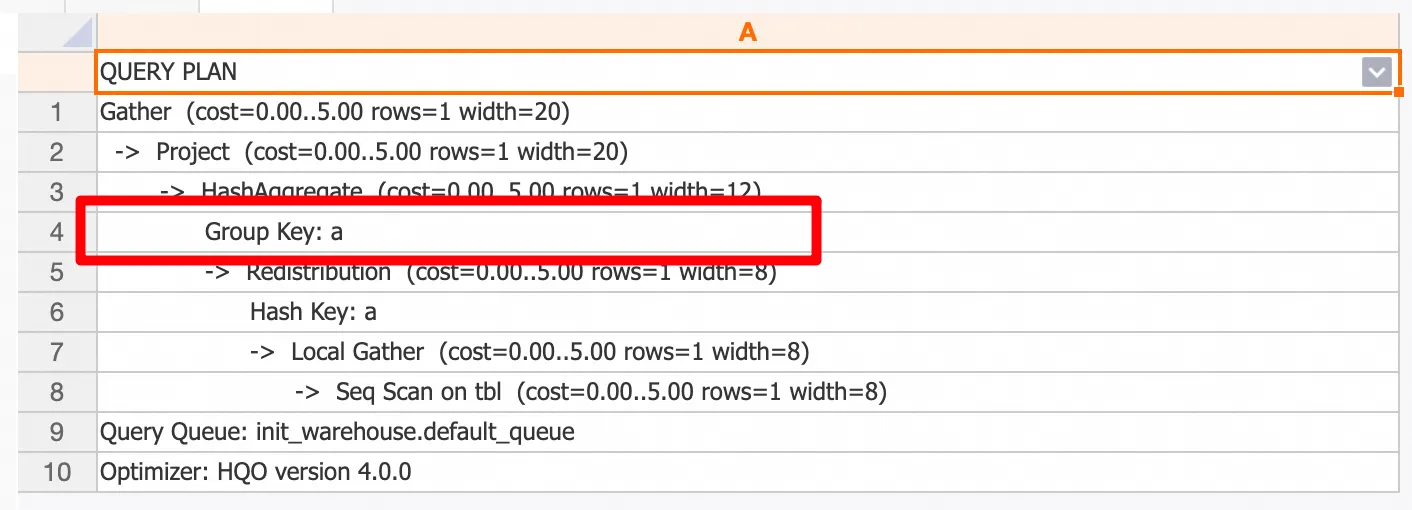
-- 创建测试表 CREATE TABLE tbl(x int4, y int4); -- 插入测试数据 INSERT INTO tbl VALUES (1,2), (null,200), (1000,null), (10000,20000);样例子查询
SELECT sum(x + 1), sum(x + 2), sum(x - 3), sum(x - 4) FROM tbl;执行计划如下,可以看到进行了查询改写,仅对a列进行了分组。
该功能可以通过以下GUC关闭:
-- SESSION 级别关闭 SET hg_experimental_remove_related_group_by_key = off; -- 数据库级别关闭 ALTER DATABASE <database_name> SET hg_experimental_remove_related_group_by_key = off;
建表属性优化
选择存储类型
Hologres支持行存储、列存储和行列共存多种存储模式,您可以根据业务场景选择合适的存储类型,如下表所示。
类型 | 适用场景 | 缺点 |
行存储 |
| 大范围的查询、全表扫描及聚合等操作性能较差。 |
列存储 | 适用于多列按范围查询、单表聚合及多表连接等数据分析场景。 | UPDATE和DELETE操作及无索引场景下的点查询性能慢于行存储。 |
行列共存 | 同时具备以上行列两种使用场景。 | 存储开销更高。 |
选择数据类型
Hologres支持多种数据类型,您可以根据业务场景以及需求选择合适的数据类型,原则如下:
尽量选用存储空间小的类型。
优先使用INT类型,而不是BIGINT类型。
优先使用精确确定的DECIMAL/NUMERIC类型,明确数值精度(PRECISION,SCALE),且精度尽量小,减少使用FLOAT/DOUBLE PRECISION等非精确类型,避免统计汇总中的误差。
GROUP BY的列不建议使用FLOAT/DOUBLE等非精确类型。
优先使用TEXT,适用范围更广,当使用
VARCHAR(N)和CHAR(N),N的取值尽量小。日期类型使用TIMESTAMPTZ、DATE,避免使用TEXT。
关联条件使用一致的数据类型。
进行多表关联时,不同列尽量使用相同的数据类型。避免Hologres将不同类型的列进行隐式类型转换,造成额外的开销。
UNION或GROUP BY等操作避免使用FLOAT/DOUBLE等非精确类型。
UNION或GROUP BY等操作暂不支持DOUBLE PRECISION和FLOAT数据类型,需要使用DECIMAL类型。
选择主键
主键(Primary Key)主要用于保证数据的唯一性,适用于主键重复的导入数据场景。您可以在导入数据时设置option选择去重方式,如下所示:
ignore:忽略新数据。
update:新数据覆盖旧数据。
合理的设置主键能帮助优化器在某些场景下生成更好的执行计划。例如,查询为group by pk,a,b,c的场景。
但是在列存储场景,主键的设置对于写入数据的性能会有较大的影响。通常,不设置主键的写入性能是设置主键的3倍。
选择分区表
Hologres当前仅支持创建一级分区表。合理的设置分区会加速查询性能,不合理的设置(比如分区过多)会造成小文件过多,查询性能显著下降。
对于按天增量导入的数据,建议按天建成分区表,数据单独存储,只访问当天数据。
设置分区适用的场景如下:
删除整个子表的分区,不影响其他分区数据。DROP/TRUNCATE语句的性能高于DELETE语句。
对于分区列在谓词条件中的查询,可以直接通过分区列索引到对应分区,并且可以直接查询子分区,操作更为灵活。
对于周期性实时导入的数据,适用于创建分区表。例如,每天都会导入新的数据,可以将日期作为分区列,每天导入数据至一个子分区。示例语句如下。
begin;
create table insert_partition(c1 bigint not null, c2 boolean, c3 float not null, c4 text, c5 timestamptz not null) partition by list(c4);
call set_table_property('insert_partition', 'orientation', 'column');
commit;
create table insert_partition_child1 partition of insert_partition for values in('20190707');
create table insert_partition_child2 partition of insert_partition for values in('20190708');
create table insert_partition_child3 partition of insert_partition for values in('20190709');
select * from insert_partition where c4 >= '20190708';
select * from insert_partition_child3;选择索引
Hologres支持设置多种索引,不同索引的作用不同。您可以根据业务场景选择合适的索引,提升查询性能,因此写入数据前,请根据业务场景提前设计好表结构。索引类型如下表所示。
类型 | 名称 | 描述 | 使用建议 | 示例查询语句 |
clustering_key | 聚簇列 | 文件内聚簇索引,数据在文件内按该索引排序。 对于部分范围查询,Hologres可以直接通过聚簇索引的数据有序属性进行过滤。 | 将范围查询或Filter查询列作为聚簇索引列。索引过滤具备左匹配原则,建议设置不超过2列。 |
|
bitmap_columns | 位图列 | 文件内位图索引,数据在文件内按该索引列建立位图。 对于等值查询,Hologres可以按照数值对每一行的数据做编码,通过位操作快速索引到对应行,时间复杂度为O(1)。 | 将等值查询列作为Bitmap列。 |
|
segment_key(也称为event_time_column) | 分段列 | 文件索引,数据按Append Only方式写入文件,随后文件间按该索引键合并小文件。 Segment_key标识了文件的边界范围,您可以通过Segment Key快速索引到目标文件。 Segment_key是为时间戳、日期等有序,范围类数据场景设计的,因此与数据的写入时间有强相关性。 | 您需要先通过Segment_key进行快速过滤,再通过Bitmap或Cluster索引进行文件内范围或等值查询。具备最左匹配原则,一般只有1列。 建议将第一个非空的时间戳字段设置为Segment_key。 |
|
clustering_key和segment_key都需要满足传统数据库(例如MySQL)的最左前缀匹配原则,即按照Index书写的最左列排序进行索引。如果最左列为有序的场景,则按照左边第二列进行排序。示例如下。
call set_table_property('tmp', 'clustering_key', 'a,b,c');
select * from tmp where a > 1 ; --可以使用Cluster索引。
select * from tmp where a > 1 and c > 2 ; --只有a可以使用Cluster索引。
select * from tmp where a > 1 and b > 2 ; --a,b均可以使用Cluster索引。
select * from tmp where a > 1 and b > 2 and c > 3 ; --a,b,c均可以使用Cluster索引。
select * from tmp where b > 1 and c > 2 ; --b,c均不能使用Cluster索引。Bitmap Index支持多个列的and或or查询,示例如下。
call set_table_property('tmp', 'bitmap_columns', 'a,b,c');
select * from tmp where a = 1 and b = 2 ; -- 可以使用Bitmap索引。
select * from tmp where a = 1 or b = 2 ; -- 可以使用Bitmap索引。bitmap_columns可以在创建表后添加,clustering_key和segment_key则在创建表时已经指定,后续无法再添加。
查看是否使用Index
创建tmp表并指定索引字段,语句如下。
begin;
create table tmp(a int not null, b int not null, c int not null);
call set_table_property('tmp', 'clustering_key', 'a');
call set_table_property('tmp', 'segment_key', 'b');
call set_table_property('tmp', 'bitmap_columns', 'a,b,c');
commit;查看是否使用Cluster Index,语句如下。
explain select * from tmp where a > 1;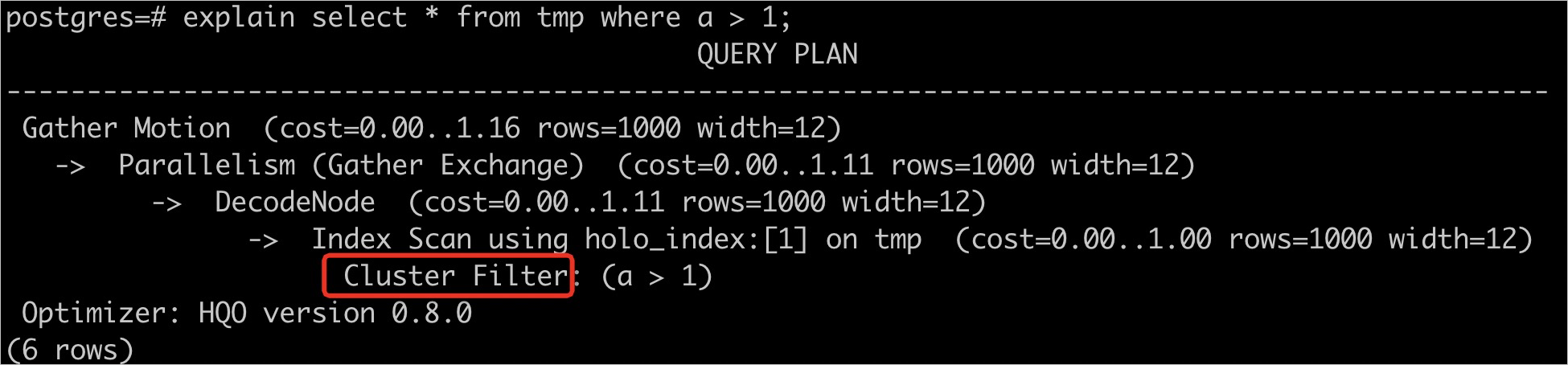
查看是否使用Bitmap Index,语句如下。
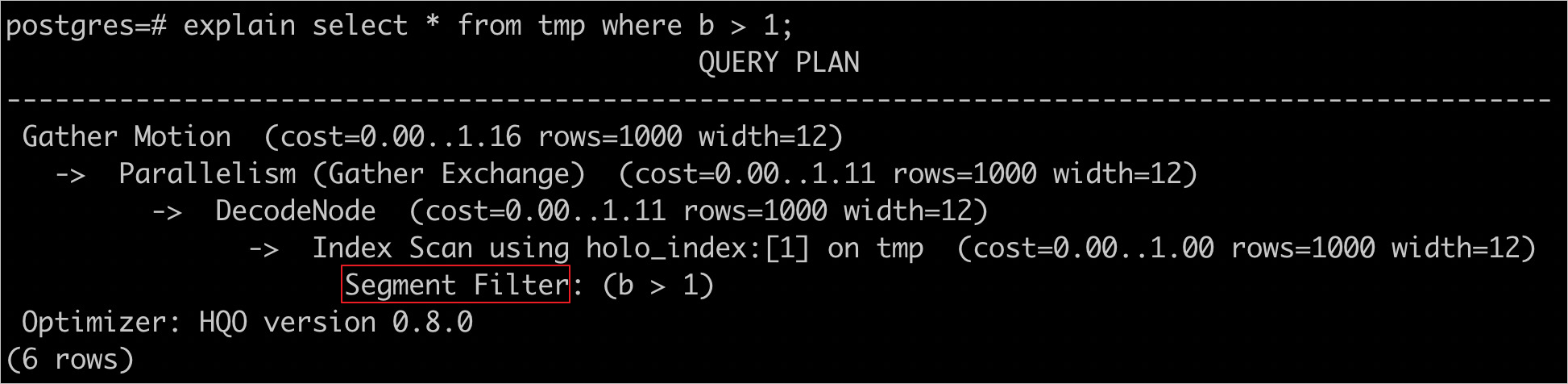
explain select * from tmp where c = 1;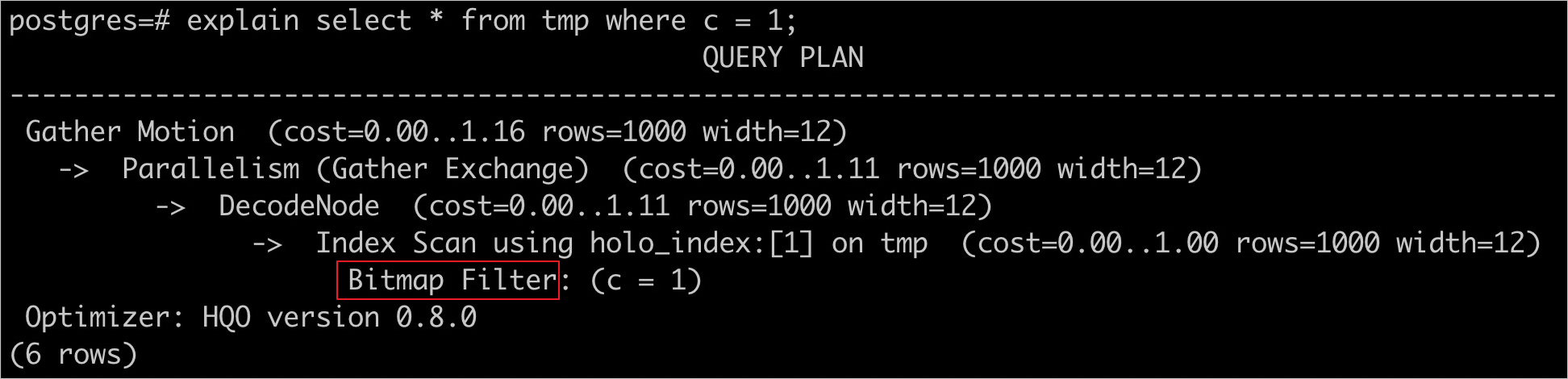
查看是否使用Segment Key,语句如下。
explain select * from tmp where b > 1;