
本文为您介绍在Hologres中数仓分层的最佳实践,方便快速构建业务,建设集高性能、敏捷化于一体的实时数仓。
背景信息
Hologres与Flink、MaxCompute、DataWorks深度兼容,能够提供实时离线一体化联合解决方案。在该方案下有着非常丰富的应用场景,例如实时大屏、实时风控、精细化运营等。不同的应用场景对处理的数据量、数据复杂度、数据来源、数据实时性等会有不一样的要求。传统数仓的开发按照经典的方法论,采用ODS(Operational Data Store) > DWD(Data Warehouse Detail) > DWS(Data WareHouse Summary) > ADS(Application Data Service)逐层开发的方法,层与层之间采用事件驱动,或者微批次的方式调度。分层带来更好的语义层抽象和数据复用,但也增加了调度的依赖、降低了数据的时效性、减少了数据灵活分析的敏捷性。
实时数仓驱动了业务决策的实时化,在决策时通常需要丰富的上下文信息,因此传统高度依据业务定制ADS的开发方法受到了较大挑战,成千上万的ADS表维护困难,利用率低,更多的业务方希望通过DWS甚至DWD进行多角度数据对比分析,这对查询引擎的计算效率、调度效率、IO效率都提出了更高的要求。
随着计算算子向量化重写、精细化索引、异步化执行、多级缓存等多种查询引擎优化技术的应用,Hologres的计算能力在每个版本都有较大改善。因此越来越多的用户采用了敏捷化的开发方式,在计算前置的阶段,只做数据质量清理、基本的大表关联拉宽,建模到DWD、DWS即可,减少建模层次。同时将灵活查询在交互式查询引擎中执行,通过秒级的交互式分析体验,支撑了数据分析民主化的重要趋势。
为了满足业务场景的不同需求,建议您通过如下图所示三种方式进行数据分层和处理,以实现更加敏捷的开发需求。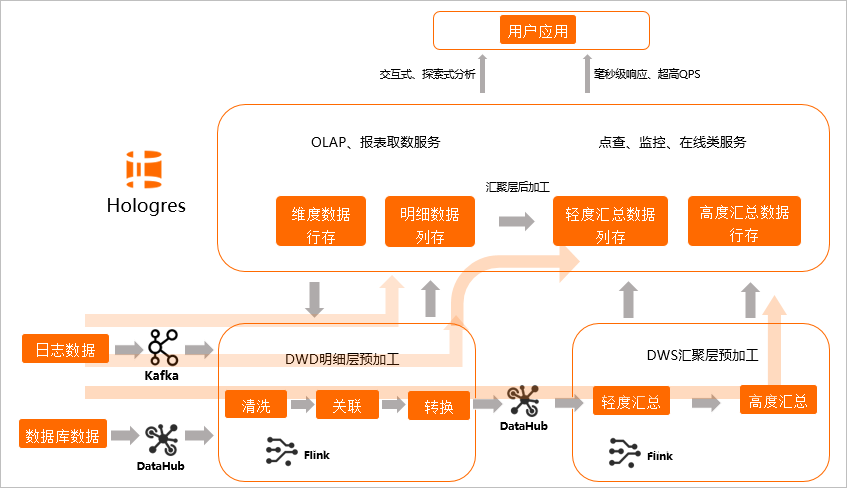
场景一(即席查询,写入即服务):在Flink中进行DWD数据明细层预加工,加工完的数据直接写入Hologres,由Hologres提供OLAP查询和在线服务。
场景二(分钟级准实时,微批次加工):在Flink中进行DWD数据明细层预加工,写入Hologres后,在Hologres中进行汇聚层加工,再对接上层应用。
场景三(增量数据实时统计,事件驱动加工):DWD明细层预加工和DWS汇聚层预加工全部由Flink完成,写入Hologres提供上层应用。
场景选择原则
当数据写入Hologres之后,Hologres里定义了三种实现实时数仓的方式:
实时要求非常高,要求写入即可查,更新即反馈,有即席查询需求,且资源较为充足,查询复杂度较低,适合实时数仓场景一:即席查询。
有实时需求,以分析为主,实时性满足分析时数据在业务场景具备实时含义,不追求数据产生到分析的秒级绝对值,但开发效率优先,推荐分钟级准实时方案,这个方案适合80%以上的实时数仓场景,平衡了时效性与开发效率,适合实时数仓场景二:分钟级准实时。
实时需求简单、数据更新少、只需要增量数据即可统计结果,以大屏和风控等在线服务场景为主,需要数据产生到分析尽量实时,可以接受一定开发效率的降低和计算成本的上升,适合实时数仓场景三:增量数据实时统计。
实时数仓场景一:即席查询
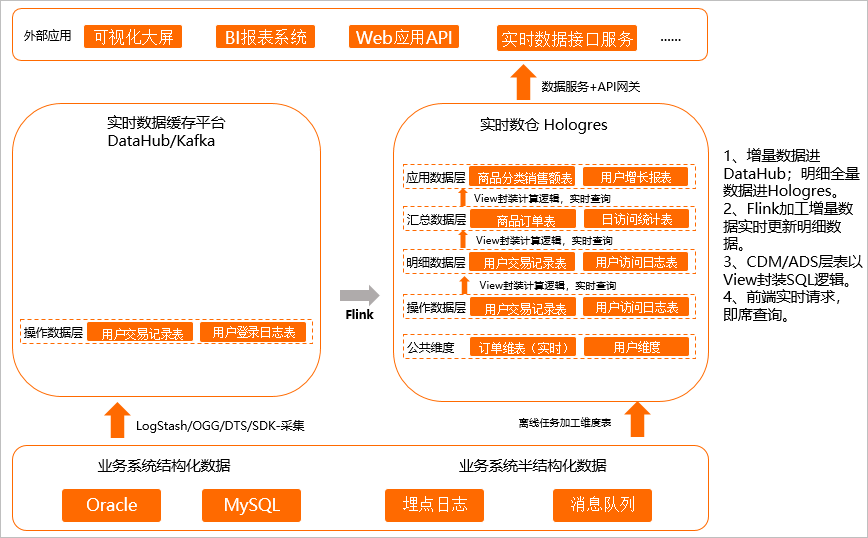
即席查询通俗来说就是不确定应用的具体查询模式,先把数据存下来,后续支撑尽量多灵活性的场景,如下图所示。
 因此建议您应用如下策略:
因此建议您应用如下策略:
将操作层(ODS层)的数据经过简单的清理、关联,然后存储到明细数据,暂不做过多的二次加工汇总,明细数据直接写入Hologres。
Flink加工增量数据,实时更新明细数据至Hologres,MaxCompute加工后的离线表写入Hologres。
因为上层的分析SQL无法固化,在CDM/ADS层以视图(View)封装成SQL逻辑。
上层应用直接查询封装好的View,实现即席查询。
方案优势:
灵活性强,可随时根据业务逻辑调整View。
指标修正简单,上层都是View逻辑封装,只需要刷新一层数据,更新底表的数据即可,因为上层没有汇聚表,无需再次更新上层应用表。
方案缺点:当View的逻辑较为复杂,数据量较多时,查询性能较低。
适用场景:数据来源于数据库和埋点系统,适合对QPS要求不高,对灵活性要求比较高,且计算资源较为充足的场景。
实时数仓场景二:分钟级准实时
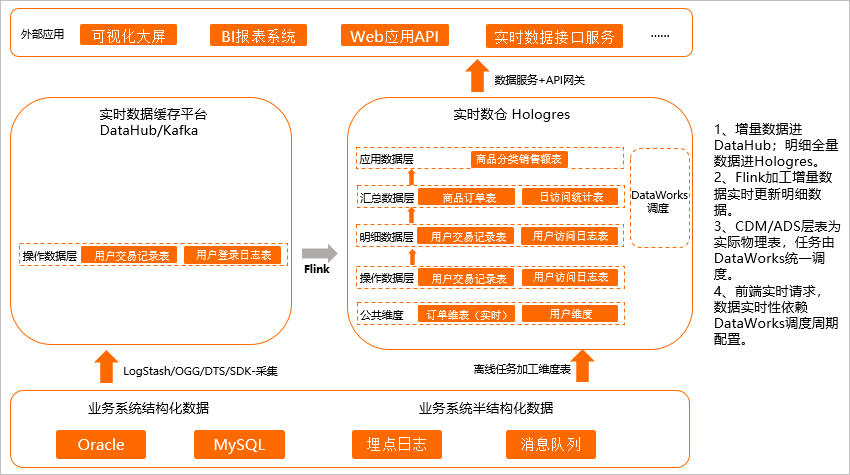
场景一的计算效率在某些场景上还存在不足,无法支撑更高的QPS,场景二是场景一的升级,把场景一中视图的部分物化成表,逻辑与场景一相同,但是最终落在表上的数据量变少,显著提升查询性能,可以获得更高的QPS,如下图所示。
 建议您应用如下策略:
建议您应用如下策略:
将操作层(ODS层)的数据经过简单的清理、关联,然后存储到明细数据,暂不做过多的二次加工汇总,明细数据直接写入Hologres。
Flink加工增量数据实时更新明细数据至Hologres。
CDM/ADS层为实际的物理表,通过DataWorks等调度工具调度周期性写入数据。
前端实时请求实际的物理表,数据的实时性依赖DataWorks调度周期配置,例如5分钟调度、10分钟调度等,实现分钟级准实时。
方案优势:
查询性能强,上层应用只查最后汇总的数据,相比View,查询的数据量更好,性能会更强。
数据重刷快,当某一个环节或者数据有错误时,重新运行DataWorks调度任务即可。因为所有的逻辑都是固化好的,无需复杂的订正链路操作。
业务逻辑调整快,当需要新增或者调整各层业务,可以基于SQL所见即所得开发对应的业务场景,业务上线周期缩短。
方案缺点:时效性低于方案一,因为引入了更多的加工和调度。
适用场景:数据来源于数据库和埋点系统,对QPS和实时性均有要求,适合80%实时数仓场景使用,能满足大部分业务场景需求。
实时数仓场景三:增量数据实时统计
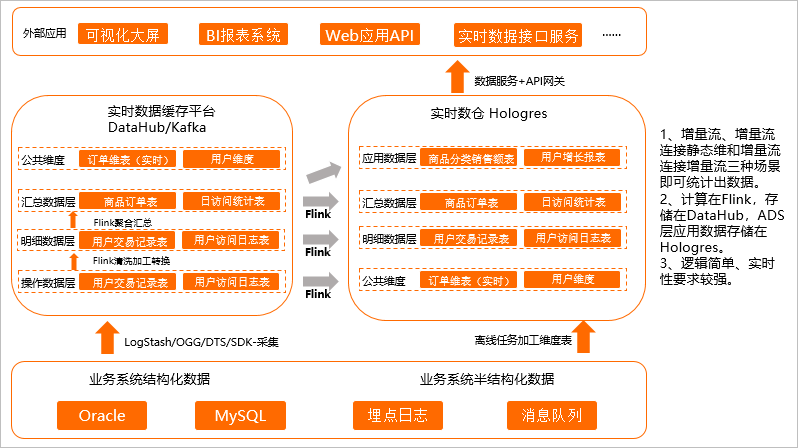
增量计算的场景是因为一些场景对数据延迟非常敏感,数据产生的时候必须完成加工,此时通过增量计算的方式,提前用Flink将明细层、汇总层等层数据进行汇聚,汇聚之后把结果集存下来再对外提供服务,如下图所示。
 在增量计算中,建议您应用如下策略:
在增量计算中,建议您应用如下策略:
增量计算的数据由Flink进行清洗加工转换和聚合汇总,ADS层应用数据存储在Hologres中。
Flink加工的结果集采取双写的方式,一方面继续投递给下一层消息流Topic,一方面Sink到同层的Hologres中,方便后续历史数据的状态检查与刷新。
在Flink内通过增量流、增量流连接静态维表、增量流连接增量流这三种场景统计出数据,写入Hologres。
Hologres通过表的形式直接对接上层应用,实现应用实时查询。
方案优势:
实时性强,能满足业务对实时性敏感的场景。
指标修正简单,与传统增量计算方式不一样的是,该方案将中间的状态也持久存储在Hologres中,提升了后续分析的灵活性,当中间数据质量有问题时,直接对表修正,重刷数据即可。
方案缺点:大部分实时增量计算都依赖Flink,对使用者Flink的技能和熟练度要求会更高一些;不适合数据频繁更新,无法累加计算的场景,不适合多流Join等计算复杂资源开销大场景。
适用场景:实时需求简单,数据量不大,以埋点数据统计为主的数据,只需要增量数据即可统计结果的场景,实时性最强。