Hologres自V3.1版本起,支持针对查询队列配置自动限流,基于计算组的负载情况,自动调整查询队列最大并发数的限制,最终实现自动限流(自动流控)。
适用场景
自动限流的原理是根据负载情况,动态调整查询队列的最大并发数,通过控制计算组中并发执行的Query数量,达到避免计算资源负载过高的目的。因此该功能的适用场景如下:
-
高并发场景:如果并发数较高,且每个请求的开销比较均匀,则自动限流功能会动态调整并发数限制,最终CPU曲线将稳定维持在高水位,且不会达到100%的占用率。
说明-
如果并发数过低,则动态调整并发数限制时,CPU曲线容易忽高忽低,出现“锯齿状”,导致CPU使用率低下。
-
在更为极端的情况下,如果仅存在单个请求的大查询,则自动限流功能不会生效。
-
-
可容忍请求适当延时:由于该功能为流量限制,超过限制的Query会在查询队列中排队,因此这部分请求的延时会相应增加。
-
高并发的时间难以预知:无法确定流量请求突发的时间,难以提前预留计算资源应对该部分请求,可以通过自动限流功能降低系统稳定性风险。
如下场景建议使用其他方案:
-
时间周期性特征明显:如果每天的流量高峰时间相对固定,推荐使用计算组分时弹性功能,定时扩缩容。
-
低并发的大查询:自动限流功能对低并发的大查询作用较小,建议使用Serverless Computing资源执行该部分请求,详情请参见Serverless Computing使用指南。
-
无法容忍请求延时:需要增加计算资源量,以兼顾高并发与低延时的需求。可以扩容计算资源,或使用查询队列的大查询控制功能,将执行慢的请求转发至Serverless中执行,详情请参见大查询控制。
前提条件
已创建查询队列。
注意事项
-
仅Hologres V3.1或以上版本的计算组型实例支持自动限流,通用型实例不支持。
说明您可先将通用型实例转为计算组型,再使用该功能,详情请参见通用型实例转换为计算组型实例。
-
仅进入查询队列的请求会受自动限流控制,即engine_type为
HQE、PQE、SQE和HiveQE查询,Query类型包括SELECT、INSERT、UPDATE、DELETE以及COPY、CTAS等命令产生的INSERT语句。 -
由于Fixed Plan的Query不进入查询队列,因此不受自动限流功能的并发数限制,详情请参见Fixed Plan加速SQL执行。建议使用不同的计算组,将Fixed Plan的请求和其他请求隔离,以便更好地管理资源和请求,具体请参见计算组实例快速入门。
使用自动限流
计算组、查询队列的自动限流功能配置方法如下。
语法格式
-
配置计算组的自动限流功能。
重要-
该功能开启后,计算组下的所有查询队列均默认开启自动限流,可根据下文步骤按需关闭查询队列的自动限流功能。
-
该功能关闭后(默认关闭),自动限流功能即关闭,系统将忽略查询队列级别自动限流配置开关。
-- 计算组级别打开自动限流 CALL hg_set_warehouse_adaptive_concurrency_limiting ('<warehouse_name>', true); -- 计算组级别关闭自动限流 CALL hg_set_warehouse_adaptive_concurrency_limiting ('<warehouse_name>', false); -
-
配置查询队列的自动限流功能。
-- 查询队列级别打开自动限流。默认即开启 CALL hg_set_query_queue_property ('<warehouse_name>', '<query_queue_name>', 'enable_adaptive_concurrency_limiting', 'true'); -- 关闭查询队列的自动限流,等价于将该队列加入白名单,不参与限流 CALL hg_set_query_queue_property ('<warehouse_name>', '<query_queue_name>', 'enable_adaptive_concurrency_limiting', 'false'); -
配置查询队列的自动限流功能的最小并发数。
说明在配置最小并发数后,即使系统达到该并发数限制且负载仍然较高,系统也不会自动进一步减少并发数限制。
-- 配置查询队列的自动限流功能的最小并发数,默认为1,最小为1 CALL hg_set_query_queue_property ('<warehouse_name>', '<query_queue_name>', 'adaptive_concurrency_limiting_min_concurrency', '<min_concurrency>');
参数说明
|
参数名 |
描述 |
|
warehouse_name |
计算组名称。详情请参见计算组实例快速入门。 |
|
query_queue_name |
查询队列名称。详情请参见查询队列Query Queue。 |
|
min_concurrency |
查询队列自动限流功能的最小并发数。默认值为1,取值范围为[1, 创建查询队列时设置的最大并发数]。 |
监控与运维
您可单击Hologres管理控制台的目标实例ID,在监控信息页面查看计算组CPU使用率(%)监控指标,监测自动限流功能的使用情况。
使用示例
本节以PG原生性能压测工具pgbench为例,为您展示自动限流的使用示例和效果。
-
在Hologres中创建测试表并写入数据:
CREATE TABLE tbl_1 (col1 INT, col2 INT, col3 TEXT); CREATE TABLE tbl_2 (col1 INT, col2 INT, col3 TEXT); INSERT INTO tbl_1 SELECT i, i+1, md5(RANDOM()::TEXT) FROM GENERATE_SERIES (0, 500000) AS i; INSERT INTO tbl_2 SELECT i, i+1, md5(RANDOM()::TEXT) FROM GENERATE_SERIES (0, 500000) AS i; -
在Hologres中将查询队列的最大并发数设为100,以计算组init_warehouse和查询队列default_queue为例:
CALL hg_set_query_queue_property ('init_warehouse', 'default_queue', 'max_concurrency', '100'); -
在客户端pgbench所在的
bin目录下创建压测SQL文件select.sql,并写入如下SQL:EXPLAIN ANALYZE SELECT * FROM tbl_1 LEFT JOIN tbl_2 ON tbl_1.col3 = tbl_2.col3 ORDER BY 1; -
在服务器的配置文件中添加以下命令并保存,将密码设置为环境变量。
export PGPASSWORD='<AccessKey_Secret>' -
进入客户端中pgbench所在的
bin目录,执行如下压测命令:./pgbench -c 30 \ -j 30 \ -f select.sql \ -d <Database> \ -U <AccessKey_ID> \ -h <Endpoint> \ -p <Port> \ -T 1800参数配置详情请参见连接Hologres并开发。
-
压测期间,在Hologres中依次开启自动限流功能、关闭自动限流功能,并观察计算组的CPU使用率监控指标,直至压测完成。
-- 开启自动限流功能 CALL hg_set_warehouse_adaptive_concurrency_limiting ('init_warehouse', true); -- 关闭自动限流功能 CALL hg_set_warehouse_adaptive_concurrency_limiting ('init_warehouse', false);
结果分析:
压测完成后,计算组的CPU使用率监控指标有如下表现:
-
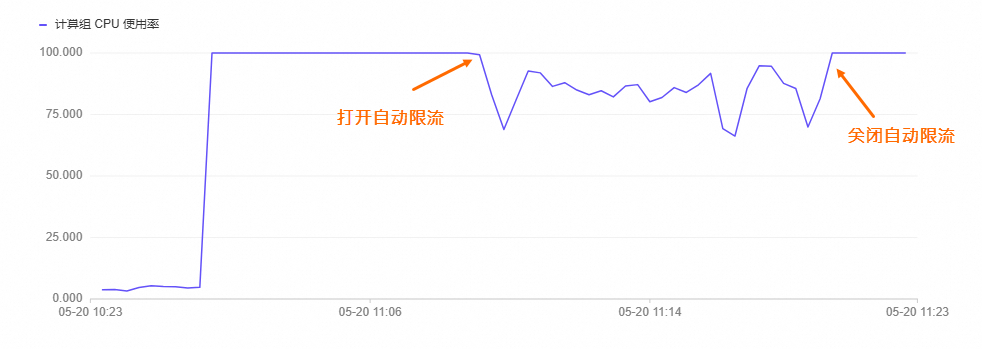
压测初期:自动限流未开启,查询队列排队数为0,计算组CPU使用率长期处于100%,系统存在稳定性风险。
-
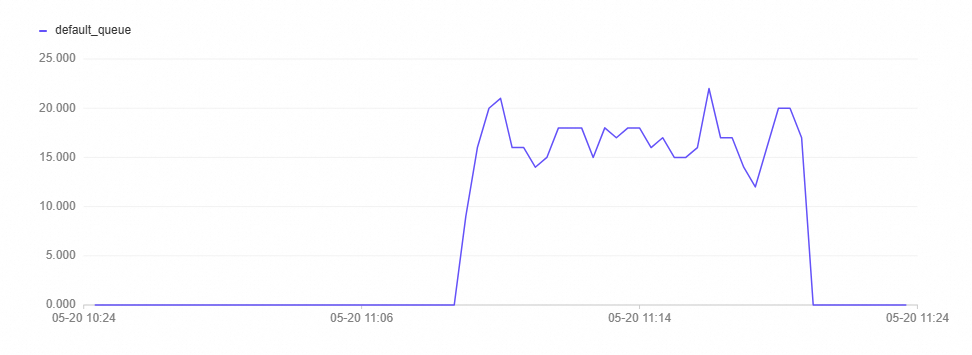
压测中期:自动限流开启,查询队列排队数和计算组CPU使用率小幅度波动,而后查询队列排队数稳定在17个左右,计算组CPU使用率稳定在80%附近,系统稳定性风险显著降低。
-
压测后期:关闭自动限流,表现与压测初期一致。
监控指标趋势图:
-
计算组CPU使用率
-
查询队列中排队状态的Query数量