
为了能够快速恢复系统故障,Hologres提供了单实例快速恢复的机制。本文为您介绍单实例快速恢复的触发条件和行为。
实例快速恢复逻辑说明
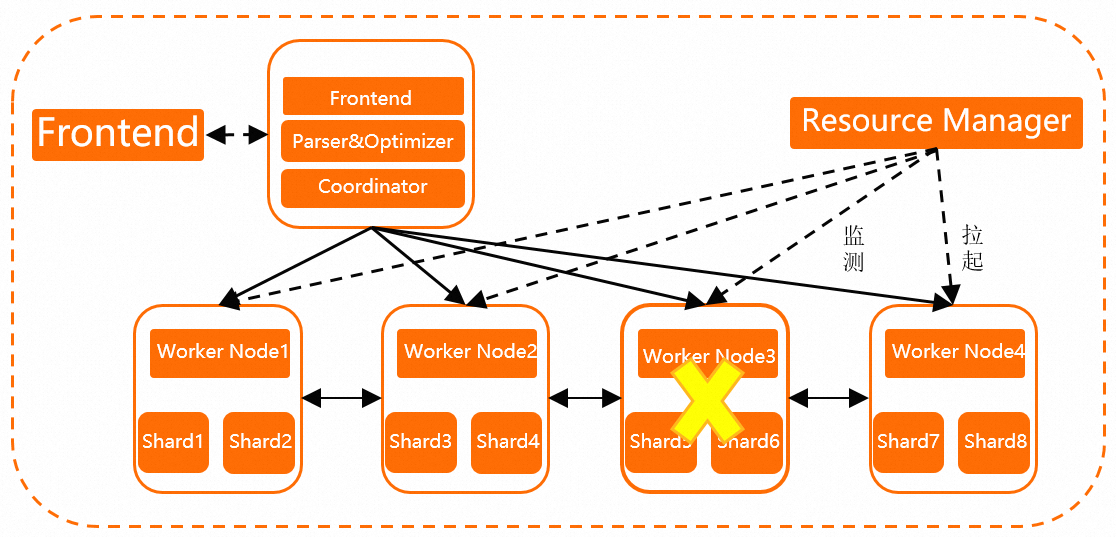
Hologres在 V2.0版本之前,Hologres计算节点均为容器调度(即下图中的Worker Node),资源管理器(Resource Manager)负责周期性健康检查。当出现1分钟容器响应超时(可能是内存溢出、硬件故障、软件Bug等原因导致),Resource Manager会自动拉起新的计算节点,并迁移数据分片(Shard)职责到新的节点上(例如Worker Node3响应超时,Resource Manager拉起Worker Node4取代Worker Node3),实现系统状态的快速恢复。数据状态保存在盘古分布式存储系统中,无需从计算节点迁移,计算节点轻量无状态,系统可以快速从故障中恢复。该方案为当前每个实例内部默认启用,当系统发生故障时,无需手工运维介入,系统可以自动恢复。在恢复期间,如果查询算子需要访问恢复中的节点,则查询会立即失败。节点恢复速度在一分钟左右,当表数量明显增加时,恢复时间会更长。
Hologres从 V2.0版本开始增加快速恢复机制,针对大规格实例,可以利用Worker的碎片资源,加快恢复速度,减小对于线上业务的影响。当实例Worker数达到一定规模时,可以在一定数量Worker故障时,使用其他正常的Worker快速加载故障Worker原始分配Shard的元数据。
实例规模和允许故障的Worker数量如下表所示:
计算资源数量
实例节点数量
允许故障的Worker数量
160CU <= 实例计算资源 < 320CU
10 <= 实例节点数量 < 20
1
320CU < 实例计算资源
20 <= 实例节点数量
2
由于临时使用了其他正常的Worker快速加载故障Worker原始分配Shard的元数据,所以可以达到快速恢复的目的。
场景样例说明
默认情况下,实例的Worker节点会均匀的加载Shard的元数据。例如下图所示,实例包含10个Worker,存在10个Shard,那么每个Worker都会加载1个Shard。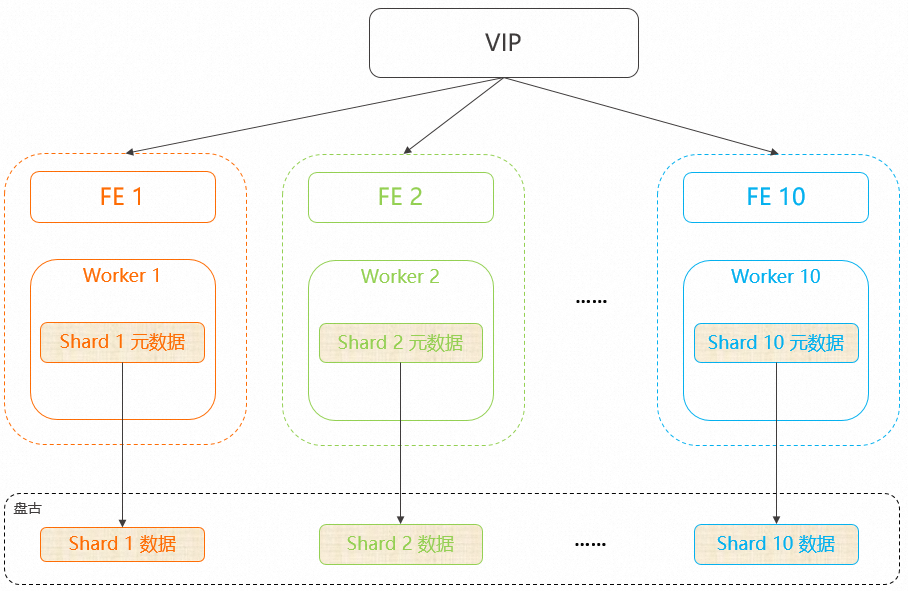
此时若Worker 2 发生故障,实例会检测到故障后10秒内使用其他的Worker(Worker 1)加载Shard 2的元数据,以起到快速恢复的作用。
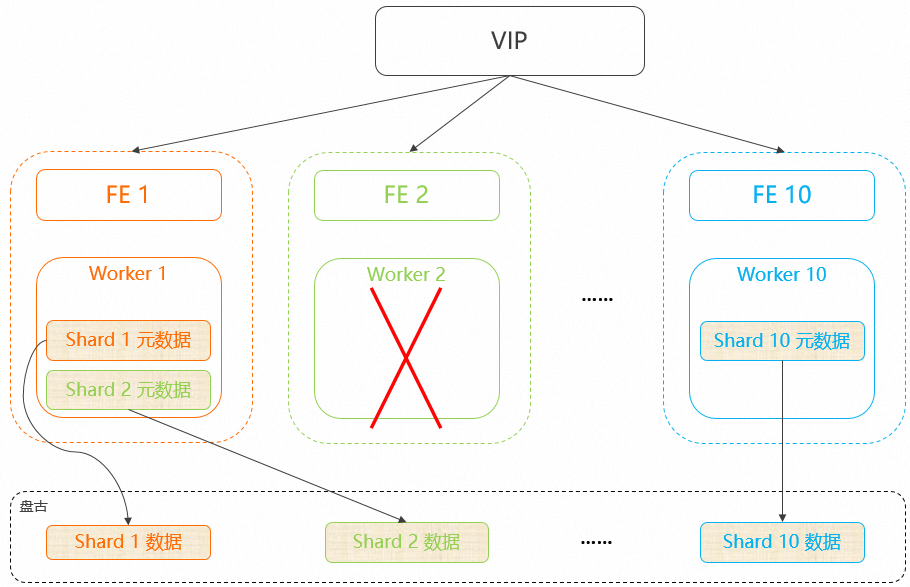
当节点重启被拉起后,系统不会自动将Shard的元数据加载到重新拉起的节点上,即Shard 2元数据还是会加载在Worker 1中。如果发现触发快速恢复后负载不均衡,可以执行Rebalance命令,使实例最终达到负载均衡的状态,Rebalance命令详情请参见均衡分片(Rebalance)。