
通义灵码企业版的管理员、组织内全局管理员(专属版)可以为企业的开发者配置智能问答、行间生成、知识库上传时的安全过滤策略。
该功能目前仅支持 Visual Studio Code 和 JetBrains IDE 插件,不适用于 Lingma IDE。
适用版本 | 企业标准版、企业专属版 |
功能入口
使用通义灵码管理员、组织内全局管理员(仅适用于企业专属版)账号登录通义灵码控制台,在左侧导航栏选择。
根据过滤器应用的场景,在顶部标签页选择智能问答、行间生成或知识库上传(仅适用于企业专属版)。
根据需求开启相应过滤器的开关,然后配置相关参数。各场景支持的过滤器类型如下:
场景
过滤器类型
说明
智能问答
智能问答前置过滤器
使用通义灵码的智能问答功能时,用户输入给大模型的内容将通过前置过滤器,大模型输出的内容将通过后置过滤器。
智能问答后置过滤器
行间生成
行间生成前置过滤器
使用通义灵码的行间生成功能时,用户输入给大模型的内容将通过前置过滤器,大模型输出的内容将通过后置过滤器。
行间生成后置过滤器
知识库上传
知识库上传前置过滤器
上传至通义灵码知识库的文件须先通过该过滤器的审核后,方可上传成功。
重要请确保将开发者的通义灵码升级到 V1.4.0 及以上,配置的过滤器方可生效。
智能问答过滤器、行间生成过滤器启用或修改后,预计需要 5~10 分钟才对开发者使用的通义灵码生效。
知识库上传过滤器启用或修改后,立即生效,上传企业知识库文件时会进行过滤。
智能问答、行间生成的前置过滤器配置
方式一:正则表达式配置
管理员在配置正则表达式时需要充分验证,以避免开发者使用IDE 插件时性能下降或产生其他异常问题。
处理方式:支持通过正则表达式的方式配置过滤器,且支持 3 种模式。
匹配规则时不处理
匹配到正则后,不做任何处理。
匹配规则时拦截
匹配到正则后,直接拦截请求,阻断模型请求。
匹配规则时替换内容
匹配到正则后,按照配置替换内容。
消息通知:支持开启消息通知,通过 webhook 的方式,推送到所需要的消息接收平台。
执行顺序:按照配置的排序执行。
正则数量限制:最多可添加10条。
正则表达式标准:正则配置遵循 ECMAScript 标准,支持
i(不区分大小写)、g(全局匹配)、s(DOTALL 模式)等常用标志位。正则配置示例:
规则名称
正则表达式
替换内容
原文
替换后
身份证号
(?<pre>.*)(\d{15})((\d{2})([0-9Xx]))(?<post>.*)
$<pre>***$<post>
身份证号:330204197709022312。
身份证号:***。
邮箱
\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
***
我的邮箱是 lin***@aliyunmail.com
我的邮箱是 ***
密码
(.*password=)([\w\d]+)(.*)
$1***$3
{password=1213213}
{password=***}
方式二:自定义脚本配置(仅适用于企业专属版)
企业专属版中支持通过自定义脚本的方式进行过滤器配置,以实现对复杂场景下的前置过滤的需求。步骤如下:
步骤一:脚本开发
目前支持使用 TypeScript 语言进行脚本开发,可以参考样例进行代码开发,操作步骤如下:
下载模板代码库:单击仓库地址:lingma-extension-template,该模板仓库集成了开发脚本所需的脚手架,请仔细阅读
README.md文件和代码示例。实现“前置处理”接口:实现接口
RequestPreHandler,API 可参考自定义脚本 API,以下为一个示例片段SensitiveContentFilter.ts的实现。/** * 敏感内容过滤器,通过该过滤器可以实现对发送给模型的数据进行敏感信息预处理 */ export const sensitiveContentFilter: RequestPreHandler = { handle: async (request: RawRequest, SDKTool: LingmaSDKTool) => { const dataMap = PayloadUtil.getPayloadData(request.payload); for (const [key, value] of dataMap.entries()) { if (value.includes('password')) { return ResultUtil.buildBlockResult('内容包含password'); } } // 如果需要针对不同的 action 做差异化处理,则参考如下实现 switch (request.action) { case ActionEnum.COMPLETION: // do something break; case ActionEnum.CODE_PROBLEM_SOLVE: // do something break; default: return ResultUtil.buildNoOpsResult(); } return ResultUtil.buildNoOpsResult(); }, };运行调试代码,通过运行
main方法来测试脚本是否符合预期,操作步骤如下:步骤一
编辑
src/index.ts文件,修改main函数,调整实际需要调试代码,如下示例:async function main() { const value1 = ['password=123', 'abc']; const value2 = 'hello world'; const dataMap = new Map<PayloadDataKeyEnum, PayloadDataValueType>(); dataMap.set(PayloadDataKeyEnum.SELECTED_CODE, value1); dataMap.set(PayloadDataKeyEnum.USER_INPUT, value2); const mockRequest: RawRequest = { action: ActionEnum.CODE_GENERATE_COMMENT, payload: { associatedContexts: [], data: dataMap, }, requestId: '123', }; const response = await sensitiveContentFilter.handle(mockRequest, SDKTool); console.log(response); }步骤二
在 VS Code 中打开想要调试的代码文件并设置断点,然后从调试视图中选择“启动程序”并单击运行按钮即可。

步骤二:编译构建
将运行调试完成的 ts 文件编译为 js 文件,如将SensitiveContentFilter.ts文件编译为SensitiveContentFilter.js文件,编译构建步骤如下:
打开配置文件
src/build.js,修改entryPoints和outfile两个配置参数,并在entryPoints参数中指定需要编译构建的 ts 文件路径,在outfile中指定构建后的产物输出路径。在代码库根目录下执行命令
node build.js,执行成功后对应的 js 文件将输出到outfile指定的产物输出路径。
步骤三:本地测试
在脚本上传企业配置后台之前,可在本地完成调试,以确保脚本能够与通义灵码的 IDE 插件集成,并对补全或问答场景的行为进行正确的安全过滤处理。具体调试步骤如下:
将构建好的 js 文件拷贝到通义灵码本地存储路径的
/extension/local/script/目录下。修改
config.json文件:该文件所在目录为通义灵码本地存储路径的/extension/local/,打开config.json文件,并找到contentHandlerScripts,在对应的内容里增加该脚本的配置信息,如果没有contentHandlerScripts,可以新增一个数组类型的配置,参考示例如下:{ "contentHandlerScripts": [ { "identifier": "SensitiveContentFilter", "name": "敏感内容过滤", "version": "1.0.0", "scriptPath": "~/.lingma/extension/local/script/SensitiveContentFilter.js", "state": "enabled", "bizType": "completion" } ] }配置参数说明:
参数
说明
identifier
脚本 ID,需确保唯一性。
name
脚本名称。
version
脚本的版本号,如果修改了脚本内容,需要升级版本号,否则脚本无法生效。
scriptPath
脚本存放的路径,请注意:
脚本一定要存放在本地存储路径的
/extension/local/script/目录下。脚本的 js 文件名称(如:
SensitiveContentFilter.js)一定要与identifier的值保持一致。
state
脚本状态,
enabled表示启用、disabled表示禁用。bizType
脚本应用的业务场景,
completion表示行间代码生成补全、chat表示智能问答。
步骤四:脚本上传
经过本地调试并通过验证后,可进行脚本上传,操作步骤如下:
前往通义灵码控制台-策略管理,选择需要开通安全过滤器的场景。
选择过滤器选项为:自定义脚本。
将构建后的 js文件上传。
上传后单击保存配置,约5分钟内会下发到插件端生效。
自定义脚本 API
目前自定义脚本支持三种处理方式,如下:
阻断处理:即阻断后续流程,一旦阻断,则不会请求大模型进行推理,中断本次请求。
过滤处理:对发送处理的数据进行了修改(如:混淆、删除、替换等),然后继续后续流程。
无处理:对发送的数据没有做任何处理,原样返回,然后继续后续流程。
接口定义
/**
* 灵码编程助手前置处理接口
*/
export interface RequestPreHandler {
// 处理请求
handle: (request: RawRequest, SDKTool: LingmaSDKTool) => Promise<HandlerResponse>;
}入参定义
/**
* 请求对象定义,请求包括触发的行为和待发送给 LLM 的原始数据
*/
export interface RawRequest {
// 当前请求唯一标识,可用于追踪请求执行
action: ActionEnum;
// 触发请求的行为枚举
payload: ContentPayload;
// 封装原始数据内容的payload
requestId: string;
}
// ContentPayload.data 中 value 类型
export type PayloadDataValueType = string | number | string[];
/**
* 封装发送给 LLM 的原始数据内容
*/
export class ContentPayload {
// 待处理的数据集合,对应的 key 参考 ContextValueKeyEnum 定义
data: Map<PayloadDataKeyEnum, PayloadDataValueType>;
// 与处理关联的上下文
associatedContexts: ContextItem[];
constructor() {
this.data = new Map<PayloadDataKeyEnum, PayloadDataValueType>();
this.associatedContexts = [];
}
}
/**
* ContentPayload.data 中 key 枚举
*/
export enum PayloadDataKeyEnum {
// 用户圈选的代码片段
SELECTED_CODE ='lingma:code',
// 用户输入的文本
USER_INPUT = 'lingma:text',
// 报错信息
ERROR_MESSAGES = 'lingma:error_messages',
// 终端打印的日志信息
TERMINAL_CONTENT = 'lingma:terminal_content',
// 代码补全时,当前光标所在行的前文代码片段
PREFIX_CODE = 'lingma:code_prefix',
// 代码补全时,当前光标所在行的后文代码片段
SUFFIX_CODE = 'lingma:code_suffix',
// 相似代码片段
SIMILAR_CODE = 'lingma:similar_code',
}
/**
* 触发请求的行为枚举
*/
export enum ActionEnum {
// 单元测试
GENERATE_TESTCASE = 'GENERATE_TESTCASE',
// 生成注释
CODE_GENERATE_COMMENT = 'CODE_GENERATE_COMMENT',
// 代码解释
EXPLAIN_CODE = 'EXPLAIN_CODE',
// 代码优化
OPTIMIZE_CODE = 'OPTIMIZE_CODE',
// 自由问答(即在问答输入框中直接输入文本的行为)
FREE_INPUT = 'FREE_INPUT',
// 代码问题快捷修复
CODE_PROBLEM_SOLVE = 'CODE_PROBLEM_SOLVE',
// shell命令生成
TERMINAL_COMMAND_GENERATION = 'TERMINAL_COMMAND_GENERATION',
// 终端报错修复
TERMINAL_EXPLAIN_FIX = 'TERMINAL_EXPLAIN_FIX',
// 代码补全
COMPLETION = 'COMPLETION',
}出参定义
/**
* 预处理结果
*/
export class HandlerResponse {
// 处理策略,通过该策略可以控制后续的处理逻辑
handlePolicy: HandlePolicy;
// 原因描述
reason?: string;
// 当handlePolicy=FILTER时,需要设置该属性,其值为经过过滤后的数据(必须与ContentRequest.payload的内容保持一致)
payload?: ContentPayload;
constructor() {
// 默认值
// eslint-disable-next-line @typescript-eslint/no-use-before-define
this.handlePolicy = HandlePolicy.NO_OPS;
this.reason = '';
this.payload = new ContentPayload();
}
}
/**
* 处理策略枚举
*/
export enum HandlePolicy {
// 阻断策略,直接阻断请求
BLOCK = 'BLOCK',
// 过滤策略,拦截请求并对payload内容进行修改
FILTER = 'FILTER',
// 忽略策略,不处理请求
NO_OPS = 'NO_OPS',
}智能问答、行间生成的后置过滤器配置
方式一:正则表达式配置
管理员在配置正则表达式时需要充分验证,以避免开发者使用IDE 插件时性能下降或产生其他异常问题。
处理方式:支持通过正则表达式的方式配置过滤器,仅支持一种模式,如下:
匹配规则时不处理
匹配到正则后,不做任何处理。
消息通知:支持开启消息通知,通过 webhook 的方式,推送到所需要的消息接收平台。
执行顺序:按照配置的排序执行。
正则数量限制:最多可添加10条。
正则表达式标准:正则配置遵循 ECMAScript 标准,支持
i(不区分大小写)、g(全局匹配)、s(DOTALL 模式)等常用标志位。正则配置示例:
规则名称
正则表达式
原文
身份证号
(?<pre>.*)(\d{15})((\d{2})([0-9Xx]))(?<post>.*)
身份证号:330204197709022312。
邮箱
\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
我的邮箱是 lin***@aliyunmail.com
密码
(.*password=)([\w\d]+)(.*)
{password=1213213}
方式二:自定义脚本配置(仅适用于企业专属版)
企业专属版中支持通过自定义脚本的方式进行过滤器配置,以实现对复杂场景下的后置过滤的需求。步骤如下:
步骤一:脚本开发
目前支持使用 TypeScript 语言进行脚本开发,可以参考样例进行代码开发,操作步骤如下:
下载模板代码库:单击仓库地址:lingma-extension-template,该模板仓库集成了开发脚本所需的脚手架,请仔细阅读
README.md文件和代码示例。实现“后置处理”接口:实现接口
RequestPostHandler,API 可参考自定义脚本 API,以下为一个示例片段LLMChatAuditHandler.ts的实现,实现的功能为对通义灵码的AIChat操作进行审计,将审计内容上报至阿里云SLS。import {ResultUtil} from '../common/HandlerRespUtil'; import { JsonUtil } from '../common/JsonUtil'; import {PayloadUtil} from '../common/PayloadUtil'; import {Config} from '../sdk/ConfigManager'; import {LingmaSDKTool} from '../sdk/LingmaSDKTool'; import axios from "axios"; import moment from "moment"; import os from "os"; import { ActionEnum, AIResponse, HandlePolicy, RawRequest, RequestPostHandler, RequestPreHandler } from '../sdk/RequestHandleSDK'; /** * 自定义脚本后置过滤器,通过该脚本可以完成将请求内容发送到远程服务器进行处理(如代码扫描、内容审计等) */ export const llmResultAuditHandler: RequestPostHandler = { handle: async (request: RawRequest, response: AIResponse,SDKTool: LingmaSDKTool) => { // 操作人名称 let userName = SDKTool.user.name; // 操作人id let userId = SDKTool.user.uid; // ide let ide = SDKTool.idePlatform; // ide let ideVersion = SDKTool.ideVersion; // 操作时间 let operationTime = moment().format("YYYY-MM-DD HH:mm:ss"); // 操作ip let opeartionIp = getIpAddress(); // 操作业务场景(补全 or 问答场景) let bizType = "chat"; // 操作的请求id let requestId = request.requestId; // 操作action let action = request.action; // 操作内容(此处建议参考自身审计需求选取合适字段,避免上报内容过大(超过16k)导致上报失败) let inferredResult = response.inferredResult.text; // 上报sls // sls的Project名称 let slsProject = "xxx"; // sls的LogStore名称 let slsLogStore = "xxx"; // sls实例所在地域的endPoint let endPoint = "cn-hangzhou.log.aliyuncs.com"; let slsWebTrackingUrl = `http://${slsProject}.${endPoint}/logstores/${slsLogStore}/track?APIVersion=0.6.0&request_id=${requestId}&action=${action}&biz_type=${bizType}&user_name=${userName}&user_id=${userId}&ide=${ide}&ide_version=${ideVersion}&operation_time=${operationTime}&opeartion_ip=${opeartionIp}&inferredResult=${inferredResult}`; axios.get(slsWebTrackingUrl).catch((error) => { console.error(error); }); // 返回过滤结果 return ResultUtil.buildPostHandlerResponse(HandlePolicy.NO_OPS, response.inferredResult,'无需处理'); }, }; /** * 将自定义脚本过滤器添加到配置中 * @param config LingmaExtensionSDK提供的统一管理配置的对象 */ export function modifyConfig(config: Config) { config.postContentHandlers.push(llmResultAuditHandler); return config; } function getIpAddress() { const interfaces = os.networkInterfaces(); for (let devName in interfaces) { let iface = interfaces[devName]; for (let i = 0; i < iface.length; i++) { let alias = iface[i]; if ( alias.family === "IPv4" && alias.address !== "127.0.0.1" && !alias.internal ) return alias.address; } } return "No IP address found"; }运行调试代码,通过运行
main方法来测试脚本是否符合预期,操作步骤如下:步骤一
编辑
src/index.ts文件,修改main函数,调整实际需要被调试的代码,如下示例:async function main() { const value2 = 'hello world'; const dataMap = new Map<PayloadDataKeyEnum, PayloadDataValueType>(); dataMap.set(PayloadDataKeyEnum.USER_INPUT, value2); const request: RawRequest = { action: ActionEnum.CODE_GENERATE_COMMENT, payload: { associatedContexts: [], data: dataMap, }, requestId: 'test-request-id', }; const aiResponse: AIResponse = { inferredResult: { text: 'reply hello world', }, }; const response = await llmResultAuditHandler.handle(request, aiResponse, SDKTool); console.log(response); }步骤二
在 VS Code 中打开想要调试的代码文件并设置断点,然后从调试视图中选择“启动程序”并单击运行按钮即可。
步骤二:编译构建
将运行调试完成的 ts 文件编译为 js 文件,如将LLMChatAuditHandler.ts文件编译为LLMChatAuditHandler.js文件,编译构建步骤如下:
打开配置文件
src/build.js,修改entryPoints和outfile两个配置参数,并在entryPoints参数中指定需要编译构建的 ts 文件路径,在outfile中指定构建后的产物输出路径。在代码库根目录下执行命令
node build.js,执行成功后对应的 js 文件将输出到outfile指定的产物输出路径。
步骤三:本地测试
在脚本上传企业配置后台之前,可在本地完成调试,以确保脚本能够与通义灵码的 IDE 插件集成,并对补全或问答场景的行为进行正确的安全过滤处理。具体调试步骤如下:
将构建好的 js 文件拷贝到通义灵码本地存储路径的
/extension/local/script/目录下。修改
config.json文件:该文件所在目录为通义灵码本地存储路径的/extension/local/,打开config.json文件,并找到contentHandlerScripts,在对应的内容里增加该脚本的配置信息,如果没有contentHandlerScripts,可以新增一个数组类型的配置,参考示例如下:{ "contentHandlerScripts": [ { "identifier": "LLMChatAuditHandler", "name": "AIChat审计", "version": "1.0.0", "scriptPath": "~/.lingma/extension/local/script/LLMChatAuditHandler.js", "state": "enabled", "stage":"post", "bizType": "completion" } ] }配置参数说明:
参数
说明
identifier
脚本 ID,需确保唯一性。
name
脚本名称。
version
脚本的版本号,如果修改了脚本内容,需要升级版本号,否则脚本无法生效。
scriptPath
脚本存放的路径,请注意:
脚本一定要存放在本地存储路径的
/extension/local/script/目录下。脚本的 js 文件名称(如:
LLMChatAuditHandler.js)一定要与identifier的值保持一致。
state
脚本状态,
enabled表示启用、disabled表示禁用。stage
脚本作用阶段,
post表示后置过滤、pre表示前置过滤,默认值为pre前置过滤。bizType
脚本应用的业务场景,
completion表示行间代码生成补全、chat表示智能问答。
步骤四:脚本上传
经过本地调试并通过验证后,可进行脚本上传,操作步骤如下:
前往通义灵码控制台-策略管理,选择需要开通安全过滤器的场景。
选择过滤器选项为:自定义脚本。
将构建后的 js文件上传。
上传后单击保存配置,约5分钟内会下发到插件端生效。
自定义脚本 API
目前自定义脚本仅支持一种处理方式,如下:
无处理:对发送的数据没有做任何处理,原样返回,然后继续后续流程。
接口定义
/**
* 灵码编程助手后置处理接口
* @param request 用户发送的请求
* @param response LLM返回的推理内容
* @param SDKTool SDK工具类,通过该工具类可以获取与IDE、Plugin相关的信息
* @returns 经过后置处理器处理后的返回结果
*/
export interface RequestPostHandler {
// 后置处理方法
handle: (request: RawRequest, response: AIResponse, SDKTool: LingmaSDKTool) => Promise<PostHandlerResponse>;
}入参定义
/**
* 请求对象定义,请求包括触发的行为和待发送给 LLM 的原始数据
*/
export interface RawRequest {
// 当前请求唯一标识,可用于追踪请求执行
action: ActionEnum;
// 触发请求的行为枚举
payload: ContentPayload;
// 封装原始数据内容的payload
requestId: string;
}
/**
* 模型推理生成的结果数据
*/
export class InferredResult {
//LLM生成的文本内容
text: string;
constructor() {
this.text = '';
}
}
// ContentPayload.data 中 value 类型
export type PayloadDataValueType = string | number | string[];
/**
* 封装发送给 LLM 的原始数据内容
*/
export class ContentPayload {
// 待处理的数据集合,对应的 key 参考 ContextValueKeyEnum 定义
data: Map<PayloadDataKeyEnum, PayloadDataValueType>;
// 与处理关联的上下文
associatedContexts: ContextItem[];
constructor() {
this.data = new Map<PayloadDataKeyEnum, PayloadDataValueType>();
this.associatedContexts = [];
}
}
/**
* ContentPayload.data 中 key 枚举
*/
export enum PayloadDataKeyEnum {
// 用户圈选的代码片段
SELECTED_CODE ='lingma:code',
// 用户输入的文本
USER_INPUT = 'lingma:text',
// 报错信息
ERROR_MESSAGES = 'lingma:error_messages',
// 终端打印的日志信息
TERMINAL_CONTENT = 'lingma:terminal_content',
// 代码补全时,当前光标所在行的前文代码片段
PREFIX_CODE = 'lingma:code_prefix',
// 代码补全时,当前光标所在行的后文代码片段
SUFFIX_CODE = 'lingma:code_suffix',
// 相似代码片段
SIMILAR_CODE = 'lingma:similar_code',
// 补全场景执行补全的文件路径
FILE_PATH = 'lingma:file_path',
}
/**
* 触发请求的行为枚举
*/
export enum ActionEnum {
// 单元测试
GENERATE_TESTCASE = 'GENERATE_TESTCASE',
// 生成注释
CODE_GENERATE_COMMENT = 'CODE_GENERATE_COMMENT',
// 代码解释
EXPLAIN_CODE = 'EXPLAIN_CODE',
// 代码优化
OPTIMIZE_CODE = 'OPTIMIZE_CODE',
// 自由问答(即在问答输入框中直接输入文本的行为)
FREE_INPUT = 'FREE_INPUT',
// 代码问题快捷修复
CODE_PROBLEM_SOLVE = 'CODE_PROBLEM_SOLVE',
// shell命令生成
TERMINAL_COMMAND_GENERATION = 'TERMINAL_COMMAND_GENERATION',
// 终端报错修复
TERMINAL_EXPLAIN_FIX = 'TERMINAL_EXPLAIN_FIX',
// 代码补全
COMPLETION = 'COMPLETION',
}出参定义
/**
* 后置处理结果
*/
export class PostHandlerResponse {
// 处理策略,通过该策略可以控制后续的处理逻辑
handlePolicy: HandlePolicy;
// 原因描述
reason?: string;
// 经过后置处理器处理过的模型返回结果
processedResult: InferredResult;
constructor() {
// 默认值
this.handlePolicy = HandlePolicy.NO_OPS;
this.reason = '';
this.processedResult = new InferredResult();
}
}
/**
* 封装大模型返回结果
*/
export class AIResponse {
// 模型推理结果
inferredResult: InferredResult;
constructor() {
this.inferredResult = new InferredResult();
}
}
/**
* 模型推理生成的结果数据
*/
export class InferredResult {
//LLM生成的文本内容
text: string;
constructor() {
this.text = '';
}
}
/**
* 处理策略枚举(后置过滤器当前只支持NO_OPS)
*/
export enum HandlePolicy {
// 阻断策略,直接阻断请求
BLOCK = 'BLOCK',
// 过滤策略,拦截请求并对payload内容进行修改
FILTER = 'FILTER',
// 忽略策略,不处理请求
NO_OPS = 'NO_OPS',
}知识库上传过滤器配置(仅适用于企业专属版)
企业专属版中,支持通义灵码管理员、全局管理员通过在策略配置中配置知识库过滤器,配置完成后,在知识库文件上传前对其进行审查,从而满足在特定场景下对知识库内容前置过滤的需求。
过滤器配置说明
步骤一:开启并编辑知识库过滤器
在左侧导航栏,单击策略配置,在右侧页面,单击知识库过滤器页签。
在知识库过滤器配置页面,您可以打开开关开启/关闭知识库上传前置过滤器,进行参数配置编辑。
URL 地址
必填
企业提供的第三方扫描服务的接口地址。要求此接口必须使用 POST 请求。
Token 字段名
必填
指定请求头中用于存放 Token 的字段名。
Secret 密钥
必填
生成访问 Token 所需的密钥。Token 会被放入指定的请求头字段中,用于验证请求的合法性。详情请参考“安全 Token”章节。

步骤二:测试过滤器连通性
填写正确后,进行连通性测试,单击测试连接按钮。当第三方过滤接口返回
2xx状态码时,测试成功。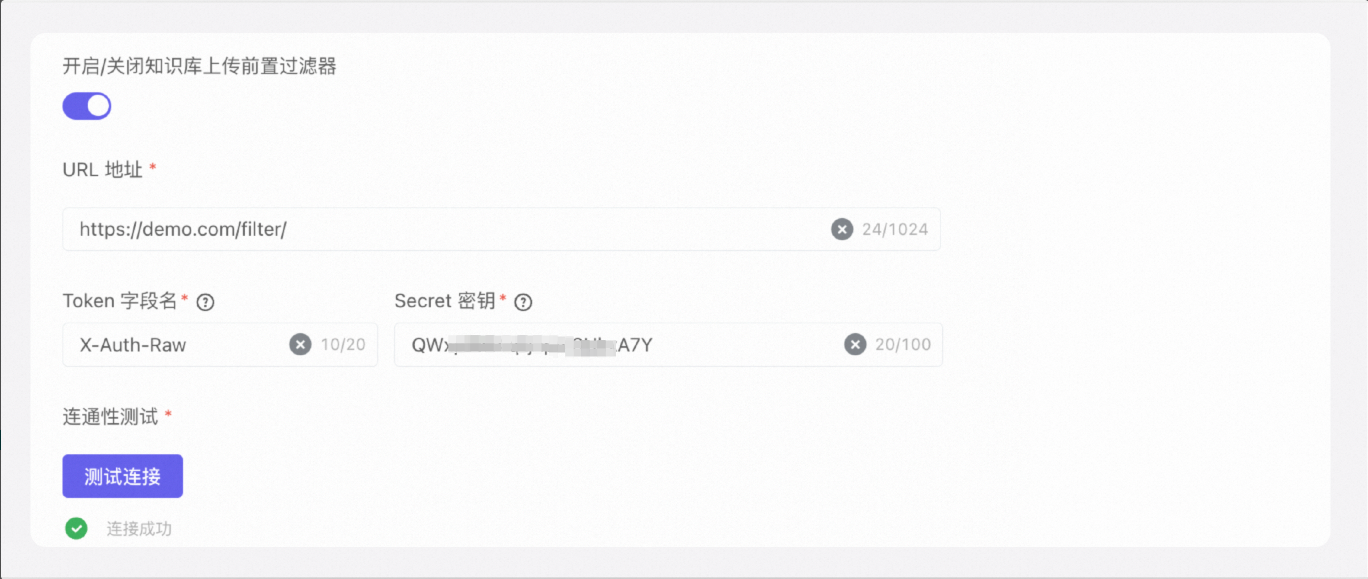
如果返回其它状态码,测试则会失败,您需要检查填写信息后再重现测试连接。
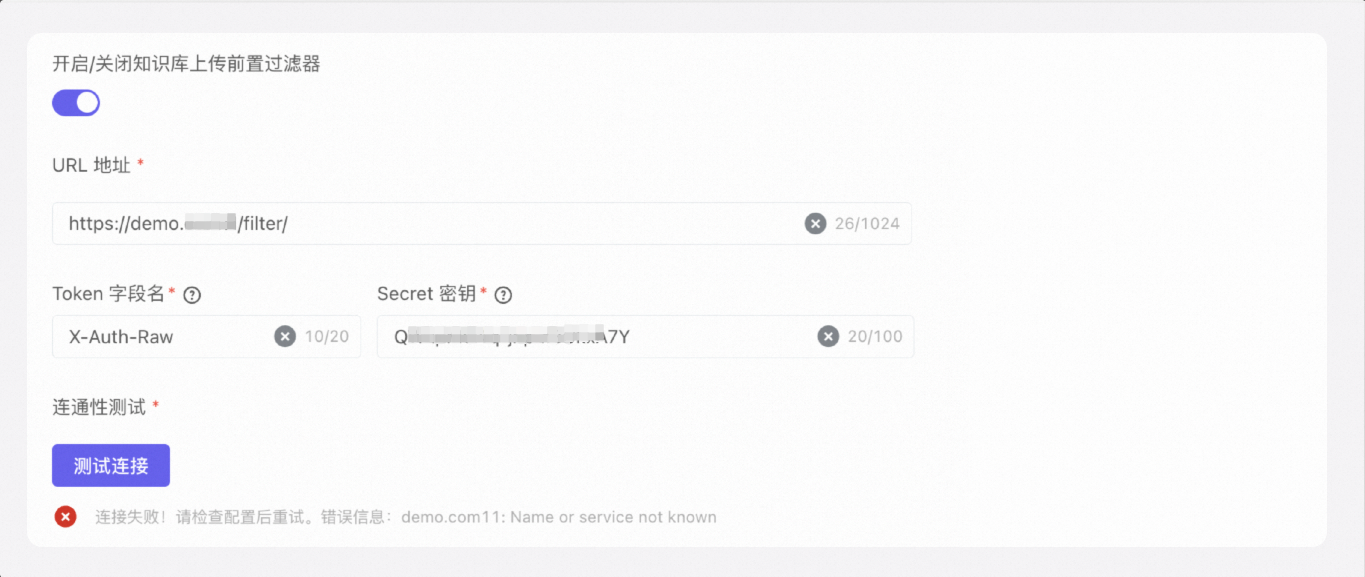
步骤三:保存知识库过滤器
单击保存配置按钮,保存您的过滤器配置。保存成功后,过滤器将立即生效。
第三方扫描服务接口规范
企业需提供第三方扫描服务,以便知识库过滤器可以使用该服务对上传的知识内容进行扫描,通过扫描后方可上传。为了确保您配置的过滤器正常运行,扫描服务的接口应符合以下设计要求:
请求头
参数名 | 是否必填 | 参数说明 | 参数示例 |
X-Auth-Raw | 是 | 接口鉴权参数,参数名为您在过滤器配置页面中配置的 Token 字段名。参数值应为Secret 密钥通过加密算法生成的最终密钥,具体生成逻辑详见“安全 Token”章节。 | 6c3baa76c62550eab864e6f75c4bb |
Content-Type | 是 | 表示请求和响应中的媒体类型信息。 | multipart/form-data |
安全Token:是阿里云设计的一种安全签名,旨在防止恶意攻击者盗用您的云服务权限。生成 Token 需要以下要素:Secret 密钥、当前时间、其他信息和加密算法。
Token生成:通义灵码调用第三方扫描服务接口时,将在请求头内携带安全Token 用于身份鉴权验证。 根据如下参数计算生成 Token 值:
token = sha256Hex(method + url + timestamp + tokenSecret) + timestampHexmethod
为POST 方法。
url
为配置知识库过滤器填写的扫描服务接口 URL 地址。
timestamp
为当前时间。
tokenSecret
为配置知识库过滤器时填写的 Secret 密钥。
timestampHex
将时间戳转换成十六进制。
Token验证:您的第三方扫描服务在验证请求的Token鉴权时,可以参考以下代码进行合法性校验。
重要时间戳:确保客户端和服务端的时间同步,避免因时间偏差导致Token验证失败。
密钥管理:妥善保管
tokenSecret,不要泄露给未经授权的用户。过期时间:根据业务需求调整 Token 的有效时间,示例中设置为60秒,可根据实际情况调整。
/* * 方法参数说明: * receivedHash:接收到的哈希值,包含了时间戳信息。 * tokenSecret:用于生成哈希的密钥。 * url:请求的URL。 */ public boolean validateAuthRaw(String receivedHash, String tokenSecret, String url) { final String method = "POST"; // 从 receivedHash 中提取时间戳部分 String tsHex = receivedHash.substring(receivedHash.length() - 8); long tsSec = Long.parseLong(tsHex, 16); // 计算当前时间与接收时间的差异,假设允许的最大时间差为60秒 long now = System.currentTimeMillis() / 1000L; if (Math.abs(now - tsSec) > 60) { return false; // 超过允许的时间范围 } // 构建待签名的字符串 String plain = method + url + tsSec + tokenSecret; // 生成预期的哈希值 String expectedHash = org.apache.commons.codec.digest.DigestUtils.sha256Hex(plain); // 比较接收到的哈希值与预期的哈希值 return expectedHash.equals(receivedHash.substring(0, receivedHash.length() - 8)); }
请求参数
参数名 | 参数类型 | 是否必填 | 参数解释 | 参数示例 |
metadata | string | 是 | 业务元数据,Content-Type: application/json | {"user": "user0000001", "queryId": "cd2fd109-c4d4-489f-9b27-53752f7827d6"} |
file | file | 是 | 送检的文件 |
请求示例。
Content-Type: multipart/form-data; boundary=${bound}
--${bound}
Content-Disposition: form-data; name="metadata"
Content-Type: application/json
{
"user":"user0000001",
"queryID":"cd2fd109-c4d4-489f-9b27-53752f7827d6"
}
--${bound}
Content-Disposition: form-data; name="file"; filename="test-file.pdf"
Content-Type: application/pdf
%binary-file-content-here%响应结构
接口应返回 HTTP 状态码 200,并包含以下格式的响应体。
参数名 | 参数类型 | 是否必填 | 参数解释 | 参数示例 |
forbidden | boolean | 是 | 安全检测结果。true表示检测失败。 | false |
errorMsg | string | 否 | 错误信息,说明检测失败的原因。 | "文件包含恶意内容,请修改后再上传" |
queryId | string | 否 | 请求 ID,需与请求 metadata 中的 queryId 字段对应。 | "cd2fd109-c4d4-489f-9b27-53752f7827d6" |
user | string | 否 | 用户 ID,需与请求 metadata 中的 user 字段对应。 | "user0001" |