
本文为您介绍使用MaxCompute过程中常见的数据倾斜场景以及对应的解决方案。
MapReduce
在了解数据倾斜之前首先需要了解什么是MapReduce,MapReduce是一种典型的分布式计算框架,它采用分治法的思想,将一些规模较大或者难以直接求解的问题分割成较小规模或容易处理的若干子问题,对这些子问题进行求解后将结果合并成最终结果。MapReduce相较于传统并行编程框架,具有高容错性、易使用性以及较好的扩展性等优点。在MapReduce中实现并行程序无需考虑分布式集群中的编程无关问题,如数据存储、节点间的信息交流和传输机制等,大大简化了其用户的分布式编程方式。
MapReduce的具体工作流程示意图如下: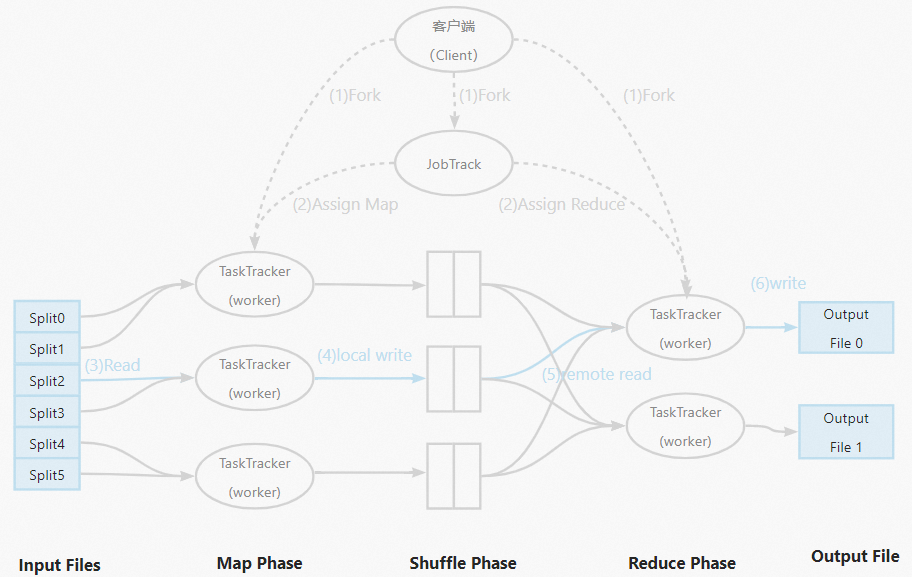
数据倾斜
数据倾斜多发生在Reducer端,Mapper按Input files切分,一般相对均匀,数据倾斜指表中数据分布不均衡的情况分配给不同的Worker。数据不均匀的时候,导致有的Worker很快就计算完成了,但是有的Worker却需要运行很长时间。在实际生产中,大部分数据存在偏斜,这符合“二八”定律,例如一个论坛20%的活跃用户贡献了80%的帖子,或者一个网站80%的访问量由20%的用户提供。在数据量爆炸式增长的大数据时代,数据倾斜问题会严重影响分布式程序的执行效率。作业运行表现为作业的执行进度一直停留在99%,作业执行感觉被卡住了。
如何判断发生数据倾斜
在MaxCompute中通过Logview可以很容易判断数据倾斜,具体步骤如下:
在Fuxi Jobs中对运行时间Latency按照降序排列,选择运行时间最长的Job Stage。
在Fuxi Instance of Fuxi Stage中对运行时间Latency按照降序排列,选择运行时长远大于平均时长的任务,一般选择第一个进行锁定,查看其对应的输出日志StdOut。
根据StdOut中的反馈信息,查看对应的作业执行图。
根据作业执行图中的Key信息,可以进而定位到导致数据倾斜的SQL代码片段。
使用示例如下。
通过任务的运行日志,找到对应的Logview日志,详情请参见Logview入口。
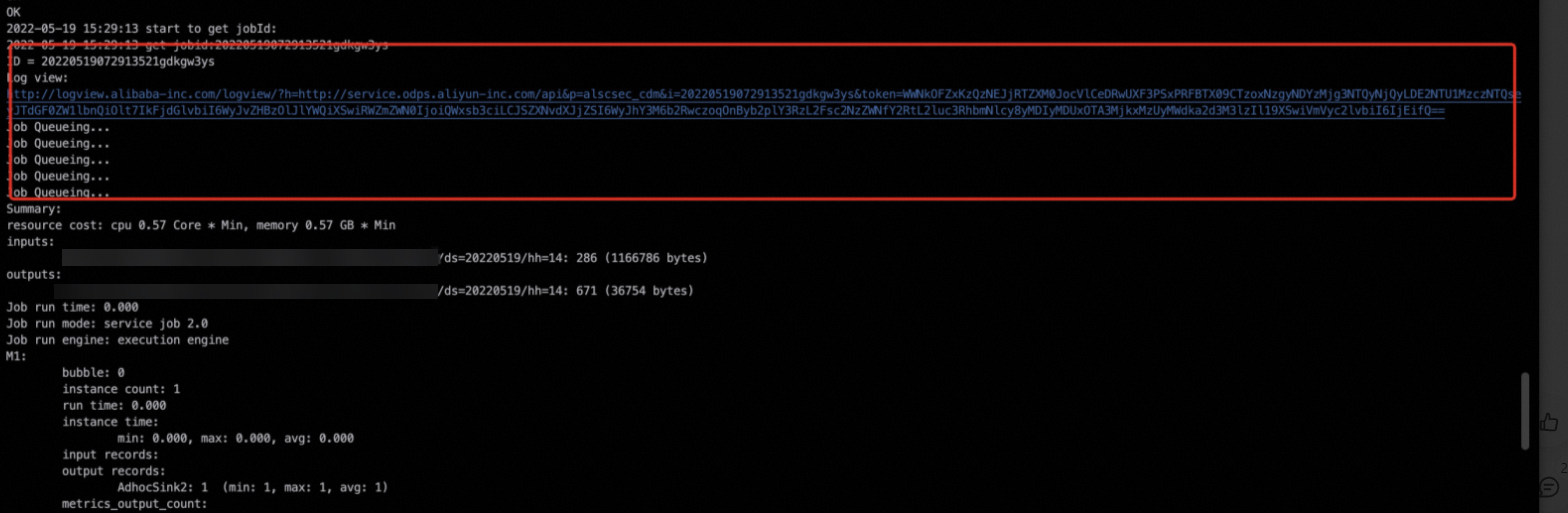
进入Logview界面,根据运行时间Latency按照降序排列,选择时间最长的Fuxi Task,就可以快速锁定问题。
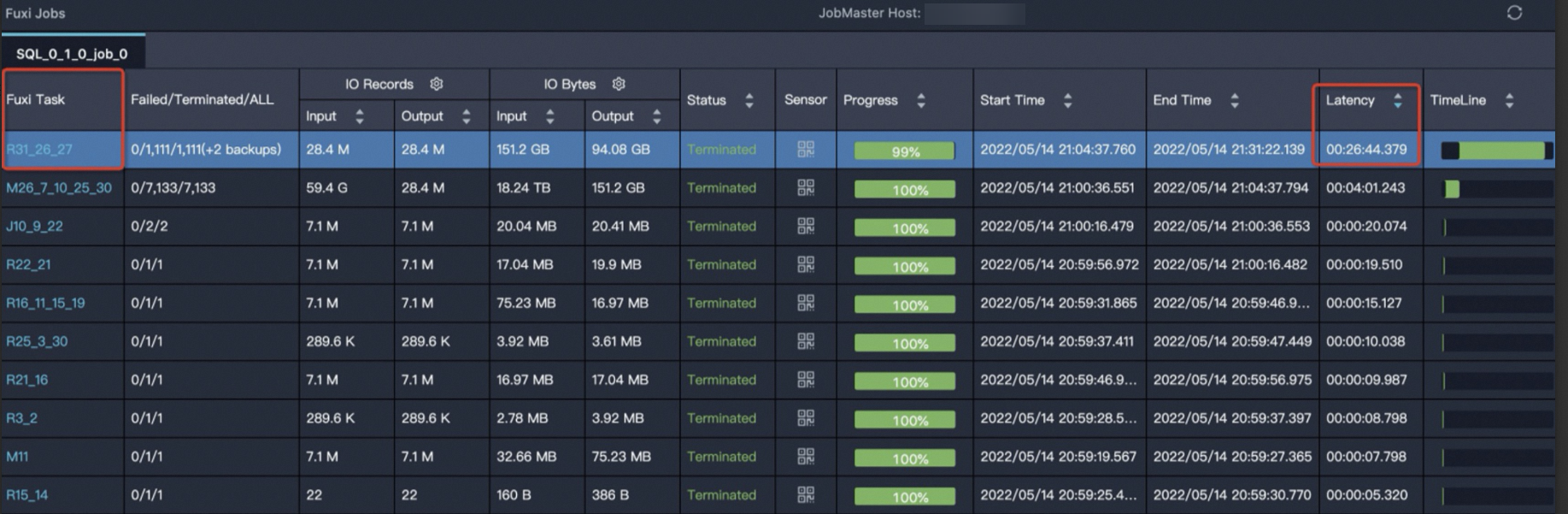
R31_26_27的运行时间最长,单击R31_26_27任务,进入实例运行情况详情页,如下所示。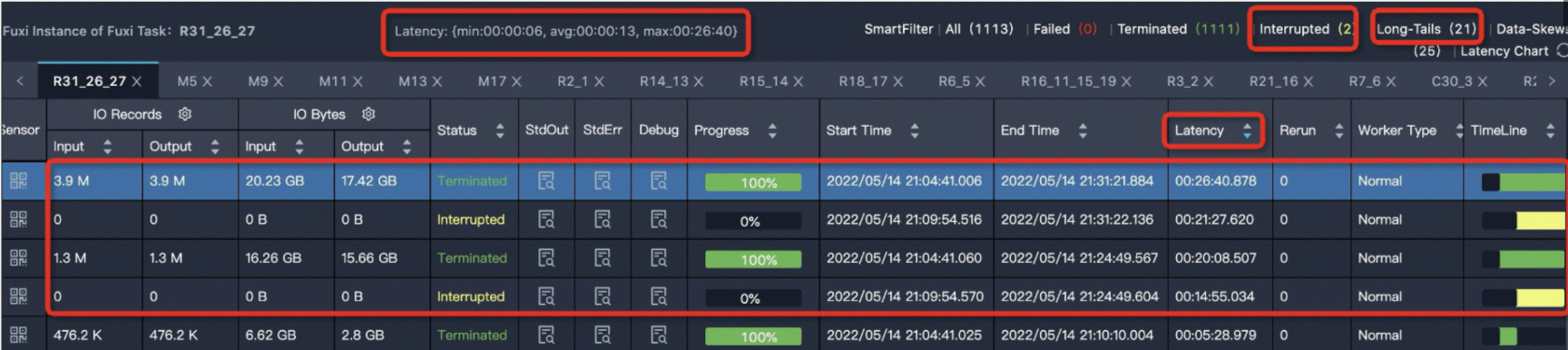
Latency: {min:00:00:06, avg:00:00:13, max:00:26:40}表示任务下的所有实例的最小运行时长是6s,平均运行时长是13s,最大运行时长是26分钟40s。可以通过Latency(实例运行时长)进行降序排序,可以看到有四个运行时间比较长的实例。MaxCompute将Fuxi Instance耗费时长高于平均值2倍的实例判定为长尾,也就是说任务实例运行时长大于26s的都会判定为长尾(Long-Tails),此处有21个实例大于26s。有Long-Tails实例不一定代表任务倾斜,还需要看实例运行时间avg、max两值的对比,对max值远远大于avg值的任务,也就是严重数据倾斜任务,对此任务需要进行治理。单击StdOut列的
 图标,查看输出日志,示例如下。
图标,查看输出日志,示例如下。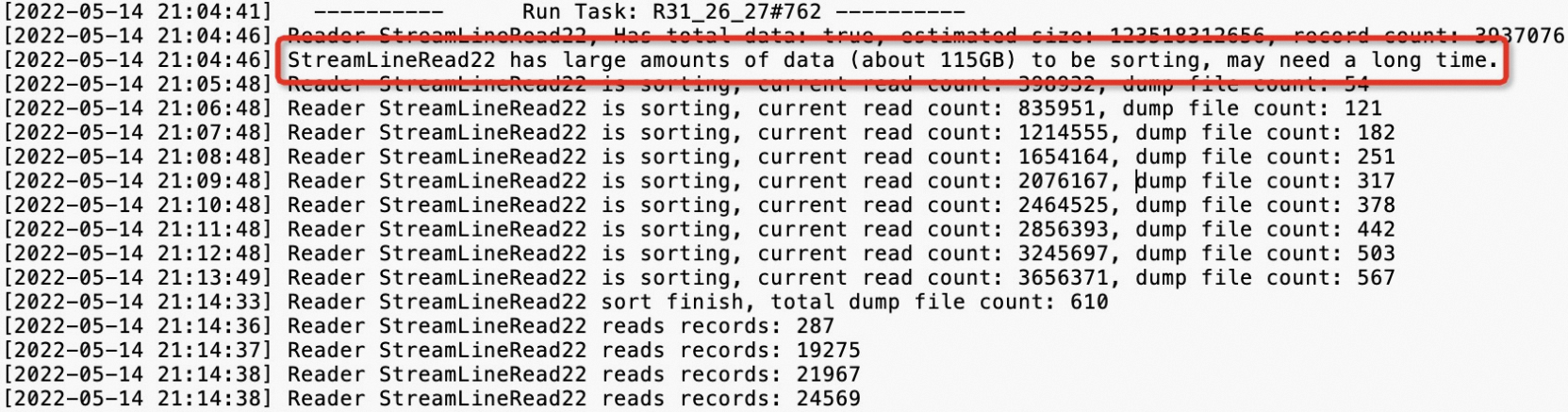
锁定到问题后,在Job Details页签右键单击
R31_26_27选择expand all展开任务,详情请参见使用Logview 2.0查看作业运行信息。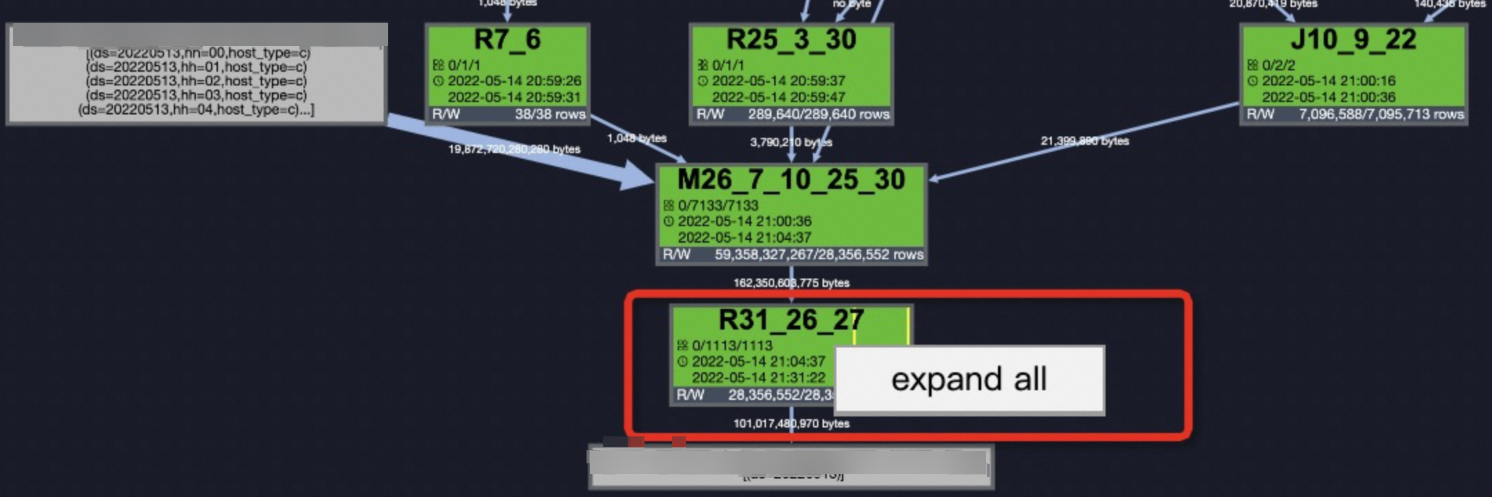 查看
查看StreamLineRead22的上一步StreamLineWriter21,即可定位到导致数据倾斜的Key:new_uri_path_structure、cookie_x5check_userid、cookie_userid。这样也就定位到数据倾斜的SQL片段了。
数据倾斜排查及解决方法
根据使用经验总结,引起数据倾斜的主要原因有如下几类:
Join
GroupBy
Count(Distinct)
ROW_NUMBER(TopN)
动态分区
其中出现的频率排序为JOIN > GroupBy > Count(Distinct) > ROW_NUMBER > 动态分区。
Join
针对Join端产生的数据倾斜,会存在多种不同的情况,例如大表和小表Join、大表和中表Join、Join热值长尾。
大表Join小表。
数据倾斜示例。
如下示例中
t1是一张大表,t2、t3是小表。SELECT t1.ip ,t1.is_anon ,t1.user_id ,t1.user_agent ,t1.referer ,t2.ssl_ciphers ,t3.shop_province_name ,t3.shop_city_name FROM <viewtable> t1 LEFT OUTER JOIN <other_viewtable> t2 ON t1.header_eagleeye_traceid = t2.eagleeye_traceid LEFT OUTER JOIN ( SELECT shop_id ,city_name AS shop_city_name ,province_name AS shop_province_name FROM <tenanttable> WHERE ds = MAX_PT('<tenanttable>') AND is_valid = 1 ) t3 ON t1.shopid = t3.shop_id解决方案。
使用MAPJOIN HINT语法,如下所示。
SELECT /*+ mapjoin(t2,t3)*/ t1.ip ,t1.is_anon ,t1.user_id ,t1.user_agent ,t1.referer ,t2.ssl_ciphers ,t3.shop_province_name ,t3.shop_city_name FROM <viewtable> t1 LEFT OUTER JOIN (<other_viewtable>) t2 ON t1.header_eagleeye_traceid = t2.eagleeye_traceid LEFT OUTER JOIN ( SELECT shop_id ,city_name AS shop_city_name ,province_name AS shop_province_name FROM <tenanttable> WHERE ds = MAX_PT('<tenanttable>') AND is_valid = 1 ) t3 ON t1.shopid = t3.shop_id注意事项。
引用小表或子查询时,需要引用别名。
MapJoin支持小表为子查询。
在MapJoin中可以使用不等值连接或
or连接多个条件。您可以通过不写on语句而通过mapjoin on 1 = 1的形式,实现笛卡尔乘积的计算。例如select /*+ mapjoin(a) */ a.id from shop a join table_name b on 1=1;,但此操作可能带来数据量膨胀问题。MapJoin中多个小表用半角逗号(
,)分隔,例如/*+ mapjoin(a,b,c)*/。MapJoin在Map阶段会将指定表的数据全部加载在内存中,因此指定的表仅能为小表,且表被加载到内存后占用的总内存不得超过512 MB。由于MaxCompute是压缩存储,因此小表在被加载到内存后,数据大小会急剧膨胀。此处的512 MB是指加载到内存后的空间大小。可以通过如下参数设置加大内存,最大为8192 MB。
SET odps.sql.mapjoin.memory.max=2048;
MapJoin中Join操作的限制。
left outer join的左表必须是大表。right outer join的右表必须是大表。不支持
full outer join。inner join的左表或右表均可以是大表。MapJoin最多支持指定128张小表,否则报语法错误。
大表Join中表。
数据倾斜示例。
如下示例中
t0为大表,t1为中表。SELECT request_datetime ,host ,URI ,eagleeye_traceid FROM <viewtable> t0 LEFT JOIN ( SELECT traceid, eleme_uid, isLogin_is FROM <servicetable> WHERE ds = '${today}' AND hh = '${hour}' ) t1 ON t0.eagleeye_traceid = t1.traceid WHERE ds = '${today}' AND hh = '${hour}'解决方案。
使用DISTRIBUTED MAPJOIN语法解决数据倾斜,如下所示。
SELECT /*+distmapjoin(t1)*/ request_datetime ,host ,URI ,eagleeye_traceid FROM <viewtable> t0 LEFT JOIN ( SELECT traceid, eleme_uid, isLogin_is FROM <servicetable> WHERE ds = '${today}' AND hh = '${hour}' ) t1 ON t0.eagleeye_traceid = t1.traceid WHERE ds = '${today}' AND hh = '${hour}'
Join热值长尾。
数据倾斜示例
在下面这个表中,
eleme_uid中存在很多热点数据,容易发生数据倾斜。SELECT eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> )t1 LEFT JOIN( SELECT eleme_uid, ... FROM <customertable> ) t2 ON t1.eleme_uid = t2.eleme_uid;解决方案。
可以通过如下四种方法来解决。
序号
方案
说明
方案一
手动切分热值
将热点值分析出来后,从主表中过滤出热点值记录,先进行MapJoin,再将剩余非热点值记录进行MergeJoin,最后合并两部分的Join结果。
方案二
设置SkewJoin参数
set odps.sql.skewjoin=true;。方案三
SkewJoin Hint
使用Hint提示:
/*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])]*/。SkewJoin Hint的方式相当于多了一次找倾斜Key的操作,会让Query运行时间加长;如果用户已经知道倾斜Key了,就可以通过设置SkewJoin参数的方式,能节省一些时间。方案四
倍数表取模相等Join
利用倍数表。
手动切分热值。
将热点值分析出来后,从主表中过滤出热点值记录,先进行MapJoin,再将剩余非热点值记录进行MergeJoin,最后合并两部分的Join结果。具体可以参考如下代码示例:
SELECT /*+ MAPJOIN (t2) */ eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> WHERE eleme_uid = <skewed_value> )t1 LEFT JOIN( SELECT eleme_uid, ... FROM <customertable> WHERE eleme_uid = <skewed_value> ) t2 ON t1.eleme_uid = t2.eleme_uid UNION ALL SELECT eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> WHERE eleme_uid != <skewed_value> )t3 LEFT JOIN( SELECT eleme_uid, ... FROM <customertable> WHERE eleme_uid != <skewed_value> ) t4 ON t3.eleme_uid = t4.eleme_uid设置SkewJoin参数。
该方案是一种比较常规的使用方案,MaxCompute提供数据倾斜设置参数
set odps.sql.skewjoin=true;开启SkewJoin功能,但使用时如果只开启SkewJoin,对于任务的运行并不会有任何影响,还必须设置odps.sql.skewinfo参数才会有效,odps.sql.skewinfo参数作用是设置Join优化具体信息,命令语法示例如下。SET odps.sql.skewjoin=true; SET odps.sql.skewinfo=skewed_src:(skewed_key)[("skewed_value")]; --skewed_src为流量表,skewed_value为热点值使用示例如下:
--针对单个字段单个倾斜数值 SET odps.sql.skewinfo=src_skewjoin1:(key)[("0")]; --针对单个字段多个倾斜数值 SET odps.sql.skewinfo=src_skewjoin1:(key)[("0")("1")];SkewJoin Hint。
在
SELECT语句中使用如下Hint提示:/*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])]*/才会执行MapJoin,其中table_name为倾斜表名,column_name为倾斜列名,value为倾斜Key值。使用示例如下。--方法1:Hint表名(注意Hint的是表的别名)。 SELECT /*+ skewjoin(a) */ * FROM T0 a JOIN T1 b ON a.c0 = b.c0 AND a.c1 = b.c1; --方法2:Hint表名和认为可能产生倾斜的列,例如表a的c0和c1列存在数据倾斜。 SELECT /*+ skewjoin(a(c0, c1)) */ * FROM T0 a JOIN T1 b ON a.c0 = b.c0 AND a.c1 = b.c1 AND a.c2 = b.c2; --方法3:Hint表名和列,并提供发生倾斜的key值。如果是STRING类型,需要加上引号。例如(a.c0=1 and a.c1="2")和(a.c0=3 and a.c1="4")的值都存在数据倾斜。 SELECT /*+ skewjoin(a(c0, c1)((1, "2"), (3, "4"))) */ * FROM T0 a JOIN T1 b ON a.c0 = b.c0 AND a.c1 = b.c1 AND a.c2 = b.c2;说明SkewJoin Hint方法直接指定值的处理效率比手动切分热值方法和设置SkewJoin参数方法(不指定值)高。
SkewJoin Hint支持的Join类型:
Inner Join可以对Join两侧表中的任意一侧进行Hint。
Left Join、Semi Join和Anti Join只可以Hint左侧表。
Right Join只可以Hint右侧表。
Full Join不支持Skew Join Hint。
建议只对一定会出现数据倾斜的Join添加Hint,因为Hint会运行一个Aggregate,存在一定代价。
被Hint的Join的Left Side Join Key的类型需要与Right Side Join Key的类型一致,否则SkewJoin Hint不生效。例如上例中的
a.c0与b.c0的类型需要一致,a.c1与b.c1的类型需要一致。您可以通过在子查询中将Join Key进行Cast从而保持一致。示例如下:CREATE TABLE T0(c0 int, c1 int, c2 int, c3 int); CREATE TABLE T1(c0 string, c1 int, c2 int); --方法1: SELECT /*+ skewjoin(a) */ * FROM T0 a JOIN T1 b ON cast(a.c0 AS string) = cast(b.c0 AS string) AND a.c1 = b.c1; --方法2: SELECT /*+ skewjoin(b) */ * FROM (SELECT cast(a.c0 AS string) AS c00 FROM T0 a) b JOIN T1 c ON b.c00 = c.c0;加SkewJoin Hint后,优化器会运行一个Aggregate获取前20的热值。
20是默认值,您可以通过set odps.optimizer.skew.join.topk.num = xx;进行设置。SkewJoin Hint只支持对Join其中一侧进行Hint。
被Hint的Join一定要有
left key = right key,不支持笛卡尔积Join。MapJoin Hint的Join不能再添加SkewJoin Hint。
倍数表取模相等Join。
该方案和前三个方案的逻辑不同,不是分而治之的思路,而是利用一个倍数表,其值只有一列:int列,比如可以是从1到N(具体可根据倾斜程度确定),利用这个倍数表可以将用户行为表放大N倍,然后Join时使用用户ID和
number两个关联键。这样原先只按照用户ID分发导致的数据倾斜就会由于加入了number关联条件而减少为原先的1/N。但是这样做也会导致数据膨胀N倍。SELECT eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> )t1 LEFT JOIN( SELECT /*+mapjoin(<multipletable>)*/ eleme_uid, number ... FROM <customertable> JOIN <multipletable> ) t2 ON t1.eleme_uid = t2.eleme_uid AND mod(t1.<value_col>,10)+1 = t2.number;基于上面数据膨胀的情况,我们还可以将膨胀只局限作用于两表中的热点值记录,其他非热点值记录不变。先找到热点值记录,然后分别处理流量表和用户行为表,新增加一个
eleme_uid_join列,如果用户ID是热点值,concat一个随机分配正整数(0到预定义的倍数之间,比如0~1000),如果不是则保持原用户ID不变。在两表Join时使用eleme_uid_join列。这样既起到了放大热点值倍数减小倾斜程度的作用,又减少了对非热点值无效的膨胀。不过可想而知的是这样的逻辑会将原先的业务逻辑SQL改得面目全非,因此不建议使用。
GroupBy
一个带GroupBy的伪代码示例如下。
SELECT shop_id
,sum(is_open) AS 营业天数
FROM table_xxx_di
WHERE dt BETWEEN '${bizdate_365}' AND '${bizdate}'
GROUP BY shop_id;当发生数据倾斜时,可以通过如下三种方案解决:
序号 | 方案 | 说明 |
方案一 | 设置Group By防倾斜的参数 |
|
方案二 | 添加随机数 | 把引起长尾的Key进行拆分。 |
方案三 | 创建滚存表 | 降本提效。 |
方案一:设置Group By防倾斜的参数。
SET odps.sql.groupby.skewindata=true;方案二:添加随机数。
相对于方案一,此解决方案对SQL进行改写,添加随机数,把引起长尾的Key进行拆分是解决Group By长尾的一种比较好的方法。
对于SQL:
Select Key,Count(*) As Cnt From TableName Group By Key;不考虑Combiner,M节点会Shuffle到R节点上,然后R节点再做Count操作,对应的执行计划是M->R。假定已经找到了引起长尾的key,对长尾的Key再做一次工作再分配,就变成:
--假设长尾的Key已经找到是KEY001 SELECT a.Key ,SUM(a.Cnt) AS Cnt FROM(SELECT Key ,COUNT(*) AS Cnt FROM <TableName> GROUP BY Key ,CASE WHEN KEY = 'KEY001' THEN Hash(Random()) % 50 ELSE 0 END ) a GROUP BY a.Key;改完之后的执行计划变成了
M->R->R,虽然执行步骤变长了,但是长尾的Key经过了2个步骤的处理,整体的时间消耗可能反而有所减少。资源消耗与耗时效果方面跟方案一基本持平,但实际场景中引发长尾的Key不止一个,再考虑寻找长尾Key和SQL改写的投入成本,方案一会更低一些。创建滚存表。
核心降本提效,我们的核心诉求是取过去一年的商户数据,对于线上任务而言,每次都要读取
T-1至T-365的所有分区其实是对资源的很大浪费,创建滚存表可以减少分区的读取但是又不影响过去一年的取数,示例如下。首次初始化365天的商户营业数据(Group By汇总),标记数据更新日期,记为表
a;后续线上任务切换为T-2日表a关联table_xxx_di表再Group By,这样每天读取的数据从365减少到了2个,主键shopid的重复性极大降低,对资源的消耗也会减少。--创建滚存表 CREATE TABLE IF NOT EXISTS m_xxx_365_df ( shop_id STRING COMMENT, last_update_ds COMMENT, 365d_open_days COMMENT ) PARTITIONED BY ( ds STRING COMMENT '日期分区' )LIFECYCLE 7; --假定365d是 2021.5.1-2022.5.1,先完成一次初始化 INSERT OVERWRITE TABLE m_xxx_365_df PARTITION(ds = '20220501') SELECT shop_id, max(ds) as last_update_ds, sum(is_open) AS 365d_open_days FROM table_xxx_di WHERE dt BETWEEN '20210501' AND '20220501' GROUP BY shop_id; --那么之后线上任务要执行的是 INSERT OVERWRITE TABLE m_xxx_365_df PARTITION(ds = '${bizdate}') SELECT aa.shop_id, aa.last_update_ds, 365d_open_days - COALESCE(is_open, 0) AS 365d_open_days --消除营业天数的无限滚存 FROM ( SELECT shop_id, max(last_update_ds) AS last_update_ds, sum(365d_open_days) AS 365d_open_days FROM ( SELECT shop_id, ds AS last_update_ds, sum(is_open) AS 365d_open_days FROM table_xxx_di WHERE ds = '${bizdate}' GROUP BY shop_id UNION ALL SELECT shop_id, last_update_ds, 365d_open_days FROM m_xxx_365_df WHERE dt = '${bizdate_2}' AND last_update_ds >= '${bizdate_365}' GROUP BY shop_id ) GROUP BY shop_id ) AS aa LEFT JOIN ( SELECT shop_id, is_open FROM table_xxx_di WHERE ds = '${bizdate_366}' ) AS bb ON aa.shop_id = bb.shop_id;
Count(Distinct)
假如一个表数据分布如下。
ds(分区) | cnt(记录数) |
20220416 | 73025514 |
20220415 | 2292806 |
20220417 | 2319160 |
使用下面的语句就容易发生数据倾斜:
SELECT ds
,COUNT(DISTINCT shop_id) AS cnt
FROM demo_data0
GROUP BY ds;解决方案如下:
序号 | 方案 | 说明 |
方案一 | 参数设置调优 |
|
方案二 | 通用两阶段聚合 | 在partition字段值拼接随机数。 |
方案三 | 类似两阶段聚合 | 先通过GroupBy两分组字段 |
方案一:参数设置调优。
设置如下参数。
SET odps.sql.groupby.skewindata=true;方案二:通用两阶段聚合。
若
shop_id字段数据不均匀,则无法通过方案一优化,较通用的方式是在分区(partition)字段值中拼接随机数。--方式1:拼接随机数 CONCAT(ROUND(RAND(),1)*10,'_', ds) AS rand_ds SELECT SPLIT_PART(rand_ds, '_',2) ds ,COUNT(*) id_cnt FROM ( SELECT rand_ds ,shop_id FROM demo_data0 GROUP BY rand_ds,shop_id ) GROUP BY SPLIT_PART(rand_ds, '_',2); --方式2:新增随机数字段 ROUND(RAND(),1)*10 AS randint10 SELECT ds ,COUNT(*) id_cnt FROM (SELECT ds ,randint10 ,shop_id FROM demo_data0 GROUP BY ds,randint10,shop_id ) GROUP BY ds;方案三:类似两阶段聚合。
如果GroupBy与Distinct的字段数据都均匀,则可以采用如下方式优化,先GroupBy两分组字段(ds和shop_id)再使用
count(distinct)命令。SELECT ds ,COUNT(*) AS cnt FROM(SELECT ds ,shop_id FROM demo_data0 GROUP BY ds ,shop_id ) GROUP BY ds;
ROW_NUMBER(TopN)
Top10的示例如下。
SELECT main_id
,type
FROM (SELECT main_id
,type
,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn
FROM <data_demo2>
) A
WHERE A.rn <= 10;当发生数据倾斜时,可以通过以下几种方式解决:
序号 | 方案 | 说明 |
方案一 | SQL写法的两阶段聚合。 | 增加随机列或拼接随机数,将其作为分区(Partition)中一参数。 |
方案二 | UDAF写法的两阶段聚合。 | 最小堆的队列优先的通过UDAF的方式进行调优。 |
方案一:SQL写法的两阶段聚合。
为使Map阶段中Partition各分组数据尽可能均匀,增加随机列,将其作为Partition中一参数。
SELECT main_id ,type FROM (SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn FROM (SELECT main_id ,type FROM (SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id,src_pt ORDER BY type DESC ) rn FROM (SELECT main_id ,type ,ceil(110 * rand()) % 11 AS src_pt FROM data_demo2 ) ) B WHERE B.rn <= 10 ) ) A WHERE A.rn <= 10; --2.随机数直接自定义 SELECT main_id ,type FROM (SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn FROM (SELECT main_id ,type FROM(SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id,src_pt ORDER BY type DESC ) rn FROM (SELECT main_id ,type ,ceil(10 * rand()) AS src_pt FROM data_demo2 ) ) B WHERE B.rn <= 10 ) ) A WHERE A.rn <= 10;方案二:UDAF写法的两阶段聚合。
SQL方式会有较多代码,且可能不利于维护,此处将利用最小堆的队列优先的通过UDAF的方式进行调优,即在
iterate阶段仅取TopN,merge阶段则均仅对N个元素融合,过程如下。iterate:将前K个元素进行push,K之后的元素通过不断与最小顶比较交换堆中元素。merge:将两堆merge后,原地返回前K个元素。terminate:数组形式返回堆。SQL中将数组拆为各行。
@annotate('* -> array<string>') class GetTopN(BaseUDAF): def new_buffer(self): return [[], None] def iterate(self, buffer, order_column_val, k): # heapq.heappush(buffer, order_column_val) # buffer = [heapq.nlargest(k, buffer), k] if not buffer[1]: buffer[1] = k if len(buffer[0]) < k: heapq.heappush(buffer[0], order_column_val) else: heapq.heappushpop(buffer[0], order_column_val) def merge(self, buffer, pbuffer): first_buffer, first_k = buffer second_buffer, second_k = pbuffer k = first_k or second_k merged_heap = first_buffer + second_buffer merged_heap.sort(reverse=True) merged_heap = merged_heap[0: k] if len(merged_heap) > k else merged_heap buffer[0] = merged_heap buffer[1] = k def terminate(self, buffer): return buffer[0] SET odps.sql.python.version=cp37; SELECT main_id,type_val FROM ( SELECT main_id ,get_topn(type, 10) AS type_array FROM data_demo2 GROUP BY main_id ) LATERAL VIEW EXPLODE(type_array)type_ar AS type_val;
动态分区
动态分区是指在往分区表里插入数据时,可以在分区中指定一个分区列名,但不给出具体值,而是在Select子句中的对应列来提供分区值的一种语法。 因此在SQL运行之前,是不知道会产生哪些分区,只有在SQL语句运行结束后,才能够根据分区列产生的值确定会产生哪些分区,详情请参见插入或覆写动态分区数据(DYNAMIC PARTITION)。SQL示例如下。
CREATE TABLE total_revenues (revenue bigint) partitioned BY (region string);
INSERT overwrite TABLE total_revenues PARTITION(region)
SELECT total_price AS revenue,region
FROM sale_detail;很多场景会建立动态分区的表,也容易发生数据倾斜。当发生数据倾斜时,可以通过下面的解决方案来解决。
序号 | 方案 | 说明 |
方案一 | 参数配置优化 | 通过参数配置进行优化。 |
方案二 | 裁剪优化 | 通过查找到存在记录数较多的分区裁剪后单独插入的方式解决。 |
方案一:参数配置优化。
动态分区可以把符合不同条件的数据放到不同的分区,避免需要通过多次Insert OverWrite写入到表中,特别是分区数比较多时,能够很好的简化代码,但是动态分区也有可能会带来小文件过多的困扰。
数据倾斜示例。
以如下最简SQL为例。
INSERT INTO TABLE part_test PARTITION(ds) SELECT * FROM part_test;假设其有K个Map Instance,N个目标分区。
ds=1 cfile1 ds=2 ... X ds=3 cfilek ... ds=n最极端的情况下,可能产生
K*N个小文件,而过多的小文件会对文件系统造成巨大的管理压力,因此MaxCompute对动态分区的处理是引入额外的一级Reduce Task, 把相同的目标分区交由同一个(或少量几个) Reduce Instance来写入, 避免小文件过多,并且这个Reduce肯定是最后一个Reduce Task操作。在MaxCompute中默认开启此功能,也就是如下参数设置为True。SET odps.sql.reshuffle.dynamicpt=true;默认开启该功能,解决了小文件过多的问题,不会因为单个Instance产生文件数过多而导致任务出错,但也引入了新的问题:数据倾斜,并且额外引入一级Reduce操作也耗费计算资源,因此如何保持这两者的平衡,需要认真权衡。
解决方案。
解决方案:对于开启
set odps.sql.reshuffle.dynamicpt=true;这个参数引入额外一级的Reduce的初衷是为了解决小文件数过多的问题,那么如果目标分区数比较少、根本就不会存在小文件过多的困扰,这时候默认开启该功能不仅浪费了计算资源,还降低了性能。相反,在此种情况下关闭此功能,即设置:set odps.sql.reshuffle.dynamicpt=false;反而能够大幅提高性能,示例如下。INSERT overwrite TABLE ads_tb_cornucopia_pool_d PARTITION (ds, lv, tp) SELECT /*+ mapjoin(t2) */ '20150503' AS ds, t1.lv AS lv, t1.type AS tp FROM (SELECT ... FROM tbbi.ads_tb_cornucopia_user_d WHERE ds = '20150503' AND lv IN ('flat', '3rd') AND tp = 'T' AND pref_cat2_id > 0 ) t1 JOIN (SELECT ... FROM tbbi.ads_tb_cornucopia_auct_d WHERE ds = '20150503' AND tp = 'T' AND is_all = 'N' AND cat2_id > 0 ) t2 ON t1.pref_cat2_id = t2.cat2_id;对于上面一段代码如果使用默认参数,整个任务的运行时长约为1小时30分钟,其中最后一个Reduce的运行时长约为1小时20分钟,占到总运行时长的
90%左右。由于引入额外的一个Reduce以后,使得每个Reduce Instance的数据分布特别不均匀,导致了数据长尾。
对于上述示例,我们通过统计历史动态分区产生的个数发现,每天产生的动态分区个数都只有2个左右,因此完全可以设置
set odps.sql.reshuffle.dynamicpt=false;。该任务的运行只需9分钟就可以运行完成,因此在这种情况下设置这个参数为false反而能大幅度提高性能,节约计算时间和计算资源,并且边际收益特别高,仅仅这是设置一个参数。其实不仅仅对于运行时长占用资源比较的大任务,对于普通的执行时长比较端消耗资源比较小的小任务,只要是用到了动态分区,并且动态分区的个数不多,都可以将该
odps.sql.reshuffle.dynamicpt参数设置为false,并且都能够节约资源,提高性能。满足如下三个条件的节点,都是可以被优化的,不管节点任务的时间长短。
使用了动态分区
动态分区个数<=50
没有set odps.sql.reshuffle.dynamicpt=false;
并且表根据最后一个Fuxi Instance的执行时长来判断该节点是否需要设置该参数的迫切程度,通过
diag_level字段来标识别,规则如下:Last_Fuxi_Inst_Time大于30分钟:Diag_Level=4('严重')。Last_Fuxi_Inst_Time在20到30分钟之间:Diag_Level=3 ('高')。Last_Fuxi_Inst_Time在10到20分钟之间:Diag_Level=2 ('中')。Last_Fuxi_Inst_Time小于10分钟:Diag_Level=1('低')。
方案二:裁剪优化。
根据动态分区插数据时Map阶段就存在的数据倾斜问题,可通过查找到存在记录数较多的分区裁剪后单独插入的方式解决。基于案例实际情况可修改Map阶段的参数配置,如下所示:
SET odps.sql.mapper.split.size=128; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi;由结果知,全过程进行了全表扫描,进一步优化,可通过关闭系统引入的Reduce Job优化,过程如下:
SET odps.sql.reshuffle.dynamicpt=false ; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi;根据动态分区插数据时Map阶段就存在的数据倾斜问题,可通过查找到存在记录数较多的分区裁剪后单独插入的方式解决,具体步骤如下。
使用如下命令示例查询记录数较多的特定分区。
SELECT ds ,hh ,COUNT(*) AS cnt FROM dwd_alsc_ent_shop_info_hi GROUP BY ds ,hh ORDER BY cnt DESC;部分分区如下:
ds
hh
cnt
20200928
17
1052800
20191017
17
1041234
20210928
17
1034332
20190328
17
1000321
20210504
1
19
20191003
20
18
20200522
1
18
20220504
1
18
使用如下命令示例过滤上述分区插入后,再单独插入大记录数分区数据。
SET odps.sql.reshuffle.dynamicpt=false ; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi WHERE CONCAT(ds,hh) NOT IN ('2020092817','2019101717','2021092817','2019032817'); set odps.sql.reshuffle.dynamicpt=false ; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi WHERE CONCAT(ds,hh) IN ('2020092817','2019101717','2021092817','2019032817'); SELECT ds ,hh,COUNT(*) AS cnt FROM dwd_alsc_ent_shop_info_hi GROUP BY ds,hh ORDER BY cnt desc;