
在使用MaxCompute开发过程中会产生费用,如果平时每日消费比较平稳,某段时间的费用增长翻倍。在排除业务增长的情况下,可以进行费用分析,排查导致费用突增的项目、作业是哪些,进而及时优化和调整作业,优化成本。本文为您介绍如何结合账单详情和MaxCompute元数据服务(Information Schema)排查MaxCompute后付费消费突增。
背景信息
本文排查MaxCompute后付费消费突增总体思路如下:
通过费用中心确认费用超出预期的日期,然后确认当天具体是哪个项目中的哪个计费项产生了高额费用。
分析具体的消费上涨原因:
如果是计算费用超出预期,您可以通过Information Schema视图中的TASKS_HISTORY数据统计作业量和TOP费用作业。
如果是存储费用高出预期,您可以通过下载用量明细分析存储费用变化。
如果是公网下行流量费用高出预期,您可以通过Information Schema视图中的TUNNELS_HISTORY数据统计公网下行流量费用变化。
步骤一:获取Information Schema服务
自2024年03月01日开始,MaxCompute停止对新增项目自动安装项目级别Information Schema,即新增的项目默认没有项目级别Information Schema的Package。若您有查元数据的业务,您可以查询租户级别的Information Schema,以便获取更全的信息。租户级别Information Schema的具体使用说明请参见租户级别Information Schema。
对于存量MaxCompute项目,在您开始使用Information Schema服务前,需要以项目所有者(Project Owner)或具备Super_Administrato管理角色的RAM用户身份安装Information Schema权限包,获得访问项目元数据的权限。更多为用户授权管理角色操作信息,请参见将角色赋予用户。安装方式有如下两种,更多关于Information Schema的功能及使用限制,请参见Information Schema概述。
登录MaxCompute客户端,执行如下命令:
install package Information_Schema.systables;登录DataWorks控制台,进入临时查询界面。更多临时查询操作详情,请参见使用临时查询运行SQL语句(可选)。执行如下命令:
install package Information_Schema.systables;执行示例如下。
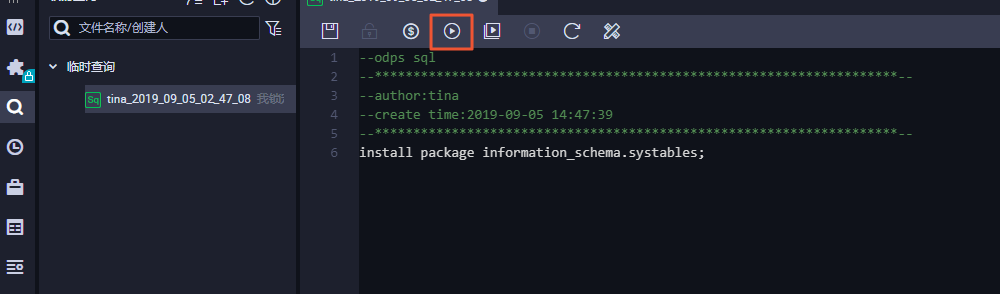
如果统计多个MaxCompute项目的元数据,您需要分别对各个MaxCompute项目安装Information Schema权限包。然后把各个MaxCompute项目的元数据的备份数据插入到同一个表中做集中统计分析。
建议您使用租户级别Information Schema服务,便于查询当前用户所有项目的元数据信息以及使用历史信息。更多信息请参见租户级别Information Schema。
(可选)步骤二:对除Project Owner外的用户授权
Information Schema的视图包含了项目级别的所有用户数据,默认项目所有者可以查看。如果项目内其他用户或角色需要查看,需要进行授权,请参见基于Package跨项目访问资源。
授权语法如下。
grant <actions> on package Information_Schema.systables to user <user_name>;
grant <actions> on package Information_Schema.systables to role <role_name>;actions:待授予的操作权限,取值为Read。
user_name:已添加至项目中的阿里云账号或RAM用户。
您可以通过MaxCompute客户端执行
list users;命令获取用户账号。role_name:已添加至项目中的角色。
您可以通过MaxCompute客户端执行
list roles;命令获取角色名称。
授权示例如下。
grant read on package Information_Schema.systables to user RAM$Bob@aliyun.com:user01;(可选)步骤三:下载并备份元数据
MaxCompute对项目内已完成的作业历史,保留近14天数据。如果您时常有查询14天以前的数据需求,建议定时备份元数据至您的项目中。如果您更多是临时查询14天以内的作业运行历史,可以忽略此步骤。
登录MaxCompute客户端或使用SQL分析连接,执行如下命令创建元数据备份表。
--project_name为MaxCompute项目名称。 --创建tasks_history备份表。 create table if not exists <project_name>.tasks_history ( task_catalog STRING ,task_schema STRING ,task_name STRING ,task_type STRING ,inst_id STRING ,status STRING ,owner_id STRING ,owner_name STRING ,result STRING ,start_time DATETIME ,end_time DATETIME ,input_records BIGINT ,output_records BIGINT ,input_bytes BIGINT ,output_bytes BIGINT ,input_tables STRING ,output_tables STRING ,operation_text STRING ,signature STRING ,complexity DOUBLE ,cost_cpu DOUBLE ,cost_mem DOUBLE ,settings STRING ,ds STRING ); --创建tunnels_history备份表 create table if not exists <project_name>.tunnels_history ( tunnel_catalog string ,tunnel_schema string ,session_id string ,operate_type string ,tunnel_type string ,request_id string ,object_name string ,partition_spec string ,data_size bigint ,block_id bigint ,offset bigint ,length bigint ,owner_id string ,owner_name string ,start_time datetime ,end_time datetime ,client_ip string ,user_agent string ,object_type string ,columns string ,ds string );进入DataWorks数据开发界面,创建ODPS SQL节点(history_backup)并配置定时调度,用于定时将数据写入备份表tasks_history和tunnels_history。完成后单击左上角
 图标保存。
图标保存。创建ODPS SQL节点操作,请参见创建ODPS SQL节点。
ODPS SQL节点运行的命令示例如下:
--project_name为MaxCompute项目名称。 use <project_name>; --备份tasks_history。 insert into table <project_name>.tasks_history select task_catalog,task_schema ,task_name,task_type STRING,inst_id,`status`,owner_id,owner_name,result,start_time,end_time,input_records,output_records,input_bytes,output_bytes,input_tables,output_tables,operation_text,signature,complexity,cost_cpu,cost_mem,settings,ds from information_schema.tasks_history where ds ='${datetime1}'; --备份tunnels_history。 insert into table <project_name>.tunnels_history select tunnel_catalog,tunnel_schema,session_id,operate_type,tunnel_type,request_id,object_name,partition_spec,data_size,block_id,offset,length,owner_id,owner_name,start_time,end_time,client_ip,user_agent,object_type,columns,ds from information_schema.tunnels_history where ds ='${datetime1}';${datetime1}为DataWorks的调度参数,您需要在ODPS SQL节点右侧,单击调度配置,在基础属性区域配置参数值为datetime1=${yyyymmdd}。说明如果需要同时对多个MaxCompute项目的元数据进行统计分析,您可以创建多个ODPS SQL节点,将这些MaxCompute项目的元数据写入到同一张数据备份表中。
步骤四:通过费用中心分析高额消费项目和计费项
进入费用中心请参见进入费用中心,在费用中心可以通过如下方式分析高额消费项目和计费项。
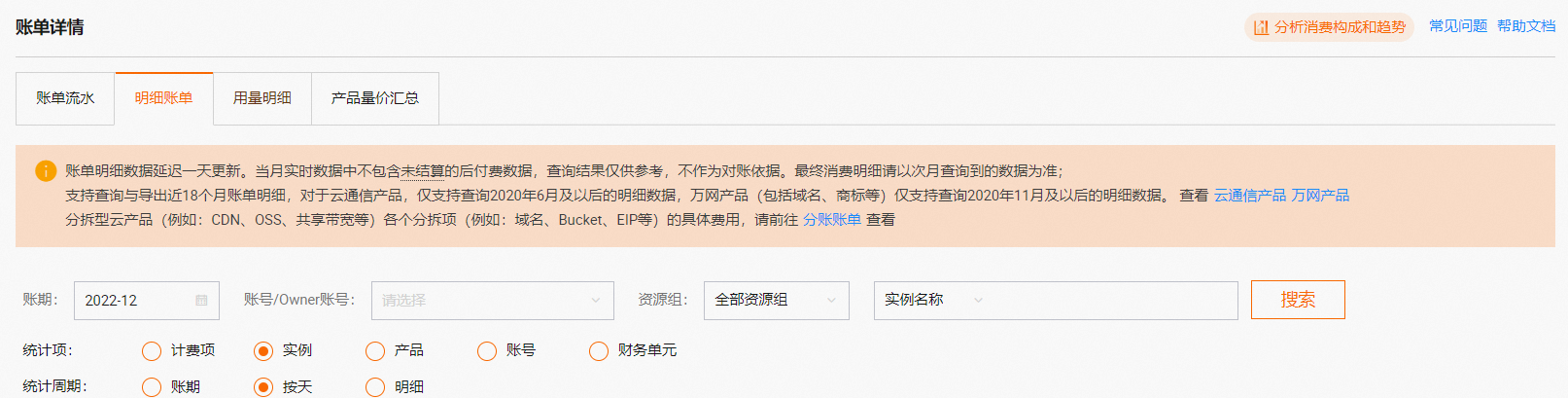
在账单详情页面的明细账单页签下,按统计项为实例、统计周期为按天进行查看,查找产生高额费用的项目(实例ID。如果有明显的某个项目消费与预期不符,则针对该项目进行分析。
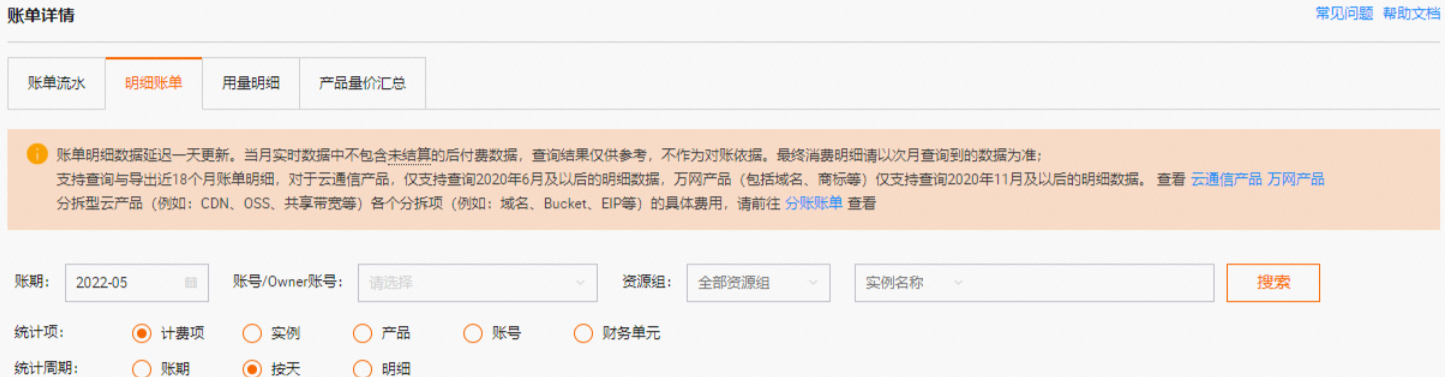
在账单详情页面的明细账单页签下,按统计项为计费项、统计周期为按天进行查看,查找产生高额费用的计费项。可以通过实例ID搜索指定的项目,针对具体项目分析具体的高额计费项。
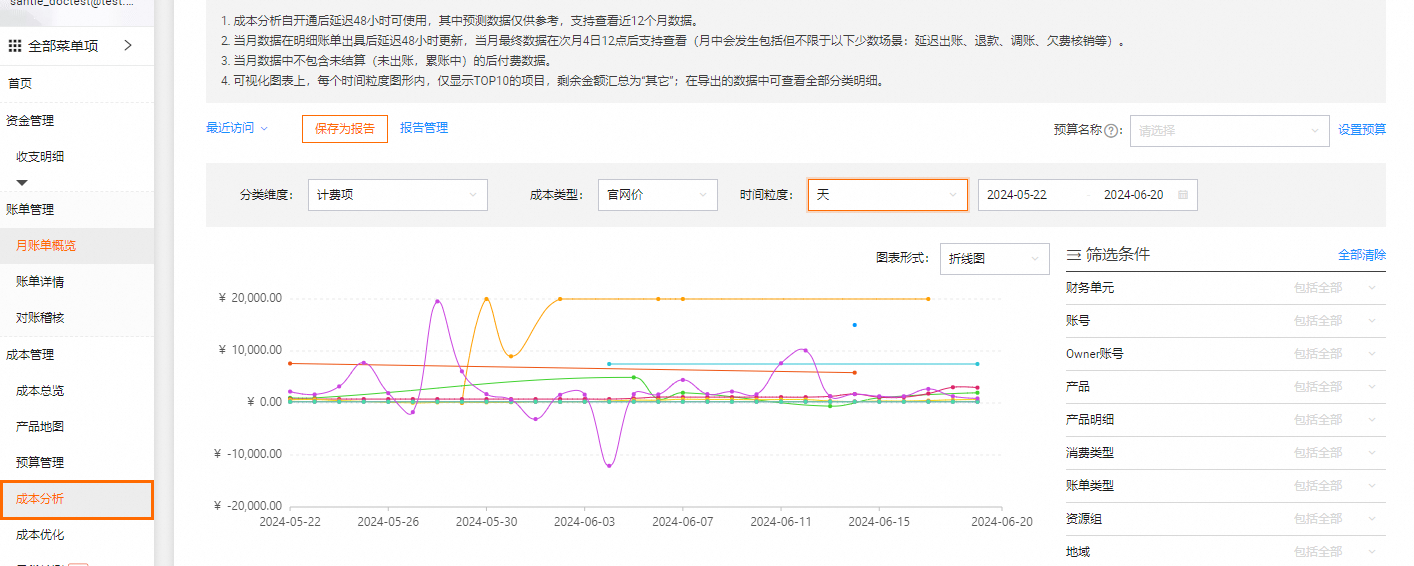
在成本分析页面也可以较为直观的查找出消费上涨的计费项。
步骤五:具体消费上涨原因排查
对高额消费项目和计费项针对性分析排查消费上涨原因。
SQL作业计算费用高出预期
SQL作业整体消费较高(包含外部表作业),可能是单条作业消费异常,也可能由于重复执行或调度属性配置不合理造成作业量突增。
可以通过查询消费异常作业的实例ID(inst_id),查看具体的执行信息。
登录MaxCompute客户端或使用SQL分析连接,使用
use命令切换到步骤四找出的高额消费的项目,通过TASKS_HISTORY查询作业消费情况,命令示例如下。--开启2.0数据类型开关。2.0数据类型详情,请参见2.0数据类型版本。 set odps.sql.decimal.odps2=true; select inst_id ---实例id ,input_bytes ---数据输入量( ,complexity ,cast(input_bytes/1024/1024/1024 * complexity * 0.3 as DECIMAL(18,5) ) cost_sum ,get_json_object(settings, "$.SKYNET_ID") SKYNET_ID ---DataWorks调度任务ID from information_schema.tasks_history --如果是查询14天前的元数据,需要查询通过步骤三备份的表,表名为<project_name>.tasks_history where task_type = 'SQL' OR task_type = 'SQLRT' AND ds = '待查询的日期分区' ORDER BY cost_sum DESC LIMIT 10000 ;说明一次SQL计算费用 = 计算输入数据量×SQL复杂度×单价(0.3 元/GB)。
示例中的
task_type = 'SQL'表示SQL作业;task_type = 'SQLRT'表示SQL查询加速作业。
查看消费较高SQL作业的
SKYNET_ID(DataWorks调度任务ID)。如果有ID,请在DataWorks上查看节点具体执行情况。
如果没有ID,说明此任务不是通过DataWorks调度节点发起的任务,可以根据
inst_id,查看具体的执行信息,命令示例如下。select operation_text from information_schema.tasks_history where ds='<任务执行所在日期分区>' and inst_id='<inst_id>';
查找运行数量较多的重复作业。
登录MaxCompute客户端或使用SQL分析连接,使用use命令切换到步骤四找出的高额消费的项目,通过TASKS_HISTORY查询重复运行的作业,命令示例如下。
--分析作业增长趋势。
SELECT signature
,ds
,COUNT(*) AS tasknum
FROM information_schema.tasks_history
--如果是查询14天前的元数据,需要查询通过步骤三备份的表,表名为<project_name>.tasks_history
where task_type = 'SQL' OR task_type = 'SQLRT'
AND ds >= '待查询的日期分区'
GROUP BY ds
,signature
ORDER BY tasknum DESC
LIMIT 10000
;
--确认异常的signature,查看对应的SQL作业近期执行情况
SELECT *
FROM information_schema.tasks_history
--如果是查询14天前的元数据,需要查询通过步骤三备份的表,表名为<project_name>.tasks_history
where signature = '异常signature'
AND ds >= '待查询的日期分区'
;Spark计算费用高出预期
Spark作业整体消费较高,可以通过查询消费异常的作业inst_id,查看具体的执行信息。
登录MaxCompute客户端或使用SQL分析连接,使用
use命令切换到步骤四找出的高额消费的项目,通过TASKS_HISTORY查询作业消费情况,命令示例如下。--开启2.0数据类型开关。2.0数据类型详情,请参见2.0数据类型版本。 set odps.sql.decimal.odps2=true; select inst_id --实例id ,cost_cpu --作业CPU消耗(100表示1 core×s。例如:10 core运行5s,cost_cpu为10×100×5=5000)。 ,cast(cost_cpu/100/3600 * 0.66 as DECIMAL(18,5) ) cost_sum from information_schema.tasks_history --如果是查询14天前的元数据,需要查询通过步骤三备份的表,表名为<project_name>.tasks_history where task_type = 'CUPID' and status='Terminated' AND ds = '待查询的日期分区' ORDER BY cost_sum DESC LIMIT 10000 ;说明Spark作业当日计算费用 = 当日总计算时×单价(0.66 元/计算时)。
task_type = 'CUPID'表示Spark作业。
根据
inst_id,查看具体的执行信息,命令示例如下。select operation_text from information_schema.tasks_history where ds='任务执行所在日期分区' and inst_id='<inst_id>';
MapReduce作业消费高出预期
MapReduce作业整体消费较高,可以通过查询消费异常的作业inst_id,查看具体的执行信息。
登录MaxCompute客户端或使用SQL分析连接,使用
use命令切换到步骤四找出的高额消费的项目,通过TASKS_HISTORY查询作业消费情况,命令示例如下。--开启2.0数据类型开关。2.0数据类型详情,请参见2.0数据类型版本。 set odps.sql.decimal.odps2=true; select inst_id --实例id ,cost_cpu --作业CPU消耗(100表示1 core×s。例如:10 core运行5s,cost_cpu为10×100×5=5000)。 ,cast(cost_cpu/100/3600 * 0.46 as DECIMAL(18,5) ) cost_sum from information_schema.tasks_history --如果是查询14天前的元数据,需要查询通过步骤三备份的表,表名为<project_name>.tasks_history where task_type = 'LOT' and status='Terminated' AND ds = '待查询的日期分区' ORDER BY cost_sum DESC LIMIT 10000 ;说明MapReduce作业当日计算费用 = 当日总计算时×单价(0.46 元/GB)。
task_type = 'LOT'表示MapReduce作业。
根据
inst_id,查看具体的执行信息,命令示例如下。select operation_text from information_schema.tasks_history where ds='任务执行所在日期分区' and inst_id='<inst_id>';
存储费用高出预期
需要使用用量明细查询存储费用。
下载用量明细,详情请参见下载用量明细。
上传用量明细,详情请参见上传用量明细数据至MaxCompute。
通过SQL分析,详情请参见MaxCompute账单用量明细分析。
公网下行流量费用高出预期
公网下行流量整体消费较高,可以按照如下操作分析具体哪段时间哪个类别的下载费用较高。
登录MaxCompute客户端或使用SQL分析连接,使用use命令切换到步骤四找出的高额消费的项目,通过TUNNELS_HISTORY查询下载消费情况,命令示例如下。
--开启2.0数据类型开关。2.0数据类型详情,请参见2.0数据类型版本。
set odps.sql.decimal.odps2=true;
SELECT ds
,operate_type
,SUM(CAST(data_size / 1024 / 1024 / 1024 * 0.8 AS DECIMAL(18,5))) download_fee
FROM information_schema.tunnels_history
WHERE operate_type = 'DOWNLOADLOG'
OR operate_type = 'DOWNLOADINSTANCELOG'
AND ds >= '待查询的日期分区'
GROUP BY ds
,operate_type
ORDER BY download_fee DESC
;一次下载费用=下载数据量×单价(0.8 元/GB)。
按照执行结果也可以分析出某个时间段内的下载费用走势。另外可以通过tunnel show history命令查看具体历史信息,具体命令请参见Tunnel命令。
更多信息
如果您想了解更多关于费用成本优化的文章,请参见成本优化概述。