本文介绍如何通过数据集成功能同步LogHub数据至MaxCompute。
背景信息
日志服务支持以下数据同步场景:
-
跨地域的LogHub与MaxCompute等数据源的数据同步。
-
不同阿里云账号下的LogHub与MaxCompute等数据源间的数据同步。
-
同一阿里云账号下的LogHub与MaxCompute等数据源间的数据同步。
-
公共云与金融云账号下的LogHub与MaxCompute等数据源间的数据同步。
以B账号进入数据集成配置同步任务,将A账号的LogHub数据同步至B账号的MaxCompute为例,跨阿里云账号的特别说明如下:
-
使用A账号的AccessKey ID和AccessKey Secret创建LogHub数据源。
此时B账号可以同步A账号下所有日志服务项目的数据。
-
使用A账号下的RAM用户A1的AccessKey ID和AccessKey Secret创建LogHub数据源。
-
A账号为RAM用户A1赋予日志服务的通用权限,即
AliyunLogFullAccess和AliyunLogReadOnlyAccess,详情请参见创建RAM用户及授权。说明为RAM账号授予
AliyunLogFullAccess和AliyunLogReadOnlyAccess系统策略后,RAM账号可以查询主账号下的所有日志服务。 -
A账号给RAM用户A1赋予日志服务的自定义权限。
主账号A进入页面,单击创建权限策略。
根据下述策略进行授权后,B账号通过RAM用户A1只能同步日志服务project_name1以及project_name2的数据。
{ "Version": "1", "Statement": [ { "Action": [ "log:Get*", "log:List*", "log:CreateConsumerGroup", "log:UpdateConsumerGroup", "log:DeleteConsumerGroup", "log:ListConsumerGroup", "log:ConsumerGroupUpdateCheckPoint", "log:ConsumerGroupHeartBeat", "log:GetConsumerGroupCheckPoint" ], "Resource": [ "acs:log:*:*:project/project_name1", "acs:log:*:*:project/project_name1/*", "acs:log:*:*:project/project_name2", "acs:log:*:*:project/project_name2/*" ], "Effect": "Allow" } ] }
-
新建LogHub数据源
-
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入管理中心。
-
单击左侧导航栏中的数据源。
-
在数据源列表页面,单击新增数据源。
-
在新增数据源对话框中,选择数据源类型为LogHub。
-
填写新增LogHub数据源对话框中的配置。
参数
描述
数据源名称
数据源名称必须以字母、数字、下划线组合,且不能以数字和下划线开头。
数据源描述
对数据源进行简单描述,不得超过80个字符。
LogHub Endpoint
LogHub的Endpoint,格式为
http://example.com。详情请参见服务入口。Project
输入项目名称。
AccessKey ID
访问密钥中的AccessKey ID,您可以进入控制台的用户信息管理页面进行复制。
AccessKey Secret
访问密钥中的AccessKey Secret,相当于登录密码。
-
单击测试连通性。
-
连通性测试通过后,单击完成。
新建离线同步节点
-
在数据源页面,单击左上角的
 图标,选择。
图标,选择。 -
在数据开发页面,鼠标悬停至
 图标,单击业务流程。
图标,单击业务流程。 -
在新建业务流程对话框中,输入业务流程名称和描述,单击新建。
-
展开业务流程,右键单击数据集成,选择。
-
在新建节点对话框中,输入节点名称,并选择路径。
-
单击确认,进入离线节点编辑页面。
通过向导模式配置同步任务
-
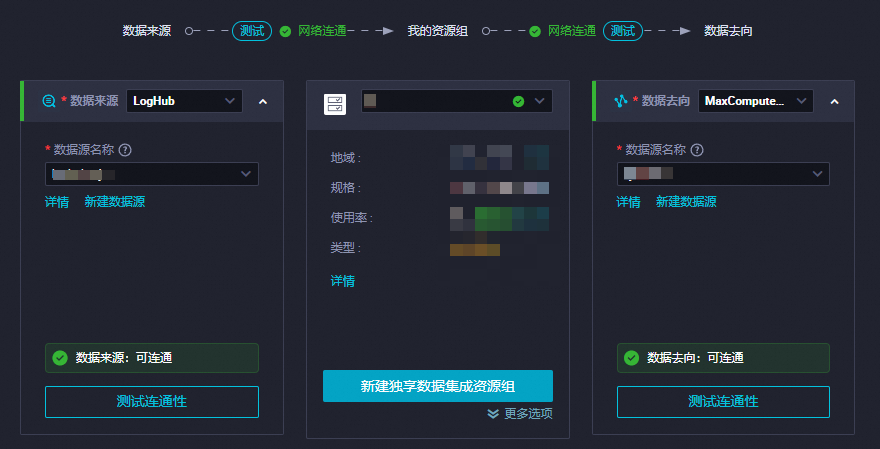
在离线节点编辑页面,选择数据来源和数据去向。
参数
描述
数据来源
选择LogHub。
数据源名称
选择以添加的日志服务数据源名称。
资源组
选择独享数据集成资源组。
数据去向
选择MaxCompute。
数据源名称
选择以添加的MaxCompute数据源名称。
-
测试网络连通性,数据来源和数据去向均可连通后,点击下一步。
-
配置数据来源与数据去向具体同步的表等信息。
数据来源参数说明:
参数
描述
Logstore
目标日志库的名称。
日志开始时间
数据消费的开始时间位点,为时间范围(左闭右开)的左边界,为yyyyMMddHHmmss格式的时间字符串(例如20180111013000)。该参数可以和DataWorks的调度时间参数配合使用。
日志结束时间
数据消费的结束时间位点,为时间范围(左闭右开)的右边界,为yyyyMMddHHmmss格式的时间字符串(例如20180111013010)。该参数可以和DataWorks的调度时间参数配合使用。
批量条数
一次读取的数据条数,默认为256。
说明您可以进行数据预览,此处仅选择LogHub中的几条数据展现在预览框。由于您在进行同步任务时,会指定开始时间和结束时间,会导致预览结果和实际的同步结果不一致。
-
选择字段的映射关系。
-
在通道控制中配置同步速率和脏数据策略等参数。
-
单击右侧调度配置,配置重跑属性、调度资源组以及依赖的上游节点等参数。
说明依赖的上游节点配置为使用工作空间根节点。
-
确认当前节点的配置无误后,单击左上角的
 。
。 -
运行离线同步节点。
您可以通过以下两种方式运行离线同步节点:
-
直接运行(一次性运行)
单击节点编辑页面工具栏中的
 图标,直接在页面运行。 说明
图标,直接在页面运行。 说明运行之前需要配置自定义参数的具体取值。
-
调度运行
-
单击右侧调度配置,设置时间属性,配置调度周期。
-
单击节点编辑页面工具栏中的
 图标,然后单击图标,提交离线同步节点至调度系统,调度系统会根据配置的属性,从第2天开始自动定时运行。
图标,然后单击图标,提交离线同步节点至调度系统,调度系统会根据配置的属性,从第2天开始自动定时运行。
-
-
 图标,然后单击
图标,然后单击 图标,提交离线同步节点至调度系统,调度系统会根据配置的属性,从第2天开始自动定时运行。
图标,提交离线同步节点至调度系统,调度系统会根据配置的属性,从第2天开始自动定时运行。通过脚本模式配置离线同步节点
-
成功创建离线同步节点后,单击工具栏中的转换脚本。
-
单击提示对话框中的确认,即可进入脚本模式进行开发。
-
单击工具栏中的导入模板。
-
在导入模板对话框中,选择从来源端的LogHub数据源同步至目标端的ODPS数据源的导入模板,单击确认。
-
导入模板后,根据自身需求编辑代码,示例脚本如下。
{ "type": "job", "version": "1.0", "configuration": { "reader": { "plugin": "loghub", "parameter": { "datasource": "loghub_lzz",//数据源名,需要和您添加的数据源名一致。 "logstore": "logstore-ut2",//目标日志库的名字,LogStore是日志服务中日志数据的采集、存储和查询单元。 "beginDateTime": "${startTime}",//数据消费的开始时间位点,为时间范围(左闭右开)的左边界。 "endDateTime": "${endTime}",//数据消费的结束时间位点,为时间范围(左闭右开)的右边界。 "batchSize": 256,//一次读取的数据条数,默认为256。 "splitPk": "", "column": [ "key1", "key2", "key3" ] } }, "writer": { "plugin": "odps", "parameter": { "datasource": "odps_source",//数据源名,需要和您添加的数据源名一致。 "table": "test",//目标表名。 "truncate": true, "partition": "",//分区信息。 "column": [//目标列名。 "key1", "key2", "key3" ] } }, "setting": { "speed": { "mbps": 8,//作业速率上限,单位MB/s。 "concurrent": 7//并发数。 } } } }