
本文介绍Append Delta Table在数据组织优化服务上的架构设计。
概述
Append Delta Table创新表格式的数据组织底层采用Range Clustering结构,默认使用Row_ID作为Cluster Key,Bucket数量会随着用户数据增长动态分配。在用户指定Cluster Key之后,后台Clustering作业会对数据执行增量Reclustering,从而保证数据的整体有序性。
Append Delta Table在复杂业务场景上表现优秀,显著的效能提升也反映出数据存储格式的技术优化在大数据分析场景下的核心价值。其技术价值及性能优化总结如下:
数据自治:通过Merge、Compaction、Reclustering等后台任务,实现存储效率与查询性能的动态平衡。
弹性扩展:动态Bucketing 与 Auto-Split/Merge策略,支持从TB到EB级数据的无缝扩展。
实时Clustering:增量Reclustering在ODS层实现毫秒级数据新鲜度与Clustering查询加速。
动态Bucket优化(Dynamic Bucketing)
面临挑战
在创建Range/Hash Cluster表时,用户需要提前评估对应业务的数据规模,以此为依据设置合适的Bucket数量和Cluster key。完成Cluster表创建后,MaxCompute通过Clustering算法将数据按照Cluster Key路由到各自对应的Bucket中。
这可能会导致出现如下两种情况:
数据倾斜:当数据量太多而Bucket数量太少时,会导致单个Bucket内数据量过大,在执行查询时,对数据的裁剪效果不佳。
数据碎片:反之,如果设置的Bucket数量远远大于业务数据量所需要的范围,会导致每个Bucket内数据量太少而产生大量碎片文件,也会影响查询性能。
因此,在创建表时显示指定Bucket数量会抬升用户的使用门槛。根据业务的数据量预设合适的Bucket数量,要求用户同时对业务本身的使用模式和MaxCompute底层表格式都有一定的理解,然后才能够正确使用Clustering的相关能力并最大化查询性能收益:
面对大规模数据迁移场景,用户需要评估每一张表的潜在业务使用规模。如果表的数量比较少,评估工作还可能通过专项推进;但是当面对成千上万张表时,评估每一张表的数据规模会变得非常难以执行。
即使用户对表的数据规模在当下做了准确的评估,但是随着业务自身的演进,实际的数据规模也会持续变化,之前适用的Bucket数量设置在未来也可能不再适用。
综上所述,静态的Bucket数量配置无论是在大规模数据迁移场景,还是在业务快速变化的日常使用环境中,都难以做出有效的支撑。更合理的方式,是平台根据用户实际数据量大小,动态地设置所需要的Bucket数量。用户无需感知底层的Bucket数量,一方面降低用户的学习和使用门槛,另一方面更好地适应不断变化的数据规模。
解决方案
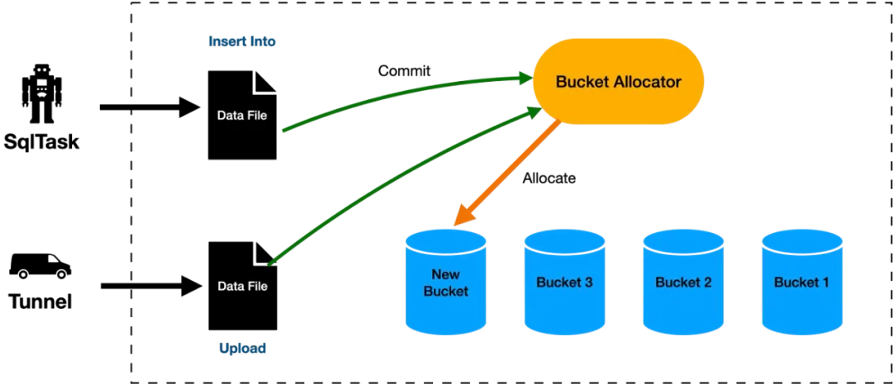
Append DeltaTable表格式在设计之初就支持Bucket的动态分配,所有存储在表中的数据都被自动划分为Bucket,每一个Bucket都是一个逻辑上连续的存储单元,包含500MB左右的数据。
用户在创建和写入数据之前,并不需要在表层面指定Bucket的数量,随着用户数据的持续写入,会自动按需创建出新的Bucket。用户并不需要担心随着数据量的增加或者减少,导致Bucket内数据量过大或者过小导致的数据倾斜和数据碎片问题。
工作流程图如下:
增量重聚簇(Incremental Reclustering)
面临挑战
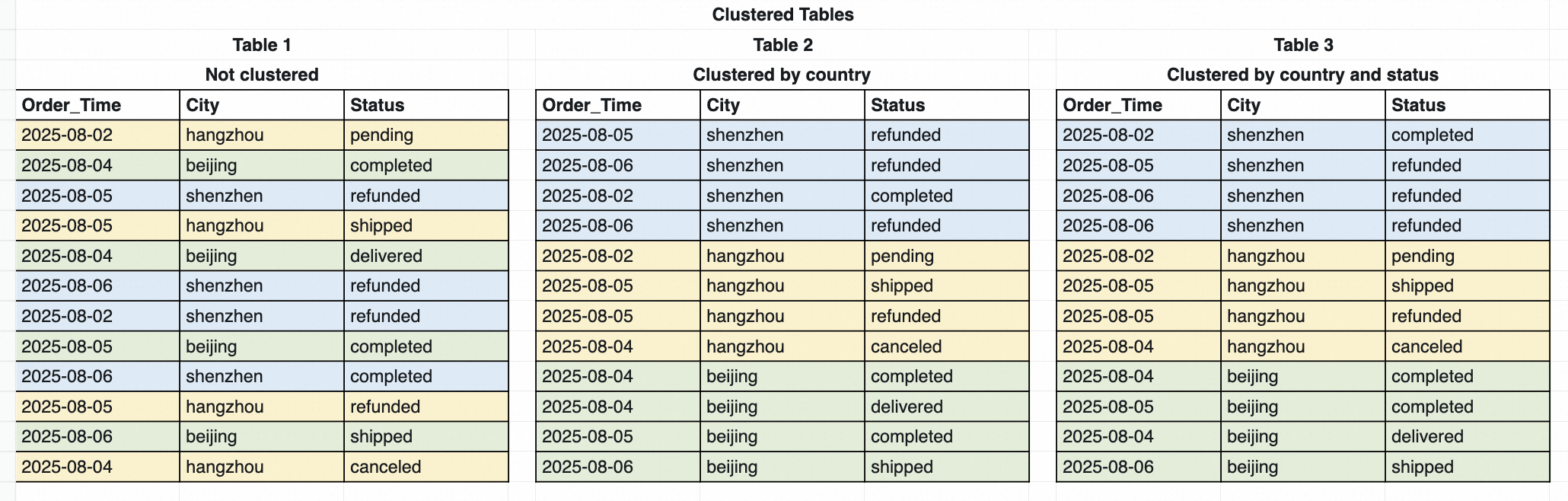
Clustering是数据领域最常见的数据优化手段之一,Cluster Key是用户指定的表属性,通过排序并连续存储用户指定的数据字段,当用户查询Cluster Key时,可以通过下推、裁剪等优化方式,缩小数据扫描的范围,从而达到提升查询效率的目的。
MaxCompute之前提供了Range/Hash Clustering两种Clustering能力,支持通过Range或者Hash两种方式对数据分桶,并对单个桶内的数据排序,通过对查询过程中Bucket和单个桶内数据的裁剪,达到查询加速的效果。如下图所示:
问题1:数据追加代价大
Range/Hash Clustering的表能力存在一个限制是,数据必须在写入过程中就完成数据的分桶与排序,从而达到全局有序的状态。因此限制了数据写入的方式,要求数据必须以插入或覆写数据(INSERT INTO | INSERT OVERWRITE)的形式一次性写入,在写入完成后,如果需要再进一步追加数据,则需要将表中原有的数据全部读取,与新增数据并集(UNION)之后再次写入,数据追加代价非常大,效率很低。
一般来说,业务通常不会对ODS层的数据表使用Clustering,原因在于ODS层的数据比较接近原始的业务数据,通常是通过外部的采集链路持续导入的,对数据导入的性能有很高的要求,而原有Clustering表代价巨大的写入模式无法满足低延迟高吞吐的写入要求。
问题2:DW层数据新鲜度延迟
因此业务侧往往倾向于在DW层的表中设置Cluster Key,前一个业务日期完成数据导入的ODS表,会在数据清洗后,导入到新的数据相对稳定的DW层,进而加速后续的查询业务性能。
但是这种方案带来的问题在于,DW层数据的新鲜度上会存在一定的延迟,为了避免反复更新DW层带来的读写放大,DW层的更新通常在ODS 层数据稳定后才进行,这导致通过DW层查询到的数据在业务日期上是存在滞后的。然而在有些场景中,业务方对查询性能和数据新鲜度都有着非常极致的要求,希望能够在ODS层之间实现Clustering,加速查询ODS表数据,获取实时信息。
因此,原本MaxCompute提供的在写入数据时同步执行Clustering的方案无法在数据的实时性上满足用户诉求。
解决方案
Append DeltaTable的增量Clustering能力,通过后台数据服务异步执行增量Clustering,在数据导入性能、数据实时性以及数据查询性能上做到了最大限度的平衡。
如下图所示,用户通过Streaming写入方式将数据导入MaxCompute。写入阶段为了最大限度保障写入延迟与吞吐,数据直接以未排序的方式落盘,被分配到Bucket中。此时由于新写入到Bucket的数据没有执行Clustering操作,新增Bucket在数据范围上会和其他已经完成Clustering的 Bucket产生重叠。在执行查询任务时,SQL 引擎对Clustered Bucket执行Bucket 裁剪,对增量Bucket则执行扫描。
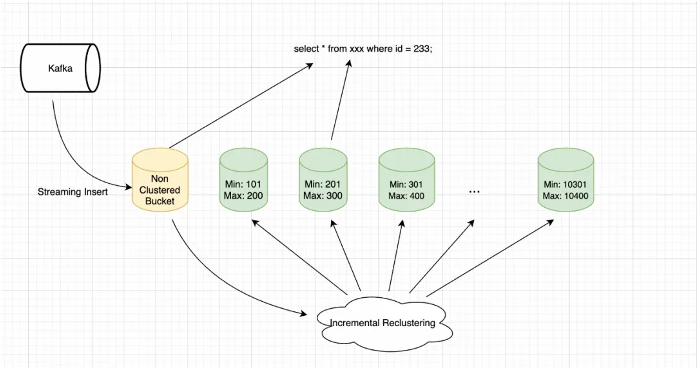
MaxCompute后台数据服务持续对Bucket Overlap Depth监控,当Overlap达到特定阈值后触发增量Reclustering,对新写入的Bucket执行 Reclustering操作,确保用户数据的主体部分始终维持在一个有序状态,从而确保了整体查询性能的稳定。