
本文为您介绍Delta Table在数据组织优化服务上的架构设计。
背景介绍
Delta Table是MaxCompute推出的增量数据表格式,支持分钟级近实时增量数据导入,高流量场景下可能会存在增量小文件数量膨胀,过多的中间状态冗余等问题。为了降低存储压力和计算成本,提高分析执行和数据读写速度,MaxCompute提供了三种优化服务,包括小文件合并Clustering(小文件合并)、数据COMPACTION和数据回收。
Clustering(小文件合并)
面临挑战
Delta Table支持分钟级近实时增量数据导入,高流量场景下可能会导致增量小文件数量膨胀。这种情况会引发以下问题:
存储成本高、访问压力大。
大量的小文件还会引发Meta更新。
分析执行速度变慢,数据读写I/O效率低下。
因此需要设计合理的小文件合并服务,即Clustering服务来自动优化此类场景。
解决方案
Clustering服务主要由MaxCompute内部的Storage Service来负责执行,专门解决小文件合并的问题。Clustering并不会改变任何数据的历史中间状态,即不会消除任何一条记录数据的中间历史状态。
工作流程
Clustering服务的整体操作流程如图所示。
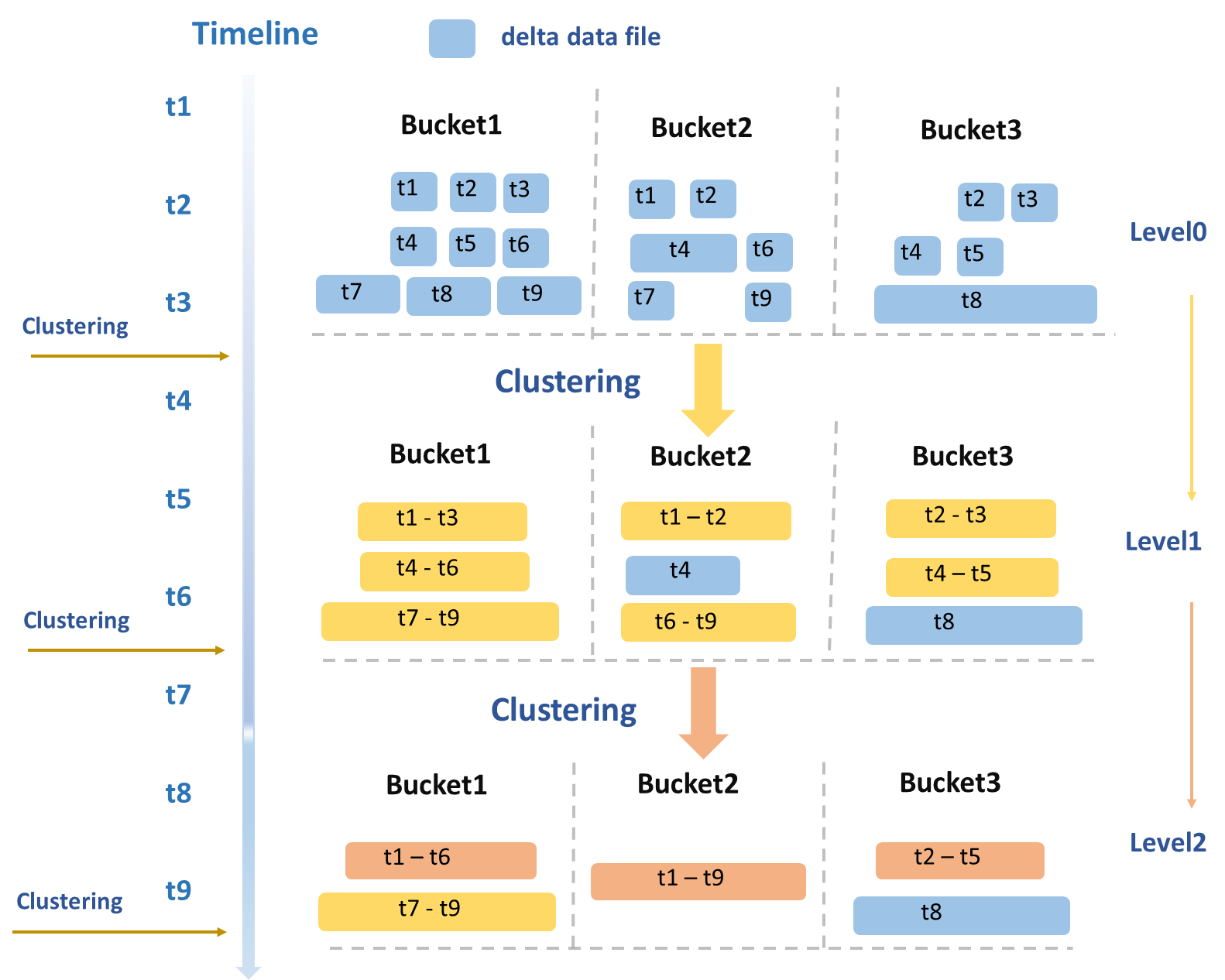
分层次合并
Clustering策略的制定主要基于典型的读写业务场景,会周期性地根据数据文件的大小、数量等多个维度综合评估,并进行分层次的合并。
Level 0 → Level 1:原始写入的、最小的DeltaFile(图中蓝色数据文件)被合并成中等大小的DeltaFile(图中黄色数据文件)。
Level 1 → Level 2:当中等大小的DeltaFile达到一定规模后,会触发更高层级的合并,生成更大的优化文件(图中橙色数据文件)。
避免读写放大
大文件隔离:体积超过一定大小的数据文件(如Bucket3中的T8文件)会被专门隔离处理并排除在合并之外。
时间跨度限制:时间跨度过大的文件也不会被合并,避免在进行Time Travel或者增量查询时读取大量不属于此次查询时间范围的历史数据。
自动触发执行:每次执行Clustering至少需要读写一遍数据,消耗计算和I/O资源,存在一定的读写放大问题。为了确保Clustering服务的高效执行,当前MaxCompute引擎能够根据系统状态自动触发执行。
并发与事务性
并发执行:由于数据按照BucketIndex来切分存储,因此Clustering服务会以Bucket粒度来并发执行,大幅缩短整体运行时间。
事务保证:Clustering服务会与Meta Service进行交互,以获取待处理的表或分区列表。完成操作后,会将新旧数据文件的信息传入Meta Service。Meta Service在此过程中起到关键作用,它负责进行事务冲突检测,协调新旧文件Meta信息的无缝更新以及安全地回收旧数据文件。
Compaction
面临挑战
Delta Table支持UPDATE和DELETE操作。这些操作通过写入新的记录来标记旧记录的状态,而非原地修改。大量此类操作会导致:
数据冗余:中间状态的冗余记录过多,增加存储和计算成本。
查询效率降低
因此需要设计合理的Compaction服务,以消除中间状态并优化此类场景。
解决方案
Compaction会把选中的数据文件,包含BaseFile和DeltaFile,将其中同一主键的多条记录合并,消除数据的UPDATE和DELETE中间状态,只保留最新状态的一行记录,最后生成新的只包含INSERT类型数据的数据文件BaseFile。
工作流程
Compaction服务的整体操作流程如下所示。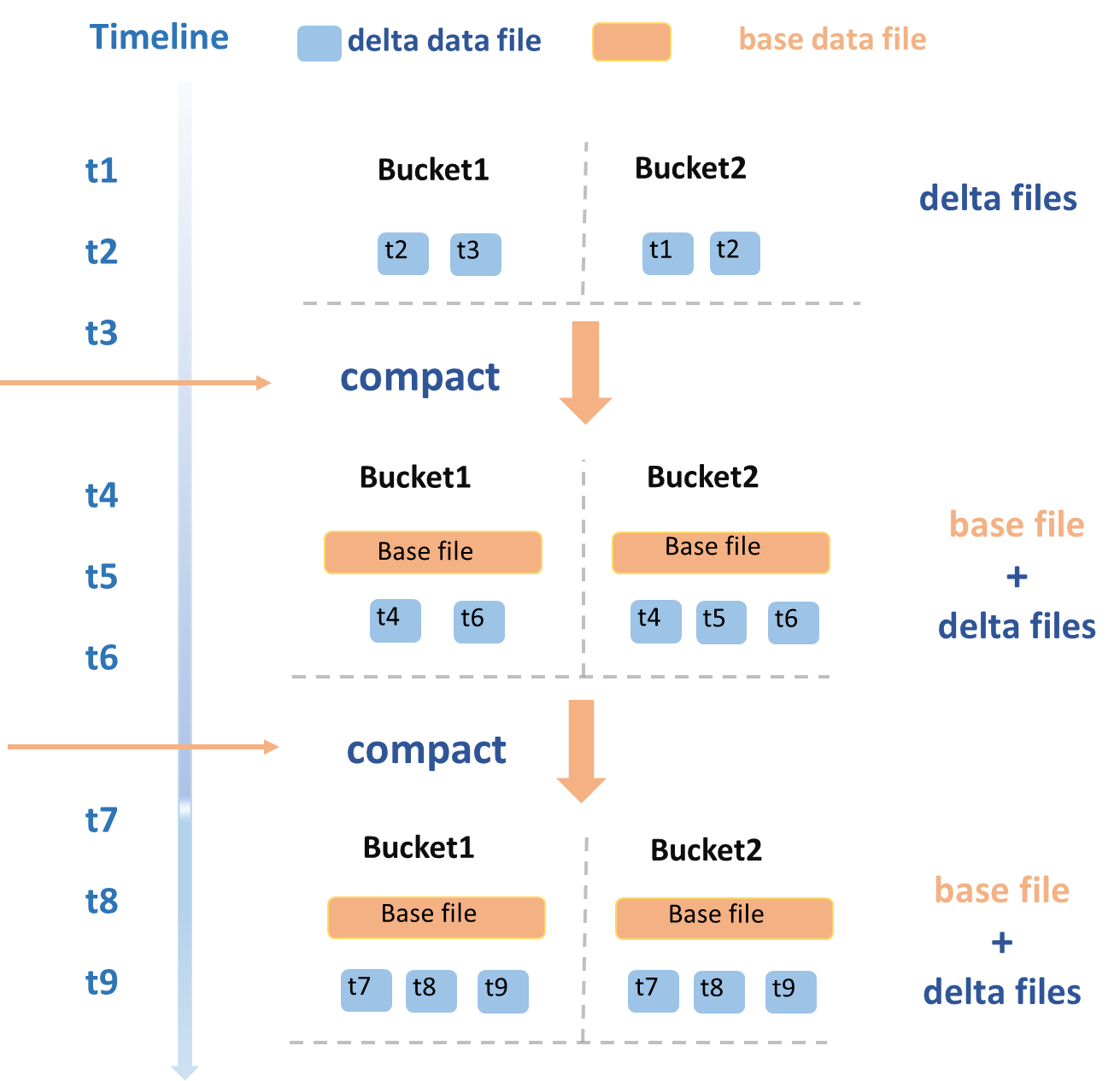
合并DeltaFile
t1~t3时间段,新写入的一批DeltaFile触发Compaction操作,以Bucket粒度并发执行,合并生成了新的BaseFile,每个Bucket会生成新的BaseFile。
t4和t6时间段,又写入了一批新的DeltaFile,再次触发Compaction操作,将当前存在的BaseFile和新增的DeltaFile一起合并,重新生成一个新的BaseFile。
事务保证
Compaction服务还需要与Meta Service进行交互。其流程与Clustering类似,需要获取需要执行此操作的表或分区的列表。执行结束后,将新旧数据文件的信息传入Meta Service。其中,Meta Service负责Compaction操作的事务冲突检测、新旧文件Meta信息的原子更新以及旧数据文件的回收等工作。
执行频率
Compaction服务通过消除记录的历史状态以节省计算和存储资源,提升全量快照查询的效率。然而,频繁执行Compaction需要大量计算和I/O资源,并可能导致新BaseFile占用额外存储,历史DeltaFile文件可能会被用于Time Travel查询,不能立即删除,将继续产生存储成本。
因此,应根据具体业务需求和数据特性来决定Compaction操作的执行频率。在Update和Delete操作频繁以及全量查询需求高的情况下,可以考虑增加Compaction的频率以优化查询速度。
数据回收
由于Time Travel和增量查询都会查询数据的历史状态,因此Delta Table会在一定时间内保留数据的历史版本。
回收策略:可通过表属性
acid.data.retain.hours来配置数据保留的时间范围。如果历史状态数据存在的时间早于配置值,系统会开始自动回收清理,一旦清理完成,该历史版本将无法再通过Time Travel查询到。回收的数据主要包含操作日志和数据文件。说明对于Delta Table,如果用户一直写入新的DeltaFile,那永远也删除不了任何一个DeltaFile,因为其他的DeltaFile可能对它有状态依赖。只有执行COMPACTION或者InsertOverwrite操作后,之后产生的数据文件对之前的那些DeltaFile就没有依赖了,如果超过Time Traval可查询的时间周期后,就可以被删除了。
强制清理:在特殊场景下,可通过
PURGE命令来手动触发强制的历史数据清理。自动机制:为避免因长期不执行Compaction而导致历史数据无限增长的极端情况,MaxCompute引擎侧也做了一些优化。后台系统会周期性地对超过Time Travel时间的BaseFile或者DeltaFile进行自动Compaction,以确保回收机制的正常运行。