
如果您需要将外部存储上的数据导入MaxCompute的表或表的分区中,可以通过LOAD命令实现该操作。本文为您介绍如何使用LOAD命令将外部存储上的CSV格式或其他开源格式数据导入MaxCompute。
本文中的命令您可以在如下工具平台执行:
功能介绍
MaxCompute支持使用load overwrite或load into命令将Hologres、OSS、Amazon Redshift、BigQuery外部存储的CSV格式或其他开源格式数据导入MaxCompute的表或表的分区。其中:
Amazon Redshift和BigQuery的数据需要先导入OSS,才可以通过OSS导入MaxCompute。
MaxCompute支持将数据按照动态分区方式导入MaxCompute的分区表的分区。
load into命令会直接向表或分区中追加数据。load overwrite命令会先清空表或分区中的原有数据,再向表或分区中插入数据。
使用限制
当前只支持将外部存储的数据导入至同区域的MaxCompute项目空间中。
通过OSS导入数据时:
导入到目标MaxCompute分区表时,目标表的Schema(除分区列)需要和外部数据格式一致,且外部数据的Schema不包含分区列。
通过Hologres导入数据时:
不支持将Hologres分区表数据导入MaxCompute。
不支持使用双签名授权模式的Hologres外表导入数据至MaxCompute。
前提条件
操作账号已具备MaxCompute的相关权限。
执行
load操作前,操作账号需要具备MaxCompute项目空间创建表权限(CreateTable)及修改表权限(Alter)。授权操作请参见MaxCompute权限。操作账号已具备外部存储数据对应数据源的相关权限。
向MaxCompute导入外部存储数据前,您需要先对MaxCompute进行授权,允许MaxCompute访问外部存储(OSS或Hologres)。
load overwrite或load into命令的授权模式沿用了MaxCompute外部表的授权模式,OSS和Hologres的授权引导如下。外部存储:OSS
您可以一键授权,具备更高安全性。详情请参见STS模式授权。
外部存储:Hologres
您可创建一个RAM角色,为其授权允许MaxCompute访问的权限,并将角色添加至Hologres实例,完成授权,操作详情请参见创建Hologres外部表(STS模式)。
完成上述授权的前期准备后,您需要根据导入数据的格式类型,选择对应的导入方式:
通过内置Extractor(StorageHandler)导入数据
命令格式
{load overwrite|into} table <table_name> [partition (<pt_spec>)] from location <external_location> stored by <StorageHandler> [with serdeproperties (<Options>)];参数说明
外部存储:OSS
table_name:必填。需要插入数据的目标表名称。目标表需要提前创建,目标表的Schema(除分区列)需要和外部数据格式一致。
pt_spec:可选。需要插入数据的目标表分区信息。格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。external_location:必填。指定读取外部存储数据的OSS目录,格式为
'oss://<oss_endpoint>/<object>',详情请参见通过IPv6协议访问OSS,系统会默认读取该目录下所有的文件。StorageHandler:必填。指定内置的StorageHandler名称。
com.aliyun.odps.CsvStorageHandler是内置的处理CSV格式文件的StorageHandler,定义了如何读或写CSV文件。您只需要指定该参数,相关逻辑已经由系统实现。使用方法和MaxCompute外部表一致,详情请参见创建OSS外部表。Options:可选。指定外部表相关参数,SERDEPROPERTIES支持的属性和MaxCompute外部表一致,属性列表详情请参见创建OSS外部表。
外部存储:Hologres
table_name:必填。需要插入数据的目标表名称。目标表需要提前创建,目标表的Schema(除分区列)需要和外部数据格式一致。
pt_spec:可选。需要插入数据的目标表分区信息。格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。external_location:必填。指定Hologres的JDBC连接地址,格式为
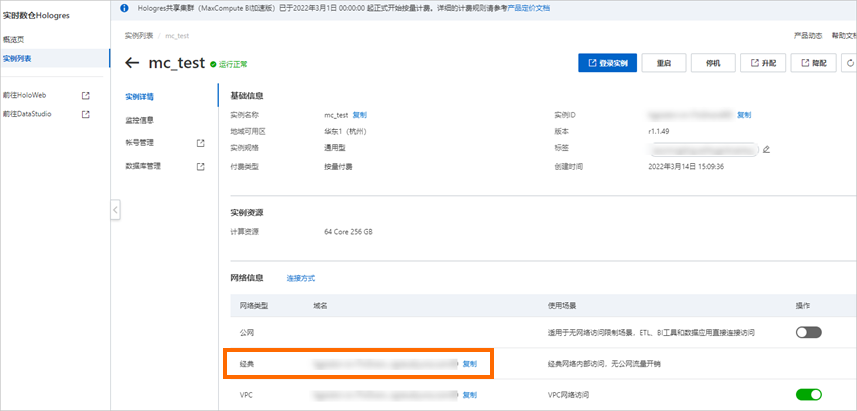
'<jdbc:postgresql://<endpoint>:<port>/<database>?ApplicationName=MaxCompute&[currentSchema=<schema>&][useSSL={true|false}&]table=<holo_table_name>/>'。endpoint:必填。Hologres实例的经典网络域名。获取方式,请参见实例配置。
重要目前仅支持通过经典网络域名进行访问。不支持通过VPC 网络域名访问Hologres。
port:必填。Hologres实例的网络端口。获取方式,请参见实例配置。
database:必填。连接的Hologres数据库名称。更多Hologres数据库信息,请参见CREATE DATABASE。
ApplicationName:必填。默认为MaxCompute,无需修改。
schema:可选。如果表名在Hologres数据库内是唯一的,或源表是默认Schema中的表,可以不配置该属性。更多Schema信息,请参见CREATE SCHEMA。
holo_table_name:必填。Hologres源表名称。更多Hologres源表信息,请参见CREATE TABLE。
StorageHandler:必填。定义了如何查询Hologres外部表。固定取值为
com.aliyun.odps.jdbc.JdbcStorageHandler,使用JdbcStorageHandler连接方式。tblproperties必填。指定外部表相关参数,SERDEPROPERTIES支持的属性和MaxCompute外部表一致。
mcfed.mapreduce.jdbc.driver.class:必填。指定连接Hologres数据库的驱动程序。固定取值为
org.postgresql.Driver。odps.federation.jdbc.target.db.type:必填。指定连接的数据库类型。固定取值为
holo。odps.federation.jdbc.colmapping:可选。如果需要将指定数据源的部分列映射至Hologres外部表,需要配置该参数,指定Hologres源表的字段和Hologres外部表字段的映射关系。
若未配置该参数,按照源表字段名映射至Hologres外部表同名列。
若配置该参数,但是只指定Hologres外部表部分列的映射关系,则按照源表字段名映射至Hologres外部表同名列,其他未指定的列,列名或类型不匹配会报错。
若配置该参数,Hologres里的字段名称存在大写的情形,需要为Hologres字段名称添加双引号(
"")。格式为:MaxCompute字段1 : "Hologres字段1"[ ,MaxCompute字段2 : "Hologres字段2" ,...]。说明Hologres源表字段是
c bool, map_B string, a bigint。Hologres外部表字段是a bigint, x string, c bool。colmapping配置的内容是'x: "map_B"',则可以成功映射并查询Hologres数据。
mcfed.mapreduce.jdbc.input.query:可选。读取Hologres数据源表数据。外部表的列、列名与直接查询的Hologres数据源表的列、列名及数据类型保持一致。如果使用了别名,则与别名保持一致。
select_sentence格式为SELECT xxx FROM <holo_database_name>.<holo_schema_name>.<holo_table_name>。
使用示例
外部存储:OSS
通过内置Extractor(StorageHandler)导入数据。假设MaxCompute和OSS的Owner是同一个账号,通过阿里云内网将vehicle.csv文件的数据导入MaxCompute。
将vehicle.csv文件保存至OSS Bucket目录下
mc-test/data_location/,地域为oss-cn-hangzhou,并组织OSS目录路径。创建OSS Bucket详情请参见创建存储空间。vehicle.csv文件数据如下:
1,1,51,1,46.81006,-92.08174,9/14/2014 0:00,S 1,2,13,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,3,48,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,4,30,1,46.81006,-92.08174,9/14/2014 0:00,W 1,5,47,1,46.81006,-92.08174,9/14/2014 0:00,S 1,6,9,1,46.81006,-92.08174,9/14/2014 0:00,S 1,7,53,1,46.81006,-92.08174,9/14/2014 0:00,N 1,8,63,1,46.81006,-92.08174,9/14/2014 0:00,SW 1,9,4,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,10,31,1,46.81006,-92.08174,9/14/2014 0:00,N根据Bucket、地域、Endpoint信息组织OSS目录路径如下:
oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-test/data_location/登录MaxCompute客户端创建目标表ambulance_data_csv_load。命令示例如下:
create table ambulance_data_csv_load ( vehicleId INT, recordId INT, patientId INT, calls INT, locationLatitute DOUBLE, locationLongtitue DOUBLE, recordTime STRING, direction STRING );执行
load overwrite命令,将OSS上的vehicle.csv文件导入目标表。命令示例如下:load overwrite table ambulance_data_csv_load from location 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-test/data_location/' stored by 'com.aliyun.odps.CsvStorageHandler' with serdeproperties ( 'odps.properties.rolearn'='acs:ram::xxxxx:role/aliyunodpsdefaultrole', --AliyunODPSDefaultRole的ARN信息,可通过RAM角色管理页面获取。 'odps.text.option.delimiter'=',' );查看角色的ARN信息请参见查看RAM角色。
查看目标表ambulance_data_csv_load的导入结果。命令示例如下:
--开启全表扫描,仅此Session有效。 set odps.sql.allow.fullscan=true; select * from ambulance_data_csv_load;返回结果如下:
+------------+------------+------------+------------+------------------+-------------------+------------+------------+ | vehicleid | recordid | patientid | calls | locationlatitute | locationlongtitue | recordtime | direction | +------------+------------+------------+------------+------------------+-------------------+------------+------------+ | 1 | 1 | 51 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | S | | 1 | 2 | 13 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | NE | | 1 | 3 | 48 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | NE | | 1 | 4 | 30 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | W | | 1 | 5 | 47 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | S | | 1 | 6 | 9 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | S | | 1 | 7 | 53 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | N | | 1 | 8 | 63 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | SW | | 1 | 9 | 4 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | NE | | 1 | 10 | 31 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | N | +------------+------------+------------+------------+------------------+-------------------+------------+------------+
外部存储:Hologres
示例场景
已创建Hologres实例及数据库,并创建一张表;已在MaxCompute创建了一个Hologres外部表,通过外部表查询已创建的Hologres表数据如下。
--查询holo外表: select * from mf_holo_ext4; --返回 +------------+------+ | id | name | +------------+------+ | 1 | abc | | 2 | ereg | +------------+------+通过LOAD命令将此Hologres表数据导入MaxCompute内表操作示例。
创建一个MaxCompute内表。
--创建内表 create table mf_from_holo(id bigint,name string);通过LOAD命令导入数据至MaxCompute。
--load holo表数据到mc内表 load into table mf_from_holo from location 'jdbc:postgresql://hgprecn-cn-wwo3ft0l****-cn-beijing-internal.hologres.aliyuncs.com:80/mf_db?application_name=MaxCompute¤tSchema=public&useSSL=false&table=mf_holo/' stored by 'com.aliyun.odps.jdbc.JdbcStorageHandler' with serdeproperties ( 'odps.properties.rolearn'='acs:ram::18927322887*****:role/hologressrole', 'mcfed.mapreduce.jdbc.driver.class'='org.postgresql.Driver', 'odps.federation.jdbc.target.db.type'='holo' );查询导入结果。
select * from mf_from_holo; --返回 +------------+------+ | id | name | +------------+------+ | 2 | ereg | | 1 | abc | +------------+------+
导入其他开源格式数据
命令格式
{load overwrite|into} table <table_name> [partition (<pt_spec>)] from location <external_location> [row format serde '<serde_class>' [with serdeproperties (<Options>)] ] stored as <file_format>;参数说明
table_name:必填。需要插入数据的目标表名称。目标表需要提前创建,目标表的Schema(除分区列)需要和外部数据格式一致。
pt_spec:可选。需要插入数据的目标表分区信息。格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。external_location:必填。指定读取外部存储数据的OSS目录,格式为
'oss://<oss_endpoint>/<object>',详情请参见通过IPv6协议访问OSS,系统会默认读取该目录下所有的文件。serde_class:可选。使用方法和MaxCompute外部表一致,详情请参见创建OSS外部表。
Options:必填。指定外部表相关参数,SERDEPROPERTIES支持的属性和MaxCompute外部表一致,属性列表详情请参见创建OSS外部表。
file_format:必填。指定导入数据文件格式。例如ORC、PARQUET、RCFILE、SEQUENCEFILE和TEXTFILE。使用方法和MaxCompute外部表一致,详情请参见创建OSS外部表。
说明serde_class和Options使用默认值时,可以省略不写。导入的单个文件大小不能超过3 GB,如果文件过大,建议拆分。
使用示例
示例1:导入其他开源格式数据。假设MaxCompute和OSS的Owner是同一个账号,通过阿里云内网将vehicle.textfile文件的数据导入MaxCompute。
说明若MaxCompute和OSS的Owner不是同一个账号,授权方式可参见OSS的STS模式授权。
将vehicle.txtfile文件保存至OSS Bucket目录下
mc-test/data_location/,地域为oss-cn-hangzhou,并组织OSS目录路径。创建OSS Bucket详情请参见创建存储空间。vehicle.textfile文件数据如下:
1,1,51,1,46.81006,-92.08174,9/14/2014 0:00,S 1,2,13,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,3,48,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,4,30,1,46.81006,-92.08174,9/14/2014 0:00,W 1,5,47,1,46.81006,-92.08174,9/14/2014 0:00,S 1,6,9,1,46.81006,-92.08174,9/14/2014 0:00,S 1,7,53,1,46.81006,-92.08174,9/14/2014 0:00,N 1,8,63,1,46.81006,-92.08174,9/14/2014 0:00,SW 1,9,4,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,10,31,1,46.81006,-92.08174,9/14/2014 0:00,N根据Bucket、地域、Endpoint信息组织OSS目录路径如下:
oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-test/data_location/登录MaxCompute客户端创建目标表ambulance_data_textfile_load_pt。命令示例如下:
create table ambulance_data_textfile_load_pt ( vehicleId STRING, recordId STRING, patientId STRING, calls STRING, locationLatitute STRING, locationLongtitue STRING, recordTime STRING, direction STRING) partitioned by (ds STRING);执行
load overwrite命令,将OSS上的vehicle.textfile文件导入目标表。命令示例如下:load overwrite table ambulance_data_textfile_load_pt partition(ds='20200910') from location 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-test/data_location/' row format serde 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' stored as textfile;查看目标表ambulance_data_textfile_load_pt的导入结果。命令示例如下:
--开启全表扫描,仅此Session有效。 set odps.sql.allow.fullscan=true; select * from ambulance_data_textfile_load_pt;返回结果如下:
+------------+------------+------------+------------+------------------+-------------------+------------+------------+------------+ | vehicleid | recordid | patientid | calls | locationlatitute | locationlongtitue | recordtime | direction | ds | +------------+------------+------------+------------+------------------+-------------------+------------+------------+------------+ | 1,1,51,1,46.81006,-92.08174,9/14/2014 0:00,S | NULL | NULL | NULL | NULL | NULL | NULL | NULL | 20200910 | | 1,2,13,1,46.81006,-92.08174,9/14/2014 0:00,NE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | 20200910 | | 1,3,48,1,46.81006,-92.08174,9/14/2014 0:00,NE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | 20200910 | | 1,4,30,1,46.81006,-92.08174,9/14/2014 0:00,W | NULL | NULL | NULL | NULL | NULL | NULL | NULL | 20200910 | | 1,5,47,1,46.81006,-92.08174,9/14/2014 0:00,S | NULL | NULL | NULL | NULL | NULL | NULL | NULL | 20200910 | | 1,6,9,1,46.81006,-92.08174,9/14/2014 0:00,S | NULL | NULL | NULL | NULL | NULL | NULL | NULL | 20200910 | | 1,7,53,1,46.81006,-92.08174,9/14/2014 0:00,N | NULL | NULL | NULL | NULL | NULL | NULL | NULL | 20200910 | | 1,8,63,1,46.81006,-92.08174,9/14/2014 0:00,SW | NULL | NULL | NULL | NULL | NULL | NULL | NULL | 20200910 | | 1,9,4,1,46.81006,-92.08174,9/14/2014 0:00,NE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | 20200910 | | 1,10,31,1,46.81006,-92.08174,9/14/2014 0:00,N | NULL | NULL | NULL | NULL | NULL | NULL | NULL | 20200910 | +------------+------------+------------+------------+------------------+-------------------+------------+------------+------------+
示例2:将数据按动态分区方式导入目标表。
说明如果OSS目录下的子目录是以分区名方式组织的,则可以将数据按动态分区的方式导入到分区表。
将vehicle1.csv文件和vehicle2.csv文件分别保存至OSS Bucket目录
mc-test/data_location/ds=20200909/和mc-test/data_location/ds=20200910/,地域为oss-cn-hangzhou,并组织OSS目录路径。创建OSS Bucket详情请参见创建存储空间。vehicle1.csv文件和vehicle2.csv文件数据如下:
--vehicle1.csv 1,1,51,1,46.81006,-92.08174,9/14/2014 0:00,S 1,2,13,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,3,48,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,4,30,1,46.81006,-92.08174,9/14/2014 0:00,W 1,5,47,1,46.81006,-92.08174,9/14/2014 0:00,S 1,6,9,1,46.81006,-92.08174,9/14/2014 0:00,S --vehicle2.csv 1,7,53,1,46.81006,-92.08174,9/14/2014 0:00,N 1,8,63,1,46.81006,-92.08174,9/14/2014 0:00,SW 1,9,4,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,10,31,1,46.81006,-92.08174,9/14/2014 0:00,N根据Bucket、地域、Endpoint信息组织OSS目录路径如下:
oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-test/data_location/ds=20200909/' oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-test/data_location/ds=20200910/'登录MaxCompute客户端创建目标表ambulance_data_csv_load_dynpt。命令示例如下:
create table ambulance_data_csv_load_dynpt ( vehicleId STRING, recordId STRING, patientId STRING, calls STRING, locationLatitute STRING, locationLongtitue STRING, recordTime STRING, direction STRING) partitioned by (ds STRING);执行
load overwrite命令,将OSS上的文件导入目标表。命令示例如下:load overwrite table ambulance_data_csv_load_dynpt partition(ds) from location 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-test/data_location/' row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde' stored as textfile;查看目标表ambulance_data_csv_load_dynpt的导入结果。命令示例如下:
--开启全表扫描,仅此Session有效。 set odps.sql.allow.fullscan=true; select * from ambulance_data_csv_load_dynpt;返回结果如下:
+------------+------------+------------+------------+------------------+-------------------+------------+------------+------------+ | vehicleid | recordid | patientid | calls | locationlatitute | locationlongtitue | recordtime | direction | ds | +------------+------------+------------+------------+------------------+-------------------+------------+------------+------------+ | 1 | 7 | 53 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | N | 20200909 | | 1 | 8 | 63 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | SW | 20200909 | | 1 | 9 | 4 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | NE | 20200909 | | 1 | 10 | 31 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | N | 20200909 | | 1 | 1 | 51 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | S | 20200910 | | 1 | 2 | 13 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | NE | 20200910 | | 1 | 3 | 48 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | NE | 20200910 | | 1 | 4 | 30 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | W | 20200910 | | 1 | 5 | 47 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | S | 20200910 | | 1 | 6 | 9 | 1 | 46.81006 | -92.08174 | 9/14/2014 0:00 | S | 20200910 | +------------+------------+------------+------------+------------------+-------------------+------------+------------+------------+
相关文档
若您希望将MaxCompute项目中的数据导出到外部存储(OSS、Hologres),以供其他计算引擎使用,请参见UNLOAD。