
数据流入Delta Table主要存在近实时增量写入和批量写入两种场景,本文为您介绍高并发近实时增量写入场景的架构设计。
实际业务数据处理场景中,涉及的数据源丰富多样,可能存在数据库、日志系统或者其他消息队列等系统,为了方便用户将数据写入MaxCompute的Delta Table, MaxCompute深度定制开发了开源Flink Connector工具,联合DataWorks数据集成以及其它数据导入工具,针对高并发、容错、事务提交等场景做了定制化的设计及开发优化,以满足延时低、正确性高等要求。
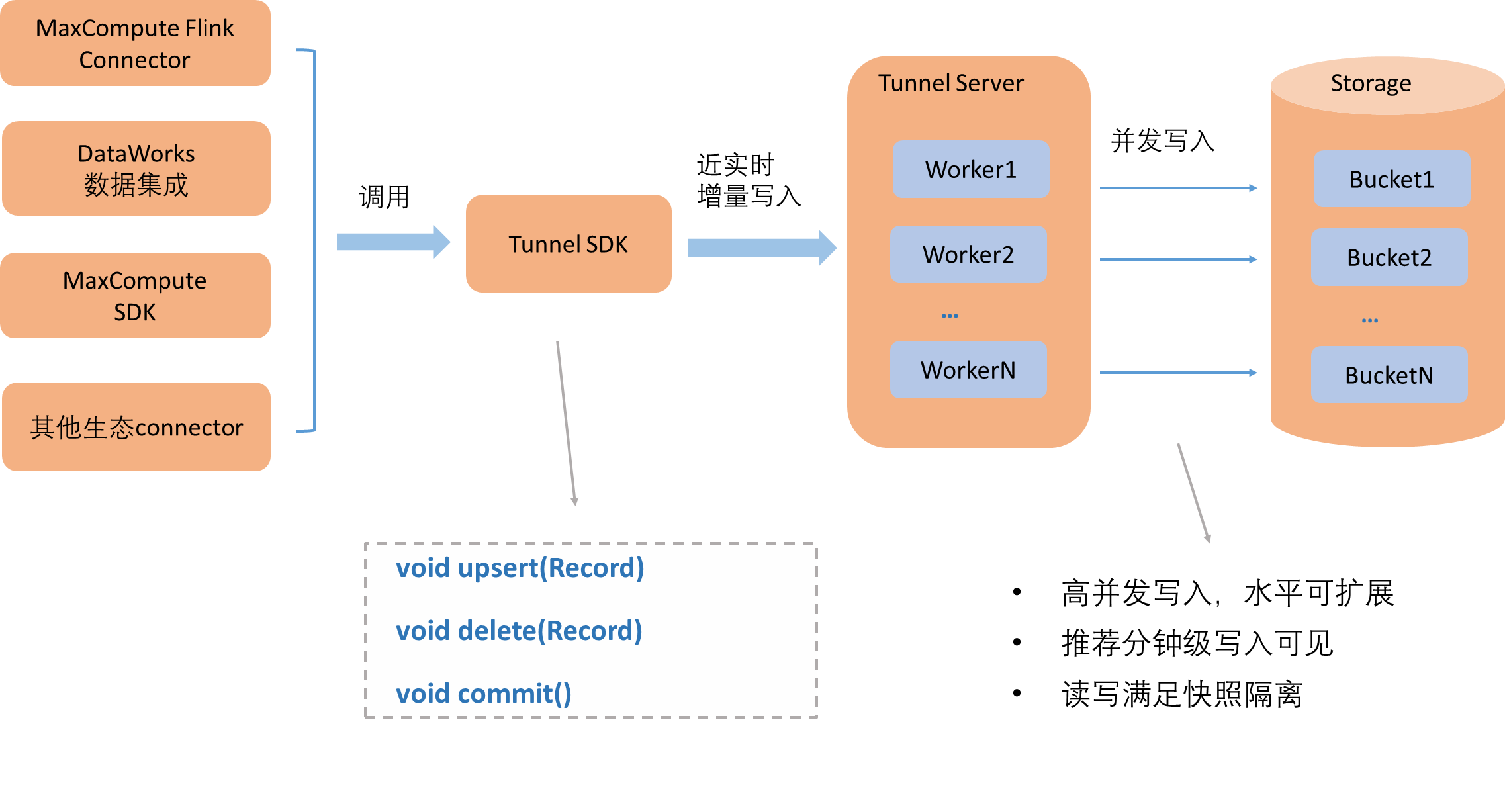
如上图所示:
数据导入工具内部会集成MaxCompute数据通道服务Tunnel提供的SDK Client,支持分钟级高并发写入数据到Tunnel Server,由它把数据并发写入到每个Bucket的数据文件中。
写入并发度可通过表属性write.bucket.num来配置,因此写入速度可水平扩展。数据切分Bucket的优势可详细参考表数据格式。
Tunnel SDK提供的数据写入接口目前支持upsert和delete,详情请参见Upsert。
commit接口调用代表原子提交这段时间写入的数据。
如返回成功就代表写入数据查询可见,满足读写快照隔离级别。
如返回失败,可支持重试,如果不是数据损坏等不可恢复的错误,则存在重试成功的可能,不需要重新写入数据,否则需要重写数据之后,重新提交Commit。
该文章对您有帮助吗?