
本文介绍了MaxCompute的元数据服务Information Schema服务的基本概念、操作使用以及使用限制。
MaxCompute的Information Schema提供了项目元数据及使用历史数据等信息。在ANSI SQL-92的Information Schema基础上,添加了面向MaxCompute服务特有的字段及视图。MaxCompute提供了名称为Information Schema的公共项目,通过访问该公共项目提供的只读视图,可以查询到用户项目的元数据信息及使用历史信息。
使用限制
Information Schema提供的是当前项目的元数据视图,不支持跨项目的元数据访问。如果需要对多个项目的元数据进行统一查询、分析,需要分别获取各个项目中的元数据并整合在一起进行跨项目元数据分析。
元数据系统表目前提供准实时视图,对元数据时效性要求较高的应用,建议使用SDK/CLI直接获取指定对象的元数据。
元数据及作业历史数据保存在Information Schema空间下,如果需要对历史数据进行快照备份或获得超过14天的作业历史,您可以定期将Information Schema的数据备份到指定项目。
获取Information Schema服务
自2024年03月01日开始,MaxCompute停止对新增项目自动安装项目级别Information Schema,即新增的项目默认没有项目级别Information Schema的Package。若您有查元数据的业务,您可以查询租户级别的Information Schema,以便获取更全的信息。租户级别Information Schema的具体使用说明请参见租户级别Information Schema。
对于存量MaxCompute项目,在您开始使用Information Schema服务前,需要以项目所有者(Project Owner)或具备Super_Administrator管理角色的RAM用户身份安装Information Schema权限包,获得访问项目元数据的权限。更多为用户授权管理角色操作信息,请参见将角色赋予用户。安装方式有如下两种:
登录MaxCompute客户端,执行如下命令:
install package Information_Schema.systables;登录DataWorks控制台,进入临时查询界面。更多临时查询操作详情,请参见使用临时查询运行SQL语句(可选)。执行如下命令:
install package Information_Schema.systables;执行示例如下。
Package安装成功后,当前操作所在项目即获得了通过Information Schema查询本项目相关元数据的权限。数据保存在Information Schema项目内,无需为元数据存储付费。
执行如下命令,可以查看Information Schema所提供的视图列表。
odps@myproject1> describe package Information_Schema.systables;查询结果如下图。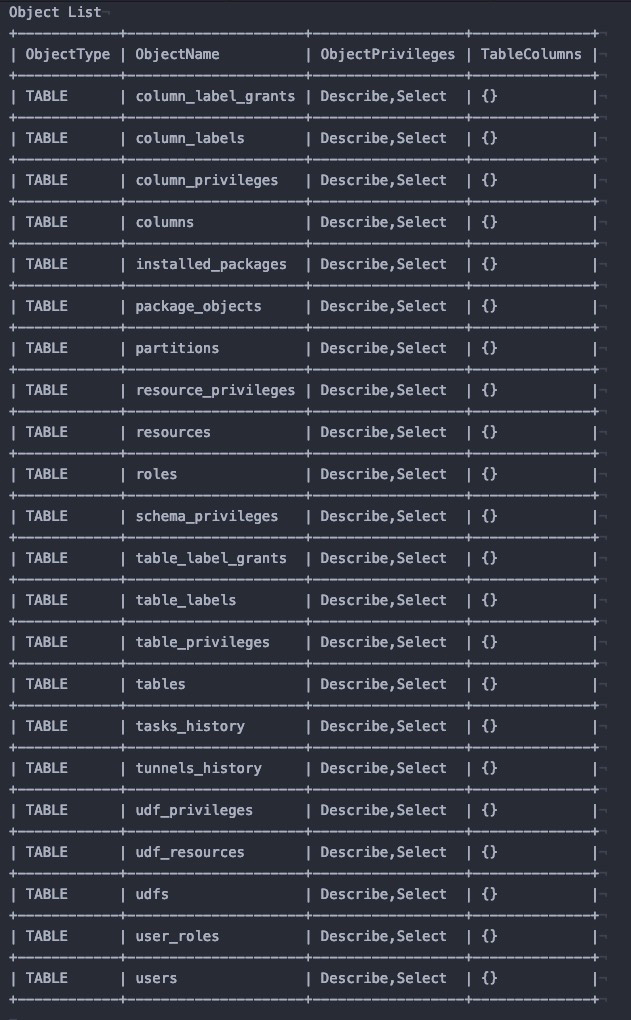
查询元数据视图
查询元数据视图时,需要在视图名称前指定项目Information Schema,即Information Schema.view_name。
例如,您登录访问的当前项目为myproject1,在myproject1中,执行如下命令查询当前myproject1中所有表的元数据信息。
odps@myproject1>select * from Information_Schema.tables;Information Schema同时也包含了作业历史视图,可以查询到当前项目内的作业历史信息。使用时可添加日期分区进行过滤,请参见如下命令。
odps@myproject1>select * from Information_Schema.tasks_history where ds='yyyymmdd' limit 100;访问授权
Information Schema的视图包含了项目级别的所有用户数据,默认项目所有者可以查看。如果项目内其他用户或角色需要查看,需要进行授权,请参见基于Package跨项目访问资源。
授权语法如下。
grant <actions> on package Information_Schema.systables to user <user_name>;
grant <actions> on package Information_Schema.systables to role <role_name>;actions:待授予的操作权限,取值为Read。
user_name:已添加至项目中的阿里云账号或RAM用户。
您可以通过MaxCompute客户端执行
list users;命令获取用户账号。role_name:已添加至项目中的角色。
您可以通过MaxCompute客户端执行
list roles;命令获取角色名称。
授权示例如下。
grant read on package Information_Schema.systables to user RAM$Bob@aliyun.com:user01;元数据视图列表
借助Information_Schema元数据视图,您可以浏览和检索元数据。
借助Information_Schema使用信息视图,您可以对作业的运行情况,例如资源消耗、运行时长、数据处理量等指标进行分析,用于优化作业或规划资源容量。
不同视图存在不同的时效性或系统默认的保留周期,超过保留周期的数据将无法访问。您可以手工从Information_Schema周期性导出数据到本地表中,备份更长周期的历史数据。
费用说明如下。
对于使用按量计费计算资源的项目,针对Information Schema视图的查询会产生查询费用,查询视图的SQL产生的费用按视图底层展开的SQL进行计费。Information Schema视图为了提升查询性能底层统一通过
Range聚簇表进行优化,减少查询输入量。如果您查询TASKS_HISTORY和TUNNELS_HISTORY这两个视图,请在每天6:00:00后查询前一天数据,避免查询当天的数据,可最大程度减少输入量从而降低查询费用。对于使用包年包月计算资源的项目,查询Information Schema视图时会消耗您购买的CU。
您不需要为Information Schema视图支付存储费用。
导出数据时,建议显性地选择视图的字段名称,尽量避免使用insert into select * from information_schema.***的方式导出数据,防止新增字段后导致备份失败。
元数据视图列表如下。
分类 | 视图 | 时效性/保留周期 | 延迟说明 |
元数据信息 | 准实时视图 | 与在线数据存在一定延迟,延迟时间为3小时左右。 | |
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
准实时视图 | |||
使用信息 | 运行中作业的实时快照 | 与在线数据存在秒级延迟,当前处于内测(Preview)中,无SLA保障,后续会逐步开放。 | |
准实时视图,分区表,保留最近14天明细 | 与在线数据存在一定延迟,延迟时间为15分钟左右。 | ||
准实时视图,分区表,保留最近14天明细 |
TABLES
项目空间下的表信息。
字段 | 类型 | 值 |
table_catalog | STRING | 固定值 |
table_schema | STRING | 项目空间名称。 |
table_name | STRING | 表名。 |
table_type | STRING | 表类型。取值范围:
|
is_partitioned | BOOLEAN | 是否是分区表。 |
owner_id | STRING | 表所有者的ID。 |
owner_name | STRING | 可选。表所有者的云账号名称。 |
create_time | DATETIME | 表的创建时间。 |
last_modified_time | DATETIME | 表的数据最后更新时间。 |
data_length | BIGINT | 如果表为非分区表,值为表的数据量大小。如果表为分区表,系统不会计算表的数据量大小,值为NULL。PARTITIONS视图中包含分区表各个分区的数据量大小。单位:字节(Byte)。 |
table_comment | STRING | 表的注释。 |
life_cycle | BIGINT | 可选。生命周期。 |
is_archived | BOOLEAN | 预留字段,无意义。 |
table_exstore_type | STRING | 预留字段,无意义。 |
cluster_type | STRING | MaxCompute表的分桶(Clustering)类型。取值为HASH或RANGE。 |
number_buckets | BIGINT | 可选字段,Cluster表的Bucket数目,0表示作业执行时动态决定。 |
view_original_text | STRING | VIRTUAL_VIEW类型表的view text。 |
PARTITIONS
项目空间下的表分区信息。
字段 | 类型 | 值 |
table_catalog | STRING | 固定值 |
table_schema | STRING | 项目名称。 |
table_name | STRING | 表名。 |
partition_name | STRING | 分区名。例如 |
create_time | DATETIME | 分区的创建时间。 |
last_modified_time | DATETIME | 表的最后更新时间。 |
data_length | BIGINT | 分区的数据量大小。单位:字节(Byte)。 |
is_archived | BOOLEAN | 预留字段,无意义。 |
is_exstore | BOOLEAN | 预留字段,无意义。 |
cluster_type | STRING | 可选字段。MaxCompute表的分桶(Clustering)类型。取值为HASH或RANGE。 |
number_buckets | BIGINT | 可选字段,Cluster表的Bucket数目。0表示作业执行时动态决定。 |
COLUMNS
描述项目空间下的表字段信息。
字段 | 类型 | 值 |
table_catalog | STRING | 固定值 |
table_schema | STRING | 项目名称。 |
table_name | STRING | 表名。 |
column_name | STRING | 列名。 |
ordinal_position | BIGINT | 列序号。 |
column_default | STRING | 字段默认值。 |
is_nullable | BOOLEAN | 可选字段。始终为YES。 |
data_type | STRING | 数据类型。 |
column_comment | STRING | 列注释。 |
is_partition_key | BOOLEAN | 是否是分区键。 |
UDFS
项目空间下的UDF信息。
字段 | 类型 | 值 |
udf_catalog | STRING | 固定值 |
udf_schema | STRING | 项目名称。 |
udf_name | STRING | UDF名称。 |
owner_id | STRING | UDF拥有者的ID。 |
owner_name | STRING | 可选字段,UDF拥有者的云账号名称。 |
create_time | DATETIME | UDF的创建时间。 |
last_modified_time | DATETIME | UDF的最后修改时间。 |
RESOURCES
项目空间下的资源信息。
字段 | 类型 | 值 |
resource_catalog | STRING | 固定值 |
resource_schema | STRING | 项目的名称。 |
resource_name | STRING | 资源名。 |
resource_type | STRING | 资源类型。取值为Py或Jar。 |
owner_id | STRING | 资源所有者的ID。 |
owner_name | STRING | 可选字段,资源所有者的云账号名称。 |
create_time | DATETIME | 资源的创建时间。 |
last_modified_time | DATETIME | 资源的最后修改时间。 |
size | BIGINT | 资源占用的存储空间。 |
comment | STRING | 资源的注释。 |
is_temp_resource | BOOLEAN | 是否是临时资源。 |
UDF_RESOURCES
项目空间下UDF的资源依赖。
字段 | 类型 | 值 |
udf_catalog | STRING | 固定值 |
udf_schema | STRING | 项目名称。 |
udf_name | STRING | UDF名称。 |
resource_schema | STRING | 资源所在的项目。 |
resource_name | STRING | 资源名。 |
USERS
项目空间下的用户列表。
字段 | 类型 | 值 |
user_catalog | STRING | 取值为ALIYUN或RAM。 |
user_schema | STRING | 项目名称。 |
user_name | STRING | 可选字段,用户名。 |
user_id | STRING | 用户ID。 |
user_label | STRING | 用户标签。 |
ROLES
项目空间下的角色列表。
字段 | 类型 | 值 |
role_catalog | STRING | 固定值 |
role_schema | STRING | 项目名称。 |
role_name | STRING | 角色名。 |
role_label | STRING | 角色标签。 |
comment | STRING | 角色的注释。 |
USER_ROLES
项目空间下用户拥有的角色信息。
字段 | 类型 | 值 |
user_role_catalog | STRING | 固定值 |
user_role_schema | STRING | 项目名称。 |
role_name | STRING | 角色名。 |
user_name | STRING | 用户名。 |
user_id | STRING | 用户的ID。 |
PACKAGE_OBJECTS
项目空间下Package中的对象信息。
字段 | 类型 | 值 |
package_catalog | STRING | 固定值 |
package_schema | STRING | 项目名称。 |
package_name | STRING | Package名称。 |
object_type | STRING | Package内成员的类型。 |
object_name | STRING | Package内成员的名字。 |
column_name | STRING | 表的列名。 |
allowed_privileges | VECTOR<STRING> | 共享的权限。 |
allowed_label | STRING | 共享的标签。 |
INSTALLED_PACKAGES
项目空间下已安装的Package信息。
字段 | 类型 | 值 |
installed_package_catalog | STRING | 固定值 |
installed_package_schema | STRING | 项目名称。 |
package_project | STRING | 创建Package的项目空间名称。 |
package_name | STRING | Package名称。 |
installed_time | DATETIME | 安装时间(预留字段)。 |
allowed_label | STRING | 共享的标签。 |
SCHEMA_PRIVILEGES
项目空间下SCHEMA的权限信息。
字段 | 类型 | 值 |
user_catalog | STRING | 固定值 |
user_schema | STRING | 项目名称。 |
grantee | STRING | 用户名。 |
user_id | STRING | 账户ID。 |
grantor | STRING | 授权者账号,当前值为NULL。 |
privilege_type | STRING | 权限类型。 |
TABLE_PRIVILEGES
项目空间下表的权限信息。
字段 | 类型 | 值 |
table_catalog | STRING | 固定值 |
table_schema | STRING | 表所在的项目名称。 |
table_name | STRING | 表名。 |
grantee | STRING | 用户名。 |
user_id | STRING | 账户ID。 |
grantor | STRING | 授权者账号,当前值为NULL。 |
privilege_type | STRING | 权限类型。 |
user_schema | STRING | 用户所在的项目名称。 |
COLUMN_PRIVILEGES
项目空间下表字段级的权限信息。
字段 | 类型 | 值 |
table_catalog | STRING | 固定值 |
table_schema | STRING | 表所在的项目名称。 |
table_name | STRING | 表名。 |
column_name | STRING | 列名。 |
grantee | STRING | 用户名。 |
user_id | STRING | 账户ID。 |
grantor | STRING | 可选字段。目前为NULL。 |
privilege_type | STRING | 权限类型。 |
user_schema | STRING | 用户所在的项目名称。 |
UDF_PRIVILEGES
项目空间下UDF的权限信息。
字段 | 类型 | 值 |
udf_catalog | STRING | 固定值 |
udf_schema | STRING | 项目名称。 |
udf_name | STRING | UDF名称。 |
user_schema | STRING | 用户所在的项目名称。 |
grantee | STRING | 用户名。 |
user_id | STRING | 账户ID。 |
grantor | STRING | 授权者账号,当前值为NULL。 |
privilege_type | STRING | 权限类型。 |
RESOURCE_PRIVILEGES
项目空间下资源的权限信息。
字段 | 类型 | 值 |
resource_catalog | STRING | 固定值 |
resource_schema | STRING | 项目名称。 |
resource_name | STRING | 资源名称。 |
user_schema | STRING | 用户所在项目空间。 |
grantee | STRING | 用户名。 |
user_id | STRING | 账户ID。 |
grantor | STRING | 授权者账号,当前值为NULL。 |
privilege_type | STRING | 权限类型。 |
TABLE_LABELS
项目空间下表的LABEL信息。
字段 | 类型 | 值 |
table_catalog | STRING | 固定值 |
table_schema | STRING | 项目名称。 |
table_name | STRING | 表名。 |
label_type | STRING | 标签类型(始终为NULL)。 |
label_level | STRING | 标签等级。 |
COLUMN_LABELS
项目空间下表字段级的LABEL信息。
字段 | 类型 | 值 |
table_catalog | STRING | 固定值 |
table_schema | STRING | 项目名称。 |
table_name | STRING | 表名。 |
column_name | STRING | 字段名。 |
label_type | STRING | 标签类型(始终为NULL)。 |
label_level | STRING | 标签等级。 |
TABLE_LABEL_GRANTS
项目空间下表的LABEL授权信息。
字段 | 类型 | 值 |
table_label_grant_catalog | STRING | 固定值 |
table_label_grant_schema | STRING | 用户所在的项目名称。 |
user | STRING | 用户名称。 |
user_id | STRING | 用户的ID。 |
table_schema | STRING | 表所在的项目名称。 |
table_name | STRING | 表名。 |
grantor | STRING | 授权者账号,当前值为NULL。 |
label_level | STRING | 授予的标签等级。 |
expired | DATETIME | 过期时间。 |
COLUMN_LABEL_GRANTS
项目空间下表字段的LABEL授权信息。
字段 | 类型 | 值 |
column_label_grant_catalog | STRING | 固定值 |
column_label_grant_schema | STRING | 用户所在项目名称。 |
user | STRING | 用户名称。 |
user_id | STRING | 用户的ID。 |
table_schema | STRING | 表所在的项目名称。 |
table_name | STRING | 表名。 |
column_name | STRING | 字段名。 |
grantor | STRING | 授权者账号,当前值为NULL。 |
label_level | STRING | 授予的标签等级。 |
expired | DATETIME | 过期时间。 |
TASKS
作业实时快照,用于实时监控作业。
TASKS视图当前处于内测发布状态,存在字段和字段内容变更的可能,无SLA保障,请您谨慎使用。后续发布状态变更请关注公告。
字段 | 类型 | 值 |
project_name | STRING | 项目名称。 |
task_name | STRING | 作业名称。 |
task_type | STRING | 作业类型。 作业类型取值如下:
|
inst_id | STRING | 实例ID。 |
status | STRING | 数据采集瞬间的运行状态,取值为Running或Waiting。 |
owner_id | STRING | 作业提交人云账号ID。 |
owner_name | STRING | 作业提交人云账号名称。 |
start_time | DATETIME | 作业启动时间。 |
priority | BIGINT | 作业优先级,仅支持采用包年包月资源的作业。 |
signature | STRING | 作业签名。 |
queue_name | STRING | 计算队列名称。 |
cpu_usage | BIGINT | 当前CPU用量,值为core×100。 |
mem_usage | BIGINT | 当前内存用量,单位为MB。 |
gpu_usage | BIGINT | 当前GPU用量,值为卡×100。 |
total_cpu_usage | BIGINT | 累计CPU用量,值为core×100×s。 |
total_mem_usage | BIGINT | 累计内存用量,值为MB×s。 |
total_gpu_usage | BIGINT | 累计GPU用量,值为卡×100×s。 |
cpu_min_ratio | BIGINT | 作业当前CPU用量占用队列保障水位比例,仅支持采用包年包月资源的作业。 |
mem_min_ratio | BIGINT | 作业当前内存用量占用队列保障水位比例,仅支持采用包年包月资源的作业。 |
gpu_min_ratio | BIGINT | 作业当前GPU用量占用队列保障水位比例,仅支持采用包年包月资源的作业。 |
cpu_max_ratio | BIGINT | 作业当前CPU用量占用队列最高弹性水位比例,仅支持采用包年包月资源的作业。 |
mem_max_ratio | BIGINT | 作业当前内存用量占用队列最高弹性水位比例,仅支持采用包年包月资源的作业。 |
gpu_max_ratio | BIGINT | 作业当前GPU用量占用队列最高弹性水位比例,仅支持采用包年包月资源的作业。 |
settings | STRING | DataWorks等上层自定义调度设置。 |
additional_info | STRING | 附加信息,保留字段。 |
TASKS_HISTORY
MaxCompute项目内已完成的作业历史,保留近14天数据。
字段 | 类型 | 值 |
task_catalog | STRING | 固定值 |
task_schema | STRING | 项目名称。 |
task_name | STRING | 作业名称。 |
task_type | STRING | 作业类型。 作业类型取值如下:
|
inst_id | STRING | 实例ID。 |
status | STRING | 数据采集瞬间的运行状态(非实时状态)。包含以下状态:
|
owner_id | STRING | 账户ID。 |
owner_name | STRING | 云账户名称。 |
result | STRING | 仅在SQL作业出错时有值,提供报错信息。 |
start_time | DATETIME | 作业启动时间。 |
end_time | DATETIME | 作业结束时间(当天未结束为NULL)。 |
input_records | BIGINT | 作业读取的records数目。 |
output_records | BIGINT | 作业输出的records数目。 |
input_bytes | BIGINT | 实际扫描的数据量,与Logview相同。 |
output_bytes | BIGINT | 输出字节数。 |
input_tables | STRING | [project.table1,project.table2]格式的作业输入表。有些作业无此信息,如SQL COST类型作业。 |
output_tables | STRING | [project.table1,project.table2]格式的作业输出表。 |
operation_text | STRING | 查询语句的source_xml(source_xml超过256 KB时值为NULL)。 |
signature | STRING | 可选字段。作业签名。 |
complexity | DOUBLE | 可选字段,作业复杂度。仅SQL作业有此字段。 |
cost_cpu | DOUBLE | 作业CPU消耗(100表示1 core×s。例如:10 core运行5s,cost_cpu为10×100×5=5000)。 |
cost_mem | DOUBLE | 作业内存消耗(MB×s)。 |
settings | STRING | 上层调度或用户传入的信息,以JSON格式存储。包含字段:USERAGENT、BIZID、SKYNET_ID和SKYNET_NODENAME。 |
ds | STRING | 数据采集日期。例如20190101。 |
TUNNELS_HISTORY
数据通道批量上传下载的历史数据,保留近14天数据。
字段 | 类型 | 值 |
tunnel_catalog | STRING | 固定值 |
tunnel_schema | STRING | 项目名称。 |
session_id | STRING | 会话ID,格式为 |
operate_type | STRING | 操作类型。取值范围:
|
tunnel_type | STRING | 通道类型。取值为TUNNEL LOG或TUNNEL INSTANCE LOG。 |
request_id | STRING | 请求ID。 |
object_type | STRING | 操作对象类型。取值为TABLE或INSTANCE。 |
object_name | STRING | 表名称或实例ID。 |
partition_spec | STRING | 分区信息。例如 |
data_size | BIGINT | 数据的字节数,单位:字节(Byte)。 |
block_id | BIGINT | Tunnel上传的Block编号。当操作类型是UPLOADLOG时有效,否则为空。 |
offset | BIGINT | 下载的起始偏移位置,表示从第几条记录开始(起始是0)。 |
length | BIGINT | 即record_count,本次下载或上传的记录数(下载的记录数为用户指定的length值)。 |
owner_id | STRING | 云账户ID。 |
owner_name | STRING | 云账户名称。 |
start_time | DATETIME | 请求开始时间。 |
end_time | DATETIME | 请求结束时间。 |
client_ip | STRING | 发起Tunnel请求的客户端IP地址。 |
user_agent | STRING | User Agent,发起Tunnel请求的客户端的相关信息。例如Java版本、操作系统。 |
columns | STRING | Tunnel下载数据时指定列的集合。 |
ds | STRING | 数据采集日期。例如20190101。 |