
Milvus+n8n:基于GitHub文档分析的垂直领域智能问答解决方案
本文将聚焦于向量检索服务Milvus版(简称Milvus),借助低代码工作流编排平台n8n(全称NodeNation),展示如何将二者无缝结合,以利用GitHub的API快速搭建一个企业级的垂直领域智能问答应用。
背景信息
n8n介绍
n8n是一个开源、可视化的工作流自动化平台,被誉为“程序员的Zapier”或可自部署的Make。它旨在通过连接不同的节点(Node)来构建强大的自动化任务,简化复杂工作流程的实现。
核心特点:
可视化设计:用户可以在一个直观的画布上,通过拖拽和连接节点,轻松构建自动化流程,而无需编写大量代码。
灵活性与可扩展性:支持数百种应用和服务的即用型集成,用户可以根据需求自定义工作流。
支持多种触发模式:支持事件驱动(Webhook)和定时调度两种触发方式。
基础概念:
节点(Node):工作流的最小功能单元,负责集成外部服务和实现特定操作,如发送HTTP请求、解析JSON或写入数据库。节点通过输入/输出端口以JSON格式传递数据,支持本地和分布式执行。
工作流(Workflow):由多个节点按逻辑顺序连接而成的自动化流程,支持分支、循环和错误处理。工作流的定义是执行引擎的输入,从而形成完整的操作逻辑。
执行引擎(Engine):n8n的核心运行时,负责解析工作流的定义、调度节点执行、管理任务队列及处理错误重试。
卷(Volume):在容器化部署(如Docker)中用于持久化存储n8n的配置、工作流数据和日志。通过将宿主机目录绑定到容器内路径(如
/home/n8n/.n8n),确保数据不丢失。
方案概述
为了快速搭建一个企业级的垂直领域智能问答应用,我们将在n8n中创建两个工作流,以实现高效的数据处理和响应机制。
工作流设计
工作流一:文档数据拉取与存储
用于定时从GitHub拉取Milvus产品的文档数据,并将其写入Milvus向量库。
工作流二:智能问答处理
利用AI Agent和大模型的能力判断客户提问的内容。当问题与Milvus产品相关时,从Milvus向量库召回相应的答案,并将答案整合到大模型的输出中返回给客户;否则,则直接通过大模型提供通用的回答。

通过这两个工作流的协同工作,我们能够实现对Milvus产品文档的实时更新与智能问答的高效处理。这一方案不仅提升了客户的查询效率,也增强了整体用户体验,为企业提供了强有力的技术支持。
前提条件
已创建Milvus实例,具体操作请参见快速创建Milvus实例。
已开通阿里云百炼服务并获得API-KEY,具体操作请参见获取API Key。
已创建OpenAPI密钥,具体操作请参见GitHub credentials。
已安装Docker,具体操作请参见安装并使用Docker和Docker Compose。
操作流程
步骤一:n8n安装与配置
安装n8n。
创建数据卷。
为了持久化n8n的数据(如工作流、凭据等),首先需要创建一个Docker数据卷。执行以下命令,创建一个名为
n8n_data的数据卷。docker volume create n8n_data启动n8n容器。
执行以下命令启动n8n容器,并将数据卷挂载到容器中。
docker run --name n8n -d \ -e N8N_SECURE_COOKIE=false \ -p 5678:5678 \ -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8n涉及参数说明如下:
--name n8n:指定容器名称为n8n。-d:以后台模式运行容器。-e N8N_SECURE_COOKIE=false:禁用安全Cookie设置(适用于开发或测试环境)。-p 5678:5878:将主机的5678端口映射到容器的5678端口。-v n8n_data:/home/node/.n8n:将本地数据卷n8n_data挂载到容器内的/home/node/.n8n目录,用于存储n8n的数据。docker.n8n.io/n8nio/n8n:使用的n8n镜像。
验证安装是否成功。
启动容器后,在浏览器中访问
http://127.0.0.1:5678/地址,验证n8n服务是否正常运行。说明如果n8n运行在远程服务器(例如,云服务器或虚拟机)上,则需要将
127.0.0.1替换为服务器的公网IP地址或域名,并确保网络能够正常访问。如果安装成功,您将看到n8n的登录页面。
设置管理员账号。
首次访问时,n8n会提示您设置管理员账号和密码。
配置Milvus的Credential。
在n8n控制台左侧导航栏,选择
 > Credential。
> Credential。在Add new credential对话框中,搜索Milvus,单击Continue。
在Milvus account对话框中,配置以下信息,单击Save。

参数
说明
Base URL
填写格式为
http://localhost:19530,需替换localhost为Milvus公网地址。Username
填写为您的Milvus用户。例如,默认的root。
Password
填写为您的Milvus用户的密码。
配置Github的Credential。
在n8n控制台左侧导航栏,选择
> Credential。在Add new credential对话框中,搜索GitHub API,单击Continue。
在GitHub account对话框中,配置以下参数,单击Save。
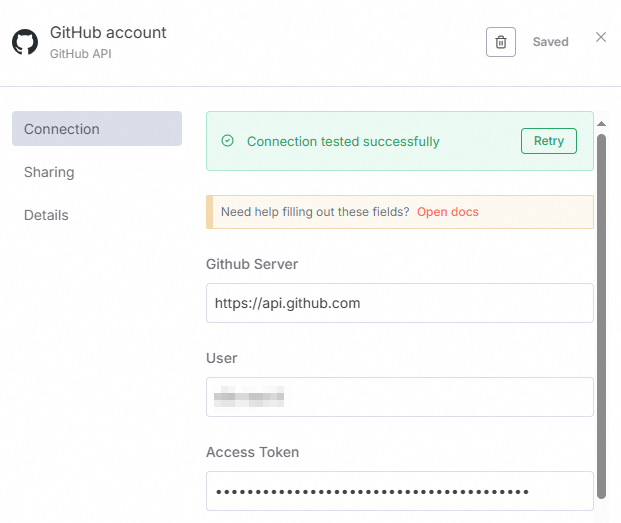
参数
说明
Github Server
GitHub API 的服务端地址。使用默认值即可。
User
GitHub账户的用户名(Username)。
Access Token
GitHub的Token信息。
步骤二:拉取GitHub数据创建知识库
在n8n控制台左侧导航栏,选择
> Workflow。配置List files节点。
在打开的Workflow页面,单击
 ,在右侧选择GitHub的List files节点。
,在右侧选择GitHub的List files节点。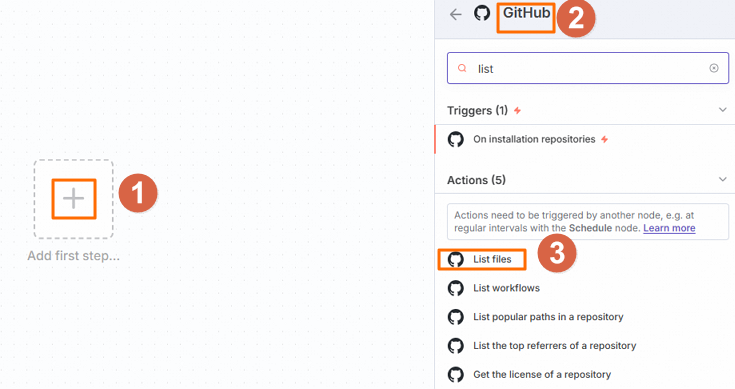
在List files节点中,配置以下参数。
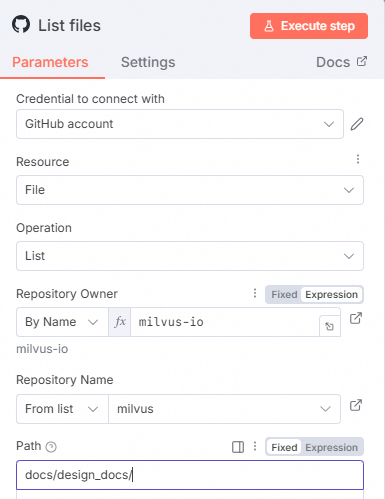
参数
说明
Repository Owner
选择By Name,然后填写仓库Owner,例如,
milvus-io。Repository Name
选择milvus。
Path
指定操作的具体位置。本文示例填写为
docs/design_docs。单击Execute step,查看输出信息。
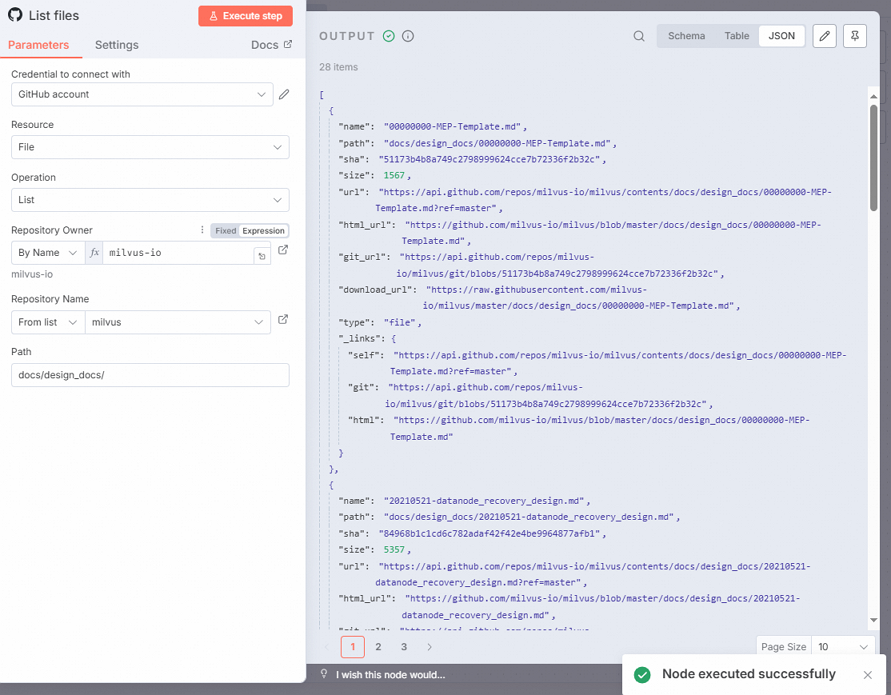
配置Split Out节点。
在工作流页面,单击
,然后在右侧面板中搜索并单击Split Out。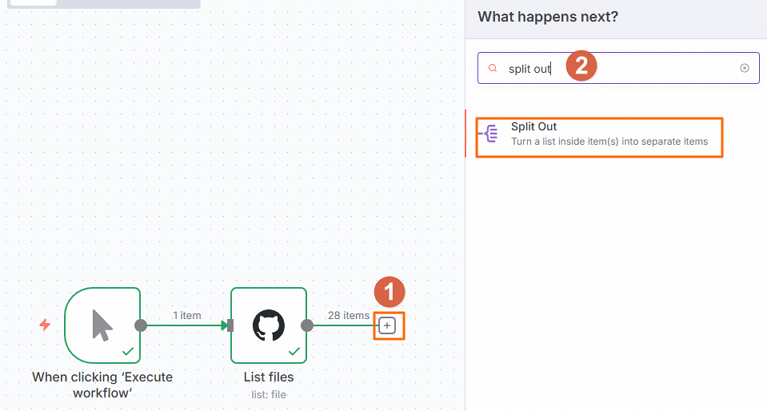
在Split Out节点中,配置Fields To Split Out为download_url,然后单击Execute step。

配置If节点。
为避免在执行后出现null或以.png结尾的文档,从而可能影响后续HTTP获取的准确性,因此我们需要配置一个If Node,以过滤掉null和非.md的链接。
在工作流页面,单击
,然后在右侧面板中搜索并单击If。在If节点中,按照下图配置Conditions,然后单击Execute step。
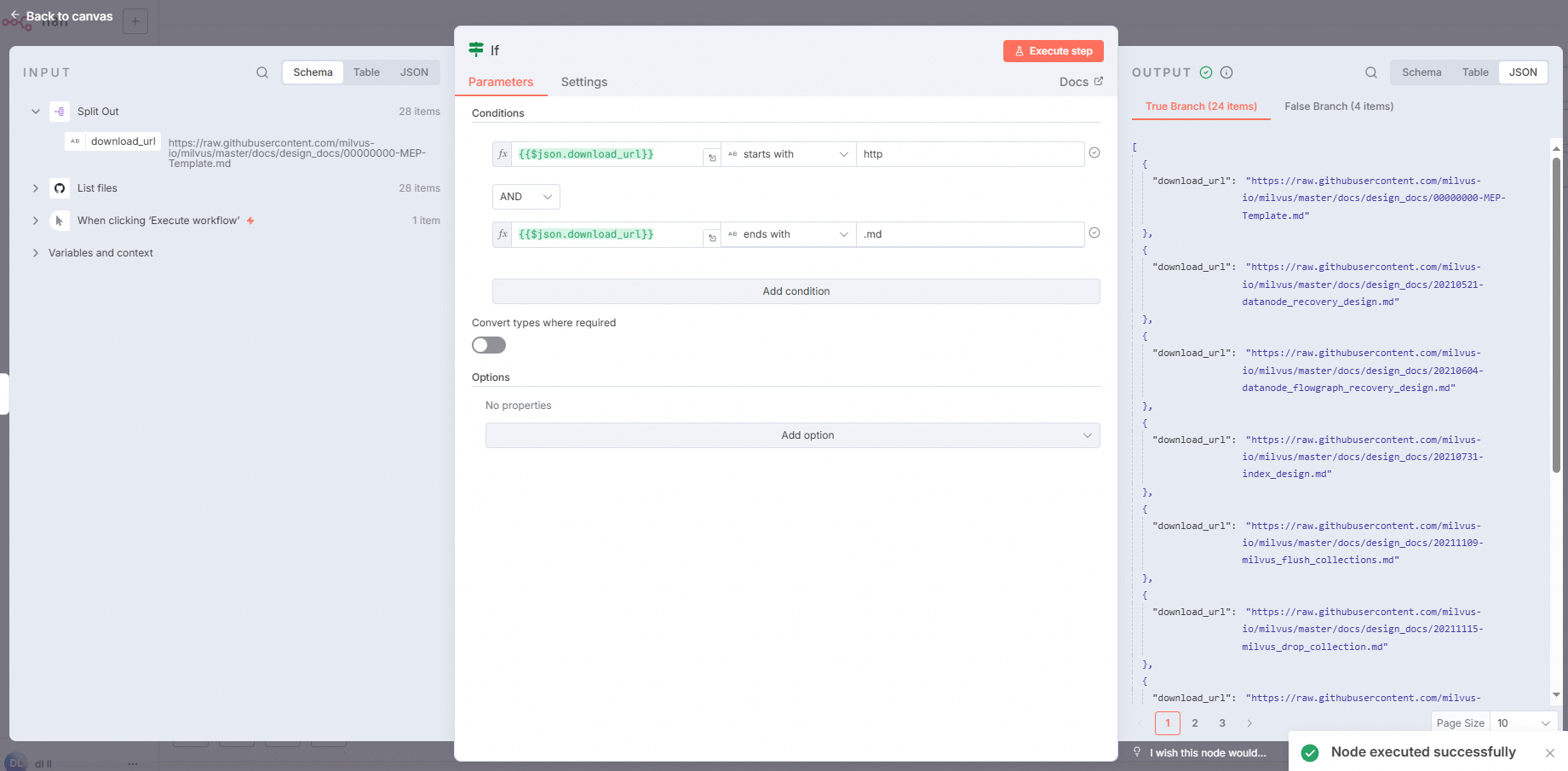
配置Http Request节点。
在工作流页面,单击true所在行的
,然后在右侧面板中搜索并单击Http Request。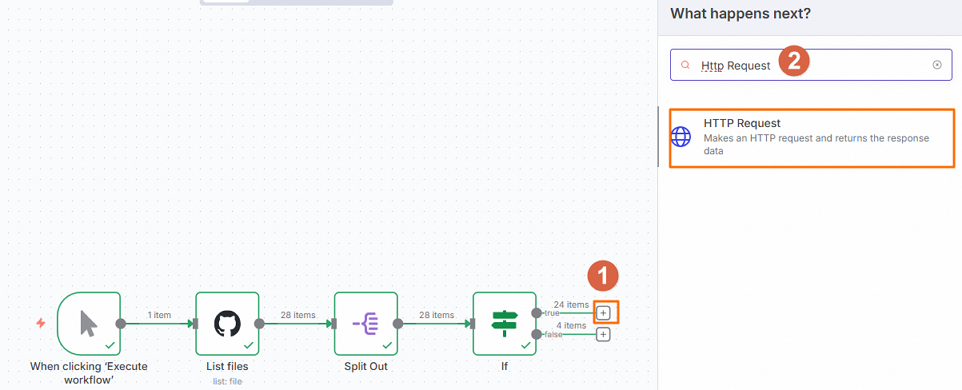
在Http Request节点中,配置URL为
{{ $json.download_url }},然后单击Execute step。
截至目前,我们已成功提取了Milvus官方网站的文档内容。该部分的完整工作流程如下图所示。
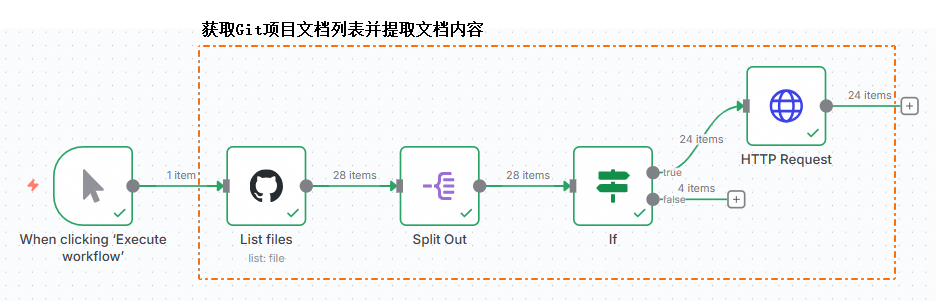
配置Milvus Vector Store节点。
在工作流页面,单击Http Request节点后的
,然后在右侧面板中搜索并选择。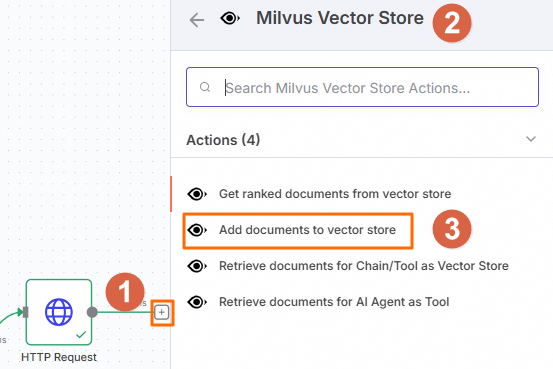
在Milvus Vector Store节点中,配置以下参数。

参数
说明
Milvus Collection
选择By ID,然后填写Collection名称。例如,n8n_test。
Embedding Batch Size
该参数用于控制每次嵌入操作中处理的文档数量。本文设置为25。
Options
单击Add Option,然后打开Clear Collection的开关,这样在每次插入时,将自动清除数据。
在Milvus Vector Store节点的左下角,单击Embedding的
图标,添加embedding模型。在右侧面板中搜索并选择Embeddings OpenAI。
在Embeddings OpenAI节点中,配置以下参数。
在Credential to connect with下拉列表中选择Create new credential。
在弹出的OpenAi account对话框中,配置以下信息后关闭该对话框。
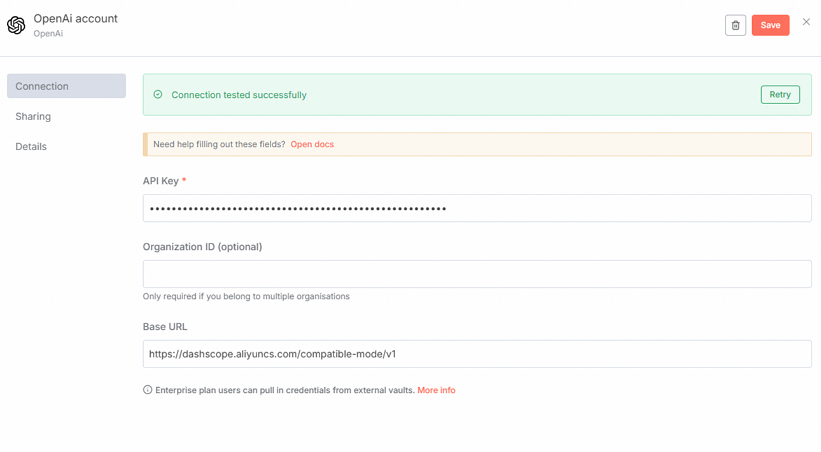
参数
说明
API Key
填写已获取的API Key,具体请参见获取API Key。
Base URL
填写为
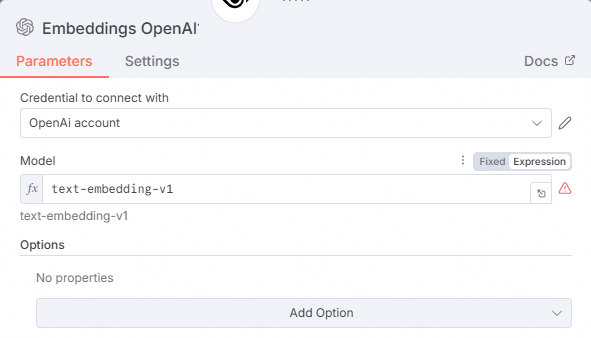
https://dashscope.aliyuncs.com/compatible-mode/v1。在Model下拉列表中选择text-embedding-v1模型。
配置Data Loader。
在工作流页面,单击
图标,选择Default Data Loader。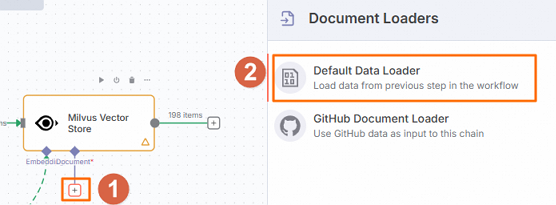
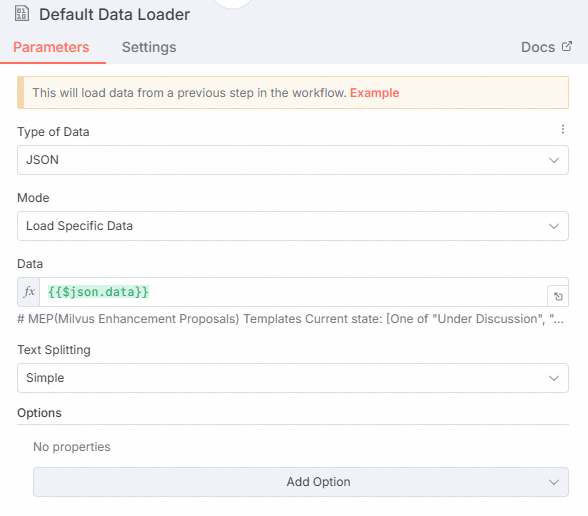
在Default Data Loader节点,配置以下参数。
参数
说明
Mode
选择Load Specific Data。
Data
填写为
{{$json.data}}。
配置Schedule Trigger节点。
考虑到GitHub上文档的实时性,我们需要定期同步所有文档。因此,添加一个Schedule Trigger节点,以定时执行的方式放在工作流的最前面以触发工作流。具体配置如下,我们选择的定期同步周期为每天。
在工作流页面,单击右侧的
图标,搜索并选择Schedule Trigger。单击Back to canvas。
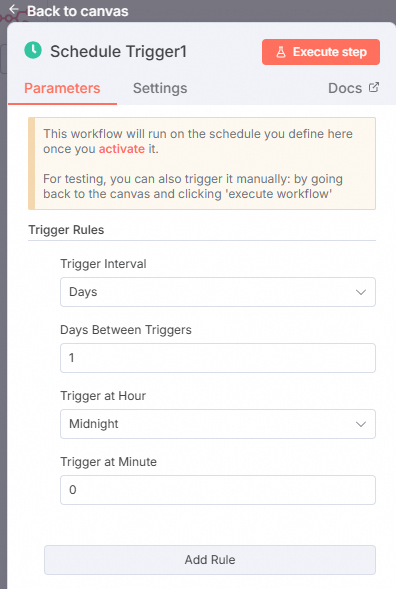
将Schedule Trigger节点放在工作流的最前面。
截至目前,GitHub上提取文档内容及录入Milvus向量库的工作流程已完成配置,如下图所示。
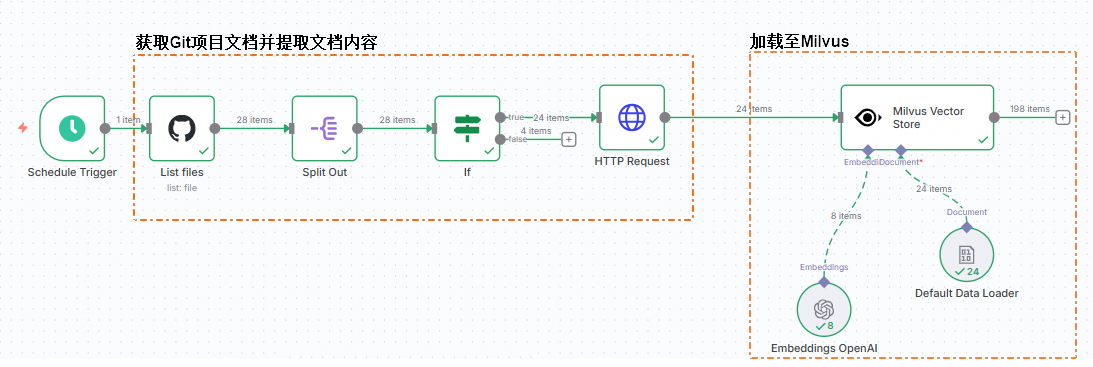
执行工作流并查看日志。
在工作流页面,执行该工作流以查看下方的交互式日志。

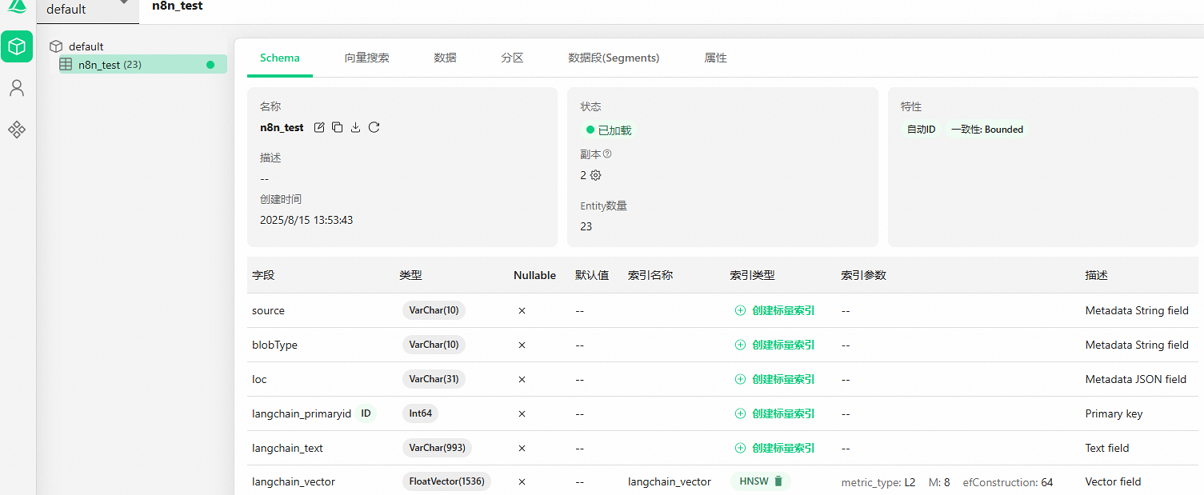
在Milvus控制台验证数据。
步骤三:大模型结合Milvus检索增强实现智能问答
为了实现智能化的问答功能,本例将展示如何通过n8n工作流,结合大语言模型(LLM)和Milvus向量数据库的知识检索能力,构建一个高效的问答系统。
在n8n控制台左侧导航栏,选择
> Workflow。配置When chat message received节点。
在打开的Workflow页面,单击
,在右侧选择On chat message节点。单击Back to canvas。
配置AI Agent节点。
创建一个AI Agent节点,该节点通过接收Chat输入,以便在客户搜索Milvus相关信息时,从之前建立的知识库中进行内容召回。此外,采用大型模型的默认输出进行返回。
在打开的Workflow页面,单击
,在右侧选择AI Agent节点。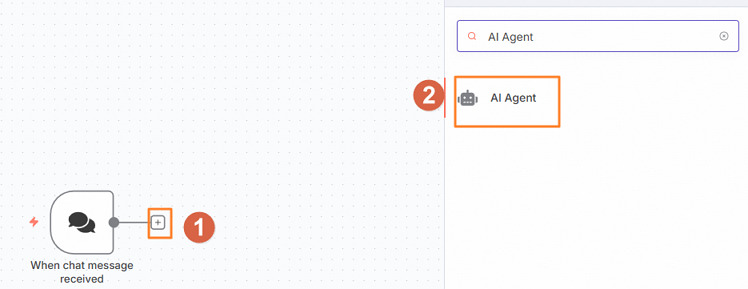
在AI Agent对话框中,单击Add Option,然后选择System Message。在本例中,输入以下内容作为System Prompt。
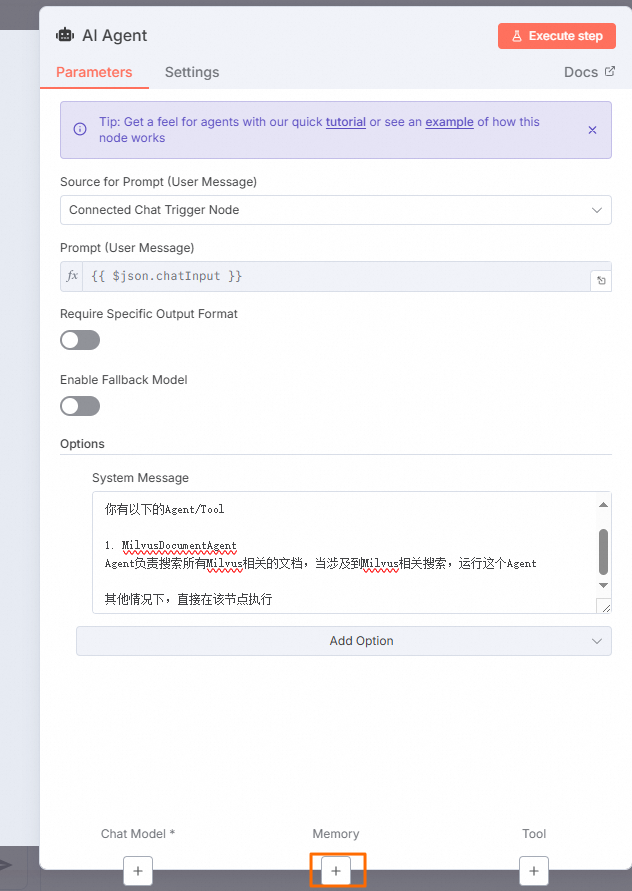
你是主控 AI,负责统筹不同的专业子代理,以执行复杂的用户任务。 你有以下的Agent/Tool 1. MilvusDocumentAgent Agent负责搜索所有Milvus相关的文档,当涉及到Milvus相关搜索,运行这个Agent 其他情况下,直接在该节点执行配置Chat Model节点。
单击下方Chat Model的
。在右侧选择OpenAI Chat Model。
在OpenAI Chat Model对话框中,Model设选用qwen-plus模型。

单击Back to canvas。
配置Memory节点。
单击下方Memory的
。在右侧选择Simple Memory。
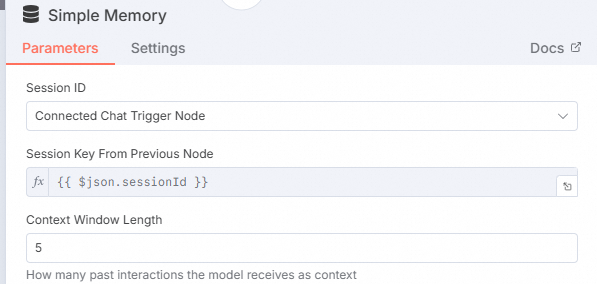
单击Back to canvas。
配置Milvus Vector Store节点。
在工作流页面,单击AI Agent节点Tool的
,然后在右侧面板中搜索并选择Milvus Vector Store。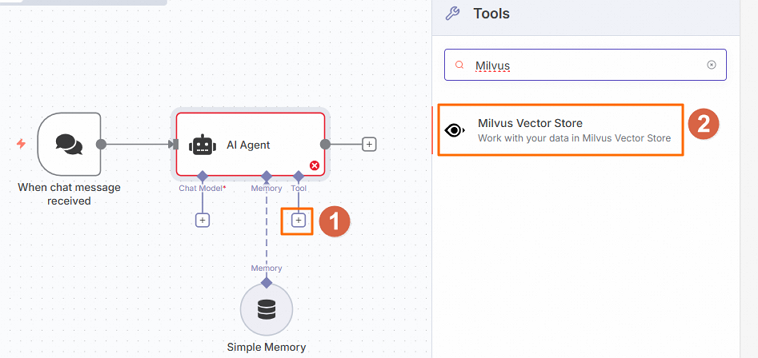
在Milvus Vector Store节点中,填写Description,Milvus Collection选择之前创建知识库的n8n_test。
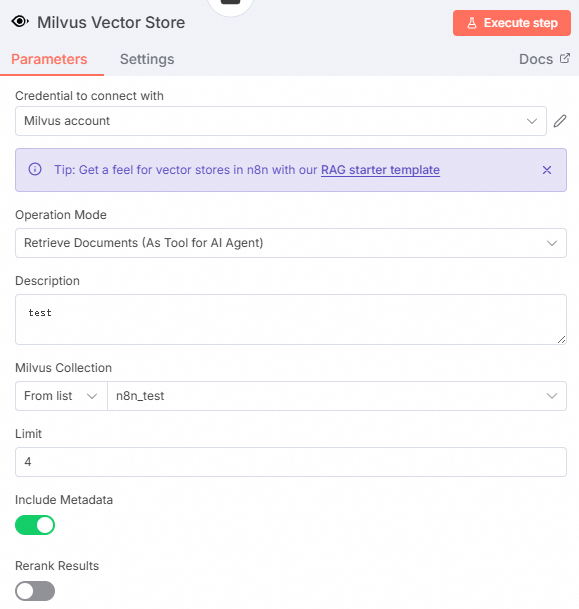
单击下方Embedding的
图标,添加embedding模型。在右侧面板中搜索并选择Embeddings OpenAI。
在Model下拉列表中选择text-embedding-v1模型。
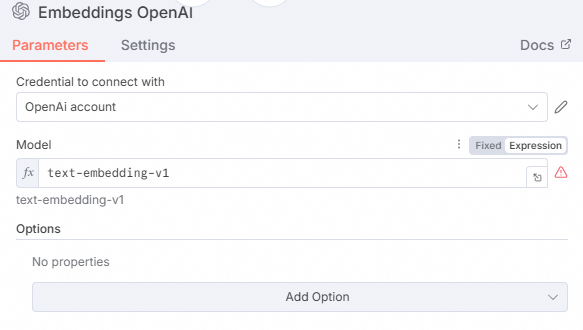
单击Back to canvas。
配置Set节点。
单击AI Agent节点后的
,然后在右侧面板中搜索并选择Edit Fields。
在Edit Fields对话框中,单击Add Field,设置以下信息将本文输出的内容提取出来。
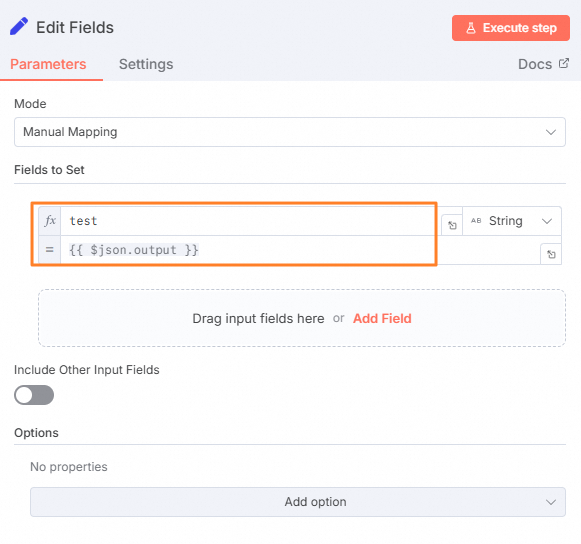
单击Back to canvas。
验证效果。
在Chat输入框中输入以下问题。
Milvus的Data Classification策略有哪些?可以看到AI Agent通过将Milvus知识库召回的内容,结合大模型润色总结,输出了一个可读性较强的内容。
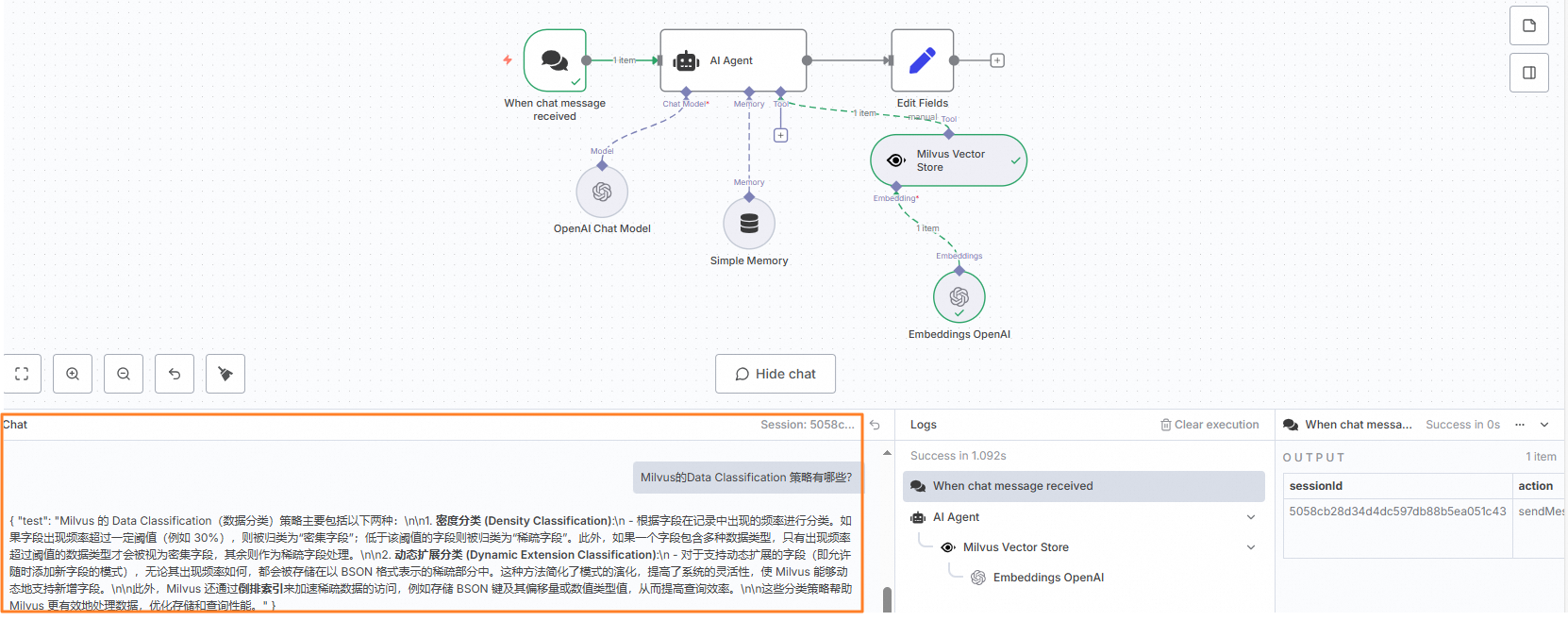
通过上述配置,我们成功实现了大模型与Milvus向量检索的结合,构建了一个智能化的问答系统。该系统不仅能够快速从知识库中召回相关内容,还能借助大模型的能力生成高质量的回答,显著提升了用户体验。