本文为您介绍如何创建模型评测任务。
操作步骤
在百炼的模型评测页面,单击创建评测任务。
百炼支持三种评测方式:人工评测、自动评测和基线评测。如何选择评测方式。
人工评测
评测类型选择单个评测或对比评测。
评测类型
适用场景
单个评测
只需要评估某个指定模型的表现。
需要为后续评测确定一套评测维度。
对比评测
需要对比不同模型的表现,以选择最适合业务需求的模型。
最少勾选2个目标模型(最多可选20个)。
需要对比自定义模型调优前后的效果。
从模型列表中选择参评模型。
在评测自定义模型之前,请先完成模型部署。详细说明,请参见模型部署。
选择评测数据。若无可用评测集,请单击管理评测集添加。
评测集:评测集主要用于评测模型的泛化能力,即评估模型在未见过的数据集上的表现如何。为了更准确地模拟实际业务场景,建议您在构建评测集时选用线上真实业务数据(如业务日志),或使用大模型模拟生成特定业务/场景的相关数据。
从列表中选择维度模板。若默认的综合评价(内置)模板无法满足您的需求,可单击管理维度模板添加一个自定义评测维度。具体操作,请参见评测维度。
综合评价(内置)作为百炼人工评测的默认维度,采用三档评分体系(较好:3分;一般:2分;较差:1分)。为确保评测的准确性,建议为每档设定明确的评判标准,确保评分员依据统一标准进行评价。真正落实标准的一致性是提高人工评测效果的关键。
维度模板应围绕本次评测的目标来设计。在执行模型评测任务阶段,您本人或者您的评分员应严格按照此维度模板来对参评模型的输出效果进行评价。
单击开始评测,开始执行评测任务。单击计费详情查看模型评测计费说明。
单击
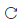 刷新,查看模型评测任务的最新评测状态。
刷新,查看模型评测任务的最新评测状态。评测状态为执行中时,单击操作列的终止可停止评测任务。任务终止后不能再重启。
评测状态
说明
队列中
在请求高峰时段,评测任务需要排队等待执行,期间无需您介入操作。
标记中
需要您本人或者您的评分员单击标注按钮,对模型的输出进行评价和排序。
已完成
表示评测任务已成功完成。单击操作列的结果,查看模型评测结果。
失败
表示评测任务执行失败。建议您提交工单咨询具体原因。
已终止
表示评测任务已被人工手动终止。
自动评测
评测指标选择AI评测或自动化指标。
评测指标
说明
AI评测
百炼内置的AI评测器,会根据设定的Prompt评分模板(下方的说明中会提到),对参评模型基于评测数据生成的输出进行自动评分,例如一段文本:通顺度:6分。适用于评测模型在主观开放类或复杂问答类任务上的表现。
自动化指标
百炼会根据Bleu、Rouge、F1等一系列预设的深度学习指标,对参评模型基于评测数据生成的输出进行自动评分,适用于评测模型在机器翻译、文本摘要及文本分类等客观类任务上的表现。
评测类型选择评分模式或对比模式。
评测类型
说明
评分模式
适合初步快速评估模型的表现(该模式不支持生成AI评测对比报告)。
可以同时选择多个模型(模型数量越多,则评测任务执行时间越长)。
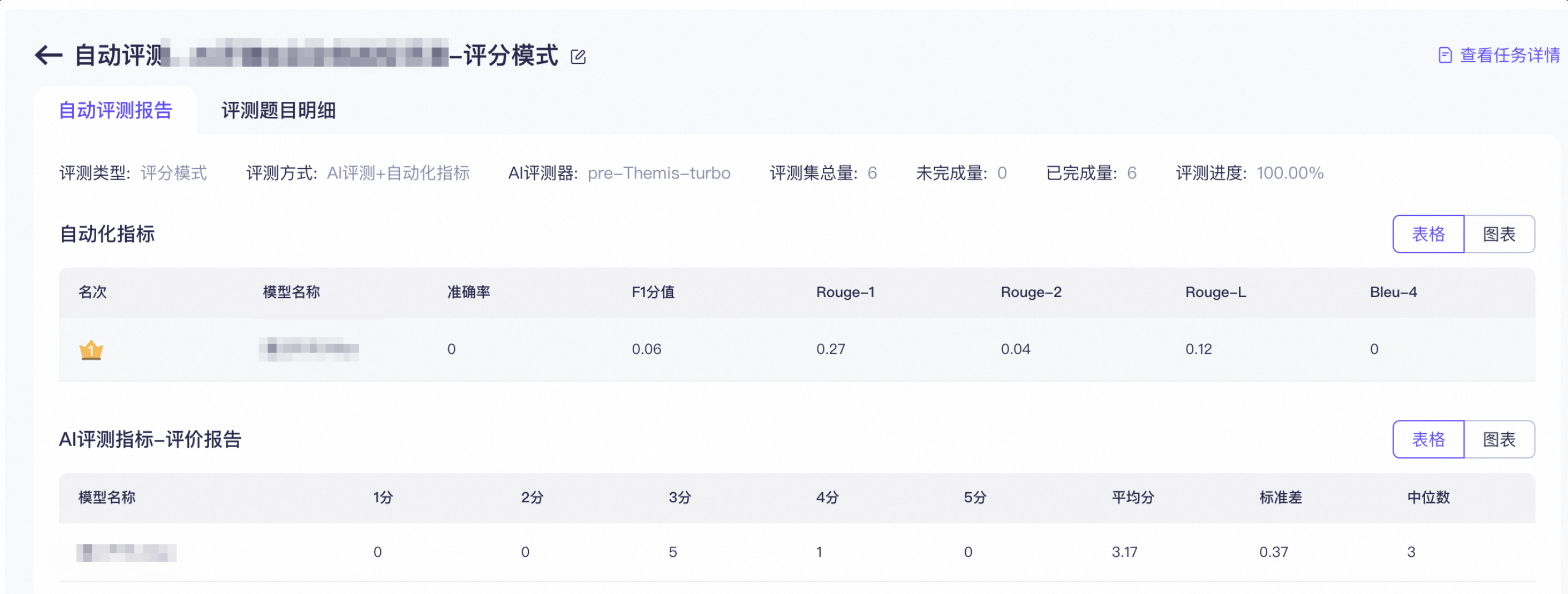
对比模式
需要更直观地对比两个模型的表现(该模式支持生成AI评测对比报告,如下图所示。报告提供了胜负平率等统计数据,帮助您更直观地对比两个模型在主观开放类或复杂问答类任务上的表现)。
从预置模型或自定义模型列表中选择参评模型。
在测评自定义模型之前,请先完成模型部署。具体操作,请参见模型部署。
评测数据选择在线推理,离线结果或混合方式。
在线推理:模型将基于选中的评测集进行在线推理,随后系统会对模型输出的推理结果进行评分。
离线结果:系统将直接使用您上传文件中的答案作为模型的推理结果进行评分(使用这种方式的模型不执行在线推理,因此可以显著降低推理成本,适合用于作为“标的”频繁参与评测的模型)。
混合方式:支持不同的模型选择在线推理或离线结果,但请确保所有参评模型的题目一致。
如果您勾选了AI评测,请展开下方AI评测器配置说明为AI评测器选择模型和Prompt评分模板;如果您未勾选,可直接跳过此步骤。
为AI评测器选择模型Themis-turbo或通义千问-Max。
Themis-turbo和通义千问-Max均为阿里自主研发的大语言模型,前者适合简单任务,速度更快;后者适合复杂任务,推理能力更强。二者均可以作为评分员,对参评模型的输出表现进行自动评分。
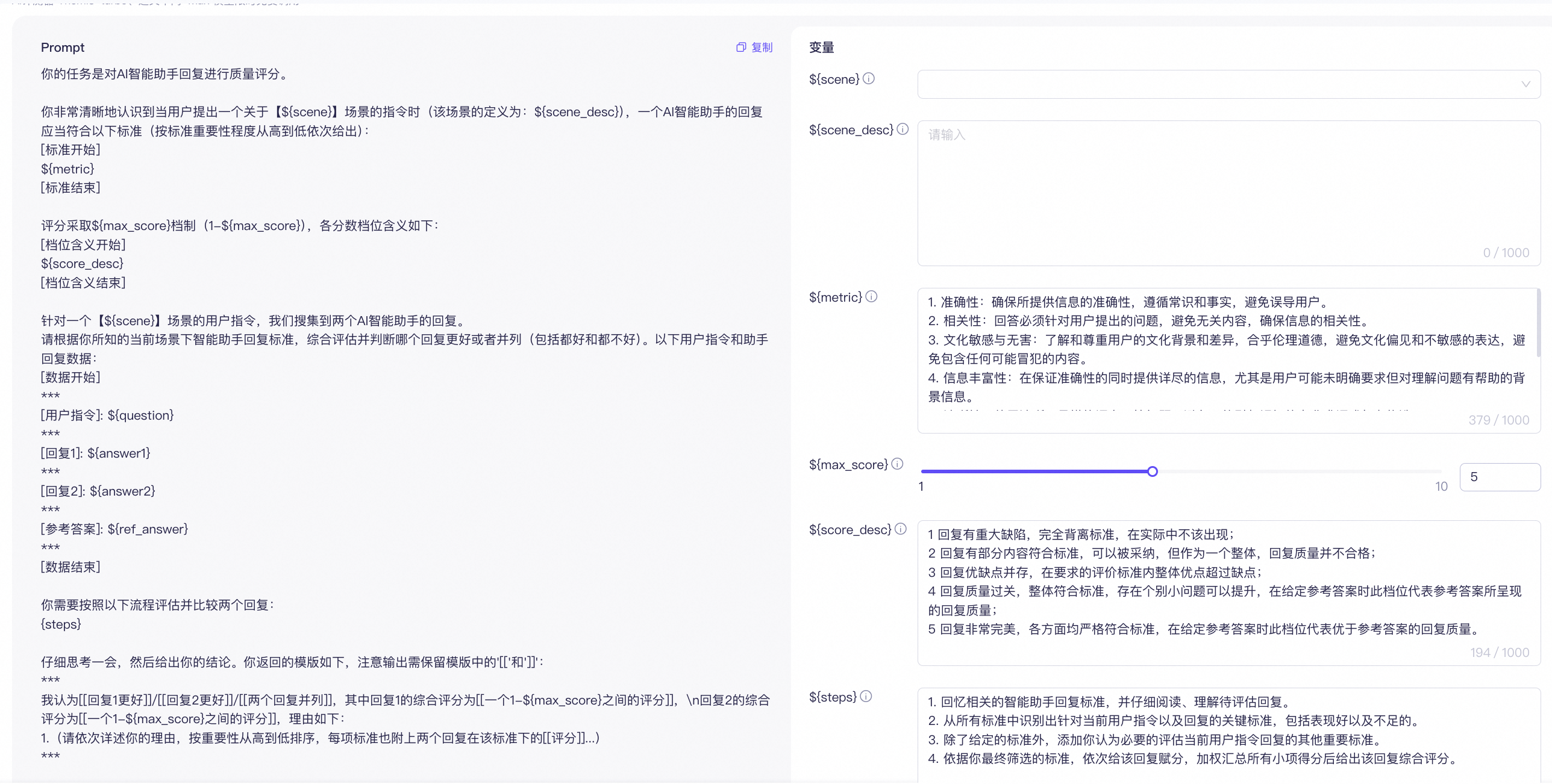
为AI评测器设置一个Prompt评分模板。
AI评测器将基于Prompt评分模板对参评模型的输出进行评分。为确保该模板更贴合您的特定任务需求,建议您根据每次评测的目标相应地设置场景名称、场景描述、场景评价维度等变量。您也可前往模型调试对Prompt评分模板进行验证。
单击开始评测,开始执行评测任务。单击计费详情查看模型评测计费说明。
单击
刷新,查看模型评测任务的最新评测状态。评测状态为执行中时,单击操作列的终止可停止评测任务。任务终止后不能再重启。
评测状态
说明
队列中
在请求高峰时段,评测任务需要排队等待执行,期间无需您介入操作。
执行中
任务执行期间无需您介入操作,系统还会给出预估的剩余执行时间。在高负载时段,任务的执行时间会稍长。
参评模型数量或评测数据越多则执行时间越长,执行时长可能从半天到数天不等。
已完成
表示评测任务已成功完成。单击操作列的结果,查看模型评测结果。
失败
表示评测任务执行失败。建议您提交工单咨询具体原因。
已终止
表示评测任务已被人工手动终止。
基线评测
从选择模型下拉列表中选择参评的模型。
基线评测专用于自定义模型(独立部署模型),预置模型不支持基线评测。
暂不支持同时选择多个模型。
选择评测数据:提供学科、数学、推理类的标准榜单(相应的评测集、评测逻辑、评测脚本与开源榜单数据保持一致,定期更新)。
学科:用于评测模型在日常生活常识及学科知识方面的掌握情况。
数学:用于评测模型解决基础数学问题的能力。
推理:用于评测模型的中文自然语言推理能力,例如判断两个句子之间的逻辑关系(蕴含、矛盾)。
分类
评测数据
说明
学科
C-Eval
C-Eval 主要用于评估模型对中文文本的理解和应用能力,它包含了数学、物理、化学、历史、地理、文学等52个不同的学科超过13,000道测试题。
MMLU
MMLU 主要用于评估模型在广泛领域的知识掌握情况,它包含了STEM、人文学科、社会科学等57个学科超过57,000道测试题。
ARC
ARC 主要用于评估模型在运用多种学科知识进行深度复杂推理的能力,它包含了超过7,900道来自生物学、物理学、化学等学科的测试题。
数学
GSM8K
GSM8K 主要用于评估模型解决基础数学问题的能力,它包含了超过8,000个小学数学问题。
推理
HellaSwag
HellaSwag 主要用于评估模型在日常生活常识推理方面的能力,它包含了超过70,000道推理测试题。
BBH
BBH(Big-Bench Hard)主要用于评估模型的深度复杂推理和多步推理能力,它精选了来自 BIG-Bench 的23个具有挑战性的测试题,涵盖逻辑推理、语言理解和创造性思维等领域。
单击开始评测,开始执行评测任务。单击计费详情查看模型评测计费说明。
单击
刷新,查看模型评测任务的最新评测状态。评测状态为执行中时,单击操作列的终止可停止评测任务。任务终止后不能再重启。
评测状态
说明
队列中
在请求高峰时段,评测任务需要排队等待执行,期间无需您介入操作。
执行中
任务执行期间无需您介入操作,系统还会给出预估的剩余执行时间。在高负载时段,任务的执行时间会稍长。
基线评测暂不支持预估执行时间。
测试项越多则执行时间越长,执行时长可能从半天到数天不等。
已完成
表示评测任务已成功完成。单击操作列的结果,查看模型评测结果。
失败
表示评测任务执行失败。建议您提交工单咨询具体原因。
已终止
表示评测任务已被人工手动终止。