开通百炼不会产生费用,调用大模型实现文本生成、图片生成、语音合成等任务时,会产生模型推理(调用)费用。此外,如果训练(调优)新模型或将模型部署到实例也会产生费用。

您可以在账单详情和成本分析页面查询已经产生的费用。更多问题请参考:账单常见问题。
使用时发生余额不足、欠费等情况请直接前往费用与成本页面充值需要的金额。更多问题请参考:计费常见问题。
当然您可以在百炼控制台-调用统计页面查看您某个具体模型的调用次数和消耗Token数。
计费项
计费项 | 计费说明 | 计费方式 | 计费公式 |
模型推理(调用) | 完整的模型调用价格和免费额度,请参考模型列表。 详细的 RPM、TPM 等性能信息请参考限流。 | 按模型调用量计费 (可预付费) | 推理(调用)费用 = 调用消耗 × 推理(调用)单价 在免费额度内,实时调用不会产生费用。查看免费额度请参考新人免费额度。 |
模型调优 | 模型训练完成后获得的新模型必须进行模型部署后才能评测和调用。 | 按训练的数据量计费 | 训练费用 = (训练数据 Token 总数 + 混合训练数据 Token 总数)× 循环次数 × 训练单价(最低为 0.006元/千Token) 在开始训练前会显示预估费用和计费详情。 |
| 按时间计费 (可包月预付费) | 部署费用 = 使用时长 × 实例数量 × 实例单价 支持模型丰富 | |
按模型调用量计费 | 部署费用 = 调用消耗 × 部署后调用单价 单价与模型推理(调用)单价相同 |
模型推理(调用)计费
完整的模型调用价格和免费额度,请参考模型列表。详细的 RPM、TPM 等性能信息请参考限流。可以在百炼控制台-调用统计页面查看您某个具体模型的调用次数和消耗Token数。
计费公式:
文本
文本生成费用 = 模型输入 Token 数 × 模型输入单价 + 模型输出 Token 数 × 模型输出单价(最低为 0.0003元/千Token,最小计费单位:1 token)
图像转成Token:每28×28像素对应一个Token;一张图最少4个Token。
文本向量、多模态向量、文本分类、文本抽取、文本排序费用 = 模型输出 Token 数 × 模型单价(最低为 0.0007元/千Token,最小计费单位:1 token)
图像
图像生成费用 = 模型输出图片张数 × 单价(最低为 0.06元/张)
完整的模型调用价格和免费额度表格请前往:图像生成-通义万相与图像编辑
语音
语音合成(文本转语音)费用 = 输入字符数 × 单价(最低为 1元/万字符)
根据待合成字符数计费(其中1个汉字算2个字符,英文、标点符号、空格均按照1个字符计费)。
语音识别(语音转文本)费用 = 语音时间 × 单价(最低为 0.00008元/秒)
视频
有的需要进行模型部署后才能使用,有的根据生成时长或动态图片张数计费。
完整的价格明细和免费额度请前往:视频生成、合成计费表。
免费额度
如何获取免费额度以及如何查看剩余免费额度请参考新人免费额度。
预付费(节省计划)
您可以购买节省计划(预付费),用于抵扣模型推理超出免费额度后产生的推理费用。节省计划用完后,系统会开始使用账户余额扣费,您也可以购买多个节省计划进行抵扣。
购买方式:单击此处购买大语言模型推理节省计划。
适用范围:通义千问、通义法睿、百川-开源版、ChatGLM以及OpenNLU模型。请前往模型列表获取完整的模型的调用价格和免费额度。
使用说明:使用百炼时,将优先消耗节省计划的额度。如果购买了多个节省计划,抵扣时将按节省计划到期时间的先后顺序抵扣。如果到期时间相同,先购买的节省计划将优先抵扣。
退订规则:退订规则请提交工单进行咨询。
查询节省计划账单:请参考如何查询节省计划账单。
旗舰模型
其他模型的调用价格和免费额度,请参考模型列表。
旗舰模型 |
适合复杂任务,推理能力最强 |
效果、速度、成本均衡 |
适合简单任务,速度快、成本低 |
支持长达千万字文档,成本低 |
API调用模型名 (稳定版本) | qwen-max | qwen-plus | qwen-turbo | qwen-long |
最大上下文长度 (Token数) | 32,768 | 131,072 | 1,000,000 | 10,000,000 |
最低输入价格 (每千Token) | 0.02元 | 0.0008元 | 0.0003元 | 0.0005元 |
最低输出价格 (每千Token) | 0.06元 | 0.002元 | 0.0006元 | 0.002元 |
Batch 调用减免
通义千问模型qwen-max、qwen-plus、qwen-turbo、qwen-long、qwen-vl-max、qwen-vl-plus,qwq-32b-preview支持 Batch 调用,调用费用为实时调用的 50%。Batch调用不支持其他类型优惠(免费额度、Context Cache等)。
您可以通过文件方式提交批量任务,任务将异步执行,系统将在任务执行完成或设置的最长等待时间到达后返回任务执行结果。您可以通过控制台或API两种方式使用批量推理任务。
Context Cache(上下文缓存)计费
当前仅 qwen-plus 模型支持Context Cache功能。更多详细信息请参考Context Cache(上下文缓存)。
开启 Context Cache 模式无需额外付费。若您的请求被系统判断命中了 Cache,被命中的 Token 会按照 cached_token 来计费,cached_token的单价为input_token单价的40%;未被命中的 Token 仍按照 input_token计费。假设某一次请求的输入 Token 数为10,000,有5,000个 Token 被系统判断命中了 Cache,则 input_token 的计费为未开启 Context Cache 模式的 70%[(50% 未命中 Cache Token)*100%单价 + (50% 命中 Cache Token)*40%单价] )。计费示意图如下:
output_token仍按原价计费。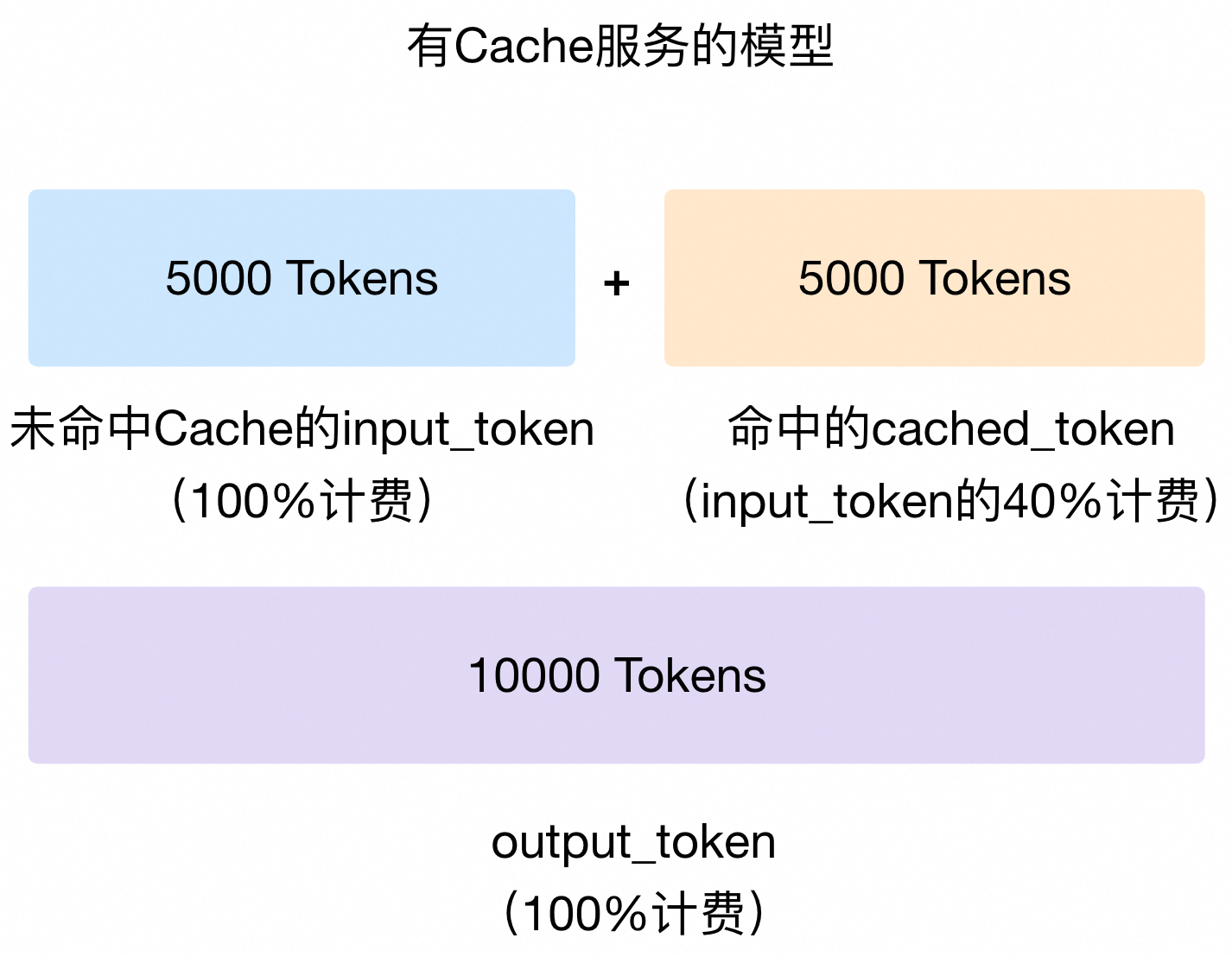
您可以从返回结果的cached_tokens属性获取命中 Cache 的 Token 数。
如果您通过Batch方式调用,则无法享受 Cache 的折扣。
模型评测计费
模型评测是否产生费用取决于评测的对象:
对已经部署的模型进行评测:只收取模型部署费用,评测不额外收费。
对其他模型进行评测:按照 Token 消耗量计费。
模型训练计费(模型调优)
计费方式 | 计费公式 |
按训练的数据量计费 | 模型训练费用 = (训练数据 Token 总数 + 混合训练数据 Token 总数)× 循环次数 × 训练单价(最小计费单位:1 token) 您可以查看模型训练控制台底部的预估训练费用,并单击计算详情,查看训练 Token 总数、循环次数和训练单价。 |
模型服务 | 模型规格 | 价格 |
通义千问2.5-开源版-72B | qwen2.5-72b-instruct | 0.15元/千Token |
通义千问2-开源版-72B | qwen2-72b-instruct | |
通义千问1.5-开源版-72B | qwen1.5-72b-chat | |
通义千问-开源版-72B | qwen-72b-chat | |
通义千问-Plus-0723 | qwen-plus-0723 | |
通义千问VL-Max-0201 | qwen-vl-max-0201 | |
通义千问2.5-开源版-32B | qwen2.5-32b-instruct | 0.03元/千Token |
通义千问2.5-开源版-14B | qwen2.5-14b-instruct | |
通义千问1.5-开源版-14B | qwen1.5-14b-chat | |
通义千问-开源版-14B | qwen-14b-chat | |
通义千问-Plus | qwen-plus | |
通义千问Turbo | qwen-turbo | |
通义千问-Turbo-0624 | qwen-turbo-0624 | |
通义千问VL-Plus | qwen-vl-plus | |
通义千问2.5-开源版-7B | qwen2.5-7b-instruct | 0.006元/千Token |
通义千问2-开源版-7B | qwen2-7b-instruct | |
通义千问1.5-开源版-7B | qwen1.5-7b-chat | |
通义千问-开源版-7B | qwen-7b-chat |
模型部署计费
按时间
按时间计费方式都支持手动扩缩容,灵活调整并发量。
按使用时长计费的计费粒度更小(小时),使用灵活。
包月计费的计费周期长(天),但更加便宜(7折)。
计费方式 | 计费公式 |
按使用时长计费 | 费用 = 使用时长(小时)× 实例数量 × 模型对应的实例单价(不满1小时按1小时计费) 部署前可以在模型部署控制台查看不同模型的预估每小时费用。 |
包月计费/预付费 | 费用 = 购买时长(月)× 实例数量 × 模型对应的实例单价 购买资源:请前往模型部署控制台(点击右上角的资源池管理)购买。(资源购买完成后便开始计费) 退订资源:请前往主账号的退订管理退订。退订后,将根据未用时长退回未使用金额。(不满1天按1天计费) |
模型服务 | 独占实例资源规格 | 实例单价 | 实例单价(预付费) |
悦动人像EMO-detect-deployment | 轻量版 | 20元/实例/小时 | 10,000元/月 |
悦动人像EMO-deployment | |||
舞动人像AnimateAnyone-detect | |||
舞动人像AnimateAnyone | |||
通义万相-文本生成图像-0521 | |||
通义千问-Turbo | 基础版 | 40元/实例/小时 | 20,000元/月 |
通义千问1.5-开源版-7B | |||
通义千问1.5-开源版-14B | |||
基于通义千问2-开源版-7B训练出来的模型 | 基础版v2-Qwen2 | - | 20,000元/月 |
通义千问-Plus | 标准版 | 160元/实例/小时 | 80,000元/月 |
通义千问1.5-开源版-72B | |||
通义千问1.5-开源版-110B | |||
基于通义千问2-开源版-72B训练出来的模型 | 标准版v2-Qwen2 | - | 80,000元/月 |
通义千问-Max | 高级版 | 320元/实例/小时 | 160,000元/月 |
基于通义千问VL-Plus训练出来的模型 | - | 40元/实例/小时 | - |
基于通义千问VL-Max-0201训练出来的模型 | - | 160元/实例/小时 | - |
当模型完成部署,即状态为“运行中”时,开始收取模型部署的费用。模型状态为“部署中”、“欠费”、“部署失败”时,均不会计费。
如果是包月预付费,资源购买后便开始消耗包月时间。
模型部署后性能参考
(由于 QPM 受调用的 Token 长度影响较大,仅供参考)
模型名称 | 每实例参考处理能力 |
qwen-plus | 70 QPM |
按模型调用量
按模型调用量计费方式价格很低。而如果需要进一步增加并发量,需要部署后在模型部署控制台手动申请,平台会进行人工审批。
计费方式 | 计费公式 |
按模型调用量 | 费用 = 模型输入 Token 数 × 模型输入单价 + 模型输出 Token 数 × 模型输出单价(最小计费单位:1 token) |
支持的自定义模型
一个模型是可以在百炼的模型调优中进行重复训练的。
只有在基于以下基础模型,且只进行一次“SFT高效训练”后获得的自定义模型,才支持按调用量计费。
基础模型 | 输入单价 | 输出单价 |
通义千问 2.5-开源版-72B | 0.004元/千Token | 0.012元/千Token |
通义千问 2.5-开源版-32B | 0.0035元/千Token | 0.007元/千Token |
通义千问 2.5-开源版-14B | 0.002元/千Token | 0.006元/千Token |
通义千问 2.5-开源版-7B | 0.001元/千Token | 0.002元/千Token |
通义千问 2-开源版-7B | 0.001元/千Token | 0.002元/千Token |
调用统计
您可以在百炼控制台-调用统计页面查看已部署的模型的调用统计数据。
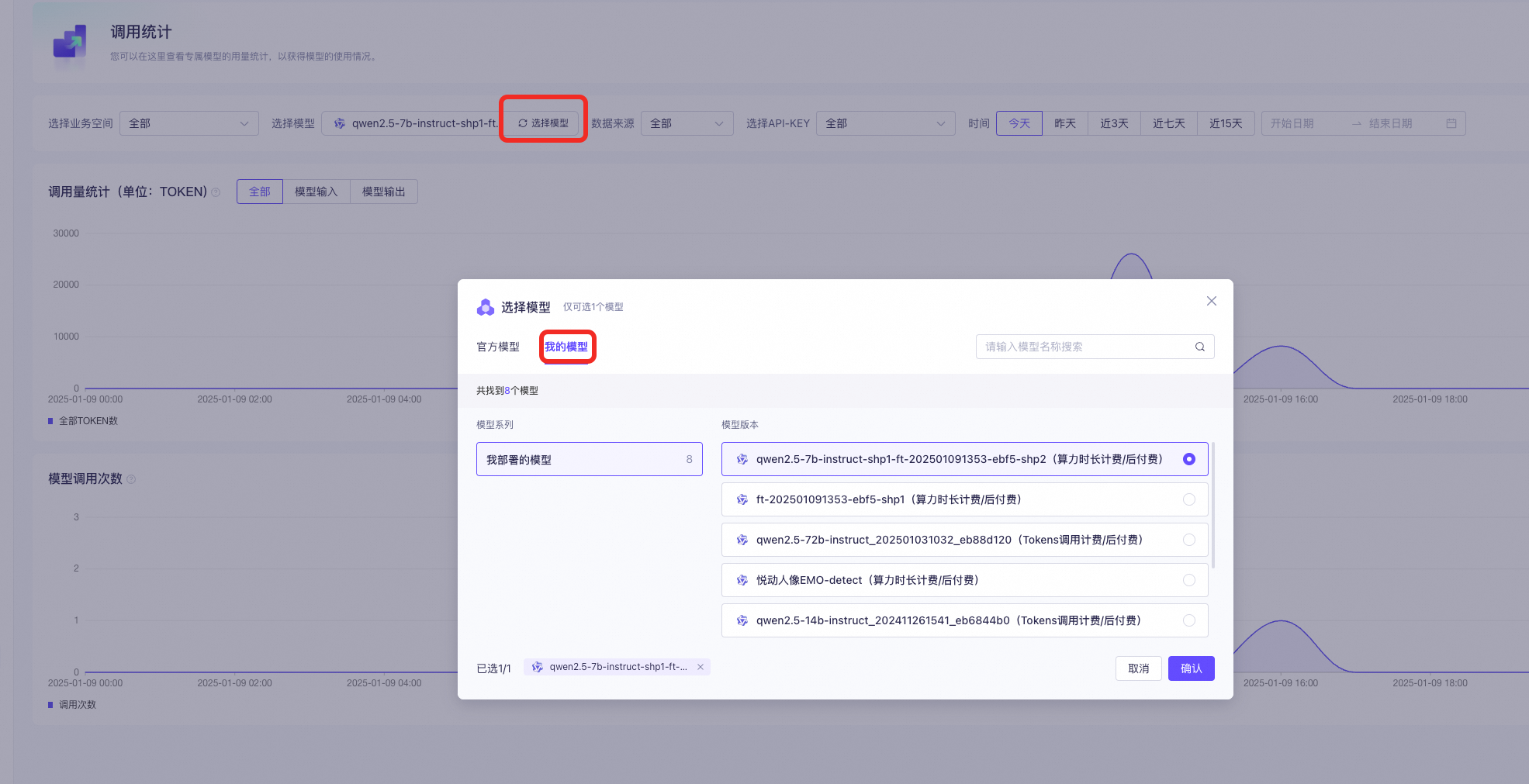
计费常见问题
如何付费?
使用时发生余额不足、欠费等情况请直接前往费用与成本页面充值需要的金额。
预付费方法:
模型推理(调用):单击此处购买大语言模型推理节省计划。
模型部署:请前往模型部署控制台模型部署(点击右上角“资源池管理”)购买实例或查看已购买的实例信息。
模型训练:不支持预付费。
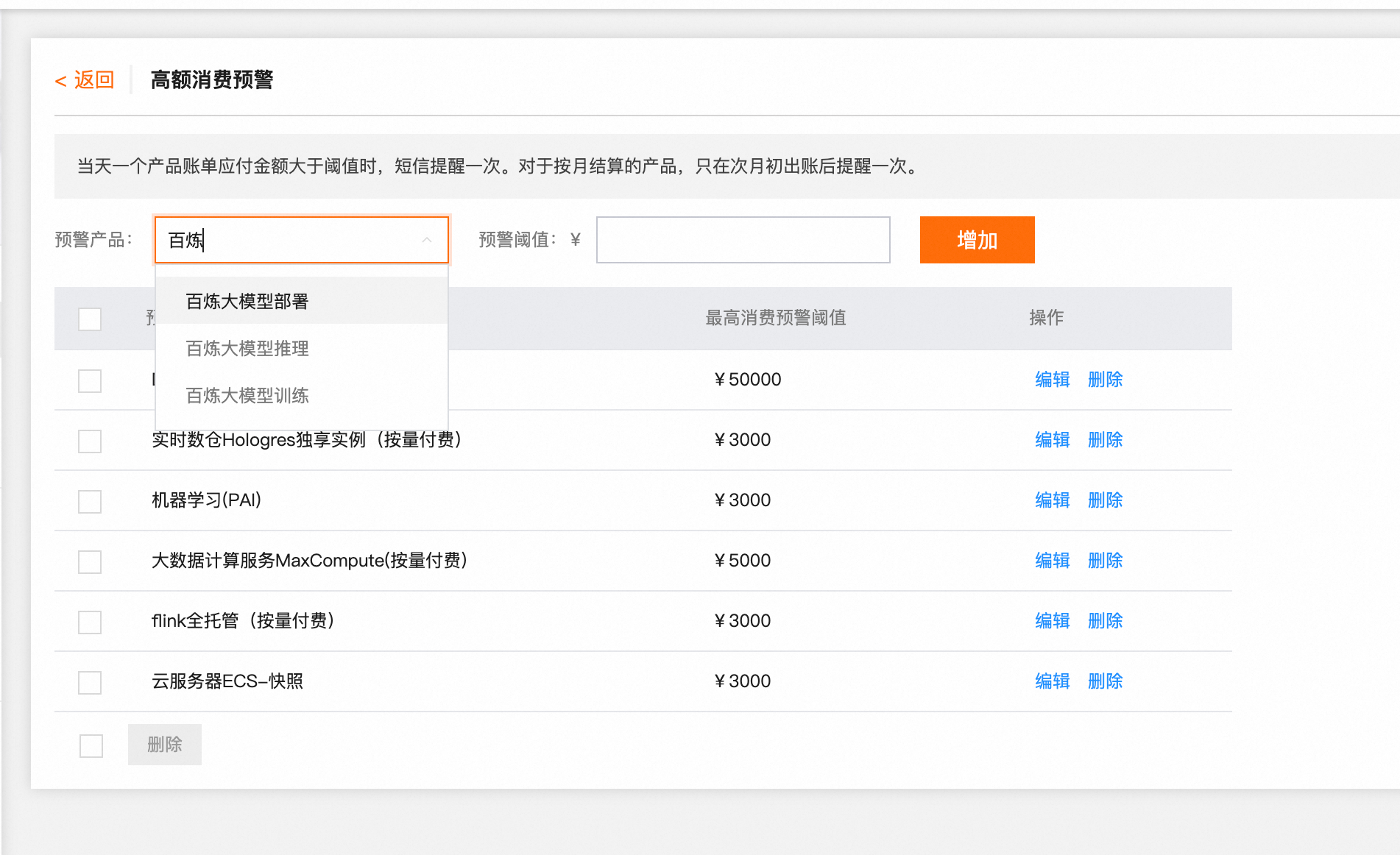
如何预警大额计费?
您可以在费用与成本中心设置高额消费预警。
如何关闭计费、关闭按量付费、关闭按调用量计费?
按量、按调用量计费方式无法关闭,您只要不再使用百炼的功能,就不会产生费用。
为防止意外的API调用费用,您可以删除百炼的API Key。
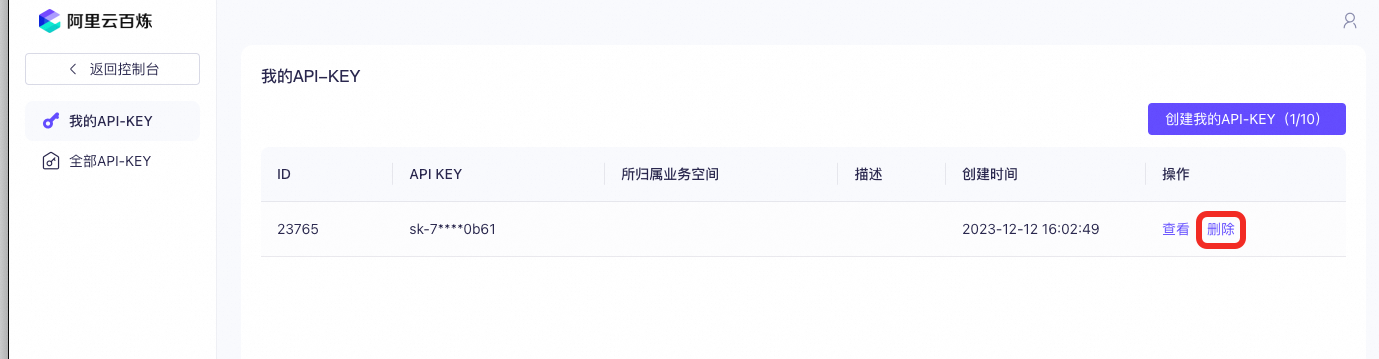
您也可以设置高额消费预警,将预警阈值设置为一个较低值,阿里云将在产生意外扣费时第一时间通知您,避免您产生更多损失。
如何计算 Token 数?
Token是模型用来表示自然语言文本的基本单位,可以直观地理解为“字”或“词”。
对于中文文本,1个Token通常对应一个汉字或词语。例如,“你好,我是通义千问”会被转换成['你好', ',', '我是', '通', '义', '千', '问']。
对于英文文本,1个Token通常对应3至4个字母或1个单词。例如,"Nice to meet you."会被转换成['Nice', ' to', ' meet', ' you', '.']。
不同的大模型切分Token的方法可能不同。您可以使用SDK在本地查看经过通义千问模型切分后的Token数据。
本地运行的tokenizer可以用来估计文本的Token量,但是得到的结果不保证与模型服务端完全一致,仅供参考。如果您对通义千问的tokenizer细节感兴趣,请参考: tokenizer参考。
如何统计调用量?
当然您可以在百炼控制台-调用统计页面查看您某个具体模型的调用次数和消耗Token数。
多轮对话怎么计费?
在多轮对话中,历史对话的输入输出都会作为新一轮的模型输入 token 进行计费。
怎么增加并发量?
如果您需要进一步提高模型的RPM或TPM,请发送邮件至modelstudio@service.aliyun.com进行申请,并在邮件中告知阿里云主账号uid、期望申请的模型和RPM和TPM。申请通过后,您可以在模型广场中找到目标模型并单击查看详情,查看更新后的限流数据。
如果是独立部署的模型,部署完成后控制台有按钮可以操作扩容,详情请查看模型部署。
大模型应用会收费吗?
只创建应用不会收费。但如果调用应用进行了问答,则会根据调用的模型类型收取模型调用费用。
取消模型训练会收费么?
会,如果您主动取消训练,之前已产生的费用仍会被计算。其他原因导致的训练中断,百炼平台不会向您收取训练费用。
模型部署什么时候开始计费?
当模型完成部署,即状态为运行中时,开始收取模型部署的费用。模型状态为部署中、欠费、部署失败时,均不会计费。
如果是包月预付费,模型状态为运行中后,开始消耗包月时间。
模型部署是否可以暂停计费?
没有暂停计费的方法,但您可以通过以下方式终止计费:
对于包月预付费实例,您可以在下线实例后,在退订管理页面,退订购买的预付费资源。退订时,将从实付金额中扣除已消费金额,退回剩余金额。具体说明请参考退订说明。
按小时、按模型调用量付费的实例,您可以下线实例。实例下线后,将不再产生模型部署费用。
账单常见问题
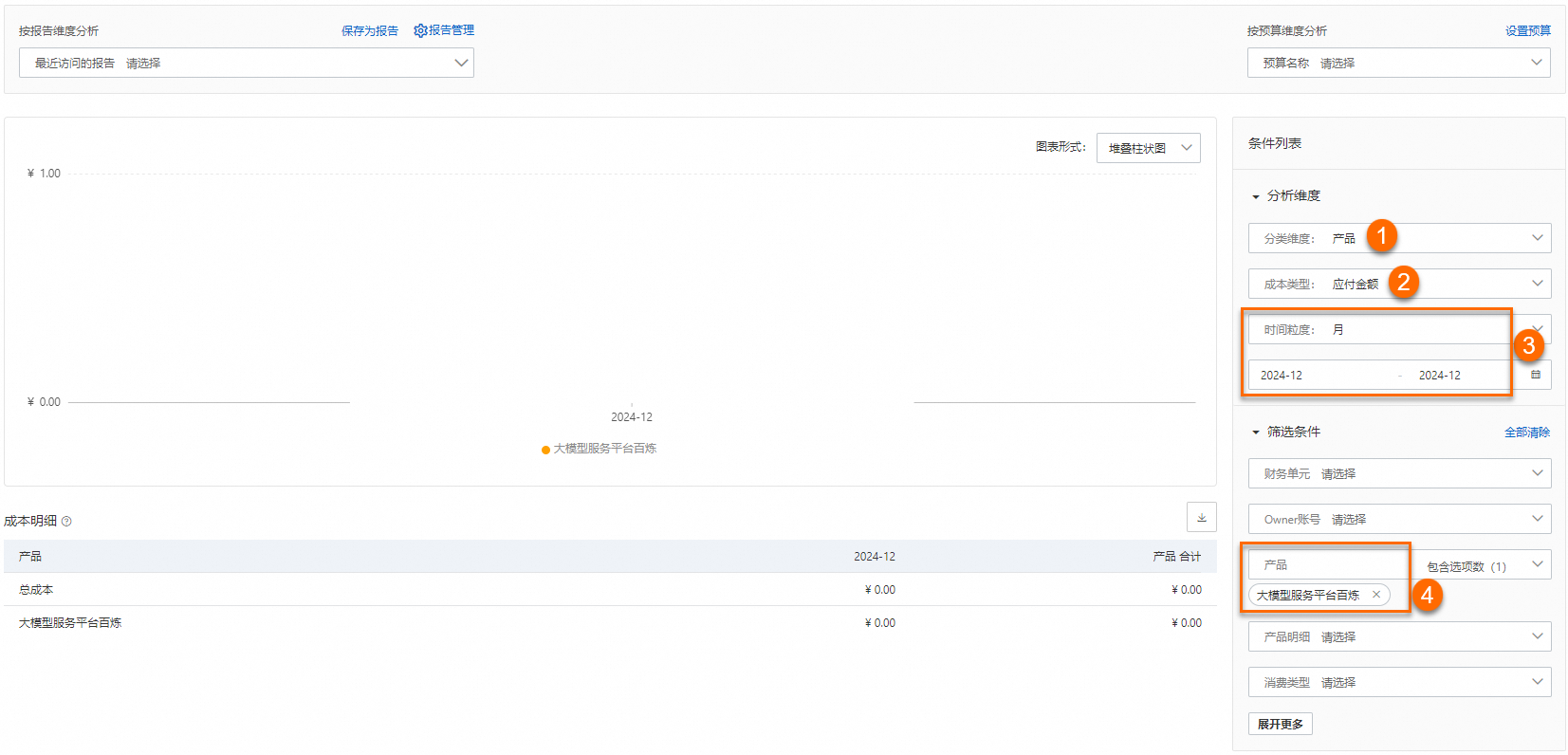
查看百炼的成本支出
在成本分析页面,成本类型选择应付金额,时间粒度选择月,选择时间范围(假设为2024年12月),产品选择大模型服务平台百炼,即可查看所选时间范围内百炼的成本支出。
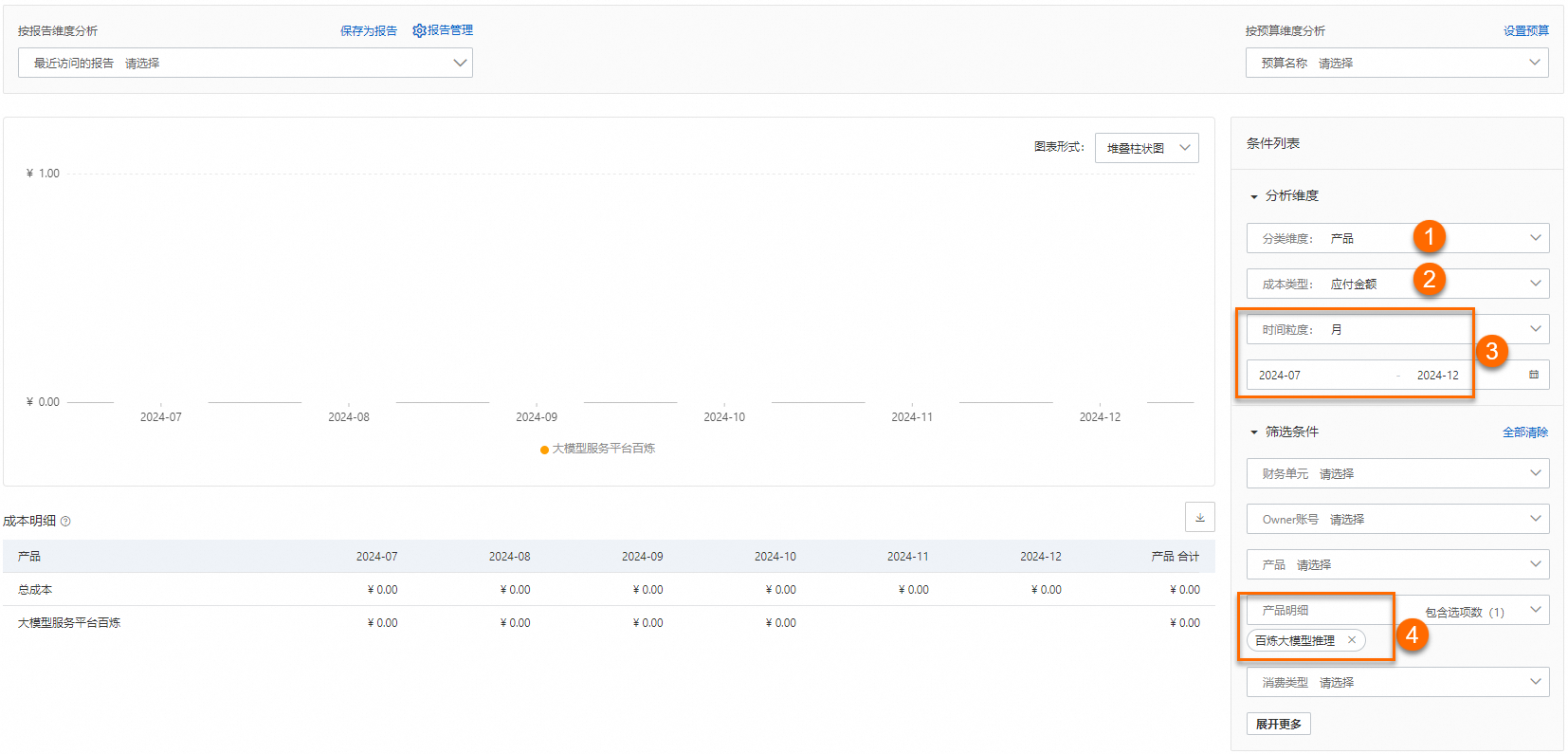
查看模型推理总消费
在成本分析页面,成本类型选择应付金额,时间粒度选择月,选择时间范围(假设为2024年07月~12月),产品明细选择百炼大模型推理,即可查看所选时间范围内模型推理总花费。
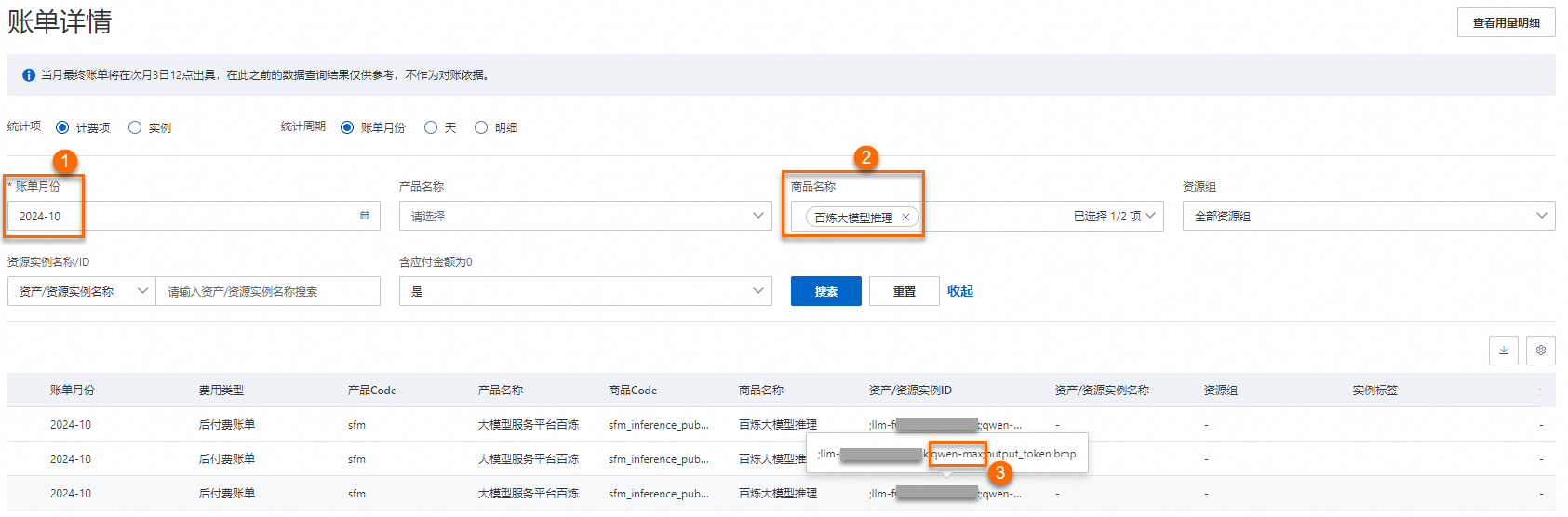
查看具体模型的推理花费
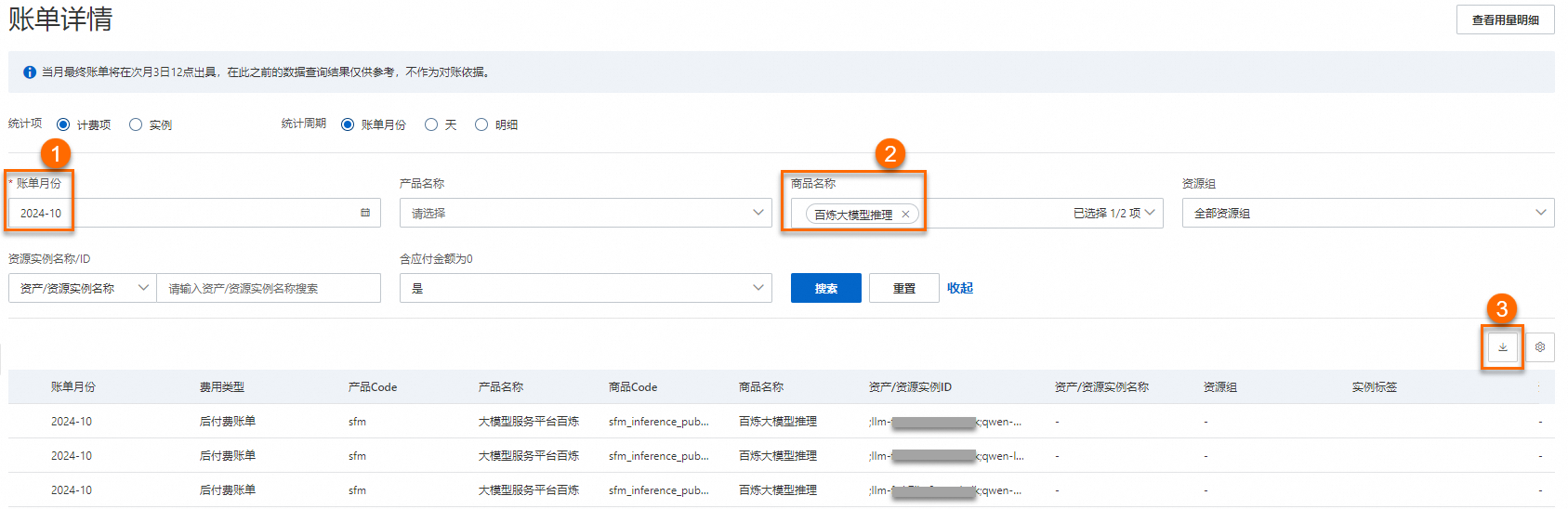
以模型 qwen-max 为例。在账单详情页面,选择账单月份,再选择商品名称为百炼大模型推理,单击搜索。
在资产/资源实例ID列找到所有与qwen-max相关的实例。将这些实例对应的应付金额相加,即可得出所选账期内调用qwen-max模型进行模型推理所支付的费用。
如何对大模型推理明细账单进行分账?
自2024年9月7日以后产生的大模型推理账单,可通过ApiKeyID、业务空间ID、模型名称、输入/输出类型、调用渠道进行分账。
在账单详情页面,选择账单月份,再选择商品名称为百炼大模型推理,单击搜索。将搜索结果下载到本地,按照资产/资源实例ID列的内容进行分账。
完整的资产/资源实例ID,例如12xxx;llm-xxx;qwen-max;output_token;app,依次表示ApiKeyID;业务空间ID;模型名称;输入/输出类型;调用渠道。如果您的资产/资源实例ID中没有包含ApiKeyID,则表示该收费项是通过控制台调用产生的。
完整的实例ID,例如text_token;llm-xxx;qwen-max;output_token;app,依次表示计费类型;业务空间ID;模型名称;输入/输出类型;调用渠道。
您可以前往百炼API Key管理查看API Key与ApiKeyID的对应关系。
调用渠道包括app、bmp及assistant-api。app表示通过应用调用模型,bmp表示通过控制台首页或模型体验调用模型,assistant-api表示通过Assistant API调用模型。
抵扣券或者优惠券相关
如果有抵扣券或者优惠券,产生的费用如何扣费?
阿里云扣费顺序请前往阿里云后付费账单扣款顺序查询。