
无论是平台的预置模型还是您调优后的模型,您可通过部署获得独立的、资源专享的推理服务,以满足您对高并发、低延迟等不同性能的业务需求。
计费方式
部署前可以在模型部署控制台查看不同模型的预估每小时费用。
计费方式在服务创建后无法更改。如需切换,必须下线已经部署的模型后再重新部署。
|
预置吞吐(PTU,Provisioned Throughput Unit) (高吞吐;高性能) |
模型单元 (自定义性能指标;资源隔离) |
Token 用量 (调优后按量计费/效果验证) |
|||
|
定义 |
通过平台预留资源,保障特定TPM 吞吐能力的模型部署方式;在保障额度内不限速。 |
按使用时长与模型单元数量配置算力,资源独占的模型部署方式。 |
以每次调用产生的输入 Token 与输出 Token 作为用量计量依据的模型部署方式。 |
||
|
优势 |
|
|
不使用不计费。 |
||
|
支持模型 |
部分预置模型 |
部分预置模型与所有调优后模型 |
部分经过 LoRA 调优后的模型 |
||
|
使用场景 |
|
|
调优后模型效果验证 |
||
|
计费图示 |
|
|
|
||
|
计费方式 |
按使用时长和预置吞吐 随用随付、包天 |
按使用时长和模型单元数量 随用随付、包月 |
按模型 Token 使用量 随用随付 |
||
|
扩缩容方式 |
自助增减吞吐量 |
自助增减模型单元数量 |
在控制台提交申请,等待人工审核。 |
||
|
产品约束 |
|
预付费购买后,若在首月内提前退订,日单价(≈ 月单价 / 30)将按 1.2 倍计费 |
|
||
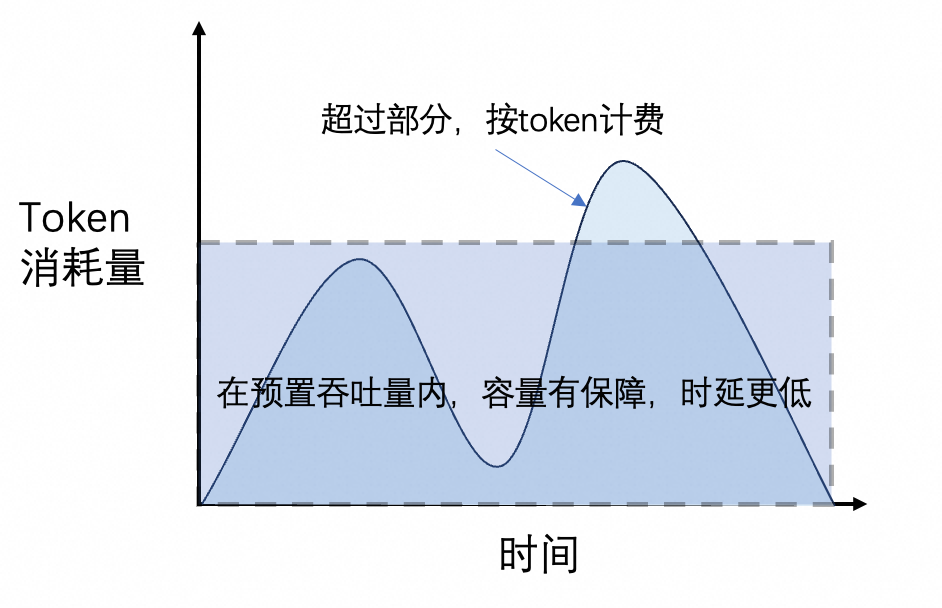
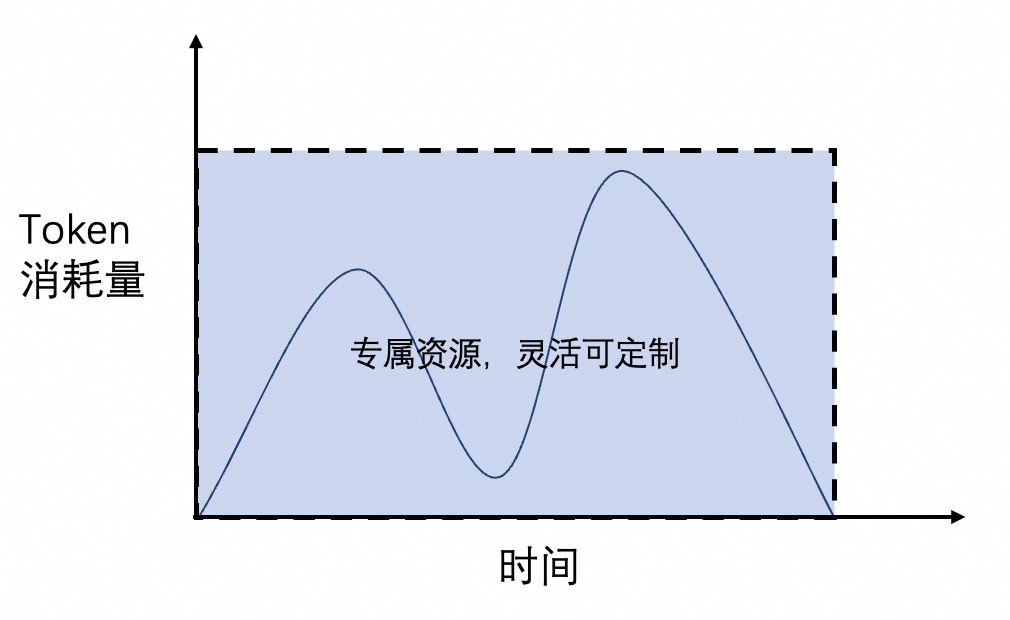
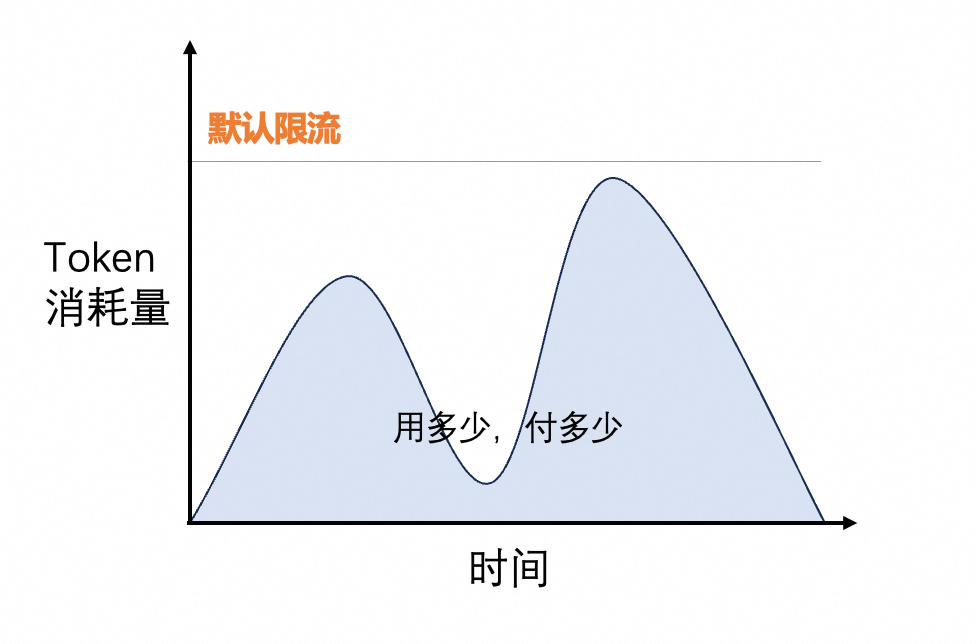
如需查看单次调用的 Token 使用量及调用次数历史统计,请前往:模型监控。
计费详情
按使用时长计费(预置吞吐)
费用 = 使用时长 × (输入 TPM 单价 × 输入 TPM + 输出 TPM 单价 × 输出 TPM)
后付费按小时计算:使用时长单位为小时,单价取下表"持续 1 小时"列;预付费按天计算:使用时长单位为天,单价取下表"持续 1 天"列。
-
预付费订单支付后实时生效,有效期 N 天至第 N 天 23:59 结束。若在 22:00 后下单,到期日将自动顺延1天。
-
预付费订单到期后,将延后2小时停止服务,停止后资源保留14小时后释放。
-
预付费订单无法提前终止服务。
-
后付费时,如果账户欠费,部署的资源将继续保留并计费 24 小时,在这 24 小时内服务仍可正常使用。超过 24 小时后系统停止计费,模型部署进入欠费状态,底层资源将被删除,但模型部署任务仍会保留。补足欠费后,系统将重新分配资源并恢复使用(恢复后继续产生费用)。如果您不希望继续产生费用,可删除模型部署任务,删除成功后将不再计费。
当模型输入超过最长输入 Token 或 超出购买的 TPM 量时,相关调用将自动切换为当前模型的按量付费模式。此时,推理性能可能下降,将受业务空间中当前快照模型的公共流量的管控,费用按模型调用(按量付费)标准计收。
-
此时,调用 API 返回 Header 将包含:
x-dashscope-ptu-overflow:true。 -
TPM 统计请前往:模型监控(北京)。
缩容场景(降配)的具体降费退费规则请参考:降配退款规则说明。
千问
|
模型名称 |
模型代码 |
最长输入Token |
后付费输入 Per 10K TPM/小时 |
后付费输出 Per 1K TPM/小时 |
预付费输入 Per 10K TPM/天 |
预付费输出 Per 1K TPM/天 |
|
千问3.7-Max-2026-05-20 |
qwen3.7-max-2026-05-20 |
256K |
¥28.8 |
¥8.64 |
¥345.6 |
¥103.68 |
|
千问3.7-Plus-2026-05-26 |
qwen3.7-plus-2026-05-26 |
256K |
¥4.8 |
¥1.92 |
¥57.6 |
¥23.04 |
|
千问3.6-Plus-2026-04-02 |
qwen3.6-plus-2026-04-02 |
128K |
¥4.8 |
¥2.88 |
¥57.6 |
¥34.56 |
|
千问3.5-Plus-2026-04-20 |
qwen3.5-plus-2026-04-20 |
128K |
¥1.92 |
¥1.15 |
¥23.04 |
¥13.82 |
|
千问3-Max-2025-09-23 |
qwen3-max-2025-09-23 |
128K |
¥7.68 |
¥3.08 |
¥92.16 |
¥36.96 |
|
千问-Flash-2025-07-28 |
qwen-flash-2025-07-28 |
128K |
¥0.36 |
¥0.36 |
¥4.32 |
¥4.32 |
|
千问-Plus-2025-12-01 |
qwen-plus-2025-12-01 |
128K |
¥1.92 |
非思考:¥0.48 思考:¥1.92 |
¥23.04 |
非思考:¥5.76 思考:¥23.04 |
DeepSeek
|
模型名称 |
模型代码 |
最长输入Token |
后付费输入 Per 10K TPM/小时 |
后付费输出 Per 1K TPM/小时 |
预付费输入 Per 10K TPM/天 |
预付费输出 Per 1K TPM/天 |
|
DeepSeek-v4-Flash |
deepseek-v4-flash |
256K |
¥3.6 |
¥0.72 |
¥43.2 |
¥8.64 |
|
DeepSeek-v4-Pro |
deepseek-v4-pro |
256K |
¥43.2 |
¥8.64 |
¥518.4 |
¥103.68 |
|
DeepSeek-v3.2 |
deepseek-v3.2 |
64K |
¥7.2 |
¥1.08 |
¥86.4 |
¥12.96 |
|
DeepSeek-v3 |
deepseek-v3 |
64K |
¥7.2 |
¥2.88 |
¥86.4 |
¥34.56 |
千问VL
|
模型名称 |
模型代码 |
最长输入Token |
后付费输入 Per 10K TPM/小时 |
后付费输出 Per 1K TPM/小时 |
预付费输入 Per 10K TPM/天 |
预付费输出 Per 1K TPM/天 |
|
千问3-VL-Plus-2025-09-23 |
qwen3-vl-plus-2025-09-23 |
128K |
¥2.4 |
¥2.4 |
¥28.8 |
¥28.8 |
更多模型
|
模型名称 |
模型代码 |
最长输入Token |
Per 10K TPM/小时 |
后付费输出 Per 1K TPM/小时 |
预付费输入 Per 10K TPM/天 |
预付费输出 Per 1K TPM/天 |
|
GLM-5.2 |
glm-5.2 |
1M |
¥28.8 |
¥10.08 |
¥345.6 |
¥120.96 |
|
GLM-5.1 |
glm-5.1 |
64K |
¥21.6 |
¥8.64 |
¥259.2 |
¥103.68 |
按使用时长计费(模型单元)
费用 = 使用时长(小时)× 模型单元数量 × 模型单元单价
"模型单元单价"在后付费场景下取下表"小时单价"列;预付费按月计费时,公式改为 包月数 × 模型单元数量 × 月单价。
-
预付费购买的首月,如在首月内提前退订,日单价(≈ 月单价 / 30)将按 1.2 倍计费(不满一天按一天计费)
模型单元-后付费方式的算力资源先买到先得。如购买不成功会全额退款。
文本生成
千问
|
模型名称 |
模型代码 |
模型单元规格 |
小时单价(元) 最小计费:分钟 |
包月单价(元) 最小计费:天 |
|
千问3.7-Plus-2026-05-26 |
qwen3.7-plus-2026-05-26 |
MU3 x 8 |
¥1,096 |
¥527,752 |
|
千问3.6-35B-A3B |
qwen3.6-35b-a3b |
MU8 x 1 |
¥47 |
¥22,400 |
|
MU9 x 1 |
¥51 |
¥24,600 |
||
|
千问3.6-27B |
qwen3.6-27b |
MU9 x 1 |
¥51 |
¥24,600 |
|
千问3.6-Flash-2026-04-16 |
qwen3.6-flash-2026-04-16 |
MU1 x 2 |
¥108 |
¥52,236 |
|
千问3.6-Plus-2026-04-02 |
qwen3.6-plus-2026-04-02 |
MU1 x 8 MU1 x 16(PD分离模式) |
¥432 PD分离模式:¥864 |
¥208,944 PD分离模式:¥417,888 |
|
千问3.5-397B-A17B |
qwen3.5-397b-a17b |
MU2 x 8 |
¥504 |
¥240,288 |
|
MU3 x 8 MU3 x 16(PD分离模式) |
¥1,096 PD分离模式:¥2,192 |
¥527,752 PD分离模式:¥1,055,504 |
||
|
MU6 x 16 |
¥400 |
¥193,424 |
||
|
千问3.5-122B-A10B |
qwen3.5-122b-a10b |
MU1 x 4 |
¥216 |
¥104,472 |
|
MU2 x 8 |
¥504 |
¥240,288 |
||
|
MU6 x 16 |
¥400 |
¥193,424 |
||
|
MU9 x 2 |
¥102 |
¥49,200 |
||
|
千问3.5-35B-A3B |
qwen3.5-35b-a3b |
MU1 x 2 |
¥108 |
¥52,236 |
|
MU2 x 8 |
¥504 |
¥240,288 |
||
|
MU8 x 1 |
¥47 |
¥22,400 |
||
|
MU9 x 1 |
¥51 |
¥24,600 |
||
|
千问3.5-27B |
qwen3.5-27b |
MU9 x 1 |
¥51 |
¥24,600 |
|
千问3.5-9B |
qwen3.5-9b |
MU8 x 1 |
¥47 |
¥22,400 |
|
MU9 x 1 |
¥51 |
¥24,600 |
||
|
千问3.5-Flash-2026-02-23 |
qwen3.5-flash-2026-02-23 |
MU1 x 2 |
¥108 |
¥52,236 |
|
千问3.5-Plus-2026-02-15 |
qwen3.5-plus-2026-02-15 |
MU1 x 16(PD分离模式) |
PD分离模式:¥864 |
PD分离模式:¥417,888 |
|
MU3 x 8 MU3 x 16(PD分离模式) |
¥1,096 PD分离模式:¥2,192 |
¥527,752 PD分离模式:¥1,055,504 |
||
|
千问3-235B-A22B-Instruct-2507 |
qwen3-235b-a22b-instruct-2507 |
MU1 x 4 |
¥216 |
¥104,472 |
|
MU2 x 8 |
¥504 |
¥240,288 |
||
|
千问3-Next-80B-A3B-Instruct |
qwen3-next-80b-a3b-instruct |
MU1 x 2 |
¥108 |
¥52,236 |
|
千问3-32B |
qwen3-32b |
MU1 x 4 |
¥216 |
¥104,472 |
|
MU6 x 4 |
¥100 |
¥48,356 |
||
|
千问3-30B-A3B |
qwen3-30b-a3b |
MU9 x 2 |
¥102 |
¥49,200 |
|
千问3-30B-A3B-Instruct-2507 |
qwen3-30b-a3b-instruct-2507 |
MU1 x 4 |
¥216 |
¥104,472 |
|
MU2 x 8 |
¥504 |
¥240,288 |
||
|
千问3-8B |
qwen3-8b |
MU1 x 2 |
¥108 |
¥52,236 |
|
MU2 x 2 |
¥126 |
¥60,072 |
||
|
MU5 x 1 |
¥21 |
¥10,139 |
||
|
千问3-4B |
qwen3-4b |
MU1 x 2 |
¥108 |
¥52,236 |
|
MU5 x 1 |
¥21 |
¥10,139 |
||
|
千问3-1.7B |
qwen3-1.7b |
MU1 x 2 |
¥108 |
¥52,236 |
|
MU5 x 1 |
¥21 |
¥10,139 |
||
|
千问3-Embedding-0.6B |
qwen3-embedding-0.6b |
MU5 x 1 |
¥21 |
¥10,139 |
|
MU6 x 1 |
¥25 |
¥12,089 |
||
|
千问3-MoE-Rerank-0.6B |
qwen3-moe-rerank-0.6b |
MU5 x 1 |
¥21 |
¥10,139 |
|
千问3-Rerank-0.6B |
qwen3-rerank-0.6b |
MU5 x 1 |
¥21 |
¥10,139 |
|
MU6 x 1 |
¥25 |
¥12,089 |
||
|
千问3-Max-2025-09-23 |
qwen3-max-2025-09-23 |
MU2 x 8 |
¥504 |
¥240,288 |
|
MU3 x 8 |
¥1,096 |
¥527,752 |
||
|
千问3-Rerank |
qwen3-rerank |
MU5 x 1 |
¥21 |
¥10,139 |
|
千问2.5-开源版-72B |
qwen2.5-72b-instruct |
MU1 x 4 |
¥216 |
¥104,472 |
|
千问2.5-开源版-32B |
qwen2.5-32b-instruct |
MU1 x 4 |
¥216 |
¥104,472 |
|
千问2.5-开源版-14B |
qwen2.5-14b-instruct |
MU1 x 2 |
¥108 |
¥52,236 |
|
千问2.5-开源版-7B |
qwen2.5-7b-instruct |
MU1 x 2 |
¥108 |
¥52,236 |
|
MU5 x 1 |
¥21 |
¥10,139 |
||
|
千问2.5-开源版-3B |
qwen2.5-3b-instruct |
MU5 x 1 |
¥21 |
¥10,139 |
|
千问-Flash-2025-07-28 |
qwen-flash-2025-07-28 |
MU1 x 4 |
¥216 |
¥104,472 |
|
千问-Plus-2025-07-28 |
qwen-plus-2025-07-28 |
MU1 x 4 MU1 x 16(PD分离模式) |
¥216 PD分离模式:¥864 |
¥104,472 PD分离模式:¥417,888 |
|
千问-Plus-2025-12-01 |
qwen-plus-2025-12-01 |
MU1 x 4 |
¥216 |
¥104,472 |
|
Qwen-Plus-Character-2025-11-06 |
qwen-plus-character-2025-11-06 |
MU1 x 4 |
¥216 |
¥104,472 |
GLM
|
模型名称 |
模型代码 |
模型单元规格 |
小时单价(元) 最小计费:分钟 |
包月单价(元) 最小计费:天 |
|
GLM-5.1 |
glm-5.1 |
MU2 x 8 MU2 x 16(PD分离模式) |
¥504 PD分离模式:¥1,008 |
¥240,288 PD分离模式:¥480,576 |
|
MU3 x 8 MU3 x 16(PD分离模式) |
¥1,096 PD分离模式:¥2,192 |
¥527,752 PD分离模式:¥1,055,504 |
||
|
MU6 x 16 |
¥400 |
¥193,424 |
||
|
GLM-5 |
glm-5 |
MU3 x 16(PD分离模式) |
PD分离模式:¥2,192 |
PD分离模式:¥1,055,504 |
|
GLM-4.7 |
glm-4.7 |
MU6 x 32(PD分离模式) |
PD分离模式:¥800 |
PD分离模式:¥386,848 |
DeepSeek
|
模型名称 |
模型代码 |
模型单元规格 |
小时单价(元) 最小计费:分钟 |
包月单价(元) 最小计费:天 |
|
DeepSeek-v4-Flash |
deepseek-v4-flash |
MU1 x 8 |
¥432 |
¥208,944 |
|
DeepSeek-v3.2 |
deepseek-v3.2 |
MU2 x 16(PD分离模式) |
PD分离模式:¥1,008 |
PD分离模式:¥480,576 |
更多模型
|
模型名称 |
模型代码 |
模型单元规格 |
小时单价(元) 最小计费:分钟 |
包月单价(元) 最小计费:天 |
|
MiniMax-M2.5 |
MiniMax-M2.5 |
MU1 x 16(PD分离模式) |
PD分离模式:¥864 |
PD分离模式:¥417,888 |
|
Kimi-K2.5 |
kimi-k2.5 |
MU2 x 8 |
¥504 |
¥240,288 |
模型类型:
-
Instruct - 模型部署后以非思考模式进行推理。
-
Thinking - 模型部署后以思考模式进行推理。
模型部署类型:
-
PD 分离模式 - 降低首 Token 延迟、提高吞吐。
该部署模式部署的模型在进行模型推理时,将首 Token 计算(Prefill)和后续 Token 计算(Decode)两个计算阶段,拆到不同的计算节点执行。
多模态
千问VL
|
模型名称 |
模型代码 |
模型单元规格 |
小时单价(元) 最小计费:分钟 |
包月单价(元) 最小计费:天 |
|
千问3-VL-235B-A22B-Instruct |
qwen3-vl-235b-a22b-instruct |
MU1 x 4 |
¥216 |
¥104,472 |
|
千问3-VL-235B-A22B-Thinking |
qwen3-vl-235b-a22b-thinking |
MU1 x 4 |
¥216 |
¥104,472 |
|
千问3-VL-32B-Instruct |
qwen3-vl-32b-instruct |
MU2 x 8 |
¥504 |
¥240,288 |
|
千问3-VL-8B-Instruct |
qwen3-vl-8b-instruct |
MU1 x 2 |
¥108 |
¥52,236 |
|
千问3-VL-4B-Instruct |
qwen3-vl-4b-instruct |
MU1 x 2 |
¥108 |
¥52,236 |
|
千问3-VL-2B-Instruct |
qwen3-vl-2b-instruct |
MU5 x 1 |
¥21 |
¥10,139 |
|
千问3-VL-Embedding-2B |
qwen3-vl-embedding-2b |
MU5 x 1 |
¥21 |
¥10,139 |
|
千问3-VL-Flash-2025-10-15 |
qwen3-vl-flash-2025-10-15 |
MU1 x 4 |
¥216 |
¥104,472 |
|
千问3-VL-Plus-2025-09-23 |
qwen3-vl-plus-2025-09-23 |
MU1 x 4 |
¥216 |
¥104,472 |
|
千问VL-Max-2025-08-13 |
qwen-vl-max-2025-08-13 |
MU6 x 4 |
¥100 |
¥48,356 |
|
千问VL-OCR-2025-11-20 |
qwen-vl-ocr-2025-11-20 |
MU6 x 4 |
¥100 |
¥48,356 |
千问 Omni
|
模型名称 |
模型代码 |
模型单元规格 |
小时单价(元) 最小计费:分钟 |
包月单价(元) 最小计费:天 |
|
千问3.5-Omni-Flash |
qwen3.5-omni-flash |
MU8 x 1 |
¥47 |
¥22,400 |
|
MU9 x 1 |
¥51 |
¥24,600 |
||
|
千问3.5-Omni-Plus |
qwen3.5-omni-plus |
MU9 x 8 |
¥408 |
¥196,800 |
模型类型:
-
Instruct - 模型部署后以非思考模式进行推理。
-
Thinking - 模型部署后以思考模式进行推理。
-
Instruct/Thinking - 可在模型部署时选择是否开启思考模式。
语音合成
CosyVoice
|
模型名称 |
模型代码 |
模型单元规格 |
小时单价(元) |
包月单价(元) |
|
cosyvoice-v3-flash |
cosyvoice-v3-flash |
MU5 |
¥21 |
¥10,139 |
按模型 Token 使用量
费用 = 模型输入 Token 数 × 模型输入单价 + 模型输出 Token 数 × 模型输出单价(最小计费单位:1 token)
-
仅当对下列基础模型完成 SFT 高效训练并得到自定义模型后,才支持按模型 Token 使用量计费。
千问
|
基础模型 |
模型代码 |
输入 元/千Token |
输出 元/千Token |
|
千问3-32B |
qwen3-32b |
¥0.002 |
非思考模式:¥0.008 思考模式:¥0.02 |
|
千问3-14B |
qwen3-14b |
¥0.001 |
非思考模式:¥0.004 思考模式:¥0.01 |
|
千问3-8B |
qwen3-8b |
¥0.0005 |
非思考模式:¥0.002 思考模式:¥0.005 |
|
千问2.5-开源版-72B |
qwen2.5-72b-instruct |
¥0.004 |
¥0.012 |
|
千问2.5-开源版-32B |
qwen2.5-32b-instruct |
¥0.002 |
¥0.006 |
|
千问2.5-开源版-14B |
qwen2.5-14b-instruct |
¥0.001 |
¥0.003 |
|
千问2.5-开源版-7B |
qwen2.5-7b-instruct |
¥0.0005 |
¥0.001 |
千问VL
|
基础模型 |
模型代码 |
输入 元/千Token |
输出 元/千Token |
|
千问3-VL-8B-Instruct |
qwen3-vl-8b-instruct |
¥0.0005 |
¥0.002 |
|
千问2.5-VL-72B |
qwen2.5-vl-72b-instruct |
¥0.016 |
¥0.048 |
|
千问2.5-VL-32B |
qwen2.5-vl-32b-instruct |
¥0.008 |
¥0.024 |
|
千问2.5-VL-7B |
qwen2.5-vl-7b-instruct |
¥0.002 |
¥0.005 |
如果需要部署更多模型,请参考此解决方案并结合具体业务需求选择最适合的部署方案。
部署方法
您可以在控制台上部署模型,请参考以下操作步骤:
如果提示权限不足,请参考:部署时提示权限不足怎么办?
|
|
|
|
重要
模型部署成功后将产生费用。 |
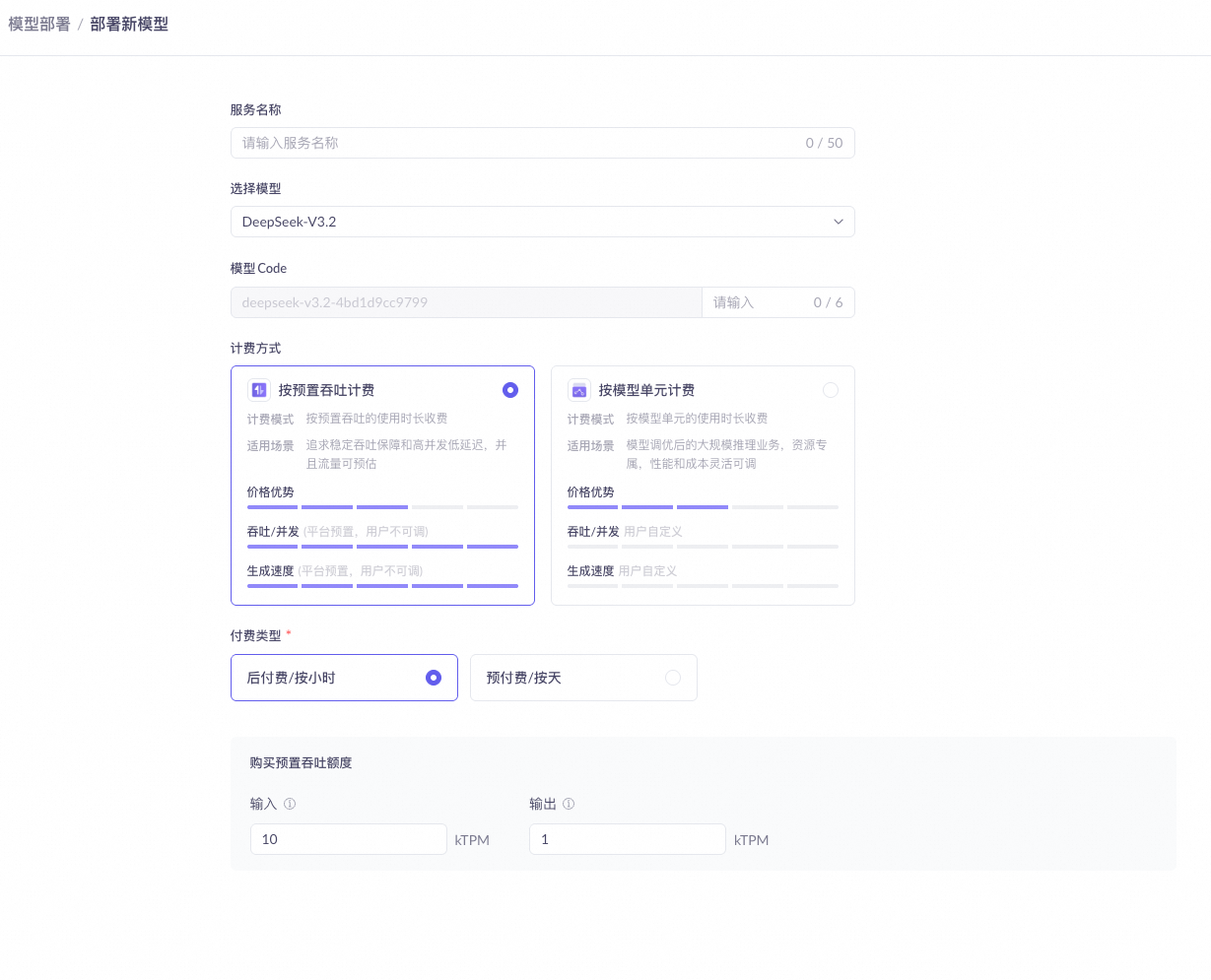
部署配置
模型单元
|
配置内容 |
配置详情 |
|
服务名称 |
自定义部署服务的名称。 |
|
选择模型 |
选择要部署的模型,包括平台预置模型和已调优的模型。 |
|
模型单元类型 |
选择部署规格,不同规格对应不同的算力和性能。 |
|
部署副本数 |
设置初始部署副本数量,影响服务的并发处理能力。 |
|
部署模版 |
选择部署模版(如"单机部署"),不同模版对应不同的资源配置方案。仅在模型单元计费模式下可用。 |
|
配置模型推理模式 |
部分模型在以模型单元方式部署时,可配置推理模式、最长上下文等。
|
|
最长上下文 |
部分模型的模型单元部署模式支持该设置。最长上下文长度基于模型类型。 |
|
服务限流 |
部分模型的模型单元部署模式支持该设置,可限制模型调用的 RPM、TPM。 |
部署列表页
部署成功后,您可以在部署列表页查看和管理所有部署服务。列表页包含以下信息:
-
服务名称:部署服务的名称,单击可查看部署详情。
-
模型名称:部署使用的模型。
-
模型Code:模型部署成功后生成的唯一标识,用于 API 调用时指定模型。
-
部署状态/事件状态:包括待部署、部署中、运行中、部署失败、下线中、服务暂停、已停止、删除中、退订停服/欠费停服、停服恢复中、运行中(变配中)、运行中(变配失败)等状态。
-
计费方式:当前部署服务的计费方式。
-
部署详情:模型单元类型、副本数等配置信息。
-
限流详情:展示当前部署服务的 RPM(每分钟请求数)、TPM(每分钟 Token 数)等限流配置。
-
服务时间:展示部署服务的创建时间与到期时间。
-
操作:根据部署状态和计费方式,可执行更新、监控、扩缩容、续费、下线、删除、体验等操作。
部署后调用
模型部署成功后,支持通过 OpenAI 兼容、Dashscope及Assistant SDK进行调用。
在调用已部署成功的模型时,model的取值应为模型部署成功后的模型code。请前往模型部署控制台(北京)界面获取模型code。

示例代码以调用微调后的 qwen3-8b 模型为例:
模型特性(是否支持非流式输出、结构化输出等)与微调前的模型保持一致。
经过调优的深度思考模型在调用时是否开启深度思考,建议与调优数据格式一致:
-
调优数据含深度思考,调用时建议开启
enable_thinking参数。 -
调优数据不含深度思考,调用时不建议开启
enable_thinking参数。
DashScope
import os
import dashscope
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"},
]
response = dashscope.Generation.call(
# 若没有配置环境变量,请用百炼API Key将下一行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen3-14b-xxx-xxx", # 请替换为模型部署成功后的code
messages=messages,
result_format="message",
enable_thinking=False,
)
print(response)
OpenAI兼容接口
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下一行替换为:api_key="sk-xxx",
api_key=os.getenv('DASHSCOPE_API_KEY'),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-14b-xxx-xxx", # 请替换为模型部署成功后的code
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"},
],
extra_body={"enable_thinking": False},
)
print(completion)
部署服务扩缩容
-
预置吞吐(按时长):点击扩缩容按钮,自助、手动调节实例数量。具体降费退费规则请参考:降配退款规则说明。
-
模型单元(按时长):点击扩缩容按钮,自助、手动调节实例数量。
-
按 Token 调用量:点击扩容按钮,填写并提交扩容申请表单,等待人工审核。
此外,您还可以通过操作列的伸缩配置按钮,配置自动伸缩策略(包括伸缩阈值、最小/最大副本数、定时伸缩等)。
部署服务下线
前往模型部署控制台,找到要停止的部署服务,根据计费类型点击对应操作:
-
模型单元预付费:点击下线并确认。
-
后付费:点击删除并确认。
操作完成后将不再产生计费。

其他操作
除下线外,部署列表页的操作列还支持以下操作:
-
更新:更新已部署服务的模型版本,支持全部更新或分批更新(金丝雀发布)。
-
删除:按量付费服务可直接删除,停止计费。
-
续费:预付费服务可续费延长服务时间,支持自动续费。
-
购买容量包:为预置吞吐部署购买容量包。
常见问题
可以上传和部署自己的模型吗?
支持在我的模型控制台(北京)导入部分开源模型,详细支持列表请参考:模型导入。
此外,阿里云人工智能平台 PAI 提供了部署自有模型的功能,您可以参考PAI-LLM大语言模型部署了解部署方法。
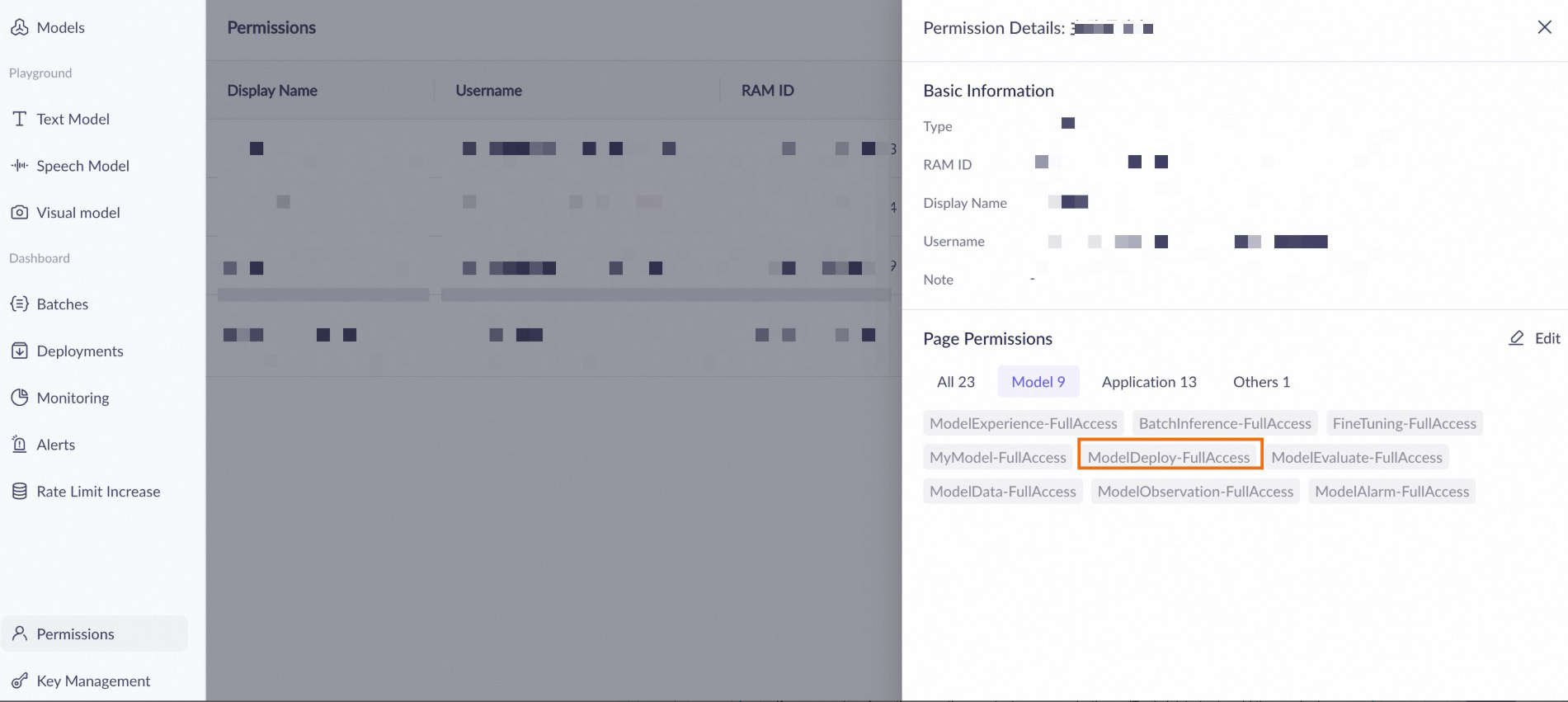
部署时提示权限不足怎么办?
-
如果显示“缺少该模块的权限”,请确保您的账号在该业务空间的权限管理页面中拥有模型部署-操作权限。

如果无法正常操作,请联系您的组织或 IT 管理员添加相关权限或代为检查权限问题。
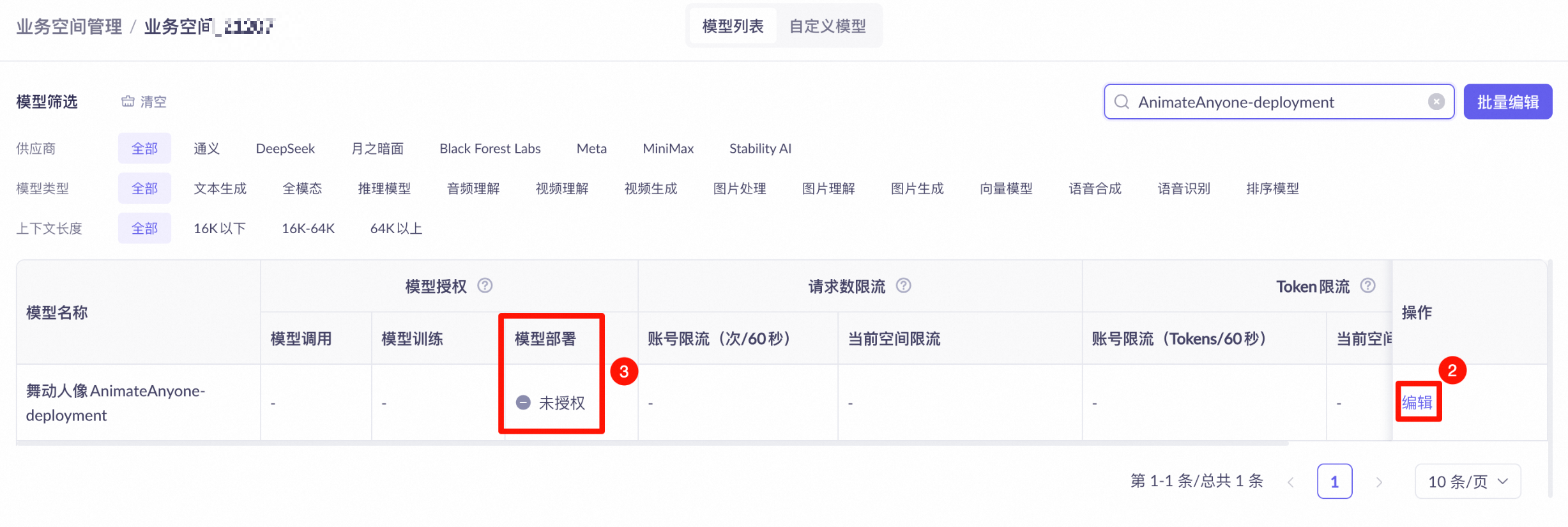
-
如果部署时报错“xx业务空间没有部署xx模型的权限”,请前往百炼的业务空间管理页面,为对应业务空间添加对应模型的部署权限。
API 调用报错:
Workspace xxx does not have deployment privilege for model xxxx。如果提示权限不足,请联系您的组织或 IT 管理员添加相关权限或代为操作。

该如何切换到其他的计费方式?
只能释放原有资源,再通过需要的计费方式创建新资源。
建议按照以下步骤进行切换:
-
使用需要的计费方式部署新的资源。
-
切换 API 并测试服务可用性。
-
下线释放原有资源。