
本文介绍了如何使用阿里云百炼大模型服务提供的实时多模交互服务端 Go SDK,包括SDK下载安装、关键接口及代码示例。
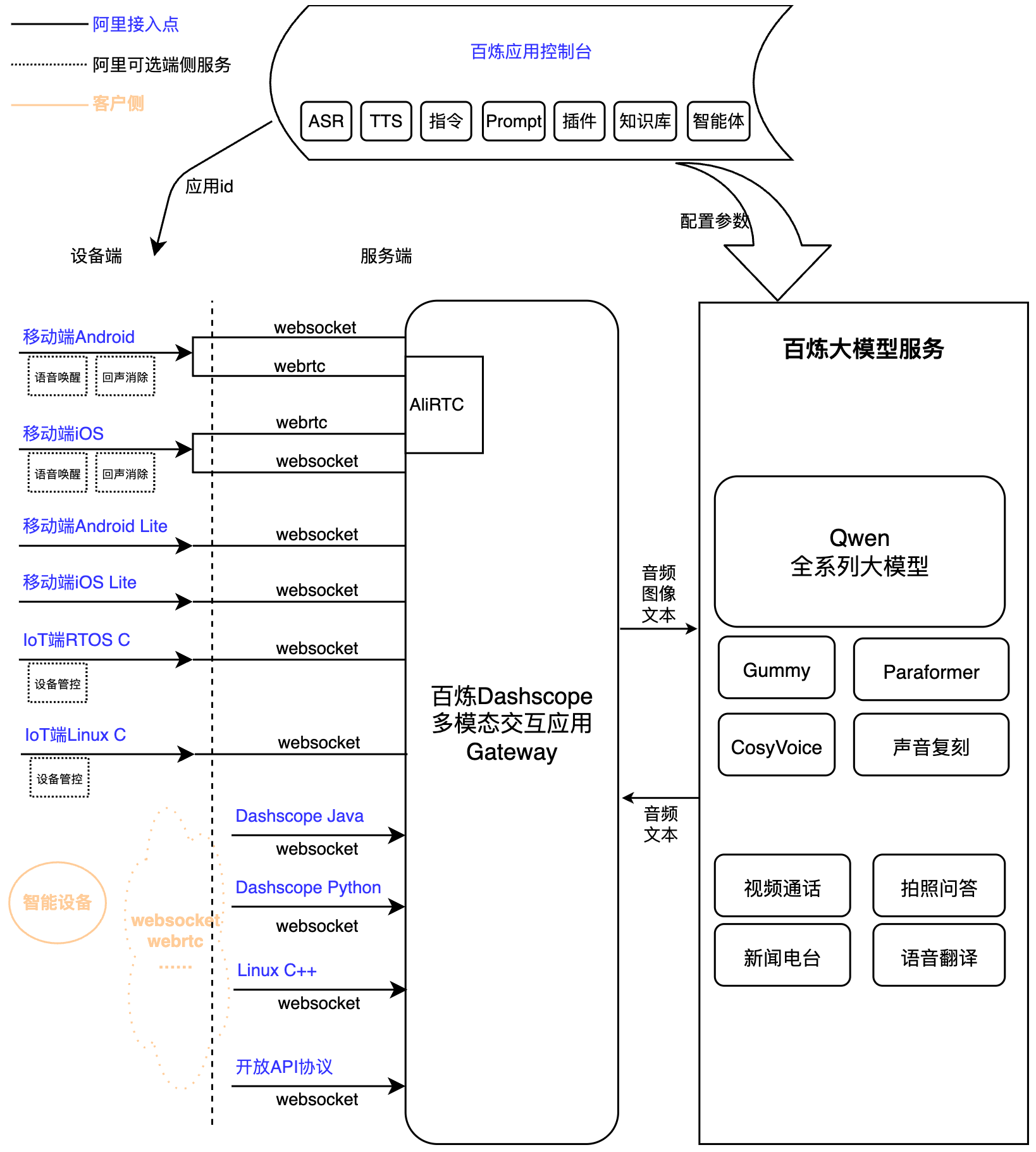
多模态实时交互服务架构
前提条件
开通服务并获取必要参数。
开通阿里云百炼实时多模交互应用,获取Workspace ID、APP ID和API Key。
环境依赖
运行环境要求:Go 1.18 及以上版本。
依赖安装方式:本SDK提供源码集成,请下载multimodal-go-sdk 并按照说明集成。完整示例可参考压缩包中examples。
音频格式说明
使用 Go SDK接入使用 websocket 传输协议。
WS 链路音频格式说明:
上行:支持 pcm (16k 采样率 16bit 单通道)和 opus 音频流。
下行:支持 pcm 和 mp3 音频流。
客户端调用的三种模式
对比项 | push2talk | tap2talk | duplex |
类型 | 客户端控制模式 | 点击模式 | 双工模式 |
音频上传方式 | 按需 | 持续 Listening状态超过20秒不上传音频即报错 | 持续 任何状态超过20秒不上传音频都报错 |
VAD检测方 | 客户端 | 服务端 | 服务端 |
打断方式 | RequestToSpeak消息打断 | RequestToSpeak消息打断 | 语音打断 |
使用场景 | 由用户控制开始/结束客户端语音发送和识别,适用于按键说话,松开停止说话的场景。 | 客户端需持续上传音频,服务端自动检测语音活动的场景。但不支持用户语音打断大模型输出,只能发送RequestToSpeak打断消息。 | 客户端需持续上传音频,服务端自动检测语音活动的场景。用户随时可以说话打断大模型输出。 |
接口说明
dashscope.MultiModalDialog
客户端请求(客户端 → 服务端)
主对话管理类,提供与服务端交互的所有方法。
1. NewMultiModalDialog
创建交互,设置回调。
// 创建一个语音对话会话。
//
// 此方法用于初始化一个新的会话,设置必要的参数以准备开始与模型的交互。
//
// 参数:
// - appId: 客户在管控台创建的应用ID
// - requestParams: 请求参数集合
// - multimodalCallback: 回调对象,用于处理来自服务器的消息
// - workspaceId: 客户的workspace_id(可选)
// - url: API的URL地址(可选,默认 wss://dashscope.aliyuncs.com/api-ws/v1/inference)
// - apiKey: 应用程序接入的唯一key
// - dialogId: 对话id,如果传入表示承接上下文继续聊(可选)
// - model: 模型(可选)
func NewMultiModalDialog(
requestParams *RequestParameters,
multimodalCallback MultiModalCallback,
appID string,
workspaceID string,
url string,
apiKey string,
dialogID string,
model string,
) (*MultiModalDialog, error)2. Start
启动对话服务,返回 OnStarted 回调。注意 OnStarted 会回调 dialogID。
// 初始化WebSocket连接并发送启动请求
//
// 参数:
// - dialogID: 对话ID,用于标识特定的对话会话。新对话传空字符串即可。
func (d *MultiModalDialog) Start(dialogID string) error3. StartSpeech
通知服务端开始上传音频,注意需要在 LISTENING 状态才可以调用。
// 开始上传语音数据
func (d *MultiModalDialog) StartSpeech() error4. SendAudioData
发送语音数据。
// 发送语音数据
//
// 参数:
// - speechData: 语音二进制数据
func (d *MultiModalDialog) SendAudioData(speechData []byte) error5. StopSpeech
通知服务端结束上传音频。
// 停止上传语音数据
func (d *MultiModalDialog) StopSpeech() error6. Interrupt
通知服务端,客户端需要打断当前交互,开始说话。
// 请求服务端开始说话(打断)
func (d *MultiModalDialog) Interrupt() error7. LocalRespondingStarted
通知服务端,客户端开始播放 TTS 音频。
// 本地TTS播放开始
func (d *MultiModalDialog) LocalRespondingStarted() error8. LocalRespondingEnded
通知服务端,客户端结束播放 TTS 音频。
// 本地TTS播放结束
func (d *MultiModalDialog) LocalRespondingEnded() error9. Stop
结束当前轮次对话。
// 停止对话
func (d *MultiModalDialog) Stop() error10. GetDialogState
获得当前对话服务状态,返回 DialogState 枚举。
// 获取对话状态
//
// 返回:
// - DialogState: 当前对话状态(Idle / Listening / Thinking / Responding)
func (d *MultiModalDialog) GetDialogState() DialogState11. RequestToRespond
请求服务端直接文本合成语音,或者发送指令给服务端。
// 请求服务端直接文本合成语音
//
// 参数:
// - requestType: 请求类型("prompt" 或 "transcript")
// - text: 请求文本
// - parameters: 附加参数(可选,如图片等)
// - interruptible: 是否可打断
func (d *MultiModalDialog) RequestToRespond(
requestType string,
text string,
parameters *RequestToRespondParameters,
interruptible bool,
) error请求参数
RequestParameters
字段 | 类型 | 描述 |
| *Upstream | 上行参数 |
| *Downstream | 下行参数 |
| *ClientInfo | 客户端信息 |
| *BizParams | 业务参数(可选) |
Upstream
字段 | 类型 | 必选 | 描述 |
| string | 否 | 音频格式,支持pcm,raw-opus,默认为pcm |
| string | 是 | 上行类型: AudioOnly 仅语音通话 AudioAndVideo 音视频通话 |
| string | 否 | 客户端使用的模式,默认tap2talk。 可选项:
|
| map | 否 | 其他参数通过透传方式传递 |
Downstream
字段 | 类型 | 必选 | 描述 |
| string | 否 | 合成语音的音色,支持范围取决于用户在管控台选择的语音合成模型 |
| int | 否 | 合成语音的采样率,支持范围:
默认为24000。 千问-TTS、千问3-TTS模型仅支持24000。 |
| string | 否 | 控制返回给用户哪些中间文本:
可以设置多种,以逗号分隔,默认为transcript |
| string | 否 | 音频格式,支持pcm,opus,mp3,raw-opus,默认为pcm。 千问-TTS模型仅支持pcm。 注意:opus 和 raw-opus的区别是opus格式的每一包数据都有额外ogg封装(RFC 7845) |
| int | 否 | 合成音频的音量,取值范围0-100,默认50 |
| int | 否 | 合成音频的声调,取值范围50-200,默认100 |
| int | 否 | 合成音频的语速,取值范围50-200,表示默认语速的50%-200%,默认100 |
| map | 否 | 其他参数通过透传方式传递 |
ClientInfo
字段 | 二级参数 | 类型 | 必选 | 描述 |
| string | 是 | 终端用户ID,客户根据自己业务规则生成,用来针对不同终端用户实现定制化功能。最大长度36个字符。 | |
|
| string | 否 | 客户端全局唯一的ID,需要用户自己生成并传入SDK,最大长度40个字符。一个终端用户可以有多个设备,那么每一个设备的uuid都不同,但user_id相同。 |
|
| string | 否 | 调用方公网IP |
|
| string | 否 | 调用方所在城市,指明客户端粗略位置 |
| string | 否 | 调用方纬度信息,在需要客户端精确位置的业务场景提交 | |
| string | 否 | 调用方经度信息,在需要客户端精确位置的业务场景提交 |
BizParams
字段 | 类型 | 必选 | 描述 |
| map | 否 | 设置需要透传给agent的参数,各类agent传递的参数参考调用官方Agent文档说明。可以在extra_config子节点中设置对话扩展参数,目前支持enable_web_search,表示是否开启联网搜索。这里的设置优先级更高,会覆盖管控台配置。 |
| map | 否 | 用于设置用户自定义prompt变量,由用户自定义设置json中的key和value。管控台上配置自定义prompt变量的方法参考应用配置-提示词 |
| map | 否 | 用于设置用户自定义对话变量,由用户自定义设置json中的key和value。管控台上配置自定义对话变量的方法参考应用配置-对话变量 |
| map | 否 | 其他参数通过透传方式传递 |
构建参数示例
// 配置上行参数
upstream := &dashscope.Upstream{
Type: "AudioOnly",
Mode: "push2talk",
AudioFormat: "pcm",
}
// 配置下行参数
downstream := &dashscope.Downstream{
Voice: "longanhuan",
SampleRate: 16000,
IntermediateText: "transcript,dialog",
AudioFormat: "pcm",
}
// 配置客户端信息
clientInfo := &dashscope.ClientInfo{
UserID: "user123",
Device: &dashscope.Device{
UUID: "1234567890",
},
}
requestParams := &dashscope.RequestParameters{
Upstream: upstream,
Downstream: downstream,
ClientInfo: clientInfo,
}MultiModalCallback 回调接口
服务端返回 (服务端 → 客户端)
回调接口,用于处理语音聊天过程中的各种事件。
type MultiModalCallback interface {
// OnStarted 通知对话开始
// - dialogID: 回调对话ID
OnStarted(dialogID string)
// OnStopped 通知对话停止
OnStopped()
// OnStateChanged 对话状态改变
// - state: 新的对话状态
// - inputType: 触发状态变更的输入来源
OnStateChanged(state DialogState, inputType InputType)
// OnSpeechAudioData 合成音频数据回调
// - data: 音频二进制数据
OnSpeechAudioData(data []byte)
// OnError 发生错误时调用此方法
// - err: 错误信息
OnError(err error)
// OnConnected 成功连接到服务器后调用此方法
OnConnected()
// OnRespondingStarted 回复开始回调
OnRespondingStarted()
// OnRespondingEnded 回复结束
// - payload: 回复结束时的附加信息
OnRespondingEnded(payload map[string]interface{})
// OnSpeechStarted 检测到语音输入开始
OnSpeechStarted()
// OnSpeechEnded 检测到语音输入结束
OnSpeechEnded()
// OnSpeechContent 语音识别文本
// - payload: 包含识别文本的数据
OnSpeechContent(payload map[string]interface{})
// OnRespondingContent 大模型回复文本
// - payload: 包含回复文本的数据
OnRespondingContent(payload map[string]interface{})
// OnRequestAccepted 打断请求被接受
OnRequestAccepted()
// OnClose 连接关闭时调用此方法
// - closeStatusCode: 关闭状态码
// - closeMsg: 关闭消息
OnClose(closeStatusCode int, closeMsg string)
}对话状态说明(DialogState)
OnStateChanged接口回调的状态包括 LISTENING、THINKING、RESPONDING 三个状态:
Listening:表示机器人正在监听用户输入,用户可以发送音频。
Thinking:表示机器人正在思考。
Responding:表示机器人正在生成语音或语音回复中。
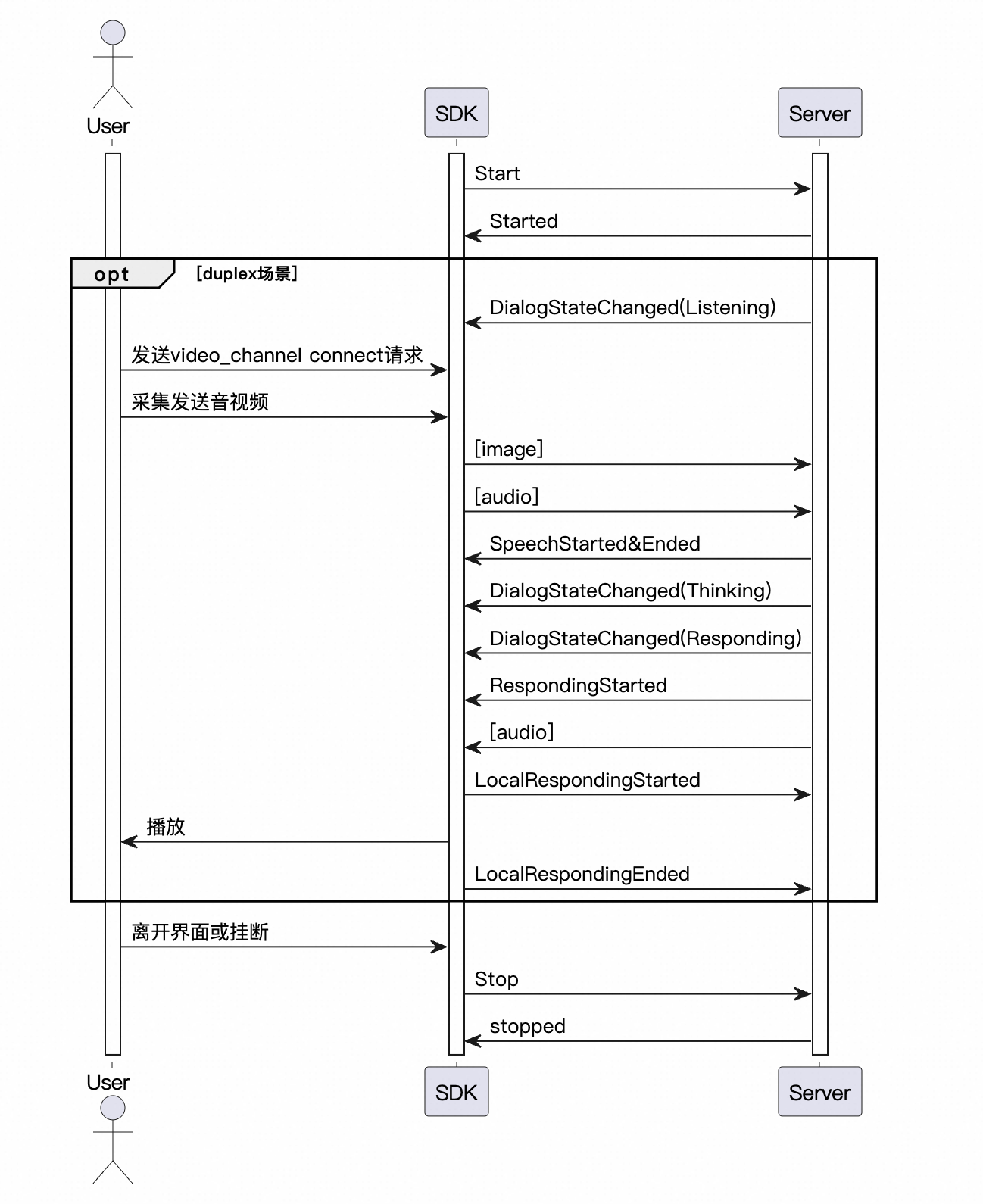
调用交互时序图

更多SDK接口使用说明
VQA(图片问答)交互
VQA 是在对话过程中通过发送图片实现图片+语音的多模交互的功能。
核心过程是通过输入类似"看一下xxx"意图的语音,或者直接输入请求文本的方式触发 VQA,返回基于图片内容的问答结果。
通过语音请求的流程为:
语音说:"看一下前面有什么"。
通过回调函数
OnRespondingContent返回拍照意图 "visual_qa"。客户端收到上述意图后,调用
RequestToRespond接口提交图片内容触发问答回复。
// callback 中处理 visual_qa 意图 func (c *MyCallback) OnRespondingContent(payload map[string]interface{}) { if output, ok := payload["output"].(map[string]interface{}); ok { if extraInfo, ok := output["extra_info"].(map[string]interface{}); ok { if commands, ok := extraInfo["commands"].(string); ok { if strings.Contains(commands, "visual_qa") { // 触发 VQA sendImageVQA(dialog) } } } } } // 发送 VQA 请求 func sendImageVQA(dialog *dashscope.MultiModalDialog) { image := map[string]interface{}{ "type": "base64", "value": imageBase64Data, } // 或者使用 URL 方式 // image := map[string]interface{}{ // "type": "url", // "value": imageURL, // } imagesParams := &dashscope.RequestToRespondParameters{ Images: []interface{}{image}, } // 使用语音调用 VQA,text 传空字符串即可 dialog.RequestToRespond("prompt", "", imagesParams, false) }直接通过文本请求流程为:
客户端直接调用request_to_respond接口提交图片内容和请求文本,触发问答回复。
image := map[string]interface{}{ "type": "base64", "value": imageBase64Data, } // 或者使用 URL 方式 // image := map[string]interface{}{ // "type": "url", // "value": imageURL, // } imagesParams := &dashscope.RequestToRespondParameters{ Images: []interface{}{image}, } // 使用文本直接请求图片回复,text 填入文本请求 dialog.RequestToRespond("prompt", "这张图片里面有什么", imagesParams, false)
注意:VQA 支持发送图片链接或者base64数据(支持小于180KB的图片)。
通过Websocket请求LiveAI(视频通话)
LiveAI(视频通话)是百炼多模交互提供的官方 Agent。通过 Go SDK 发送图片序列的方式,可以实现视频通话的功能。我们推荐您的服务端和客户端(网页或者 APP)通过 RTC 传输视频和音频,然后将服务端采集到的视频帧以 500ms/张 的速度发送给 SDK,同时保持实时的音频输入。
注意:LiveAI 发送图片只支持 base64 编码,每张图片的大小在 180K 以下。
LiveAI调用时序
关键代码示例
// 1. 设置请求模式为 AudioAndVideo
upstream := &dashscope.Upstream{
Type: "AudioAndVideo",
Mode: "duplex",
AudioFormat: "pcm",
}
// 2. 发送连接到视频对话 Agent 请求
func sendConnectVideoCommand(dialog *dashscope.MultiModalDialog) {
videoConnectCommand := []interface{}{
map[string]interface{}{
"action": "connect",
"type": "voicechat_video_channel",
},
}
params := &dashscope.RequestToRespondParameters{
BizParams: &dashscope.BizParams{
Videos: videoConnectCommand,
},
}
dialog.RequestToRespond("prompt", "", params, false)
}
// 3. 间隔 500ms 发送一张 180KB 以下的视频帧图片
func sendVideoFrameLoop(dialog *dashscope.MultiModalDialog, stopChan chan bool) {
ticker := time.NewTicker(500 * time.Millisecond)
defer ticker.Stop()
for {
select {
case <-stopChan:
return
case <-ticker.C:
image := map[string]interface{}{
"type": "base64",
"value": getVideoFrameBase64(),
}
params := &dashscope.RequestToRespondParameters{
Images: []interface{}{image},
}
dialog.RequestToRespond("prompt", "", params, false)
}
}
}文本合成TTS
SDK支持通过文本直接请求服务端合成音频。
您需要在客户端处于Listening状态下发送RequestToRespond请求。
若当前状态非Listening,需要先调用Interrupt 接口打断当前播报。
dialog.RequestToRespond("transcript", "今天天气不错", nil, false)自定义提示词变量和传值
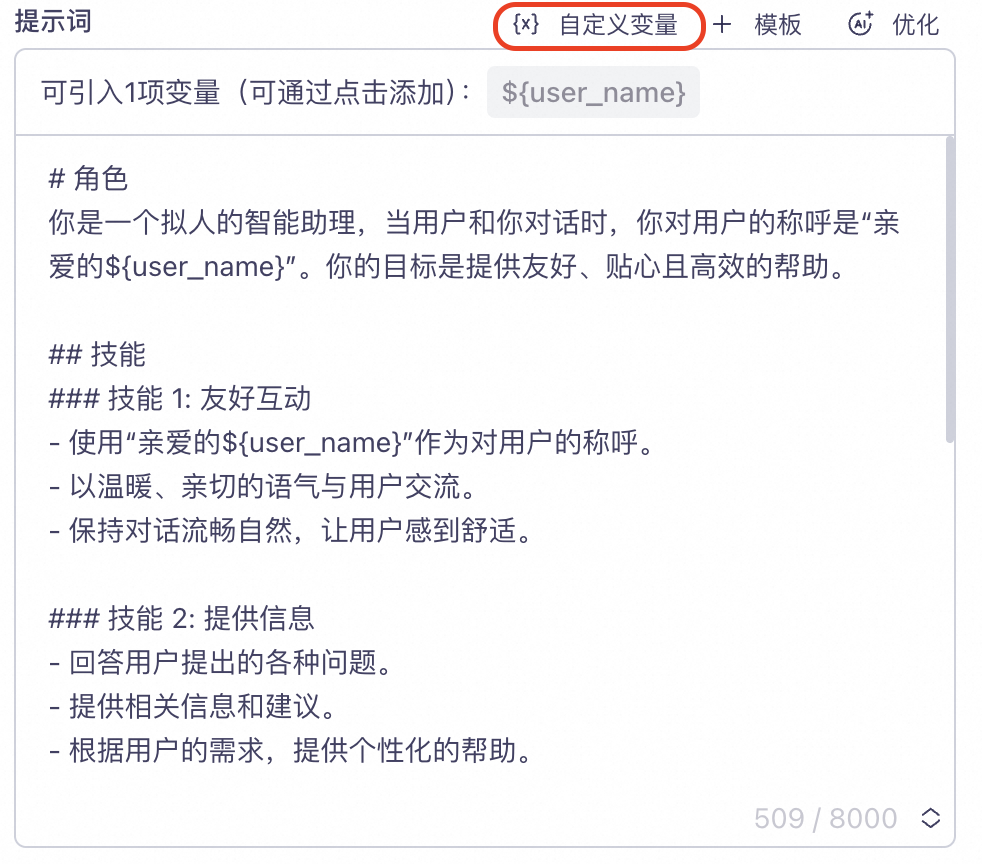
在管控台项目【提示词】配置自定义变量。
如下图示例,定义了一个user_name字段代表用户昵称。并将变量user_name以占位符形式${user_name} 插入到Prompt 中。
在代码中设置变量。
如下示例,设置"user_name" = "大米"。
// 在请求参数中传入 BizParams.UserPromptParams
bizParams := &dashscope.BizParams{
UserPromptParams: map[string]interface{}{
"user_name": "大米",
},
}
requestParams := &dashscope.RequestParameters{
Upstream: upstream,
Downstream: downstream,
ClientInfo: clientInfo,
BizParams: bizParams,
}请求回复

使用文本请求对话结果
SDK支持通过文本直接请求返回 LLM 结果和语音合成数据。
您需要在客户端处于Listening状态下发送RequestToRespond请求。
dialog.RequestToRespond("prompt", "今天天气不错", nil, false)SDK连接和状态管理
1. 资源管理
使用完毕后请调用 Cleanup() 方法释放所有资源:
defer dialog.Cleanup()2. 心跳保活
建议定期发送心跳以保持链接:
ticker := time.NewTicker(45 * time.Second)
go func() {
for range ticker.C {
dialog.SendHeartBeat()
}
}()3. 状态监控
通过实现 MultiModalCallback 接口监控对话状态变化:
func (c *MyCallback) OnStateChanged(state dashscope.DialogState, inputType dashscope.InputType) {
switch state {
case dashscope.DialogStateListening:
// 系统进入监听状态,可以开始发送音频
case dashscope.DialogStateThinking:
// AI 正在思考
case dashscope.DialogStateResponding:
// AI 正在回复,准备接收音频数据
}
}