
本文介绍通义听悟 Python SDK的实时接口,帮助开发者快速调用通义听悟的实时服务。
前提条件
已开通服务并获取API Key,请配置API Key到环境变量,而非硬编码在代码中,防范因代码泄露导致的安全风险。
说明当您需要为第三方应用或用户提供临时访问权限,或者希望严格控制敏感数据访问、删除等高风险操作时,建议使用临时鉴权Token。
与长期有效的 API Key 相比,临时鉴权 Token 具备时效性短(60秒)、安全性高的特点,适用于临时调用场景,能有效降低API Key泄露的风险。
使用方式:在代码中,将原本用于鉴权的 API Key 替换为获取到的临时鉴权 Token 即可。
安装最新版DashScope SDK(版本号>=1.24.4)
接口说明
TingWuRealtime
初始化参数
听悟实时服务的入口类。通过该接口请求千问实时服务。
以工业生产指令转写交互协议(WebSocket)为例,创建任务支持传入的主要参数如下:
名称 | 类型 | 必填 | 描述 |
appId | string | 是 | 应用id |
sampleRate | int | 否 | 音频采样率,只支持16000Hz。 |
format | string | 是 | 设置待识别音频格式。支持的音频格式:pcm、wav、mp3、opus、speex、aac、amr。对于opus和speex格式的音频,需要ogg封装;对于wav格式的音频,需要pcm编码。 |
maxEndSilence | int | 否 | 非必传,最大静音时长,单位ms,检测到超过此时长则会认为一句话结束,转写完成 |
terminology | string | 否 | 纠正指令集id |
data_id | stting | 否 | 数据集 id |
callback | TingWuRealtimeCallback | 是 | 回调听悟实时转写事件和结果 |
示例代码
tingwu_realtime = TingWuRealtime(
model=self.model,
audio_format=self.format,
sample_rate=self.sample_rate,
app_id=self.appId,
base_address=self.base_address,
api_key=self.api_key,
terminology=self.terminology,
callback=callback,
max_end_silence=3000
)start(self, **kwargs)
发起请求。
send_audio_data(self, speech_data: bytes)
发送转写音频数据。
stop(self)
结束请求
TingWuRealtimeCallback
回调听悟实时转写事件和结果。
class TingWuRealtimeCallback:
"""An interface that defines callback methods for getting TingWu results.
Derive from this class and implement its function to provide your own data.
"""
def on_open(self) -> None:
pass # connected callback
def on_started(self, task_id: str) -> None:
pass # protocal handshake over
def on_speech_listen(self, result: dict):
pass # callback speech listen event
def on_recognize_result(self, result: dict):
pass # callback recognize result
def on_ai_result(self, result: dict):
pass # callback ai result
def on_stopped(self) -> None:
pass # recognize over
def on_error(self, error_code: str, error_msg: str) -> None:
pass
def on_close(self, close_status_code, close_msg):
pass
调用时序
通过听悟实时接口调用的时序如下,在建立连接之后,收到 SpeechListen 事件即可发送流式语音数据,服务端返回流式识别和纠错结果。
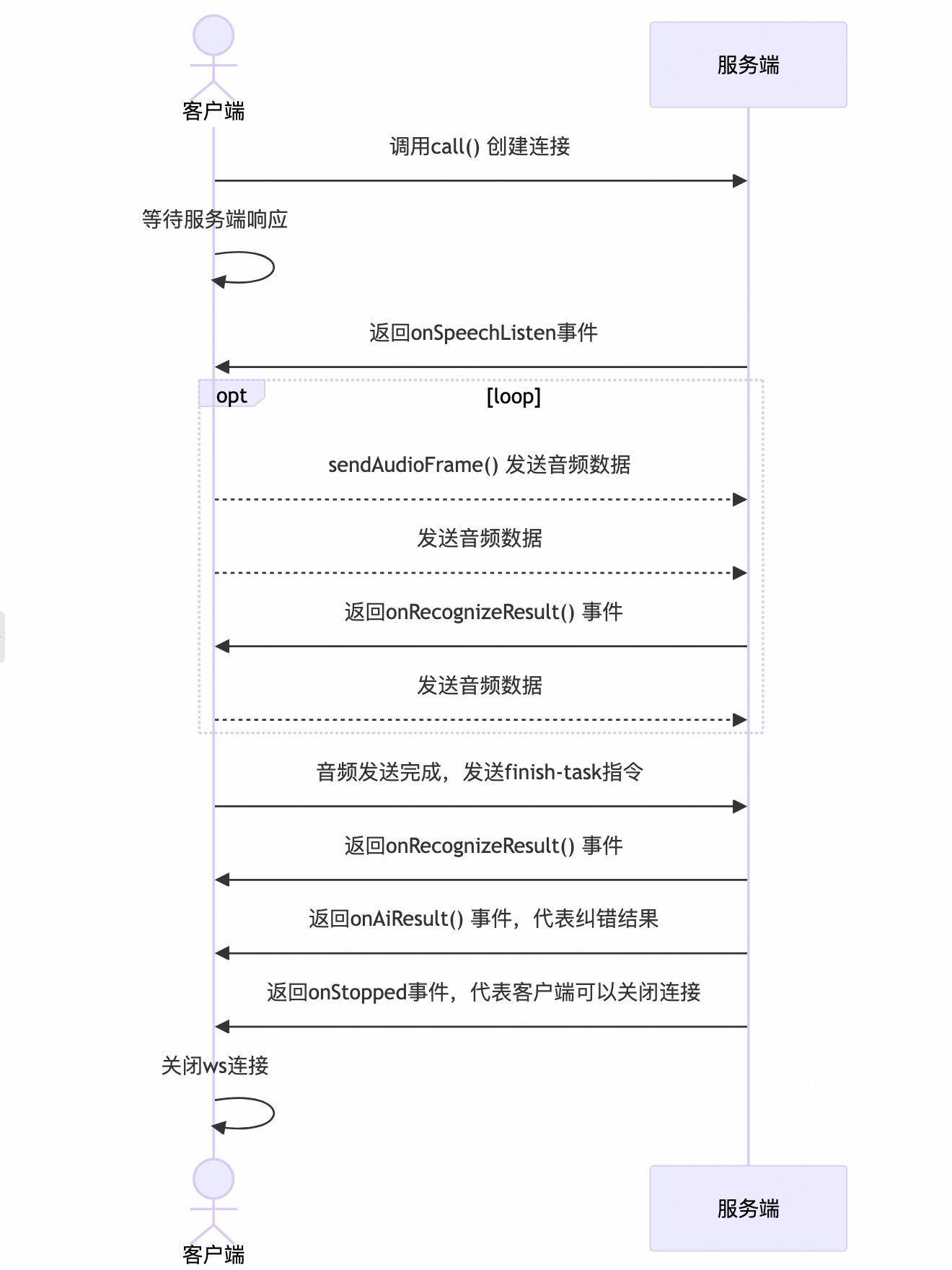
响应结果说明
以工业生产指令转写交互协议(WebSocket)为例,在指令或音频发送后,服务端会向您发送不同种类的事件,每个事件代表不同的处理阶段,请严格遵循时序图对不同事件做相应处理。
事件总共分为四种,分别是speech-listen事件、recognize-result事件、ai-result事件及speech-end事件。
speech-listen事件
对应时序图中的过程3,speech-listen事件会在run-task指令后返回,代表服务端收到了您的转写指令,并完成相关初始化工作,您可以开始发送音频了。
协议字段如下:
字段 | 类型 | 说明 |
header | Object | |
header.event | String | 固定为result-generated。 |
header.task_id | String | 您在run-task指令中填写的task_id。 |
payload | Object | |
payload.output | Object | |
payload.output.action | String | 固定为speech-listen。 |
payload.output.dataId | String | 您本次转写的任务id,您可以通过该id向我们反馈问题,同时在账单中也可以通过该id查看对应任务的计费项。 |
speech-listen事件的示例如下:
{
"header": {
"event": "result-generated",
"task_id": "f2E3zvK*******wp"
},
"payload": {
"output": {
"action": "speech-listen",
"dataId": "Adb*******uY"
}
}
}recognize-result事件
对应时序图中的过程4,recognize-result事件会在您发送一段时间的音频后返回,也可能会在您发送finish-task指令后返回,代表当前服务端识别到的原文和译文结果。
协议字段如下:
字段 | 类型 | 说明 |
header | Object | |
header.event | String | 固定为result-generated。 |
header.task_id | String | 您在run-task指令中填写的task_id。 |
payload | Object | |
payload.output | Object | |
payload.output.action | String | 固定为recognize-result。 |
payload.output.transcription | Object | 转写的原始结果。 |
payload.output.transcription.sentenceId | Integer | 句子序号。 |
payload.output.transcription.beginTime | Integer | 当前句子已识别部分的第一个字在音频中的开始时间,单位ms。 |
payload.output.transcription.endTime | Integer | 当前句子已识别部分的最后一个字在音频中的结束时间,单位ms。 |
payload.output.transcription.sentenceEnd | Boolean | 当前句子是否已结束。 |
payload.output.transcription.text | String | 当前句子已识别部分的内容。 |
payload.output.transcription.words | List[Word] | 句子分词信息。 |
payload.output.translations | Object | 转写的翻译结果。 |
payload.output.translations.sentenceEnd | Boolean | 当前句子是否结束。 |
payload.output.translations.translations | Object | 转写的翻译目标语种结果集合。 |
payload.output.translations.translations.zh | Object | 目前只支持翻译成中文,所以只会有zh一个对象。 |
payload.output.translations.translations.zh.lang | String | 固定为zh。 |
payload.output.translations.translations.zh.sentenceId | Integer | 句子序号。 |
payload.output.translations.translations.zh.beginTime | Integer | 当前句子已翻译部分的第一个字在音频中的开始时间,单位ms。 |
payload.output.translations.translations.zh.endTime | Integer | 当前句子已翻译部分的最后一个字在音频中的结束时间,单位ms。 |
payload.output.translations.translations.zh.sentenceEnd | Boolean | 当前句子是否已结束。 |
payload.output.translations.translations.zh.text | String | 当前句子已翻译部分的内容。 |
payload.output.translations.translations.zh.words | List[Word] | 已翻译句子分词信息。 |
Word类型协议如下:
字段 | 类型 | 说明 |
beginTime | Integer | 当前词在音频中的开始时间。 |
endTime | Integer | 当前词在音频中的结束时间。 |
text | String | 当前词的内容。 |
recognize-result事件的示例如下:
{
"header": {
"event":"result-generated",
"task_id": "f2E3zvK*******wp"
},
"payload": {
"output": {
"action": "recognize-result",
"transcription": {
"sentenceId": 0,
"beginTime": 100,
"endTime": 2720,
"sentenceEnd": true,
"text": "这是一句用来测试的文本。",
"words": [
{
"beginTime": 100,
"endTime": 427,
"text": "这"
},
{
"beginTime": 427,
"endTime": 755,
"text": "是一"
},
{
"beginTime": 755,
"endTime": 1082,
"text": "句"
},
{
"beginTime": 1082,
"endTime": 1410,
"text": "用来"
},
{
"beginTime": 1410,
"endTime": 1737,
"text": "测试"
},
{
"beginTime": 1737,
"endTime": 2065,
"text": "的"
},
{
"beginTime": 2065,
"endTime": 2392,
"text": "文本"
},
{
"beginTime": 2392,
"endTime": 2720,
"text": "。"
}
]
},
"translations": {
"sentenceEnd": true,
"translations": {
"zh": {
"sentenceId": 0,
"beginTime": 100,
"endTime": 2720,
"text": "这是一句用来测试的文本。",
"lang": "zh",
"words": [
{
"beginTime": 100,
"endTime": 427,
"text": "这"
},
{
"beginTime": 427,
"endTime": 755,
"text": "是一"
},
{
"beginTime": 755,
"endTime": 1082,
"text": "句"
},
{
"beginTime": 1082,
"endTime": 1410,
"text": "用来"
},
{
"beginTime": 1410,
"endTime": 1737,
"text": "测试"
},
{
"beginTime": 1737,
"endTime": 2065,
"text": "的"
},
{
"beginTime": 2065,
"endTime": 2392,
"text": "文本"
},
{
"beginTime": 2392,
"endTime": 2720,
"text": "。"
}
],
"sentenceEnd": true
}
}
}
}
}
}ai-result事件
对应时序图中的过程6。ai-result事件会在最后一条recognize-result事件后返回给您,代表工业指令转写结合指令集纠正后的最终结果。
协议字段如下:
字段 | 类型 | 说明 |
header | Object | |
header.event | String | 固定为result-generated。 |
header.task_id | String | 您在run-task指令中填写的task_id。 |
payload | Object | |
payload.output | Object | |
payload.output.action | String | 固定为ai-result。 |
payload.output.aiResult | Object | |
payload.output.aiResult.correction | String | 工业指令转写最终结果 |
ai-result事件的示例如下:
{
"header": {
"event": "result-generated",
"task_id": "f2E3zvK*******wp"
},
"payload": {
"output": {
"action": "ai-result",
"aiResult": {
"correction": "右翼子板漆渣SQE。"
}
}
}
}speech-end事件
对应时序图中的过程7。speech-end事件会在ai-result事件后发送给您,代表工业指令转写完全结束,之后您可以关闭WebSocket连接。
协议字段如下:
字段 | 类型 | 说明 |
header | Object | |
header.event | String | 固定为result-generated。 |
header.task_id | String | 您在run-task指令中填写的task_id。 |
payload | Object | |
payload.output | Object | |
payload.output.action | String | 固定为speech-end。 |
speech-end事件的示例如下:
{
"header": {
"event": "result-generated",
"task_id": "f2E3zvK*******wp"
},
"payload": {
"output": {
"action": "speech-end"
}
}
}task-failed事件
若在任务过程中,由于客户端传参错误或服务端内部错误导致任务失败,服务端会返回给您task-failed事件,随即会中断WebSocket连接。
协议字段如下:
字段 | 类型 | 说明 |
header | Object | |
header.event | String | 固定为result-generated。 |
header.task_id | String | 您在run-task指令中填写的task_id。 |
payload | Object | |
payload.output | Object | |
payload.output.action | String | 固定为task-failed。 |
payload.output.errorCode | String | 错误码 |
payload.output.errorMessage | String | 错误信息 |
task-failed事件的示例如下:
{
"header": {
"event": "result-generated",
"task_id": "f2E3zvK*******wp"
},
"payload": {
"output": {
"action": "task-failed",
"errorCode": "错误码",
"errorMessage": "错误信息"
}
}
}具体错误码及其含义,可以参考错误码。
错误码说明
错误码 | 错误信息 | 说明 |
InvalidParameter | Invalid parameter. Please refer to the official documents. | 参数错误,请检查您传入的参数。 |
InvalidParameter | MaxEndSilence invalid, must between [0. 6000]. | 传入的maxEndSilence参数不合法。 |
InvalidParameter | Terminology not exist. | 传入的指令集不存在。 |
InvalidParameter | SampleRate invalid. | 传入的采样率参数不合法。 |
InvalidParameter | Audio format invalid. | 传入的音频编码格式参数不合法。 |
InvalidParameter | Terminology invalid. | 传入的指令集Id不合法。 |
Agent.FrameSequenceIllegal | Agent Websocket Frame Sequence Illegal. | 调用指令时序不合法。 |
Agent.InputActionIllegal | Agent Input Action Illegal. | 传入的指令action字段不合法。 |
Agent.InputAppIdIllegal | Agent Input appId illegal. | 传入的应用Id字段不合法。 |
Agent.AppNotPublished | Agent App not published. | 传入的应用Id尚未发布。 |
Agent.CustomTaskIdInvalid | The length of custom task id must be 16. | 传入的taskId字段长度不合法。 |
BIL.ServiceNotActivate | User hasn't activate service. | 您尚未开通听悟Agent服务。 |
BIL.UserArrears | User is in arrears. | 您目前处在欠费状态。 |
Agent.AppInfoNotExist | Agent App Info not exist. | 传入的应用Id信息不存在,请先在控制台保存并发布应用配置信息。 |
ServerError | Server error. | 服务端内部错误。 |
代码示例
以工业生产指令转写为例,调用 Python SDK 实现的示例如下:
import logging
import time
import sys
from dashscope.multimodal.tingwu.tingwu_realtime import TingWuRealtime, TingWuRealtimeCallback
# 配置日志 - 关键改进
logger = logging.getLogger('dashscope')
logger.setLevel(logging.DEBUG)
# 创建控制台处理器并设置级别为debug
console_handler = logging.StreamHandler(sys.stdout) # 明确指定输出到stdout
console_handler.setLevel(logging.DEBUG)
# 创建格式化器
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 添加格式化器到处理器
console_handler.setFormatter(formatter)
# 添加处理器到logger
logger.addHandler(console_handler)
# 强制刷新日志输出
logger.propagate = False
class TestCallback(TingWuRealtimeCallback):
def __init__(self): # 修复:__init__ 方法名
super().__init__()
self.can_send_audio = False
print("TestCallback initialized") # 添加调试输出
sys.stdout.flush() # 强制刷新
def on_open(self) -> None:
print('TingWuClient:: on websocket open.') # 同时使用print确保输出
logger.info('TingWuClient:: on websocket open.')
sys.stdout.flush()
def on_started(self, task_id: str) -> None:
print(f'TingWuClient:: on task started. task_id: {task_id}')
logger.info('TingWuClient:: on task started. task_id: %s', task_id)
sys.stdout.flush()
def on_speech_listen(self, result: dict):
print(f'TingWuClient:: on speech listen. result: {result}')
logger.info('TingWuClient:: on speech listen. result: %s', result)
self.can_send_audio = True # 标记可以发送语音数据
sys.stdout.flush()
def on_recognize_result(self, result: dict):
print(f'TingWuClient:: on recognize result. result: {result}')
logger.info('TingWuClient:: on recognize result. result: %s', result)
sys.stdout.flush()
def on_ai_result(self, result: dict):
print(f'TingWuClient:: on ai result. result: {result}')
logger.info('TingWuClient:: on ai result. result: %s', result)
sys.stdout.flush()
def on_stopped(self) -> None:
print('TingWuClient:: on task stopped.')
logger.info('TingWuClient:: on task stopped.')
self.can_send_audio = False # 标记不能发送语音数据
sys.stdout.flush()
def on_error(self, error_code: str, error_msg: str) -> None:
print(f'TingWuClient:: on error. error_code: {error_code}, error_msg: {error_msg}')
logger.info('TingWuClient:: on error. error_code: %s, error_msg: %s',
error_code, error_msg)
sys.stdout.flush()
def on_close(self, close_status_code, close_msg):
print(f'TingWuClient:: on websocket close. close_status_code: {close_status_code}, close_msg: {close_msg}')
logger.info('TingWuClient:: on websocket close. close_status_code: %s, close_msg: %s',
close_status_code, close_msg)
sys.stdout.flush()
class RunTingWuRealtime:
@classmethod
def setup_class(cls):
cls.model = 'tingwu-industrial-instruction'
cls.format = 'pcm'
cls.sample_rate = 16000
cls.file = './data/会议音频.pcm'
cls.appId = 'your-app-id'
cls.base_address = 'wss://dashscope.aliyuncs.com/api-ws/v1/inference'
cls.api_key = 'Your-dashscope-api-key'
cls.terminology = 'your-terminology-id'
def start_with_stream(self):
print("开始测试...")
sys.stdout.flush()
callback = TestCallback()
print("创建 TingWuRealtime 实例...")
sys.stdout.flush()
tingwu_realtime = TingWuRealtime(
model=self.model,
audio_format=self.format,
sample_rate=self.sample_rate,
app_id=self.appId,
base_address=self.base_address,
api_key=self.api_key,
terminology=self.terminology,
callback=callback,
max_end_silence=3000
)
print("启动 TingWu 连接...")
sys.stdout.flush()
tingwu_realtime.start()
# 等待连接建立
time.sleep(2)
# 等待系统状态流转到speech_listen
try:
print(f"打开文件: {self.file}")
sys.stdout.flush()
with open(self.file, 'rb') as f:
chunk_count = 0
while True:
chunk = f.read(3200)
if not chunk:
print("文件读取完毕")
sys.stdout.flush()
break
# 修复逻辑错误:应该在can_send_audio为True时发送
if callback.can_send_audio:
tingwu_realtime.send_audio_frame(chunk)
time.sleep(0.1)
chunk_count += 1
if chunk_count % 10 == 0: # 每10个chunk打印一次
print(f"已发送 {chunk_count} 个音频块")
sys.stdout.flush()
else:
print("等待可以发送音频...")
sys.stdout.flush()
time.sleep(0.1) # 短暂等待
logger.info('============= 文件读取完毕')
time.sleep(100) # 等待一段时间
except FileNotFoundError:
print(f"文件未找到: {self.file}")
sys.stdout.flush()
except Exception as e:
print(f"发生错误: {e}")
sys.stdout.flush()
finally:
print("发送 stop 指令...")
sys.stdout.flush()
tingwu_realtime.stop()
time.sleep(10) # 等待一段时间
tingwu_realtime.close()
print("TingWu 连接已关闭")
if __name__ == '__main__':
print('开始 test_tingwu_realtime 测试')
sys.stdout.flush()
logger.debug('Start test_tingwu_realtime.')
test_env = RunTingWuRealtime()
test_env.setup_class() # 设置测试环境
test_env.start_with_stream() # 调用测试方法
print('测试完成')
sys.stdout.flush()