模型调优简介
当您在尝试如 Prompt 工程、插件调用等优化方法后,模型表现仍然不及预期时,请使用百炼的模型调优。模型调优作为改进模型表现的核心策略,可以很好地提升模型在特定行业/业务的表现,对齐人类偏好,降低输出延迟。
模型调优介绍
模型调优作为重要的模型效果优化方式,可以:
提升模型在特定行业/业务表现
降低模型输出延迟
抑制模型幻觉
对齐人类的价值观或偏好
使用调优后的轻量级模型替代规模更大的模型
模型在调优过程中,会学习训练数据中的知识、语气、表达习惯、自我认知等业务/场景特征。也由于已经在训练过程中学习到了大量特定行业/场景的样例,训练后模型 One-Shot 或者 Zero-Shot 的 Prompt 效果会比训练前 Few-Shot 效果更好,这样可以节省大量输入 token,从而降低模型输出延迟。
模型调优流程

百炼模型调优功能还支持:Paraformer语音识别热词定制与管理
详情参见:
支持的模型
文本生成
模型名称 | 模型代码 | CPT全参训练 (cpt) | SFT全参训练 (sft) | SFT高效训练 (efficient_sft) | DPO全参训练 (dpo_full) | DPO高效训练 (dpo_lora) |
通义千问2.5-开源版-72B | qwen2.5-72b-instruct |
|
|
| ||
通义千问2.5-开源版-32B | qwen2.5-32b-instruct |
|
| |||
通义千问2.5-开源版-14B | qwen2.5-14b-instruct |
|
|
| ||
通义千问2.5-开源版-7B | qwen2.5-7b-instruct |
|
|
| ||
通义千问2-开源版-72B | qwen2-72b-instruct |
|
| |||
通义千问2-开源版-7B | qwen2-7b-instruct |
|
|
|
| |
通义千问1.5-开源版-72B | qwen1.5-72b-chat |
| ||||
通义千问1.5-开源版-14B | qwen1.5-14b-chat |
|
| |||
通义千问1.5-开源版-7B | qwen1.5-7b-chat |
|
| |||
通义千问-开源版-72B | qwen-72b-chat |
| ||||
通义千问-开源版-14B | qwen-14b-chat |
|
| |||
通义千问-开源版-7B | qwen-7b-chat |
|
| |||
通义千问-Turbo(通义商业版) | qwen-turbo |
|
| |||
通义千问-Turbo-0624(通义商业版) | qwen-turbo-0624 |
|
|
|
| |
通义千问-Plus-0723(通义商业版) | qwen-plus-0723 |
|
| |||
通义千问VL-Max-0201 | qwen-vl-max-0201 |
| ||||
通义千问VL-Plus | qwen-vl-plus |
| ||||
百川2-7B(开源) | baichuan2-7b-chat-v1 |
| ||||
Llama2-13B | llama2-13b-chat-v2 |
| ||||
Llama2-7B | llama2-7b-chat-v2 |
| ||||
ChatGLM2-6B | chatglm-6b-v2 |
|
CPT-无监督-继续预训练(Continual Pre-Training)提升模型在特定行业的表现。
SFT-有监督-模型微调(Supervised Fine-Tuning)提升模型在特定业务/场景的表现。
DPO-有监督-直接偏好优化(Direct Preference Optimization)对bad case进行针对性优化。
全参训练-训练时间较长,收敛速度较慢,可实现模型新能力的学习和全局效果的优化提升。
高效训练-训练时间较短,收敛速度较快,适用于模型局部效果优化。
语音识别-热词定制与管理
模型代码 | SFT 全参训练 | SFT 高效训练 | DPO 全参训练 | DPO 高效训练 | 热词定制与管理 |
paraformer-realtime-v1(仅API) |
| ||||
paraformer-realtime-8k-v1(仅API) |
| ||||
paraformer-8k-v1(仅API) |
| ||||
paraformer-v1(仅API) |
| ||||
paraformer-mtl-v1(仅API) |
| ||||
paraformer-v2(仅API) |
|
SFT-有监督微调(Supervised Fine-Tuning)
DPO-直接偏好优化(Direct Preference Optimization)
全参训练-训练时间较长,收敛速度较慢,可实现模型新能力的学习和全局效果的优化提升。
高效训练-训练时间较短,收敛速度较快,适用于模型局部效果优化。
热词定制与管理-管理热词表,提升热词表内词汇的识别效果。
模型调优前必读
如果您并不是需要对文本生成模型进行调优,请直接前往Paraformer语音识别热词定制与管理页面。
文本生成模型调优虽然能在特定业务/场景取得非常好的效果,但有以下限制:
耗时较长,包括:拥有一个大规模(至少1000万 token)CPT 数据集、构建一个有效(1000+)SFT 数据集、收集足够的(100+)Bad Case 构建有效 DPO 数据集、模型优化迭代速度慢等。
费用较高,调优后的模型部署后才能使用,部署费用较高。
百炼推荐您在考虑使用文本生成模型调优前先尝试使用的 Prompt 工程(Prompt Engineering)或插件调用(Function Calling)定制化您的应用,模型调优也通常作为改进模型表现“最后的手段”。因为:
在许多任务中,模型最初可能表现不佳,但通过应用正确的 Prompt 技巧可以改进结果,不一定需要使用模型调优。
迭代优化 Prompt、插件,比模型调优的迭代更敏捷、成本更低,因为模型调优的迭代可能需要重新收集数据、清洗优化数据、收集 bad case、发起客户调研等。
即使最后一定要进行模型调优,最初的 Prompt 工程、插件迭代优化相关工作也不会浪费。您的这些前期工作可以充分地在构建调优数据集时复用(用于构建数据集的输入)。
快速开始
使用控制台进行模型调优
控制台只支持文本生成模型的调优,详细使用信息请参见在控制台使用模型调优。
调优步骤 |
|
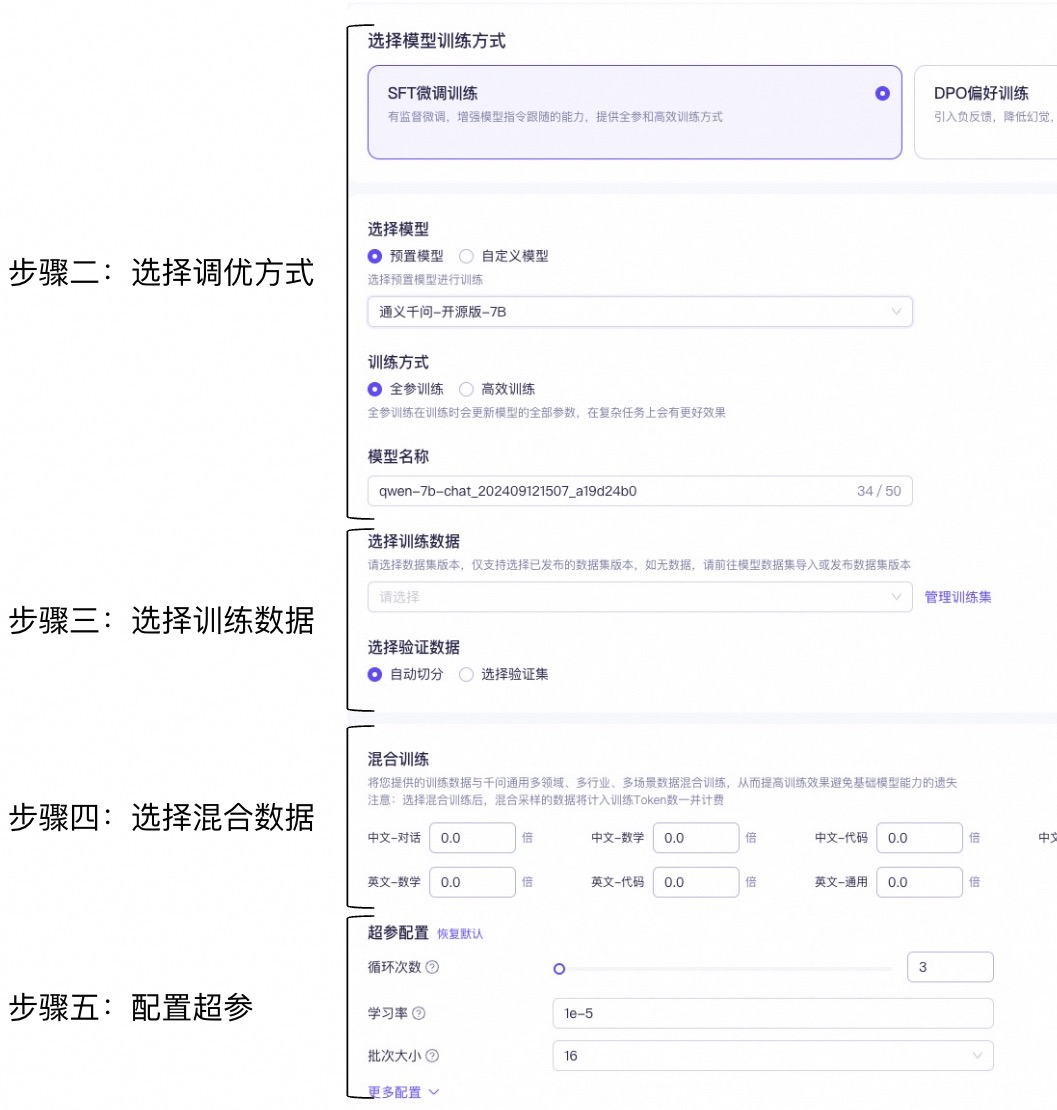
步骤一:前往模型调优页面训练新模型。 | |
步骤二:选择调优方式,请使用 SFT + 高效训练 + 您需要调优的模型。这个组合训练时间短,数据要求低。 | |
步骤三:在平台上选择构建模型所需的已上传调优数据集调优数据。 | |
步骤四(可选):选择混合训练数据,这里无需添加。 | |
步骤五:配置超参,使用默认参数,这里暂不进行修改。 | |
步骤六:点击“开始训练”后,等待模型训练完毕。 | |
步骤七:使用百炼的模型部署功能部署训练好的自定义模型,部署好后就可以对调优好的模型进行评测。模型部署相关信息请参见帮助中心:模型部署。 | |
使用命令行或 API 工具进行模型调优
API 支持各种调优功能,完整功能支持请参见使用 API 进行模型训练。
上传构建好的数据集
dashscope files.upload -f qwen-fine-tune-sample.jsonl -p fine_tune -d 'training dataset'curl --location --request POST \ 'https://dashscope.aliyuncs.com/api/v1/files' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --form 'files=@"./qwen-fine-tune-sample.jsonl"' \ --form 'descriptions="a sample fine-tune data file for qwen"'创建模型调优任务,将上一步的
response中data.uploaded_files.$.file_id放在training_file_ids中。dashscope fine_tunes.call -m qwen-turbo -t <替换为训练数据集的file_id>curl --location 'https://dashscope.aliyuncs.com/api/v1/fine-tunes' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --header 'Content-Type: application/json' \ --data '{ "model":"qwen-turbo", "training_file_ids":[ "<替换为训练数据集的file_id>" ], "hyper_parameters":{ }, "training_type":"sft" }'查看模型调优任务的状态,在上一步的response中获取到的
job_id字段,为本次模型调优任务的ID,您可以使用该ID来查询此模型调优任务的状态。dashscope fine_tunes.get -j <替换为您的调优任务 id>curl --location 'https://dashscope.aliyuncs.com/api/v1/fine-tunes/<替换为您的调优任务 id>' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --header 'Content-Type: application/json'查看模型调优的过程日志,待您查询到模型调优任务的状态为
SUCCEEDED时,表示该模型调优任务已完成。您可以通过如下方式查看模型调优任务的日志,以观察训练的效果。dashscope fine_tunes.stream -j <替换为您的调优任务 id>curl --location 'https://dashscope.aliyuncs.com/api/v1/fine-tunes/<替换为您的调优任务 id>/logs?offset=0&line=1000' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --header 'Content-Type: application/json'进行模型部署,将调优模型部署为一个可供调用的服务,从上述调优任务的response中获取到的
finetuned_output,作为创建模型服务的model_name参数。dashscope deployments.call -m <替换为上一步获取的finetuned_output>curl --location 'https://dashscope.aliyuncs.com/api/v1/deployments' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --header 'Content-Type: application/json' \ --data '{ "model_name": "<替换为调优任务成功后的模型 ID>", "capacity":2}'查询模型部署的状态。部署模型需要一定时间,您可以通过如下方式检查部署的状态,当部署状态为
RUNNING时,表示该模型当前可供调用。dashscope deployments.get -d <替换为部署任务成功后的模型实例 ID>curl --location 'https://dashscope.aliyuncs.com/api/v1/deployments/<替换为部署任务成功后的模型实例 ID>' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --header 'Content-Type: application/json'调用调优模型。当模型部署状态为
RUNNING时,您可以进行模型的调用。dashscope generation.call -m <替换为部署任务成功后的模型实例 ID> -p '你是谁?'curl --location 'https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --header 'Content-Type: application/json' \ --data '{ "model": "<替换为部署任务成功后的模型实例 ID>", "input":{ "messages":[ { "role": "user", "content": "你是谁?" } ] }, "parameters": { "result_format": "message" } }'
调优数据格式
CPT 训练集
CPT 纯文本格式训练数据,一行训练数据展开后结构如下:
{"text":"文本内容"}训练数据集样例:
SFT 训练集
SFT ChatML(Chat Markup Language)格式训练数据,支持多轮对话和多种角色设置,一行训练数据展开后结构如下:
{"messages": [
{"role": "system", "content": "<系统输入1>"},
{"role": "user", "content": "<用户输入1>"},
{"role": "assistant", "content": "<模型期望输出1>"},
{"role": "user", "content": "<用户输入2>"},
{"role": "assistant", "content": "<模型期望输出2>"}
...
...
...
]
}system/user/assistant 区别请参见消息类型。
不支持OpenAI 的name、weight参数,所有的 assistant 输出都会被训练。
训练数据集样例:
SFT 图像理解训练集
SFT图像理解 ChatML 格式训练数据(图片文件会与文本训练数据在同一目录下一起打包成 zip),一行训练数据展开后结构如下:
{"messages":[
{"role":"user",
"content":[
{"text":"<用户输入1>"},
{"image":"<图像文件名1>"}]},
{"role":"assistant",
"content":[
{"text":"<模型期望输出1>"}]},
{"role":"user",
"content":[
{"text":"<用户输入2>"}]},
{"role":"assistant",
"content":[
{"text":"<模型期望输出2>"}]},
...
...
...
]}system/user/assistant 区别请参见消息类型。
不支持OpenAI 的name、weight参数,所有的 assistant 输出都会被训练。

训练数据集样例:
DPO 数据集
DPO ChatML 格式训练数据,一行训练数据展开后结构如下:
{"messages":[
{"role":"system","content":"<系统输入>"},
{"role":"user","content":"<用户输入1>"},
{"role":"assistant","content":"<模型输出1>"},
{"role":"user","content":"<用户输入2>"},
{"role":"assistant","content":"<模型输出2>"},
{"role":"user","content":"<用户输入3>"}],
"chosen":
{"role":"assistant","content":"<赞同的模型期望输出3>"},
"rejected":
{"role":"assistant","content":"<反对的模型期望输出3>"}}模型将 messages 内的所有内容均作为输入,DPO 用于训练模型对"<用户输入3>"的正负反馈。
system/user/assistant 区别请参见消息类型。
训练数据集样例:
数据集构建技巧
数据集的规模要求
对于CPT来说,数据集最少需要一千万Token优质预训练数据;对于 SFT 来说,数据集最少需要上千条优质调优数据;对于 DPO 来说,数据集一般需要上百条人类偏好数据。如果数据调优后的模型评测结果不佳,最简单的改进方法是收集更多数据进行训练。
如果您缺乏数据,建议构建智能体应用,使用知识库索引来增强模型能力。当然在很多复杂的业务场景,可以综合采用模型调优和知识库检索结合的技术方案。
以客服场景为例,可以借助模型调优解决客服回答的语气、表达习惯、自我认知等问题,场景涉及的专业知识可以结合知识库,动态引入到模型上下文中。
百炼推荐您可以先构建 RAG 应用试运行,在收集到足够的应用数据后再通过模型调优继续提升模型表现。
您也可以采用以下策略扩充数据集:
让大模型模拟生成特定业务/场景的相关内容,辅助您生成更多用于调优数据。(生成模型建议选取表现优异、规模更大的模型)
使用百炼的数据处理功能,对您的数据集进行数据清洗、数据增强。
通过应用场景收集、网络爬虫、社交媒体和在线论坛、公开数据集、合作伙伴与行业资源、用户贡献等各种方式,人工获取更多数据。
数据的多样性与均衡性
模型调优有不同场景,针对具体业务场景时,专业性更重要;而针对问答场景时通用性更重要。您需要根据模型负责的业务模块或使用场景进行数据用例设计。因此训练效果好坏并不是仅取决于数据量,更需要考虑针对场景的专业性和多样性。
这里以智能 AI 对话场景为例,介绍一个专业、多样的数据集应该包含的各种业务场景:
具体业务 | 多样化场景/业务 |
电商客服 | 活动推送、售前咨询、售中引导、售后服务、售后回访、投诉处理等。 |
金融服务 | 贷款咨询、投资理财顾问、信用卡服务、银行账户管理等。 |
在线医疗 | 病症咨询、挂号预约、就诊须知、药品信息查询、健康小建议等。 |
AI 秘书 | IT 信息、行政信息、HR 信息、员工福利解答、公司日历查询等。 |
旅游出行助手 | 旅行规划、出入境指南、旅行保险咨询、目的地风土人情介绍等。 |
企业法律顾问 | 合同审核、知识产权保护、合规性检查、劳动法律答疑、跨境交易咨询、个案法律分析等。 |
还请特别注意的是各个场景/业务的数据数量应相对均衡,数据比例符合实际场景比例,避免某一类数据过多导致模型偏向于学习该类特征,影响模型的泛化能力。
训练集与验证集拆分
当您使用控制台进行模型调优时,支持自动将一个完整训练数据集拆分,随机抽取少量数据(20%)组成验证集,控制台也可以在训练时及时方便地显示验证集 Loss 和 Token Accuracy。

使用 API 时,您必须将准备的数据拆分成训练集和验证集,推荐两集合数据量分别为 80% 和 20%。验证集最好随机抽取,以保证验证集在各个场景/业务中相对均衡。验证集不用于训练,而是作为模型评测时的评测数据集,验证您模型调优的效果。
数据长度限制
字符与 token 的对应关系请参考字符串与Token之间的互相转换。
模型名称 | token 最大长度 |
通义千问-Plus(通义千问商业版) | 32,768 |
通义千问-Turbo(通义千问商业版) | 8,192 |
通义千问VL-Max | 8,192 |
通义千问VL-Plus | 8,192 |
通义千问2.5-开源版-72B | 131,072 |
通义千问2.5-开源版-32B | 131,072 |
通义千问2.5-开源版-14B | 131,072 |
通义千问2-开源版-72B | 8,192 |
通义千问2-开源版-7B | 8,192 |
通义千问1.5-开源版-72B | 8,192 |
通义千问1.5-开源版-14B | 8,192 |
通义千问1.5-开源版-7B | 8,192 |
通义千问-开源版-72B | 8,192 |
通义千问-开源版-14B | 2,048 |
通义千问-开源版-7B | 2,048 |
在控制台通过进行设置。

API 通过在模型训练时使用--max_length(默认值为2048)参数设置。
如果单条数据 token 长度超过设定值,API 侧 SFT 、API DPO 和控制台 SFT 会直接丢弃该条数据,不进行训练。控制台 DPO 则会自动截断超出配置长度的后续 token,截短后的数据仍参与训练。