通义千问VL模型可以根据您传入的图片或视频进行回答,支持单图或多图的输入,适用于图像描述、视觉问答、物体定位等多种任务。
快速开始
前提条件
如果通过 SDK 进行调用,需安装SDK,其中 DashScope Python SDK 版本不低于1.24.6,DashScope Java SDK 版本不低于 2.21.10。
以下示例演示了如何调用模型描述图像内容。关于本地文件和图像限制的说明,请参见如何传入本地文件、图像限制章节。
单图输入
OpenAI兼容
Python
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key="sk-xxx",
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-vl-plus", # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"
},
},
{"type": "text", "text": "图中描绘的是什么景象?"},
],
},
],
)
print(completion.choices[0].message.content)返回结果
这是一张在海滩上拍摄的照片。照片中,一个人和一只狗坐在沙滩上,背景是大海和天空。人和狗似乎在互动,狗的前爪搭在人的手上。阳光从画面的右侧照射过来,给整个场景增添了一种温暖的氛围。Node.js
import OpenAI from "openai";
const openai = new OpenAI({
// 若没有配置环境变量,请用百炼API Key将下行替换为:apiKey: "sk-xxx"
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
apiKey: process.env.DASHSCOPE_API_KEY,
// 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
baseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1"
});
async function main() {
const response = await openai.chat.completions.create({
model: "qwen3-vl-plus", // 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages: [
{
role: "user",
content: [{
type: "image_url",
image_url: {
"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"
}
},
{
type: "text",
text: "图中描绘的是什么景象?"
}
]
}
]
});
console.log(response.choices[0].message.content);
}
main()返回结果
这是一张在海滩上拍摄的照片。照片中,一个人和一只狗坐在沙滩上,背景是大海和天空。人和狗似乎在互动,狗的前爪搭在人的手上。阳光从画面的右侧照射过来,给整个场景增添了一种温暖的氛围。curl
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1/chat/completions
# === 执行时请删除该注释 ===
curl --location 'https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions' \
--header "Authorization: Bearer $DASHSCOPE_API_KEY" \
--header 'Content-Type: application/json' \
--data '{
"model": "qwen3-vl-plus",
"messages": [
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"}},
{"type": "text", "text": "图中描绘的是什么景象?"}
]
}]
}'返回结果
{
"choices": [
{
"message": {
"content": "这是一张在海滩上拍摄的照片。照片中,一个人和一只狗坐在沙滩上,背景是大海和天空。人和狗似乎在互动,狗的前爪搭在人的手上。阳光从画面的右侧照射过来,给整个场景增添了一种温暖的氛围。",
"role": "assistant"
},
"finish_reason": "stop",
"index": 0,
"logprobs": null
}
],
"object": "chat.completion",
"usage": {
"prompt_tokens": 1270,
"completion_tokens": 54,
"total_tokens": 1324
},
"created": 1725948561,
"system_fingerprint": null,
"model": "qwen3-vl-plus",
"id": "chatcmpl-0fd66f46-b09e-9164-a84f-3ebbbedbac15"
}DashScope
Python
import os
import dashscope
# 若使用新加坡地域的模型,请取消下列注释
# dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
messages = [
{
"role": "user",
"content": [
{"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"},
{"text": "图中描绘的是什么景象?"}]
}]
response = dashscope.MultiModalConversation.call(
# 若没有配置环境变量, 请用百炼API Key将下行替换为: api_key ="sk-xxx"
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key = os.getenv('DASHSCOPE_API_KEY'),
model = 'qwen3-vl-plus', # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages = messages
)
print(response.output.choices[0].message.content[0]["text"])返回结果
是一张在海滩上拍摄的照片。照片中有一位女士和一只狗。女士坐在沙滩上,微笑着与狗互动。狗戴着项圈,似乎在与女士握手。背景是大海和天空,阳光洒在她们身上,营造出温馨的氛围。Java
import java.util.Arrays;
import java.util.Collections;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.utils.JsonUtils;
import com.alibaba.dashscope.utils.Constants;
public class Main {
// 若使用新加坡地域的模型,请取消下列注释
// static {Constants.baseHttpApiUrl="https://dashscope-intl.aliyuncs.com/api/v1";}
public static void simpleMultiModalConversationCall()
throws ApiException, NoApiKeyException, UploadFileException {
MultiModalConversation conv = new MultiModalConversation();
MultiModalMessage userMessage = MultiModalMessage.builder().role(Role.USER.getValue())
.content(Arrays.asList(
Collections.singletonMap("image", "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"),
Collections.singletonMap("text", "图中描绘的是什么景象?"))).build();
MultiModalConversationParam param = MultiModalConversationParam.builder()
// 若没有配置环境变量,请用百炼API Key将下行替换为:.apiKey("sk-xxx")
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model("qwen3-vl-plus") // 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
.messages(Arrays.asList(userMessage))
.build();
MultiModalConversationResult result = conv.call(param);
System.out.println(result.getOutput().getChoices().get(0).getMessage().getContent().get(0).get("text"));
}
public static void main(String[] args) {
try {
simpleMultiModalConversationCall();
} catch (ApiException | NoApiKeyException | UploadFileException e) {
System.out.println(e.getMessage());
}
System.exit(0);
}
}返回结果
这是一张在海滩上拍摄的照片。照片中有一个穿着格子衬衫的人和一只戴着项圈的狗。人和狗面对面坐着,似乎在互动。背景是大海和天空,阳光洒在他们身上,营造出温暖的氛围。curl
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3-vl-plus",
"input":{
"messages":[
{
"role": "user",
"content": [
{"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"},
{"text": "图中描绘的是什么景象?"}
]
}
]
}
}'返回结果
{
"output": {
"choices": [
{
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": [
{
"text": "这是一张在海滩上拍摄的照片。照片中有一个穿着格子衬衫的人和一只戴着项圈的狗。他们坐在沙滩上,背景是大海和天空。阳光从画面的右侧照射过来,给整个场景增添了一种温暖的氛围。"
}
]
}
}
]
},
"usage": {
"output_tokens": 55,
"input_tokens": 1271,
"image_tokens": 1247
},
"request_id": "ccf845a3-dc33-9cda-b581-20fe7dc23f70"
}多图输入
通义千问VL 模型支持在单次请求中传入多张图片,可用于商品对比、多页文档处理等任务。实现时只需在user message 的content数组中包含多个图片对象即可。
图片数量受模型图文总 Token 上限(即模型的最大输入)的限制,所有图片和文本的总 Token 数必须小于模型的最大输入。
OpenAI兼容
Python
import os
from openai import OpenAI
client = OpenAI(
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-vl-plus", # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages=[
{"role": "user","content": [
{"type": "image_url","image_url": {"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"},},
{"type": "image_url","image_url": {"url": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/tiger.png"},},
{"type": "text", "text": "这些图描绘了什么内容?"},
],
}
],
)
print(completion.choices[0].message.content)返回结果
图1中是一位女士和一只拉布拉多犬在海滩上互动的场景。女士穿着格子衬衫,坐在沙滩上,与狗进行握手的动作,背景是海浪和天空,整个画面充满了温馨和愉快的氛围。
图2中是一只老虎在森林中行走的场景。老虎的毛色是橙色和黑色条纹相间,它正向前迈步,周围是茂密的树木和植被,地面上覆盖着落叶,整个画面给人一种野生自然的感觉。Node.js
import OpenAI from "openai";
const openai = new OpenAI(
{
// 若没有配置环境变量,请用百炼API Key将下行替换为:apiKey: "sk-xxx"
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
apiKey: process.env.DASHSCOPE_API_KEY,
// 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
baseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1"
}
);
async function main() {
const response = await openai.chat.completions.create({
model: "qwen3-vl-plus", // 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages: [
{role: "user",content: [
{type: "image_url",image_url: {"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"}},
{type: "image_url",image_url: {"url": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/tiger.png"}},
{type: "text", text: "这些图描绘了什么内容?" },
]}]
});
console.log(response.choices[0].message.content);
}
main()返回结果
第一张图片中,一个人和一只狗在海滩上互动。人穿着格子衬衫,狗戴着项圈,他们似乎在握手或击掌。
第二张图片中,一只老虎在森林中行走。老虎的毛色是橙色和黑色条纹,背景是绿色的树木和植被。curl
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1/chat/completions
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3-vl-plus",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"
}
},
{
"type": "image_url",
"image_url": {
"url": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/tiger.png"
}
},
{
"type": "text",
"text": "这些图描绘了什么内容?"
}
]
}
]
}'返回结果
{
"choices": [
{
"message": {
"content": "图1中是一位女士和一只拉布拉多犬在海滩上互动的场景。女士穿着格子衬衫,坐在沙滩上,与狗进行握手的动作,背景是海景和日落的天空,整个画面显得非常温馨和谐。\n\n图2中是一只老虎在森林中行走的场景。老虎的毛色是橙色和黑色条纹相间,它正向前迈步,周围是茂密的树木和植被,地面上覆盖着落叶,整个画面充满了自然的野性和生机。",
"role": "assistant"
},
"finish_reason": "stop",
"index": 0,
"logprobs": null
}
],
"object": "chat.completion",
"usage": {
"prompt_tokens": 2497,
"completion_tokens": 109,
"total_tokens": 2606
},
"created": 1725948561,
"system_fingerprint": null,
"model": "qwen3-vl-plus",
"id": "chatcmpl-0fd66f46-b09e-9164-a84f-3ebbbedbac15"
}DashScope
Python
import os
import dashscope
# 若使用新加坡地域的模型,请取消下列注释
# dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
messages = [
{
"role": "user",
"content": [
{"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"},
{"image": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/tiger.png"},
{"text": "这些图描绘了什么内容?"}
]
}
]
response = dashscope.MultiModalConversation.call(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx"
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv('DASHSCOPE_API_KEY'),
model='qwen3-vl-plus', # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages=messages
)
print(response.output.choices[0].message.content[0]["text"])返回结果
这些图片展示了一些动物和自然场景。第一张图片中,一个人和一只狗在海滩上互动。第二张图片是一只老虎在森林中行走Java
import java.util.Arrays;
import java.util.Collections;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import java.util.HashMap;
import com.alibaba.dashscope.utils.Constants;
public class Main {
// 若使用新加坡地域的模型,请取消下列注释
// static {Constants.baseHttpApiUrl="https://dashscope-intl.aliyuncs.com/api/v1";}
public static void simpleMultiModalConversationCall()
throws ApiException, NoApiKeyException, UploadFileException {
MultiModalConversation conv = new MultiModalConversation();
MultiModalMessage userMessage = MultiModalMessage.builder().role(Role.USER.getValue())
.content(Arrays.asList(
Collections.singletonMap("image", "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"),
Collections.singletonMap("image", "https://dashscope.oss-cn-beijing.aliyuncs.com/images/tiger.png"),
Collections.singletonMap("text", "这些图描绘了什么内容?"))).build();
MultiModalConversationParam param = MultiModalConversationParam.builder()
// 若没有配置环境变量,请用百炼API Key将下行替换为:.apiKey("sk-xxx")
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model("qwen3-vl-plus") // 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
.messages(Arrays.asList(userMessage))
.build();
MultiModalConversationResult result = conv.call(param);
System.out.println(result.getOutput().getChoices().get(0).getMessage().getContent().get(0).get("text")); }
public static void main(String[] args) {
try {
simpleMultiModalConversationCall();
} catch (ApiException | NoApiKeyException | UploadFileException e) {
System.out.println(e.getMessage());
}
System.exit(0);
}
}返回结果
这些图片展示了一些动物和自然场景。
1. 第一张图片:一个女人和一只狗在海滩上互动。女人穿着格子衬衫,坐在沙滩上,狗戴着项圈,伸出爪子与女人握手。
2. 第二张图片:一只老虎在森林中行走。老虎的毛色是橙色和黑色条纹,背景是树木和树叶。curl
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation
# === 执行时请删除该注释 ===
curl --location 'https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation' \
--header "Authorization: Bearer $DASHSCOPE_API_KEY" \
--header 'Content-Type: application/json' \
--data '{
"model": "qwen3-vl-plus",
"input":{
"messages":[
{
"role": "user",
"content": [
{"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"},
{"image": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/tiger.png"},
{"text": "这些图展现了什么内容?"}
]
}
]
}
}'返回结果
{
"output": {
"choices": [
{
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": [
{
"text": "这些图片展示了一些动物和自然场景。第一张图片中,一个人和一只狗在海滩上互动。第二张图片是一只老虎在森林中行走。"
}
]
}
}
]
},
"usage": {
"output_tokens": 81,
"input_tokens": 1277,
"image_tokens": 2497
},
"request_id": "ccf845a3-dc33-9cda-b581-20fe7dc23f70"
}模型选型
对于如高精度的物体识别与定位(包括 3D 定位)、 Agent 工具调用、文档和网页解析、复杂题目解答、长视频理解等任务,首选 Qwen3-VL。系列内模型对比如下:
qwen3-vl-plus:性能最强的模型。qwen3-vl-flash:速度更快,成本更低,是兼顾性能与成本的高性价比选择,适用于对响应速度敏感的场景。
对于简单的图像描述、短视频摘要提取等通用任务,可选 Qwen2.5-VL,系列内模型对比如下:
qwen-vl-max:在 Qwen2.5-VL 系列中,是效果最佳的版本。qwen-vl-plus:速度更快,在效果与成本之间实现良好平衡。
模型的名称、上下文、价格、快照版本等信息请参见模型列表;并发限流条件请参考限流。
效果概览
图像问答
描述图像中的内容或者对其进行分类打标,如识别人物、地点、动植物等。
如果太阳很刺眼,我应该用这张图中的什么物品? | 当太阳很刺眼时,你应该使用图中的粉色太阳镜。太阳镜可以有效阻挡强光、减少紫外线对眼睛的伤害,帮助你在阳光强烈时保护视力并提升视觉舒适度。 |

创意写作
根据图片或视频内容生成生动的文字描述,适用于故事创作、文案撰写、短视频脚本等创意场景。
请根据图片内容,帮我写一段有意思的朋友圈文案。 | 好的,这张图片充满了浓郁的中秋节日氛围,古典与现代元素结合得非常巧妙。根据图片中的主要元素,我为你准备了几个不同风格的朋友圈文案,你可以根据自己的喜好选择。 诗意唯美风 今夜月明人尽望,不知秋思落谁家。嫦娥奔月,玉兔捣药,古人的浪漫在今夜被点亮。愿这轮明月,能照亮你回家的路,也能寄去我最深的思念。中秋节快乐! 温馨祝福风 月圆人团圆,中秋夜最温柔。看烟花绽放,赏圆月当空,吃一口月饼,道一声安康。愿你我心中所念,皆能如愿以偿。祝大家中秋快乐,阖家幸福! |

文字识别与信息抽取
识别图像中的文字、公式或抽取票据、证件、表单中的信息,支持格式化输出文本;Qwen3-VL模型支持的语言增加至33种,支持的语言可参见模型特性对比。
提取图中的:['发票代码','发票号码','到站','燃油费','票价','乘车日期','开车时间','车次','座号'],请你以JSON格式输出。 | { "发票代码": "221021325353", "发票号码": "10283819", "到站": "开发区", "燃油费": "2.0", "票价": "8.00<全>", "乘车日期": "2013-06-29", "开车时间": "流水", "车次": "040", "座号": "371" } |

多学科题目解答
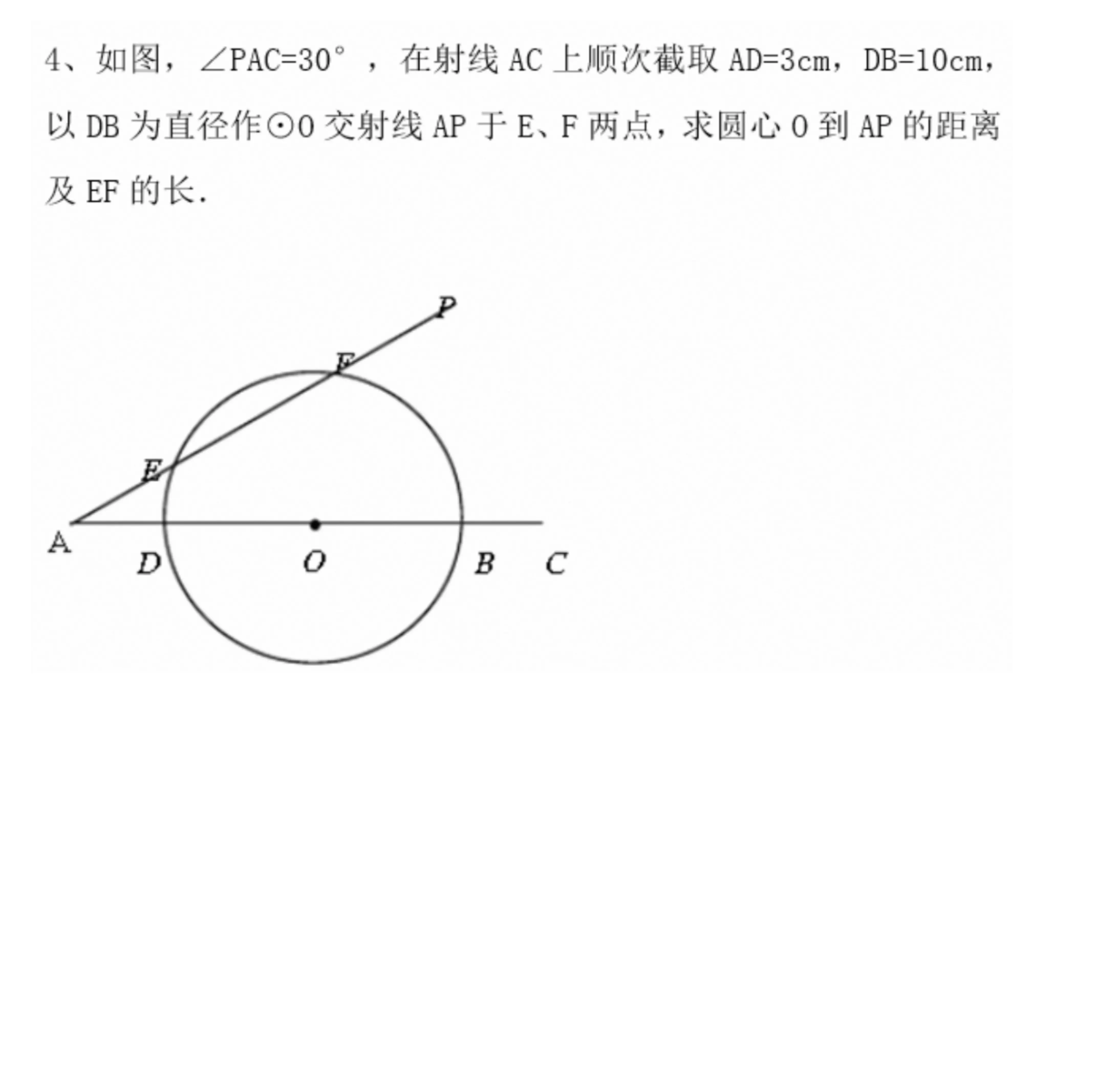
解答图像中的数学、物理、化学等问题,适用于中小学、大学以及成人教育阶段。
请你分步骤解答图中的数学题。 |
|

视觉编码
可通过图像或视频生成代码,可用于将设计图、网站截图等生成HTML、CSS、JS 代码。
根据我的草图设计使用HTML、CSS创建网页,主色调为黑色。 |
网页预览效果 |
物体定位
支持二维和三维定位,可用于判断物体方位、视角变化、遮挡关系。三维定位为Qwen3-VL模型新增能力。
Qwen2.5-VL模型 480*480 ~ 2560*2560 分辨率范围内,物体定位效果较为鲁棒,在此范围之外检测精度可能会下降(偶发检测框漂移现象);可参见常见问题将定位结果绘制到原图上。
2D定位
| 可视化展示2D定位效果
|
检测图像中的汽车并预测3D位置。输出JSON: |
|




文档解析
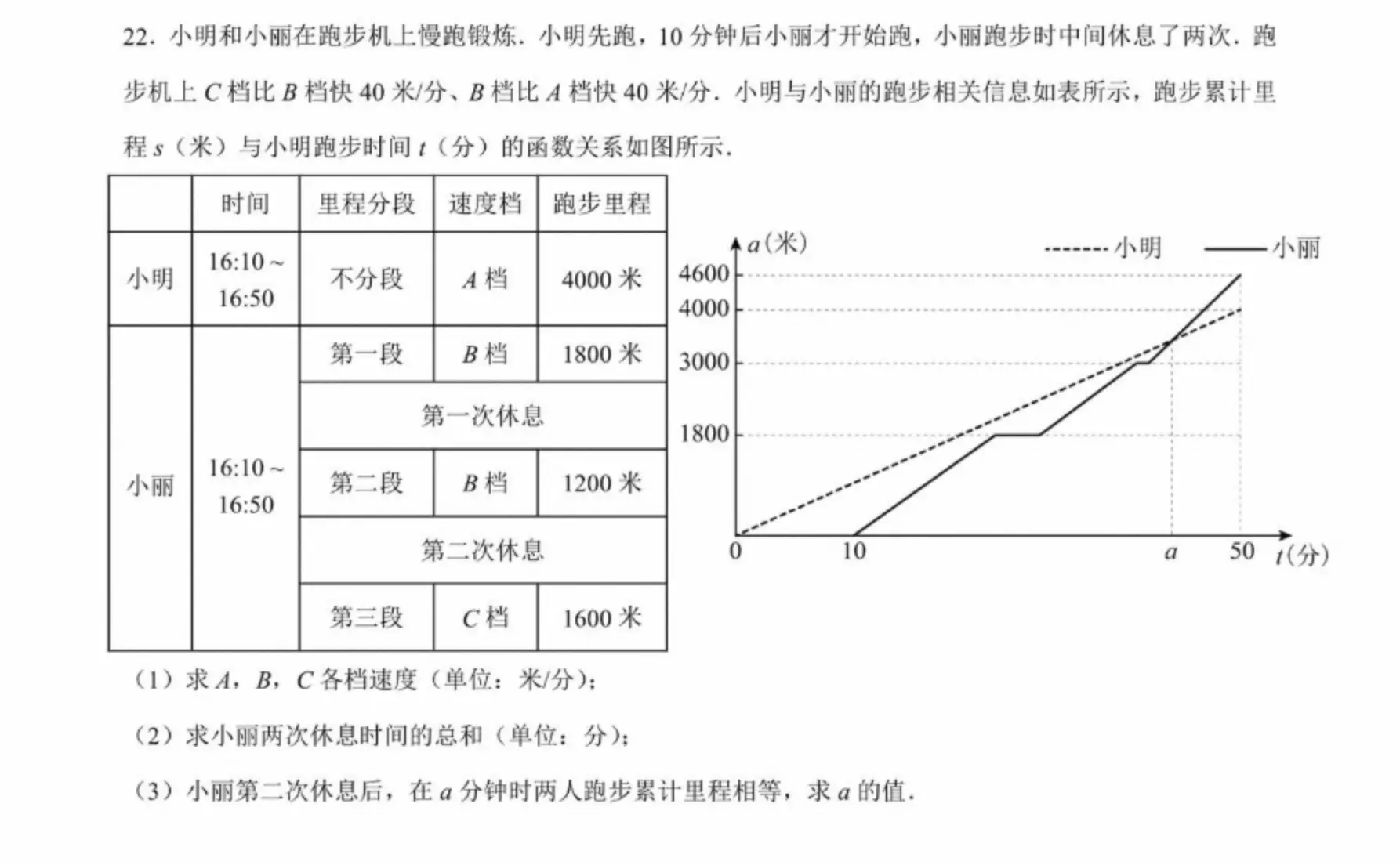
将图像类的文档(如扫描件/图片PDF)解析为 QwenVL HTML 或 QwenVL Markdown 格式,该格式不仅能精准识别文本,还能获取图像、表格等元素的位置信息。Qwen3-VL模型新增解析为 Markdown 格式的能力。
推荐提示词如下:qwenvl html(解析为HTML格式)或qwenvl markdown(解析为Markdown格式)
qwenvl markdown。 |
可视化展示效果 |
视频理解
分析视频内容,如对具体事件进行定位并获取时间戳,或生成关键时间段的摘要。
请你描述下视频中的人物的一系列动作,以JSON格式输出开始时间(start_time)、结束时间(end_time)、事件(event),请使用HH:mm:ss表示 时间戳。 | { "events": [ { "start_time": "00:00:00", "end_time": "00:00:05", "event": "人物手持一个纸箱走向桌子,并将纸箱放在桌上。" }, { "start_time": "00:00:05", "end_time": "00:00:15", "event": "人物拿起扫描枪,对准纸箱上的标签进行扫描。" }, { "start_time": "00:00:15", "end_time": "00:00:21", "event": "人物将扫描枪放回原位,然后拿起笔在笔记本上记录信息。"}] } |
核心能力
开启/关闭思考模式
qwen3-vl-plus、qwen3-vl-flash系列模型属于混合思考模型,模型可以在思考后回复,也可直接回复;通过
enable_thinking参数控制是否开启思考模式:true:开启思考模式false(默认):关闭思考模式
qwen3-vl-235b-a22b-thinking等带thinking后缀的属于仅思考模型,模型总会在回复前进行思考,且无法关闭。
模型配置:在非 Agent 工具调用的通用对话场景下,为保持最佳效果,建议不设置
System Message,可将模型角色设定、输出格式要求等指令通过User Message传入。优先使用流式输出: 开启思考模式时,支持流式和非流式两种输出方式。为避免因响应内容过长导致超时,建议优先使用流式输出方式。
限制思考长度:深度思考模型有时会输出冗长的推理过程,可使用
thinking_budget参数限制思考过程的长度。若模型思考过程生成的 Token 数超过thinking_budget,推理内容会进行截断并立刻开始生成最终回复内容。thinking_budget默认值为模型的最大思维链长度,请参见模型列表。
OpenAI 兼容
enable_thinking非 OpenAI 标准参数,若使用 OpenAI Python SDK 请通过 extra_body传入。
from openai import OpenAI
import os
# 初始化OpenAI客户端
client = OpenAI(
# 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key="sk-xxx",
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
reasoning_content = "" # 定义完整思考过程
answer_content = "" # 定义完整回复
is_answering = False # 判断是否结束思考过程并开始回复
enable_thinking = True
# 创建聊天完成请求
completion = client.chat.completions.create(
model="qwen3-vl-plus",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://img.alicdn.com/imgextra/i1/O1CN01gDEY8M1W114Hi3XcN_!!6000000002727-0-tps-1024-406.jpg"
},
},
{"type": "text", "text": "这道题怎么解答?"},
],
},
],
stream=True,
# enable_thinking 参数开启思考过程,thinking_budget 参数设置最大推理过程 Token 数
# qwen3-vl-plus、 qwen3-vl-flash可通过enable_thinking开启或关闭思考、对于qwen3-vl-235b-a22b-thinking等带thinking后缀的模型,enable_thinking仅支持设置为开启,对其他Qwen-VL模型均不适用
extra_body={
'enable_thinking': enable_thinking,
"thinking_budget": 81920},
# 解除以下注释会在最后一个chunk返回Token使用量
# stream_options={
# "include_usage": True
# }
)
if enable_thinking:
print("\n" + "=" * 20 + "思考过程" + "=" * 20 + "\n")
for chunk in completion:
# 如果chunk.choices为空,则打印usage
if not chunk.choices:
print("\nUsage:")
print(chunk.usage)
else:
delta = chunk.choices[0].delta
# 打印思考过程
if hasattr(delta, 'reasoning_content') and delta.reasoning_content != None:
print(delta.reasoning_content, end='', flush=True)
reasoning_content += delta.reasoning_content
else:
# 开始回复
if delta.content != "" and is_answering is False:
print("\n" + "=" * 20 + "完整回复" + "=" * 20 + "\n")
is_answering = True
# 打印回复过程
print(delta.content, end='', flush=True)
answer_content += delta.content
# print("=" * 20 + "完整思考过程" + "=" * 20 + "\n")
# print(reasoning_content)
# print("=" * 20 + "完整回复" + "=" * 20 + "\n")
# print(answer_content)import OpenAI from "openai";
// 初始化 openai 客户端
const openai = new OpenAI({
// 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key="sk-xxx",
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
apiKey: process.env.DASHSCOPE_API_KEY,
// 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1'
});
let reasoningContent = '';
let answerContent = '';
let isAnswering = false;
let enableThinking = true;
let messages = [
{
role: "user",
content: [
{ type: "image_url", image_url: { "url": "https://img.alicdn.com/imgextra/i1/O1CN01gDEY8M1W114Hi3XcN_!!6000000002727-0-tps-1024-406.jpg" } },
{ type: "text", text: "解答这道题" },
]
}]
async function main() {
try {
const stream = await openai.chat.completions.create({
model: 'qwen3-vl-plus',
messages: messages,
stream: true,
// 注意:在 Node.js SDK,enableThinking 这样的非标准参数作为顶层属性传递的,无需放在 extra_body 中
enable_thinking: enableThinking,
thinking_budget: 81920
});
if (enableThinking){console.log('\n' + '='.repeat(20) + '思考过程' + '='.repeat(20) + '\n');}
for await (const chunk of stream) {
if (!chunk.choices?.length) {
console.log('\nUsage:');
console.log(chunk.usage);
continue;
}
const delta = chunk.choices[0].delta;
// 处理思考过程
if (delta.reasoning_content) {
process.stdout.write(delta.reasoning_content);
reasoningContent += delta.reasoning_content;
}
// 处理正式回复
else if (delta.content) {
if (!isAnswering) {
console.log('\n' + '='.repeat(20) + '完整回复' + '='.repeat(20) + '\n');
isAnswering = true;
}
process.stdout.write(delta.content);
answerContent += delta.content;
}
}
} catch (error) {
console.error('Error:', error);
}
}
main();# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1/chat/completions
# === 执行时请删除该注释 ===
curl --location 'https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions' \
--header "Authorization: Bearer $DASHSCOPE_API_KEY" \
--header 'Content-Type: application/json' \
--data '{
"model": "qwen3-vl-plus",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://img.alicdn.com/imgextra/i1/O1CN01gDEY8M1W114Hi3XcN_!!6000000002727-0-tps-1024-406.jpg"
}
},
{
"type": "text",
"text": "请解答这道题"
}
]
}
],
"stream":true,
"stream_options":{"include_usage":true},
"enable_thinking": true,
"thinking_budget": 81920
}'DashScope
import os
import dashscope
from dashscope import MultiModalConversation
# 若使用新加坡地域的模型,请取消下列注释
# dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
enable_thinking=True
messages = [
{
"role": "user",
"content": [
{"image": "https://img.alicdn.com/imgextra/i1/O1CN01gDEY8M1W114Hi3XcN_!!6000000002727-0-tps-1024-406.jpg"},
{"text": "解答这道题?"}
]
}
]
response = MultiModalConversation.call(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv('DASHSCOPE_API_KEY'),
model="qwen3-vl-plus",
messages=messages,
stream=True,
# enable_thinking 参数开启思考过程
# qwen3-vl-plus、 qwen3-vl-flash可通过enable_thinking开启或关闭思考、对于qwen3-vl-235b-a22b-thinking等带thinking后缀的模型,enable_thinking仅支持设置为开启,对其他Qwen-VL模型均不适用
enable_thinking=enable_thinking,
# thinking_budget 参数设置最大推理过程 Token 数
thinking_budget=81920,
)
# 定义完整思考过程
reasoning_content = ""
# 定义完整回复
answer_content = ""
# 判断是否结束思考过程并开始回复
is_answering = False
if enable_thinking:
print("=" * 20 + "思考过程" + "=" * 20)
for chunk in response:
# 如果思考过程与回复皆为空,则忽略
message = chunk.output.choices[0].message
reasoning_content_chunk = message.get("reasoning_content", None)
if (chunk.output.choices[0].message.content == [] and
reasoning_content_chunk == ""):
pass
else:
# 如果当前为思考过程
if reasoning_content_chunk != None and chunk.output.choices[0].message.content == []:
print(chunk.output.choices[0].message.reasoning_content, end="")
reasoning_content += chunk.output.choices[0].message.reasoning_content
# 如果当前为回复
elif chunk.output.choices[0].message.content != []:
if not is_answering:
print("\n" + "=" * 20 + "完整回复" + "=" * 20)
is_answering = True
print(chunk.output.choices[0].message.content[0]["text"], end="")
answer_content += chunk.output.choices[0].message.content[0]["text"]
# 如果您需要打印完整思考过程与完整回复,请将以下代码解除注释后运行
# print("=" * 20 + "完整思考过程" + "=" * 20 + "\n")
# print(f"{reasoning_content}")
# print("=" * 20 + "完整回复" + "=" * 20 + "\n")
# print(f"{answer_content}")// dashscope SDK的版本 >= 2.21.10
import java.util.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import io.reactivex.Flowable;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.exception.InputRequiredException;
import java.lang.System;
import com.alibaba.dashscope.utils.Constants;
public class Main {
// 若使用新加坡地域的模型,请取消下列注释
// static {Constants.baseHttpApiUrl="https://dashscope-intl.aliyuncs.com/api/v1";}
private static final Logger logger = LoggerFactory.getLogger(Main.class);
private static StringBuilder reasoningContent = new StringBuilder();
private static StringBuilder finalContent = new StringBuilder();
private static boolean isFirstPrint = true;
private static void handleGenerationResult(MultiModalConversationResult message) {
String re = message.getOutput().getChoices().get(0).getMessage().getReasoningContent();
String reasoning = Objects.isNull(re)?"":re; // 默认值
List<Map<String, Object>> content = message.getOutput().getChoices().get(0).getMessage().getContent();
if (!reasoning.isEmpty()) {
reasoningContent.append(reasoning);
if (isFirstPrint) {
System.out.println("====================思考过程====================");
isFirstPrint = false;
}
System.out.print(reasoning);
}
if (Objects.nonNull(content) && !content.isEmpty()) {
Object text = content.get(0).get("text");
finalContent.append(content.get(0).get("text"));
if (!isFirstPrint) {
System.out.println("\n====================完整回复====================");
isFirstPrint = true;
}
System.out.print(text);
}
}
public static MultiModalConversationParam buildMultiModalConversationParam(MultiModalMessage Msg) {
return MultiModalConversationParam.builder()
// 若没有配置环境变量,请用百炼API Key将下行替换为:.apiKey("sk-xxx")
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model("qwen3-vl-plus")
.messages(Arrays.asList(Msg))
.enableThinking(true)
.thinkingBudget(81920)
.incrementalOutput(true)
.build();
}
public static void streamCallWithMessage(MultiModalConversation conv, MultiModalMessage Msg)
throws NoApiKeyException, ApiException, InputRequiredException, UploadFileException {
MultiModalConversationParam param = buildMultiModalConversationParam(Msg);
Flowable<MultiModalConversationResult> result = conv.streamCall(param);
result.blockingForEach(message -> {
handleGenerationResult(message);
});
}
public static void main(String[] args) {
try {
MultiModalConversation conv = new MultiModalConversation();
MultiModalMessage userMsg = MultiModalMessage.builder()
.role(Role.USER.getValue())
.content(Arrays.asList(Collections.singletonMap("image", "https://img.alicdn.com/imgextra/i1/O1CN01gDEY8M1W114Hi3XcN_!!6000000002727-0-tps-1024-406.jpg"),
Collections.singletonMap("text", "请解答这道题")))
.build();
streamCallWithMessage(conv, userMsg);
// 打印最终结果
// if (reasoningContent.length() > 0) {
// System.out.println("\n====================完整回复====================");
// System.out.println(finalContent.toString());
// }
} catch (ApiException | NoApiKeyException | UploadFileException | InputRequiredException e) {
logger.error("An exception occurred: {}", e.getMessage());
}
System.exit(0);
}
}# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-H 'X-DashScope-SSE: enable' \
-d '{
"model": "qwen3-vl-plus",
"input":{
"messages":[
{
"role": "user",
"content": [
{"image": "https://img.alicdn.com/imgextra/i1/O1CN01gDEY8M1W114Hi3XcN_!!6000000002727-0-tps-1024-406.jpg"},
{"text": "请解答这道题"}
]
}
]
},
"parameters":{
"enable_thinking": true,
"incremental_output": true,
"thinking_budget": 81920
}
}'开启高分辨率模式
对于需要关注大量细节的图像,可设置vl_high_resolution_images参数为True以开启高分辨率模式。开启后,每张图像的默认Token 上限(1280 或 2560)提升至 16384。
模式 | 单图Token上限 | 适用场景 | 成本与延迟 |
开启( | 16384 | 内容丰富、需要关注细节的场景 | 较高 |
关闭( | Qwen3-VL、 其他Qwen-VL模型:1280 | 细节较少、对速度要求高或成本敏感的场景。 | 较低 |
OpenAI 兼容
vl_high_resolution_images非 OpenAI 标准参数,若使用 OpenAI Python SDK 请通过 extra_body传入.
Python
import os
import time
from openai import OpenAI
client = OpenAI(
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
def test_resolution(high_resolution=False):
completion = client.chat.completions.create(
model="qwen3-vl-plus",
messages=[
{"role": "user","content": [
{"type": "image_url","image_url": {"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250212/earbrt/vcg_VCG211286867973_RF.jpg"},},
{"type": "text", "text": "这些图描绘了什么内容?"},
],
}
],
extra_body={'enable_thinking': False,
"vl_high_resolution_images":high_resolution}
)
usage_info= completion.usage.prompt_tokens
return {
'usage_info': usage_info
}
# 输出对比结果
print("\n==================== Token用量对比 ====================")
# 测试低分辨率
result_low = test_resolution(high_resolution=False)
# 等待一下避免API限制
time.sleep(2)
# 测试高分辨率
result_high = test_resolution(high_resolution=True)
if result_low['usage_info'] and result_high['usage_info']:
low_tokens = result_low['usage_info']
high_tokens = result_high['usage_info']
print(f"高分辨率模式-输入总Tokens: {high_tokens}")
print(f"低分辨率模式-输入总Tokens: {low_tokens}")
print(f"差异: {high_tokens - low_tokens} tokens")
Node.js
import OpenAI from "openai";
const openai = new OpenAI(
{
// 若没有配置环境变量,请用百炼API Key将下行替换为:apiKey: "sk-xxx"
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
apiKey: process.env.DASHSCOPE_API_KEY,
// 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
baseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1"
}
);
async function test_resolution(high_resolution) {
const response = await openai.chat.completions.create({
model: "qwen3-vl-plus",
messages: [
{role: "user",content: [
{type: "image_url",image_url: {"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250212/earbrt/vcg_VCG211286867973_RF.jpg"}},
{type: "text", text: "图像描绘了什么内容?" },
]}],
enable_thinking: false,
vl_high_resolution_images:high_resolution
});
return response.usage.prompt_tokens;
}
// 测试低分辨率和高分辨率
(async function main() {
console.log("\n==================== Token用量对比 ====================")
const result_low = await test_resolution(false);
const result_high = await test_resolution(true);
console.log("高分辨率 输入总Token 数量:",result_high);
console.log("低分辨率 输入总Token 数量:", result_low);
console.log("差异:", result_high-result_low);
})();curl
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1/chat/completions
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3-vl-plus",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250212/earbrt/vcg_VCG211286867973_RF.jpg"
}
},
{
"type": "text",
"text": "这些图描绘了什么内容?"
}
]
}
],
"enable_thinking": false,
"vl_high_resolution_images":true
}'DashScope
Python
import os
import time
import dashscope
# 若使用新加坡地域的模型,请取消下列注释
# dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
messages = [
{
"role": "user",
"content": [
{"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250212/earbrt/vcg_VCG211286867973_RF.jpg"},
{"text": "这张图表现了什么内容?"}
]
}
]
def test_resolution(high_resolution=False):
"""测试不同分辨率设置的结果"""
response = dashscope.MultiModalConversation.call(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx"
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv('DASHSCOPE_API_KEY'),
model='qwen3-vl-plus',
enable_thinking=False,
messages=messages,
vl_high_resolution_images=high_resolution
)
return {
'usage_info': response.usage
}
# 输出对比结果
print("\n==================== Token用量对比 ====================")
# 测试低分辨率
result_low = test_resolution(high_resolution=False)
# 等待一下避免API限制
time.sleep(2)
# 测试高分辨率
result_high = test_resolution(high_resolution=True)
if result_low['usage_info'] and result_high['usage_info']:
low_tokens = result_low['usage_info'].input_tokens_details['image_tokens']
high_tokens = result_high['usage_info'].input_tokens_details['image_tokens']
print(f"高分辨率模式-图像Tokens: {high_tokens}")
print(f"低分辨率模式-图像Tokens: {low_tokens}")
print(f"差异: {high_tokens - low_tokens} tokens ")Java
// dashscope SDK的版本 >= 2.21.10
import java.util.Arrays;
import java.util.Collections;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.utils.Constants;
public class Main {
// 若使用新加坡地域的模型,请取消下列注释
// static {Constants.baseHttpApiUrl="https://dashscope-intl.aliyuncs.com/api/v1";}
public static Integer simpleMultiModalConversationCall(boolean highResolution)
throws ApiException, NoApiKeyException, UploadFileException {
MultiModalConversation conv = new MultiModalConversation();
MultiModalMessage userMessage = MultiModalMessage.builder().role(Role.USER.getValue())
.content(Arrays.asList(
Collections.singletonMap("image", "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250212/earbrt/vcg_VCG211286867973_RF.jpg"),
Collections.singletonMap("text", "这张图表现了什么内容?"))).build();
MultiModalConversationParam param = MultiModalConversationParam.builder()
// 若没有配置环境变量,请用百炼API Key将下行替换为:.apiKey("sk-xxx")
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model("qwen3-vl-plus")
.enableThinking(false)
.messages(Arrays.asList(userMessage))
.vlHighResolutionImages(highResolution)
.build();
MultiModalConversationResult result = conv.call(param);
return result.getUsage().getImageTokens();
}
public static void main(String[] args) {
try {
// 调用高分辨率模式
Integer highResToken = simpleMultiModalConversationCall(true);
// 调用低分辨率模式
Integer lowResToken = simpleMultiModalConversationCall(false);
// 输出对比结果
System.out.println("=== Token使用对比 ===");
System.out.println("高分辨率模式Token数:" + highResToken);
System.out.println("低分辨率模式Token数:" + lowResToken);
System.out.println("差异:" + (highResToken - lowResToken));
} catch (ApiException | NoApiKeyException | UploadFileException e) {
System.out.println(e.getMessage());
}
System.exit(0);
}
}curl
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3-vl-plus",
"input":{
"messages":[
{
"role": "user",
"content": [
{"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250212/earbrt/vcg_VCG211286867973_RF.jpg"},
{"text": "这张图表现了什么内容?"}
]
}
]
},
"parameters": {
"vl_high_resolution_images": true,
"enable_thinking": false
}
}'视频理解
通义千问VL模型支持对视频内容进行理解,文件形式包括图像列表(视频帧)或视频文件。
建议使用性能较优的最新版或近期快照版模型理解视频文件。
视频文件
视频抽帧说明
通义千问VL模型通过对视频进行抽帧来理解其内容,抽帧的频率决定了模型分析的精细度,不同SDK的控制方式有以下不同:
使用 DashScope SDK:
可通过 fps 参数来控制,表示每隔
秒抽取一帧图像(fps参数默认 为2.0,范围 (0.1, 10),建议为高速运动场景设置较高 fps,为静态或长视频设置较低fps。
使用 OpenAI 兼容SDK:抽帧频率固定为每 0.5 秒一帧,不支持自定义。
以下是理解在线视频(通过URL指定)的示例代码。了解如何传入本地文件。
OpenAI兼容
使用OpenAI SDK或HTTP方式向通义千问VL模型直接输入视频文件时,需要将用户消息中的"type"参数设为"video_url"。
Python
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-vl-plus",
messages=[
{"role": "user","content": [{
# 直接传入视频文件时,请将type的值设置为video_url
# 使用OpenAI SDK时,视频文件默认每间隔0.5秒抽取一帧,且不支持修改,如需自定义抽帧频率,请使用DashScope SDK.
"type": "video_url",
"video_url": {"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241115/cqqkru/1.mp4"}},
{"type": "text","text": "这段视频的内容是什么?"}]
}]
)
print(completion.choices[0].message.content)Node.js
import OpenAI from "openai";
const openai = new OpenAI(
{
// 若没有配置环境变量,请用百炼API Key将下行替换为:apiKey: "sk-xxx"
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
apiKey: process.env.DASHSCOPE_API_KEY,
// 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
baseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1"
}
);
async function main() {
const response = await openai.chat.completions.create({
model: "qwen3-vl-plus",
messages: [
{role: "user",content: [
// 直接传入视频文件时,请将type的值设置为video_url
// 使用OpenAI SDK时,视频文件默认每间隔0.5秒抽取一帧,且不支持修改,如需自定义抽帧频率,请使用DashScope SDK.
{type: "video_url", video_url: {"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241115/cqqkru/1.mp4"}},
{type: "text", text: "这段视频的内容是什么?" },
]}]
});
console.log(response.choices[0].message.content);
}
main()curl
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1/chat/completions
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3-vl-plus",
"messages": [
{"role": "user","content": [{"type": "video_url","video_url": {"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241115/cqqkru/1.mp4"}},
{"type": "text","text": "这段视频的内容是什么?"}]}]
}'DashScope
Python
import dashscope
import os
# 若使用新加坡地域的模型,请取消下列注释
# dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
messages = [
{"role": "user",
"content": [
# fps 可参数控制视频抽帧频率,表示每隔 1/fps 秒抽取一帧,完整用法请参见:https://help.aliyun.com/zh/model-studio/use-qwen-by-calling-api?#2ed5ee7377fum
{"video": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241115/cqqkru/1.mp4","fps":2},
{"text": "这段视频的内容是什么?"}
]
}
]
response = dashscope.MultiModalConversation.call(
# 若没有配置环境变量, 请用百炼API Key将下行替换为: api_key ="sk-xxx"
api_key=os.getenv('DASHSCOPE_API_KEY'),
model='qwen3-vl-plus',
messages=messages
)
print(response.output.choices[0].message.content[0]["text"])Java
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.utils.JsonUtils;
import com.alibaba.dashscope.utils.Constants;
public class Main {
// 若使用新加坡地域的模型,请取消下列注释
// static {Constants.baseHttpApiUrl="https://dashscope-intl.aliyuncs.com/api/v1";}
public static void simpleMultiModalConversationCall()
throws ApiException, NoApiKeyException, UploadFileException {
MultiModalConversation conv = new MultiModalConversation();
// fps 可参数控制视频抽帧频率,表示每隔 1/fps 秒抽取一帧,完整用法请参见:https://help.aliyun.com/zh/model-studio/use-qwen-by-calling-api?#2ed5ee7377fum
Map<String, Object> params = new HashMap<>();
params.put("video", "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241115/cqqkru/1.mp4");
params.put("fps", 2);
MultiModalMessage userMessage = MultiModalMessage.builder().role(Role.USER.getValue())
.content(Arrays.asList(
params,
Collections.singletonMap("text", "这段视频的内容是什么?"))).build();
MultiModalConversationParam param = MultiModalConversationParam.builder()
// 若没有配置环境变量,请用百炼API Key将下行替换为:.apiKey("sk-xxx")
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model("qwen3-vl-plus")
.messages(Arrays.asList(userMessage))
.build();
MultiModalConversationResult result = conv.call(param);
System.out.println(result.getOutput().getChoices().get(0).getMessage().getContent().get(0).get("text"));
}
public static void main(String[] args) {
try {
simpleMultiModalConversationCall();
} catch (ApiException | NoApiKeyException | UploadFileException e) {
System.out.println(e.getMessage());
}
System.exit(0);
}
}curl
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3-vl-plus",
"input":{
"messages":[
{"role": "user","content": [{"video": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241115/cqqkru/1.mp4","fps":2},
{"text": "这段视频的内容是什么?"}]}]}
}'图像列表
图像列表数量限制
Qwen3-VL、 Qwen2.5-VL、QVQ系列模型:最少传入4张图片,最多512张图片
其他模型:最少传入4张图片,最多80张图片
视频抽帧说明
当视频以图像列表(即预先抽取的视频帧)传入时,可通过fps参数告知模型视频帧之间的时间间隔,这能帮助模型更准确地理解事件的顺序、持续时间和动态变化。
使用 DashScope SDK:
支持通过
fps参数指定原始视频的抽帧率,表示视频帧是每隔秒从原始视频中抽取的。该参数支持 Qwen2.5-VL、Qwen3-VL模型。 使用 OpenAI 兼容 SDK:
不支持
fps参数。模型将默认视频帧是按照每 0.5 秒一帧的频率抽取的。
以下是理解在线视频帧(通过URL指定)的示例代码。了解如何传入本地文件。
OpenAI兼容
使用OpenAI SDK或HTTP方式向通义千问VL模型输入图片列表形式的视频时,需要将用户消息中的"type"参数设为"video"。
Python
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-vl-plus", # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages=[{"role": "user","content": [
# 传入图像列表时,用户消息中的"type"参数为"video",
# 使用OpenAI SDK时,图像列表默认是以每隔0.5秒从视频中抽取出来的,且不支持修改。如需自定义抽帧频率,请使用DashScope SDK.
{"type": "video","video": ["https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/xzsgiz/football1.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/tdescd/football2.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/zefdja/football3.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/aedbqh/football4.jpg"]},
{"type": "text","text": "描述这个视频的具体过程"},
]}]
)
print(completion.choices[0].message.content)Node.js
// 确保之前在 package.json 中指定了 "type": "module"
import OpenAI from "openai";
const openai = new OpenAI({
// 若没有配置环境变量,请用百炼API Key将下行替换为:apiKey: "sk-xxx",
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
apiKey: process.env.DASHSCOPE_API_KEY,
// 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
baseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1"
});
async function main() {
const response = await openai.chat.completions.create({
model: "qwen3-vl-plus", // 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages: [{
role: "user",
content: [
{
// 传入图像列表时,用户消息中的"type"参数为"video"
// 使用OpenAI SDK时,图像列表默认是以每隔0.5秒从视频中抽取出来的,且不支持修改。如需自定义抽帧频率,请使用DashScope SDK.
type: "video",
video: [
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/xzsgiz/football1.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/tdescd/football2.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/zefdja/football3.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/aedbqh/football4.jpg"
]
},
{
type: "text",
text: "描述这个视频的具体过程"
}
]
}]
});
console.log(response.choices[0].message.content);
}
main();curl
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1/chat/completions
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3-vl-plus",
"messages": [{"role": "user",
"content": [{"type": "video",
"video": ["https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/xzsgiz/football1.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/tdescd/football2.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/zefdja/football3.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/aedbqh/football4.jpg"]},
{"type": "text",
"text": "描述这个视频的具体过程"}]}]
}'DashScope
Python
import os
import dashscope
# 若使用新加坡地域的模型,请取消下列注释
# dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
messages = [{"role": "user",
"content": [
# 若模型属于Qwen2.5-VL、Qwen3-VL系列且传入图像列表时,可设置fps参数,表示图像列表是由原视频每隔 1/fps 秒抽取的
{"video":["https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/xzsgiz/football1.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/tdescd/football2.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/zefdja/football3.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/aedbqh/football4.jpg"],
"fps":2},
{"text": "描述这个视频的具体过程"}]}]
response = dashscope.MultiModalConversation.call(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
model='qwen3-vl-plus', # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages=messages
)
print(response.output.choices[0].message.content[0]["text"])Java
// DashScope SDK版本需要不低于2.18.3
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.utils.Constants;
public class Main {
// 若使用新加坡地域的模型,请取消下列注释
// static {Constants.baseHttpApiUrl="https://dashscope-intl.aliyuncs.com/api/v1";}
private static final String MODEL_NAME = "qwen3-vl-plus"; // 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
public static void videoImageListSample() throws ApiException, NoApiKeyException, UploadFileException {
MultiModalConversation conv = new MultiModalConversation();
// 若模型属于Qwen2.5-VL或Qwen3-VL模型且传入的是图像列表时,可设置fps参数,表示图像列表是由原视频每隔 1/fps 秒抽取的
Map<String, Object> params = new HashMap<>();
params.put("video", Arrays.asList("https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/xzsgiz/football1.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/tdescd/football2.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/zefdja/football3.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/aedbqh/football4.jpg"));
params.put("fps", 2);
MultiModalMessage userMessage = MultiModalMessage.builder()
.role(Role.USER.getValue())
.content(Arrays.asList(
params,
Collections.singletonMap("text", "描述这个视频的具体过程")))
.build();
MultiModalConversationParam param = MultiModalConversationParam.builder()
// 若没有配置环境变量,请用百炼API Key将下行替换为:.apiKey("sk-xxx")
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model(MODEL_NAME)
.messages(Arrays.asList(userMessage)).build();
MultiModalConversationResult result = conv.call(param);
System.out.print(result.getOutput().getChoices().get(0).getMessage().getContent().get(0).get("text"));
}
public static void main(String[] args) {
try {
videoImageListSample();
} catch (ApiException | NoApiKeyException | UploadFileException e) {
System.out.println(e.getMessage());
}
System.exit(0);
}
}curl
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3-vl-plus",
"input": {
"messages": [
{
"role": "user",
"content": [
{
"video": [
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/xzsgiz/football1.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/tdescd/football2.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/zefdja/football3.jpg",
"https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241108/aedbqh/football4.jpg"
],
"fps":2
},
{
"text": "描述这个视频的具体过程"
}
]
}
]
}
}'传入本地文件(Base64 编码或文件路径)
通义千问VL 提供两种本地文件上传方式:
Base64 编码上传
文件路径直接上传(传输更稳定,推荐方式)
上传方式:
Base64 编码上传
将文件转换为 Base64 编码字符串,再传入模型。适用于 OpenAI 和 DashScope SDK 及 HTTP 方式
文件路径上传
直接向模型传入本地文件路径。仅 DashScope Python 和 Java SDK 支持,不支持 DashScope HTTP 和OpenAI 兼容方式。
请您参考下表,结合您的编程语言与操作系统指定文件的路径。
使用限制:
建议优先选择文件路径上传(稳定性更高),1MB以下的文件可选择 Base64 编码方式上传;
直接传入文件路径时,单张图像或视频帧(图像列表)本身需小于 10MB,单个视频需小于100MB;
Base64编码方式传入时,由于Base64编码会增加数据体积,需保证编码后的单个图像或视频需小于 10MB。
如需压缩文件体积请参见如何将图像或视频压缩到满足要求的大小?
图像
文件路径传入
传入文件路径仅支持 DashScope Python 和 Java SDK方式调用,不支持 DashScope HTTP 和OpenAI 兼容方式。
Python
import os
from dashscope import MultiModalConversation
import dashscope
# 若使用新加坡地域的模型,请取消下列注释
# dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
# 将xxx/eagle.png替换为你本地图像的绝对路径
local_path = "xxx/eagle.png"
image_path = f"file://{local_path}"
messages = [
{'role':'user',
'content': [{'image': image_path},
{'text': '图中描绘的是什么景象?'}]}]
response = MultiModalConversation.call(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx"
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv('DASHSCOPE_API_KEY'),
model='qwen3-vl-plus', # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages=messages)
print(response.output.choices[0].message.content[0]["text"])Java
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.utils.Constants;
public class Main {
// 若使用新加坡地域的模型,请取消下列注释
// static {Constants.baseHttpApiUrl="https://dashscope-intl.aliyuncs.com/api/v1";}
public static void callWithLocalFile(String localPath)
throws ApiException, NoApiKeyException, UploadFileException {
String filePath = "file://"+localPath;
MultiModalConversation conv = new MultiModalConversation();
MultiModalMessage userMessage = MultiModalMessage.builder().role(Role.USER.getValue())
.content(Arrays.asList(new HashMap<String, Object>(){{put("image", filePath);}},
new HashMap<String, Object>(){{put("text", "图中描绘的是什么景象?");}})).build();
MultiModalConversationParam param = MultiModalConversationParam.builder()
// 若没有配置环境变量,请用百炼API Key将下行替换为:.apiKey("sk-xxx")
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model("qwen3-vl-plus") // 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
.messages(Arrays.asList(userMessage))
.build();
MultiModalConversationResult result = conv.call(param);
System.out.println(result.getOutput().getChoices().get(0).getMessage().getContent().get(0).get("text"));}
public static void main(String[] args) {
try {
// 将xxx/eagle.png替换为你本地图像的绝对路径
callWithLocalFile("xxx/eagle.png");
} catch (ApiException | NoApiKeyException | UploadFileException e) {
System.out.println(e.getMessage());
}
System.exit(0);
}
}Base64 编码传入
OpenAI兼容
Python
from openai import OpenAI
import os
import base64
# 编码函数: 将本地文件转换为 Base64 编码的字符串
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 将xxxx/eagle.png替换为你本地图像的绝对路径
base64_image = encode_image("xxx/eagle.png")
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx"
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv('DASHSCOPE_API_KEY'),
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-vl-plus", # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
# 需要注意,传入Base64,图像格式(即image/{format})需要与支持的图片列表中的Content Type保持一致。"f"是字符串格式化的方法。
# PNG图像: f"data:image/png;base64,{base64_image}"
# JPEG图像: f"data:image/jpeg;base64,{base64_image}"
# WEBP图像: f"data:image/webp;base64,{base64_image}"
"image_url": {"url": f"data:image/png;base64,{base64_image}"},
},
{"type": "text", "text": "图中描绘的是什么景象?"},
],
}
],
)
print(completion.choices[0].message.content)Node.js
import OpenAI from "openai";
import { readFileSync } from 'fs';
const openai = new OpenAI(
{
// 若没有配置环境变量,请用百炼API Key将下行替换为:apiKey: "sk-xxx"
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
apiKey: process.env.DASHSCOPE_API_KEY,
// 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
baseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1"
}
);
const encodeImage = (imagePath) => {
const imageFile = readFileSync(imagePath);
return imageFile.toString('base64');
};
// 将xxx/eagle.png替换为你本地图像的绝对路径
const base64Image = encodeImage("xxx/eagle.png")
async function main() {
const completion = await openai.chat.completions.create({
model: "qwen3-vl-plus", // 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages: [
{"role": "user",
"content": [{"type": "image_url",
// 需要注意,传入Base64,图像格式(即image/{format})需要与支持的图片列表中的Content Type保持一致。
// PNG图像: data:image/png;base64,${base64Image}
// JPEG图像: data:image/jpeg;base64,${base64Image}
// WEBP图像: data:image/webp;base64,${base64Image}
"image_url": {"url": `data:image/png;base64,${base64Image}`},},
{"type": "text", "text": "图中描绘的是什么景象?"}]}]
});
console.log(completion.choices[0].message.content);
}
main();curl
将文件转换为 Base64 编码的字符串的方法可参见示例代码;
为了便于展示,代码中的
"data:image/jpg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAA...",该Base64 编码字符串是截断的。在实际使用中,请务必传入完整的编码字符串。
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1/chat/completions
# === 执行时请删除该注释 ===
curl --location 'https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions' \
--header "Authorization: Bearer $DASHSCOPE_API_KEY" \
--header 'Content-Type: application/json' \
--data '{
"model": "qwen3-vl-plus",
"messages": [
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "data:image/jpg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAA..."}},
{"type": "text", "text": "图中描绘的是什么景象?"}
]
}]
}'DashScope
Python
import base64
import os
from dashscope import MultiModalConversation
import dashscope
# 若使用新加坡地域的模型,请取消下列注释
# dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
# 编码函数: 将本地文件转换为 Base64 编码的字符串
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 将xxxx/eagle.png替换为你本地图像的绝对路径
base64_image = encode_image("xxxx/eagle.png")
messages = [
{
"role": "user",
"content": [
# 需要注意,传入Base64,图像格式(即image/{format})需要与支持的图片列表中的Content Type保持一致。"f"是字符串格式化的方法。
# PNG图像: f"data:image/png;base64,{base64_image}"
# JPEG图像: f"data:image/jpeg;base64,{base64_image}"
# WEBP图像: f"data:image/webp;base64,{base64_image}"
{"image": f"data:image/png;base64,{base64_image}"},
{"text": "图中描绘的是什么景象?"},
],
},
]
response = MultiModalConversation.call(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx"
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen3-vl-plus", # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages=messages,
)
print(response.output.choices[0].message.content[0]["text"])Java
import java.io.IOException;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.Base64;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import com.alibaba.dashscope.aigc.multimodalconversation.*;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.utils.Constants;
public class Main {
// 若使用新加坡地域的模型,请取消下列注释
// static {Constants.baseHttpApiUrl="https://dashscope-intl.aliyuncs.com/api/v1";}
private static String encodeImageToBase64(String imagePath) throws IOException {
Path path = Paths.get(imagePath);
byte[] imageBytes = Files.readAllBytes(path);
return Base64.getEncoder().encodeToString(imageBytes);
}
public static void callWithLocalFile(String localPath) throws ApiException, NoApiKeyException, UploadFileException, IOException {
String base64Image = encodeImageToBase64(localPath); // Base64编码
MultiModalConversation conv = new MultiModalConversation();
MultiModalMessage userMessage = MultiModalMessage.builder().role(Role.USER.getValue())
.content(Arrays.asList(
new HashMap<String, Object>() {{ put("image", "data:image/png;base64," + base64Image); }},
new HashMap<String, Object>() {{ put("text", "图中描绘的是什么景象?"); }}
)).build();
MultiModalConversationParam param = MultiModalConversationParam.builder()
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model("qwen3-vl-plus")
.messages(Arrays.asList(userMessage))
.build();
MultiModalConversationResult result = conv.call(param);
System.out.println(result.getOutput().getChoices().get(0).getMessage().getContent().get(0).get("text"));
}
public static void main(String[] args) {
try {
// 将 xxx/eagle.png 替换为你本地图像的绝对路径
callWithLocalFile("xxx/eagle.png");
} catch (ApiException | NoApiKeyException | UploadFileException | IOException e) {
System.out.println(e.getMessage());
}
System.exit(0);
}
}curl
将文件转换为 Base64 编码的字符串的方法可参见示例代码;
为了便于展示,代码中的
"data:image/jpg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAA...",该Base64 编码字符串是截断的。在实际使用中,请务必传入完整的编码字符串。
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3-vl-plus",
"input":{
"messages":[
{
"role": "user",
"content": [
{"image": "data:image/png;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAA..."},
{"text": "图中描绘的是什么景象?"}
]
}
]
}
}'视频文件
以保存在本地的test.mp4为例。
文件路径传入
传入文件路径仅支持 DashScope Python 和 Java SDK方式调用,不支持 DashScope HTTP 和OpenAI 兼容方式。
Python
import os
from dashscope import MultiModalConversation
import dashscope
# 若使用新加坡地域的模型,请取消下列注释
# dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
# 将xxxx/test.mp4替换为你本地视频的绝对路径
local_path = "xxx/test.mp4"
video_path = f"file://{local_path}"
messages = [
{'role':'user',
# fps参数控制视频抽帧数量,表示每隔1/fps 秒抽取一帧
'content': [{'video': video_path,"fps":2},
{'text': '这段视频描绘的是什么景象?'}]}]
response = MultiModalConversation.call(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx"
api_key=os.getenv('DASHSCOPE_API_KEY'),
model='qwen3-vl-plus',
messages=messages)
print(response.output.choices[0].message.content[0]["text"])Java
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.utils.Constants;
public class Main {
// 若使用新加坡地域的模型,请取消下列注释
// static {Constants.baseHttpApiUrl="https://dashscope-intl.aliyuncs.com/api/v1";}
public static void callWithLocalFile(String localPath)
throws ApiException, NoApiKeyException, UploadFileException {
String filePath = "file://"+localPath;
MultiModalConversation conv = new MultiModalConversation();
MultiModalMessage userMessage = MultiModalMessage.builder().role(Role.USER.getValue())
.content(Arrays.asList(new HashMap<String, Object>()
{{
put("video", filePath);// fps参数控制视频抽帧数量,表示每隔1/fps 秒抽取一帧
put("fps", 2);
}},
new HashMap<String, Object>(){{put("text", "这段视频描绘的是什么景象?");}})).build();
MultiModalConversationParam param = MultiModalConversationParam.builder()
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model("qwen3-vl-plus")
.messages(Arrays.asList(userMessage))
.build();
MultiModalConversationResult result = conv.call(param);
System.out.println(result.getOutput().getChoices().get(0).getMessage().getContent().get(0).get("text"));}
public static void main(String[] args) {
try {
// 将xxxx/test.mp4替换为你本地视频的绝对路径
callWithLocalFile("xxx/test.mp4");
} catch (ApiException | NoApiKeyException | UploadFileException e) {
System.out.println(e.getMessage());
}
System.exit(0);
}
}Base64 编码传入
OpenAI兼容
Python
from openai import OpenAI
import os
import base64
# 编码函数: 将本地文件转换为 Base64 编码的字符串
def encode_video(video_path):
with open(video_path, "rb") as video_file:
return base64.b64encode(video_file.read()).decode("utf-8")
# 将xxxx/test.mp4替换为你本地视频的绝对路径
base64_video = encode_video("xxx/test.mp4")
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx"
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv('DASHSCOPE_API_KEY'),
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-vl-plus",
messages=[
{
"role": "user",
"content": [
{
# 直接传入视频文件时,请将type的值设置为video_url
"type": "video_url",
"video_url": {"url": f"data:video/mp4;base64,{base64_video}"},
},
{"type": "text", "text": "这段视频描绘的是什么景象?"},
],
}
],
)
print(completion.choices[0].message.content)Node.js
import OpenAI from "openai";
import { readFileSync } from 'fs';
const openai = new OpenAI(
{
// 若没有配置环境变量,请用百炼API Key将下行替换为:apiKey: "sk-xxx"
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
apiKey: process.env.DASHSCOPE_API_KEY,
// 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
baseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1"
}
);
const encodeVideo = (videoPath) => {
const videoFile = readFileSync(videoPath);
return videoFile.toString('base64');
};
// 将xxxx/test.mp4替换为你本地视频的绝对路径
const base64Video = encodeVideo("xxx/test.mp4")
async function main() {
const completion = await openai.chat.completions.create({
model: "qwen3-vl-plus",
messages: [
{"role": "user",
"content": [{
// 直接传入视频文件时,请将type的值设置为video_url
"type": "video_url",
"video_url": {"url": `data:video/mp4;base64,${base64Video}`}},
{"type": "text", "text": "这段视频描绘的是什么景象?"}]}]
});
console.log(completion.choices[0].message.content);
}
main();
curl
将文件转换为 Base64 编码的字符串的方法可参见示例代码;
为了便于展示,代码中的
"data:video/mp4;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAA...",该Base64 编码字符串是截断的。在实际使用中,请务必传入完整的编码字符串。
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1/chat/completions
# === 执行时请删除该注释 ===
curl --location 'https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions' \
--header "Authorization: Bearer $DASHSCOPE_API_KEY" \
--header 'Content-Type: application/json' \
--data '{
"model": "qwen-vl-max",
"messages": [
{
"role": "user",
"content": [
{"type": "video_url", "video_url": {"url": "data:video/mp4;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAA..."}},
{"type": "text", "text": "图中描绘的是什么景象?"}
]
}]
}'DashScope
Python
import base64
import os
import dashscope
from dashscope import MultiModalConversation
# 若使用新加坡地域的模型,请取消下列注释
# dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
# 编码函数: 将本地文件转换为 Base64 编码的字符串
def encode_video(video_path):
with open(video_path, "rb") as video_file:
return base64.b64encode(video_file.read()).decode("utf-8")
# 将xxxx/test.mp4替换为你本地视频的绝对路径
base64_video = encode_video("xxxx/test.mp4")
messages = [{'role':'user',
# fps参数控制视频抽帧数量,表示每隔1/fps 秒抽取一帧
'content': [{'video': f"data:video/mp4;base64,{base64_video}","fps":2},
{'text': '这段视频描绘的是什么景象?'}]}]
response = MultiModalConversation.call(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx"
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv('DASHSCOPE_API_KEY'),
model='qwen3-vl-plus',
messages=messages)
print(response.output.choices[0].message.content[0]["text"])Java
import java.io.IOException;
import java.util.*;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import com.alibaba.dashscope.aigc.multimodalconversation.*;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.utils.Constants;
public class Main {
// 若使用新加坡地域的模型,请取消下列注释
// static {Constants.baseHttpApiUrl="https://dashscope-intl.aliyuncs.com/api/v1";}
private static String encodeVideoToBase64(String videoPath) throws IOException {
Path path = Paths.get(videoPath);
byte[] videoBytes = Files.readAllBytes(path);
return Base64.getEncoder().encodeToString(videoBytes);
}
public static void callWithLocalFile(String localPath)
throws ApiException, NoApiKeyException, UploadFileException, IOException {
String base64Video = encodeVideoToBase64(localPath); // Base64编码
MultiModalConversation conv = new MultiModalConversation();
MultiModalMessage userMessage = MultiModalMessage.builder().role(Role.USER.getValue())
.content(Arrays.asList(new HashMap<String, Object>()
{{
put("video", "data:video/mp4;base64," + base64Video);// fps参数控制视频抽帧数量,表示每隔1/fps 秒抽取一帧
put("fps", 2);
}},
new HashMap<String, Object>(){{put("text", "这段视频描绘的是什么景象?");}})).build();
MultiModalConversationParam param = MultiModalConversationParam.builder()
// 若没有配置环境变量,请用百炼API Key将下行替换为:.apiKey("sk-xxx")
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model("qwen3-vl-plus")
.messages(Arrays.asList(userMessage))
.build();
MultiModalConversationResult result = conv.call(param);
System.out.println(result.getOutput().getChoices().get(0).getMessage().getContent().get(0).get("text"));
}
public static void main(String[] args) {
try {
// 将 xxx/test.mp4 替换为你本地图像的绝对路径
callWithLocalFile("xxx/test.mp4");
} catch (ApiException | NoApiKeyException | UploadFileException | IOException e) {
System.out.println(e.getMessage());
}
System.exit(0);
}
}curl
将文件转换为 Base64 编码的字符串的方法可参见示例代码;
为了便于展示,代码中的
"f"data:video/mp4;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAA...",该Base64 编码字符串是截断的。在实际使用中,请务必传入完整的编码字符串。
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3-vl-plus",
"input":{
"messages":[
{
"role": "user",
"content": [
{"video": "data:video/mp4;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAA..."},
{"text": "图中描绘的是什么景象?"}
]
}
]
}
}'图像列表
以保存在本地的football1.jpg、football2.jpg、football3.jpg、football4.jpg为例。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
文件路径传入
传入文件路径仅支持 DashScope Python 和 Java SDK方式调用,不支持 DashScope HTTP 和OpenAI 兼容方式。
Python
import os
from dashscope import MultiModalConversation
import dashscope
# 若使用新加坡地域的模型,请取消下列注释
# dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
local_path1 = "football1.jpg"
local_path2 = "football2.jpg"
local_path3 = "football3.jpg"
local_path4 = "football4.jpg"
image_path1 = f"file://{local_path1}"
image_path2 = f"file://{local_path2}"
image_path3 = f"file://{local_path3}"
image_path4 = f"file://{local_path4}"
messages = [{'role':'user',
# 若模型属于Qwen2.5-VL、Qwen3-VL,且传入图像列表时,可设置fps参数,表示图像列表是由原视频每隔 1/fps 秒抽取的,其他模型设置则不生效
'content': [{'video': [image_path1,image_path2,image_path3,image_path4],"fps":2},
{'text': '这段视频描绘的是什么景象?'}]}]
response = MultiModalConversation.call(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx"
api_key=os.getenv('DASHSCOPE_API_KEY'),
model='qwen3-vl-plus', # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages=messages)
print(response.output.choices[0].message.content[0]["text"])Java
// DashScope SDK版本需要不低于2.18.3
import java.util.Arrays;
import java.util.Map;
import java.util.Collections;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.utils.Constants;
public class Main {
// 若使用新加坡地域的模型,请取消下列注释
// static {Constants.baseHttpApiUrl="https://dashscope-intl.aliyuncs.com/api/v1";}
private static final String MODEL_NAME = "qwen3-vl-plus"; // 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
public static void videoImageListSample(String localPath1, String localPath2, String localPath3, String localPath4)
throws ApiException, NoApiKeyException, UploadFileException {
MultiModalConversation conv = new MultiModalConversation();
String filePath1 = "file://" + localPath1;
String filePath2 = "file://" + localPath2;
String filePath3 = "file://" + localPath3;
String filePath4 = "file://" + localPath4;
Map<String, Object> params = Map.of(
"video", Arrays.asList(filePath1,filePath2,filePath3,filePath4),
// 若模型属于Qwen2.5-VL系列且传入图像列表时,可设置fps参数,表示图像列表是由原视频每隔 1/fps 秒抽取的,其他模型设置则不生效
"fps",2);
MultiModalMessage userMessage = MultiModalMessage.builder()
.role(Role.USER.getValue())
.content(Arrays.asList(params,
Collections.singletonMap("text", "描述这个视频的具体过程")))
.build();
MultiModalConversationParam param = MultiModalConversationParam.builder()
// 新加坡和北京地域的API Key不同。获取API Key:https://www.alibabacloud.com/help/zh/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model(MODEL_NAME)
.messages(Arrays.asList(userMessage)).build();
MultiModalConversationResult result = conv.call(param);
System.out.print(result.getOutput().getChoices().get(0).getMessage().getContent().get(0).get("text"));
}
public static void main(String[] args) {
try {
videoImageListSample(
"xxx/football1.jpg",
"xxx/football2.jpg",
"xxx/football3.jpg",
"xxx/football4.jpg");
} catch (ApiException | NoApiKeyException | UploadFileException e) {
System.out.println(e.getMessage());
}
System.exit(0);
}
}Base64 编码传入
OpenAI兼容
Python
import os
from openai import OpenAI
import base64
# 编码函数: 将本地文件转换为 Base64 编码的字符串
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
base64_image1 = encode_image("football1.jpg")
base64_image2 = encode_image("football2.jpg")
base64_image3 = encode_image("football3.jpg")
base64_image4 = encode_image("football4.jpg")
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-vl-plus", # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages=[
{"role": "user","content": [
{"type": "video","video": [
f"data:image/jpeg;base64,{base64_image1}",
f"data:image/jpeg;base64,{base64_image2}",
f"data:image/jpeg;base64,{base64_image3}",
f"data:image/jpeg;base64,{base64_image4}",]},
{"type": "text","text": "描述这个视频的具体过程"},
]}]
)
print(completion.choices[0].message.content)Node.js
import OpenAI from "openai";
import { readFileSync } from 'fs';
const openai = new OpenAI(
{
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
// 若没有配置环境变量,请用百炼API Key将下行替换为:apiKey: "sk-xxx"
apiKey: process.env.DASHSCOPE_API_KEY,
// 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
baseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1"
}
);
const encodeImage = (imagePath) => {
const imageFile = readFileSync(imagePath);
return imageFile.toString('base64');
};
const base64Image1 = encodeImage("football1.jpg")
const base64Image2 = encodeImage("football2.jpg")
const base64Image3 = encodeImage("football3.jpg")
const base64Image4 = encodeImage("football4.jpg")
async function main() {
const completion = await openai.chat.completions.create({
model: "qwen3-vl-plus", // 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages: [
{"role": "user",
"content": [{"type": "video",
// 需要注意,传入Base64,图像格式(即image/{format})需要与支持的图片列表中的Content Type保持一致。
// PNG图像: data:image/png;base64,${base64Image}
// JPEG图像: data:image/jpeg;base64,${base64Image}
// WEBP图像: data:image/webp;base64,${base64Image}
"video": [
`data:image/jpeg;base64,${base64Image1}`,
`data:image/jpeg;base64,${base64Image2}`,
`data:image/jpeg;base64,${base64Image3}`,
`data:image/jpeg;base64,${base64Image4}`]},
{"type": "text", "text": "这段视频描绘的是什么景象?"}]}]
});
console.log(completion.choices[0].message.content);
}
main();curl
将文件转换为 Base64 编码的字符串的方法可参见示例代码;
为了便于展示,代码中的
"data:image/jpg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAA...",该Base64 编码字符串是截断的。在实际使用中,请务必传入完整的编码字符串。
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下是北京地域base_url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1/chat/completions
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3-vl-plus",
"messages": [{"role": "user",
"content": [{"type": "video",
"video": [
"data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAA...",
"data:image/jpeg;base64,nEpp6jpnP57MoWSyOWwrkXMJhHRCWYeFYb...",
"data:image/jpeg;base64,JHWQnJPc40GwQ7zERAtRMK6iIhnWw4080s...",
"data:image/jpeg;base64,adB6QOU5HP7dAYBBOg/Fb7KIptlbyEOu58..."
]},
{"type": "text",
"text": "描述这个视频的具体过程"}]}]
}'DashScope
Python
import base64
import os
from dashscope import MultiModalConversation
import dashscope
# 若使用新加坡地域的模型,请取消下列注释
# dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
# 编码函数: 将本地文件转换为 Base64 编码的字符串
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
base64_image1 = encode_image("football1.jpg")
base64_image2 = encode_image("football2.jpg")
base64_image3 = encode_image("football3.jpg")
base64_image4 = encode_image("football4.jpg")
messages = [{'role':'user',
'content': [
{'video':
[f"data:image/png;base64,{base64_image1}",
f"data:image/png;base64,{base64_image2}",
f"data:image/png;base64,{base64_image3}",
f"data:image/png;base64,{base64_image4}"
]
},
{'text': '请描绘这个视频的具体过程?'}]}]
response = MultiModalConversation.call(
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
model='qwen3-vl-plus', # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages=messages)
print(response.output.choices[0].message.content[0]["text"])Java
import java.io.IOException;
import java.util.*;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import com.alibaba.dashscope.aigc.multimodalconversation.*;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.utils.Constants;
public class Main {
// 若使用新加坡地域的模型,请取消下列注释
// static {Constants.baseHttpApiUrl="https://dashscope-intl.aliyuncs.com/api/v1";}
private static String encodeImageToBase64(String imagePath) throws IOException {
Path path = Paths.get(imagePath);
byte[] imageBytes = Files.readAllBytes(path);
return Base64.getEncoder().encodeToString(imageBytes);
}
public static void videoImageListSample(String localPath1,String localPath2,String localPath3,String localPath4)
throws ApiException, NoApiKeyException, UploadFileException, IOException {
String base64Image1 = encodeImageToBase64(localPath1); // Base64编码
String base64Image2 = encodeImageToBase64(localPath2);
String base64Image3 = encodeImageToBase64(localPath3);
String base64Image4 = encodeImageToBase64(localPath4);
MultiModalConversation conv = new MultiModalConversation();
Map<String, Object> params = Map.of(
"video", Arrays.asList(
"data:image/jpeg;base64," + base64Image1,
"data:image/jpeg;base64," + base64Image2,
"data:image/jpeg;base64," + base64Image3,
"data:image/jpeg;base64," + base64Image4),
// 若模型属于Qwen2.5-VL系列且传入图像列表时,可设置fps参数,表示图像列表是由原视频每隔 1/fps 秒抽取的,其他模型设置则不生效
"fps",2
);
MultiModalMessage userMessage = MultiModalMessage.builder()
.role(Role.USER.getValue())
.content(Arrays.asList(params,
Collections.singletonMap("text", "描述这个视频的具体过程")))
.build();
MultiModalConversationParam param = MultiModalConversationParam.builder()
// 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.model("qwen3-vl-plus")
.messages(Arrays.asList(userMessage))
.build();
MultiModalConversationResult result = conv.call(param);
System.out.println(result.getOutput().getChoices().get(0).getMessage().getContent().get(0).get("text"));
}
public static void main(String[] args) {
try {
// 将 xxx/football1.png 等替换为你本地图像的绝对路径
videoImageListSample(
"xxx/football1.jpg",
"xxx/football2.jpg",
"xxx/football3.jpg",
"xxx/football4.jpg"
);
} catch (ApiException | NoApiKeyException | UploadFileException | IOException e) {
System.out.println(e.getMessage());
}
System.exit(0);
}
}curl
将文件转换为 Base64 编码的字符串的方法可参见示例代码;
为了便于展示,代码中的
"data:image/jpg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAA...",该Base64 编码字符串是截断的。在实际使用中,请务必传入完整的编码字符串。
# ======= 重要提示 =======
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation
# === 执行时请删除该注释 ===
curl -X POST https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3-vl-plus",
"input": {
"messages": [
{
"role": "user",
"content": [
{
"video": [
"data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAA...",
"data:image/jpeg;base64,nEpp6jpnP57MoWSyOWwrkXMJhHRCWYeFYb...",
"data:image/jpeg;base64,JHWQnJPc40GwQ7zERAtRMK6iIhnWw4080s...",
"data:image/jpeg;base64,adB6QOU5HP7dAYBBOg/Fb7KIptlbyEOu58..."
],
"fps":2
},
{
"text": "描述这个视频的具体过程"
}
]
}
]
}
}'更多用法
使用限制
输入文件限制
图像文件限制
支持的图像格式:
图像格式
常见扩展名
MIME Type
BMP
.bmp
image/bmp
JPEG
.jpe, .jpeg, .jpg
image/jpeg
PNG
.png
image/png
TIFF
.tif, .tiff
image/tiff
WEBP
.webp
image/webp
HEIC
.heic
image/heic
图像大小:单个图像的大小不超过10 MB。如果传入 Base64编码的图像,需保证编码后的字符串小于10MB,详情请参见传入本地文件。如需压缩文件体积请参见图像或视频压缩方法。
尺寸与比例:图像的宽度和高度均需大于 10 像素,图像的宽高比(长边与短边的比值)不得超过 200。
像素总量:对图像的像素总数无严格限制,模型会自动缩放图像。
视频文件限制
视频大小:
公网URL:
Qwen3-VL、qwen-vl-max(包含qwen-vl-max-latest、qwen-vl-max-2025-04-08之后的所有版本):不超过 2GB;
其他Qwen2.5-VL系列及QVQ系列:不超过 1GB;
其他模型不超过 150MB。
Base64编码:经Base64编码后的视频需小于10MB;
本地文件路径:视频本身需小于100MB。
视频时长:
Qwen3-VL、qwen-vl-max、qwen-vl-max-latest、qwen-vl-max-2025-08-13及qwen-vl-max-2025-04-08:2秒至20分钟;
其他Qwen2.5-VL系列及QVQ模型:2秒至10分钟;
其他模型:2秒至40秒。
视频格式: MP4、AVI、MKV、MOV、FLV、WMV 等。
视频尺寸:无特定限制,模型处理前会被调整到约60万像素数,更大尺寸的视频文件不会有更好的理解效果。
音频理解:不支持对视频文件的音频进行理解。
文件输入方式
公网URL:提供一个公网可访问的文件地址,支持 HTTP 或 HTTPS 协议。可将本地文件图像上传至OSS或上传文件获取临时URL,获取公网 URL。
Base64编码传入:将文件转换为 Base64 编码字符串。
本地文件路径传入:直接传入本地文件的路径。
应用于生产环境
图像/视频预处理:通义千问VL 对输入的文件有大小限制,如需压缩文件请参见图像或视频压缩方法。
处理文本文件:通义千问VL仅支持处理图像格式的文件,无法直接处理文本文件。但可使用以下替代方案:
异步与批量处理:对于大规模、非实时的图像或视频处理任务,推荐使用OpenAI兼容-Batch的方式(仅支持部分模型)。此方式以异步方式处理任务,并提供50%的成本折扣。
容错与稳定性
超时处理:在非流式调用中,180秒内模型没有结束输出通常会触发超时报错。为了提升用户体验,超时后响应体中会将已生成的内容返回。如果响应头包含
x-dashscope-partialresponse:true,表示本次响应触发了超时。您可以使用前缀续写功能(部分通义千问VL模型支持),将已生成的内容添加到 messages 数组并再次发出请求,使大模型继续生成内容。详情请参见:基于不完整输出进行续写。重试机制:设计合理的API调用重试逻辑(如指数退避),以应对网络波动或服务瞬时不可用的情况。
计费与限流
限流:通义千问VL模型的限流条件参见限流。
免费额度(仅北京地域):从开通百炼或模型申请通过之日起计算有效期,有效期90天内,通义千问VL模型提供100万Token的免费额度。
计费:
总费用 = 输入 Token 数 x 模型输入单价 + 模型输出 Token 数 x 模型输出单价;输入/输出价格可参见模型列表。
思考模式下,思考过程(
reasoning_content)会作为输出内容的一部分,计入输出 Token 并产生相应费用。若思考模式下未输出思考过程,按照非思考模式价格计费。
查看账单:您可以在阿里云控制台的费用与成本页面查看账单或进行充值。
API参考
关于通义千问VL模型的输入输出参数,请参见通义千问。
常见问题
如何将图像或视频压缩到满足要求的大小?
模型输出物体定位的结果后,如何将检测框绘制到原图上?
错误码
如果模型调用失败并返回报错信息,请参见错误信息进行解决。