
搜索引擎对于检索性能要求比较高,为此系统提供了两阶段排序:基础排序(粗排)和业务排序(精排)。基础排序快速挑选出质量较高的文档,从检索结果中选出TOP N个,再通过精排进行详细评分,最终返回最优结果给用户。基础排序对性能影响大,而业务排序影响最终效果。基础排序应尽量简单有效,仅提取业务排序中的关键因子。两者均通过排序表达式配置。
排序表达式(Ranking Formula)允许用户为应用自定义搜索结果排序方式,通过在查询请求中指定表达式来对结果排序。排序表达式支持基本运算(算术运算、关系运算、逻辑运算、位运算、条件运算)、数学函数和业务排序函数等。Open Search对于几种经典的应用(如论坛、资讯等)提供了相关性实战,用户可根据自己数据的特点,选择合适的表达式模板,并以此为基础进行修改,生成自己的表达式。
在相关性排序(业务排序)前,需了解系统排序策略:通过query等子句找到符合条件的文档后进入排序阶段(具体参见sort子句)。若未指定sort子句或sort子句中明确指定RANK,则会进入相关性评分阶段。
如何设计基础排序和业务排序的表达式要取决于实际搜索场景的需求,最佳实践-功能篇有个《相关性实战》的文章,较详细介绍了在几个典型场景下如何来思考和设计排序因子,大家可以参考。
排序表达式中需使用数值或数值字段类型来进行基本运算操作,如算术、关系、逻辑和条件运算。大部分函数不支持字符串类型参与运算。
基本运算
运算 | 运算符 | 说明 |
一元运算 | - | 负号,功能为对某个表达式的值取负值,如-1, -max(width)。 |
算数运算 | +, -, *, / | 如width / 10 |
关系运算 | ==,!= ,>, <, >=, <= | 如width>=400 |
逻辑运算 | and ,or,! | 如width>=400 and height >= 300, !(a > 1 and b < 2) |
位运算 | &, |,^ | 如 3 & (price ^ pubtime) + (price | pubtime) |
条件运算 | if(cond, thenValue, elseValue) | 如果cond的值非0,则该if表达式的实际值为thenValue,否则为elseValue。如if(2, 3, 5)的值为3,if(0, 3, 5)的值为5。(注意:不支持字符串字段类型,如literal或text类型都不支持;取值范围为int32的取值范围) |
in 运算 | i in [value1, value2, …, valuen] | 如果i的值在集合[value1, value2, …, valuen]中出现,则该表达式值为1,否则为0。例如: 2 in [2, 4, 6]的值为1,3 in [2, 4, 6]的值为0。 |
数学函数
函数 | 说明 |
max(a, b) | 取a和b的最大值。 |
min(a, b) | 取a和b的最小值。 |
ln(a) | 对a取自然对数。 |
log2(a) | 对a取以2为底的对数。 |
log10(a) | 对a取以10为底的对数。 |
sin(a) | 正弦函数。 |
cos(a) | 余弦函数。 |
tan(a) | 正切函数。 |
asin(a) | 反正弦函数 |
acos(a) | 反余弦函数 |
atan(a) | 反正切函数。 |
ceil(a) | 对a向上取整,如ceil(4.2)为5。 |
floor(a) | 对a向下取整,如floor(4.6)为4。 |
sqrt(a) | 对a开方,如sqrt(4)为2。 |
pow(a,b) | 返回a的b次幂,如pow(2, 3)为8。 |
now() | 返回当前时间,自Epoch (00:00:00 UTC, January 1, 1970)开始计算,单位是秒。 |
random() | 返回[0, 1]间的一个随机值。 |
内置特征函数
OpenSearch提供了丰富的基础排序函数,如LBS类、文本类、时效类等,可以用在排序表达式中,相互组合实现强大的相关性排序效果。
Cava插件
Cava是OpenSearch引擎团队基于llvm实现的一门高效的编程语言,它的语法和Java类似,性能与c++相当。Cava是一门面向对象的编程语言,支持即时编译(jit),支持各种安全检查保证程序更加健壮。使用cava和OpenSearch提供的cava库,在OpenSearch中可以定制自己的排序插件,相比于OpenSearch支持的表达式,使用cava实现排序插件具有以下优点:
更强的定制能力:cava提供了较表达式更加丰富的语法功能,比如for循环,函数定义,类定义等,用户可以实现自己的业务需求。
更易于维护:cava实现的排序插件比表达式更具有可读性,更易于维护。
更易于接受:cava的语法和Java类似,熟悉Java的同学很容易使用cava进行开发,学习成本较低。
温馨提示:Cava插件仅支持独享型应用配置。
流程演示
这里以文本相关性排序函数配置为例,演示基础排序和业务排序如何配置:
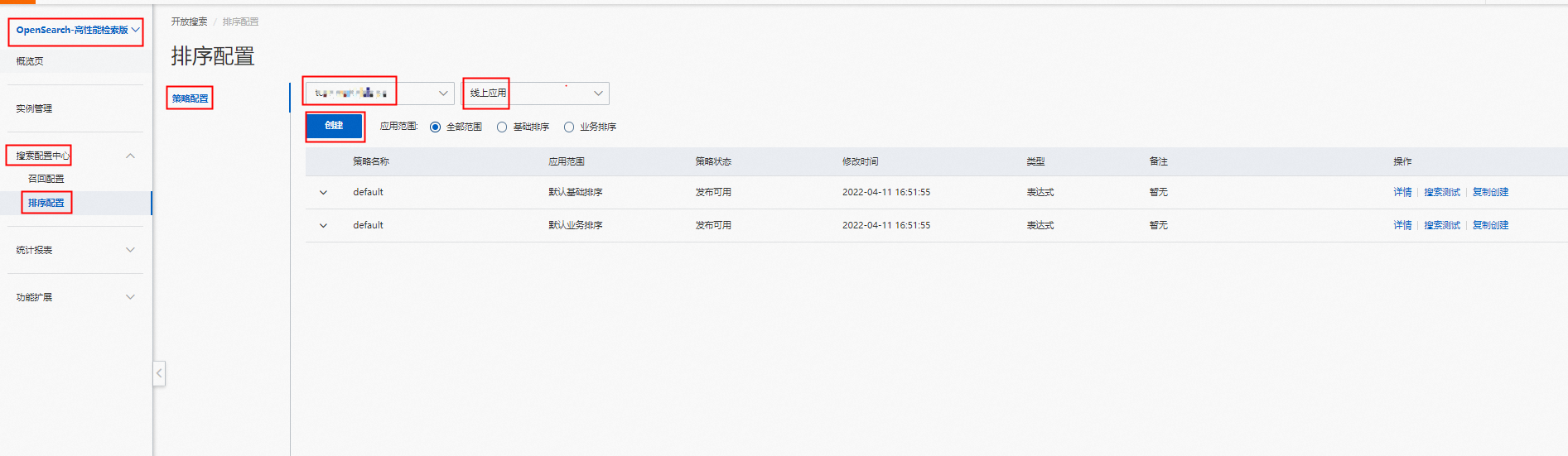
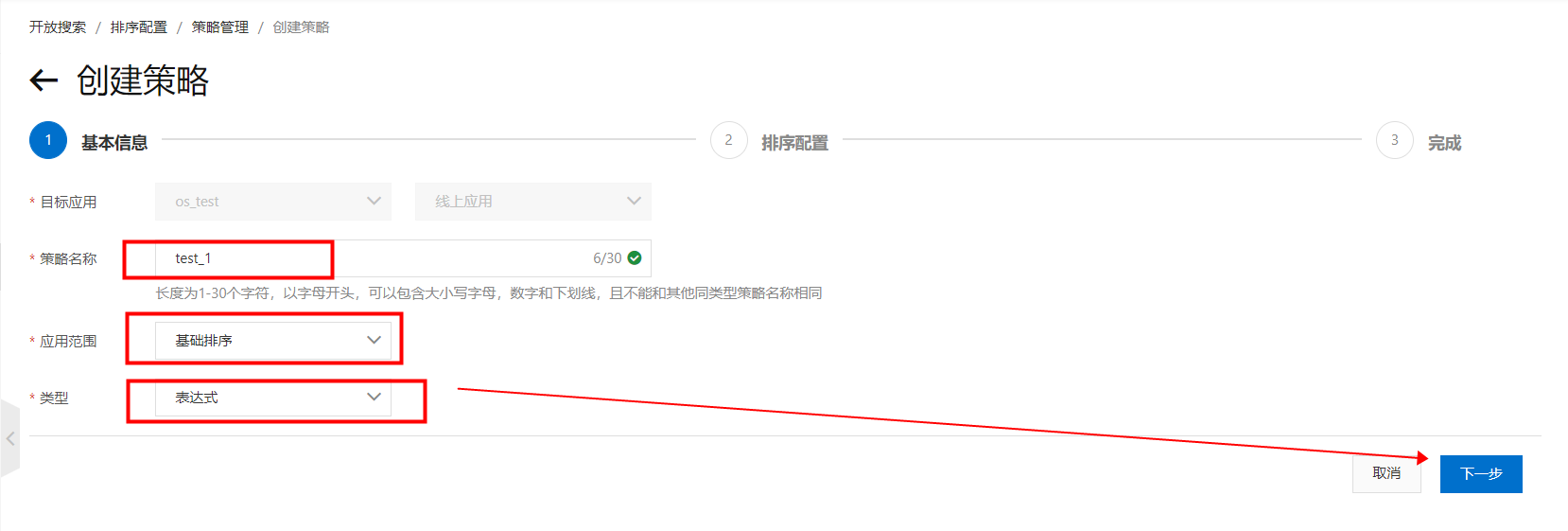
创建基础排序策略,进入“开放搜索控制台”,页面左上角选择OpenSearch-高性能检索版,在搜索配置中心>排序配置>策略管理,单击创建: 填写策略名称,选择应用范围为基础排序,选择类型为表达式,单击下一步:
 选择算分特征为“static_bm25”,设置权重为“10”(注:这里权重为10,就代表该得分在计算的时候*10):
选择算分特征为“static_bm25”,设置权重为“10”(注:这里权重为10,就代表该得分在计算的时候*10):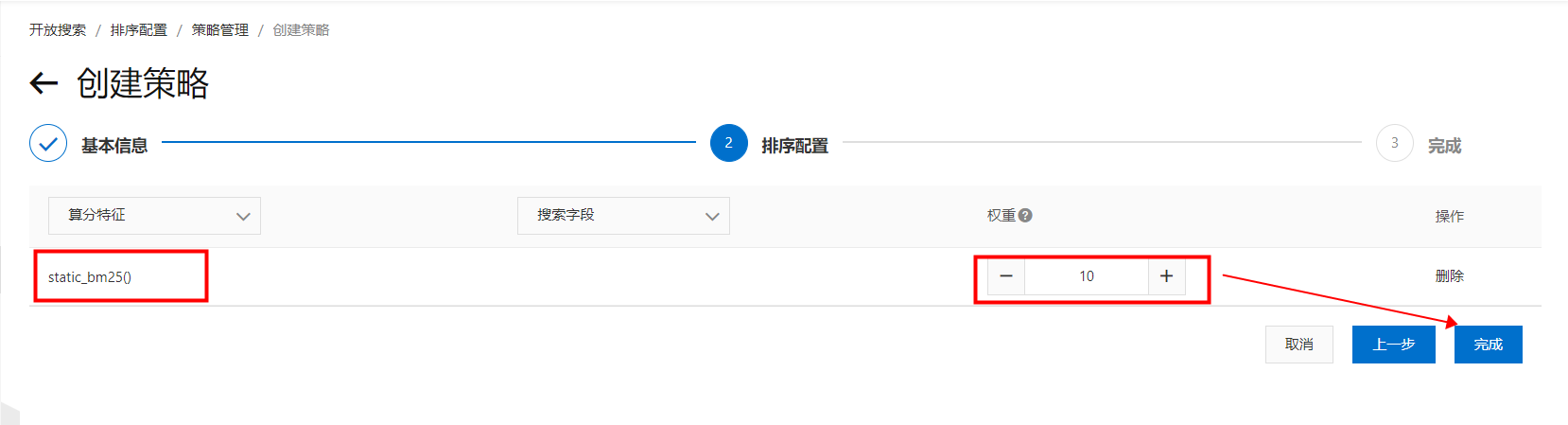 也可以选择搜索字段(字段必须是属性字段,并且只支持数值类型的字段,如:INT、DOUBLE、FLOAT类型),设置权重,则该字段*权重的得分也会加在排序分里:
也可以选择搜索字段(字段必须是属性字段,并且只支持数值类型的字段,如:INT、DOUBLE、FLOAT类型),设置权重,则该字段*权重的得分也会加在排序分里: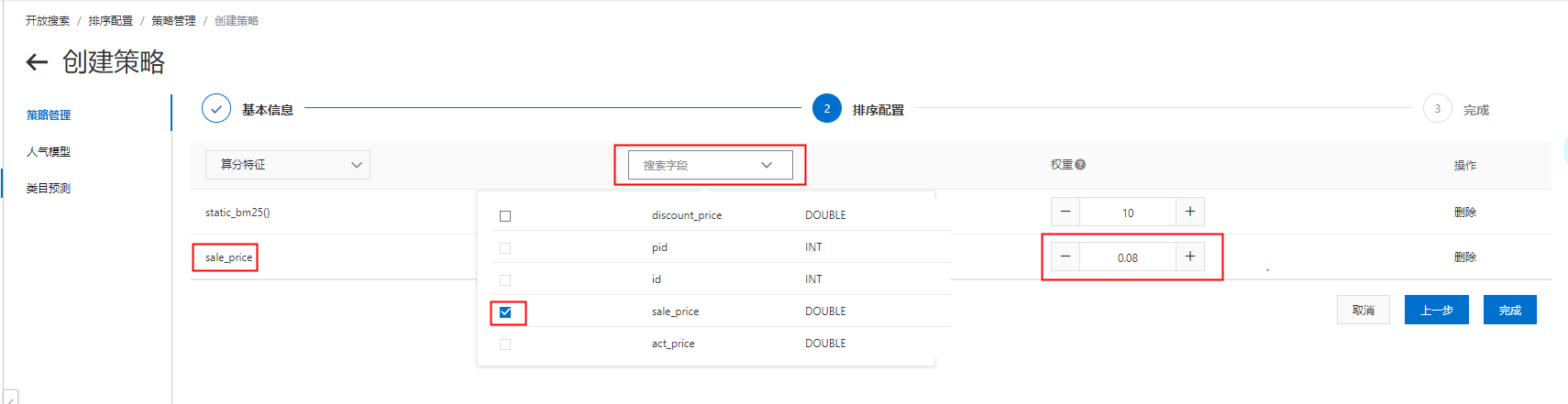
配置完成,返回策略管理页:
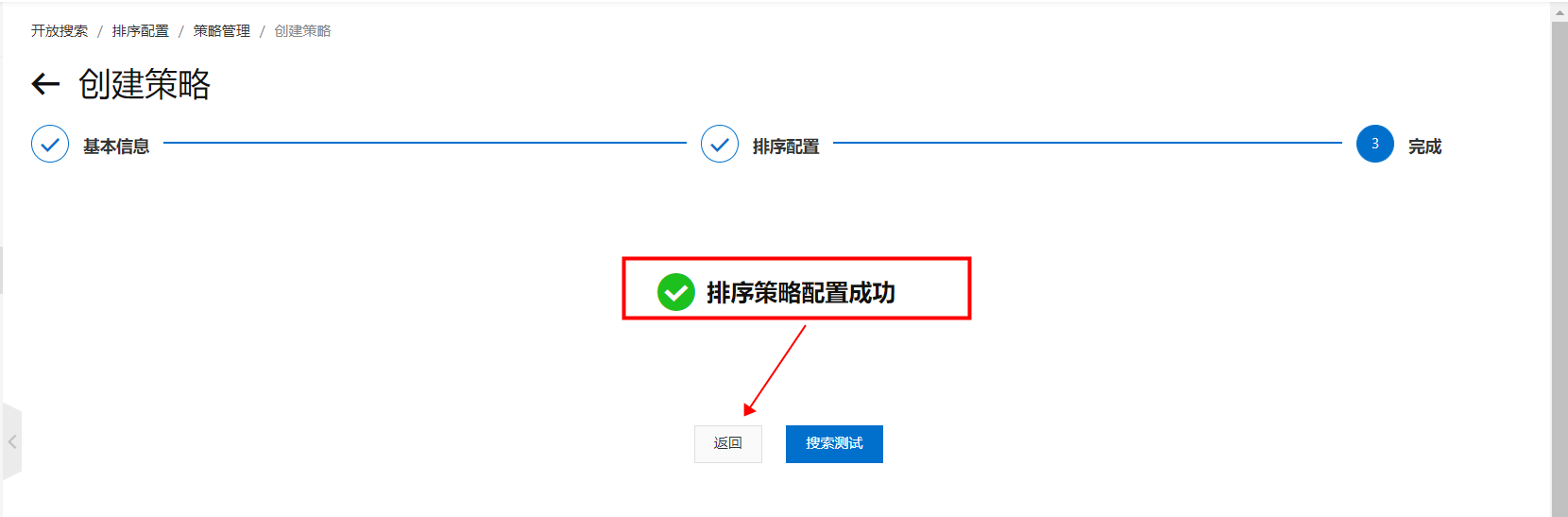
进入开放搜索控制台,单击创建: 填写策略名称,选择应用范围为业务排序,选择类型为表达式,单击下一步:
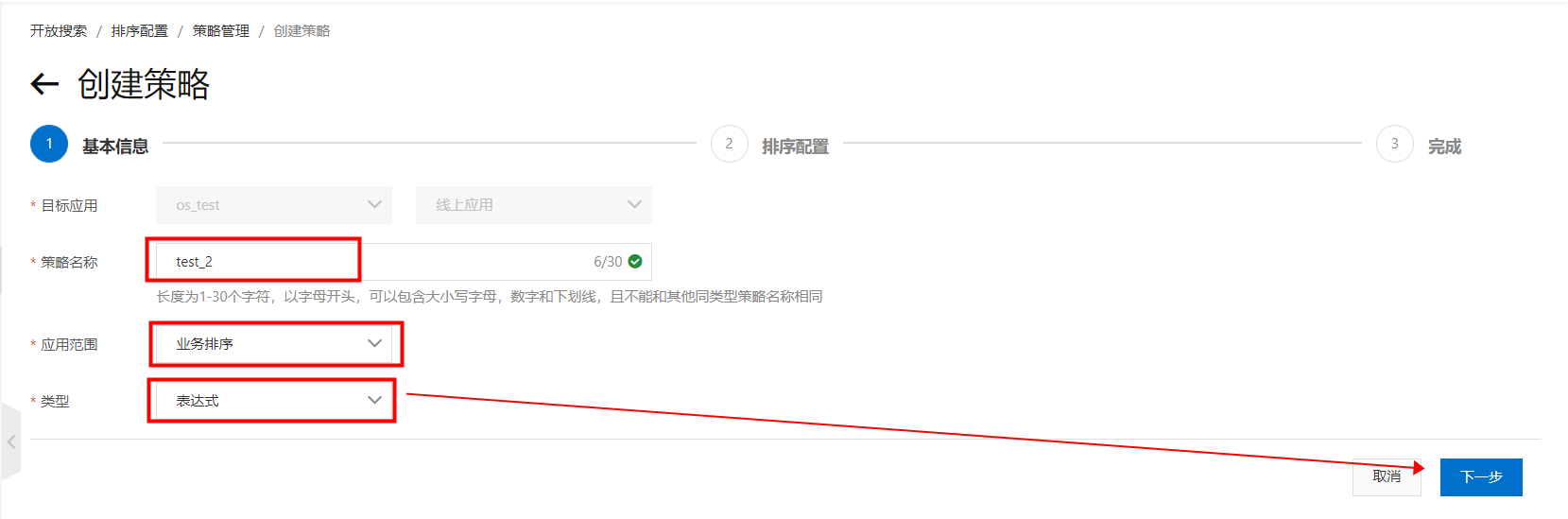 在内置函数里选择“text_relevance”,括号内填入待查询索引里配置的字段名,单击完成:
在内置函数里选择“text_relevance”,括号内填入待查询索引里配置的字段名,单击完成: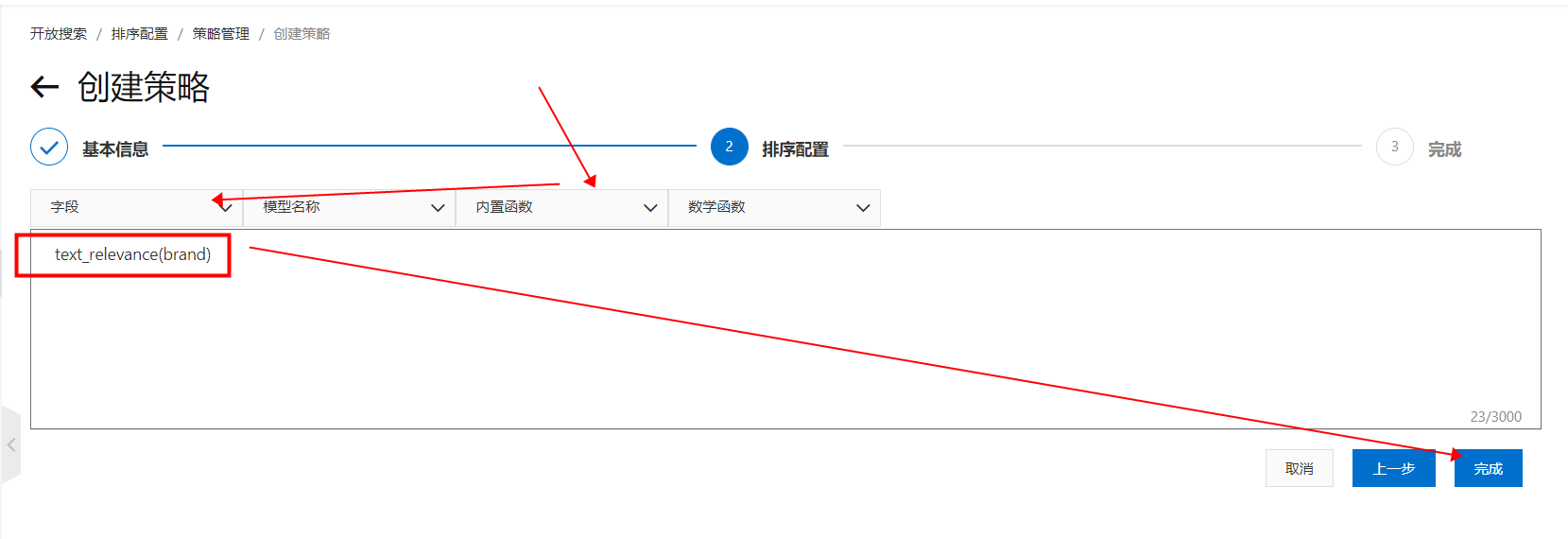 配置完成,返回策略管理页。
配置完成,返回策略管理页。查看排序效果,在搜索测试界面,配置基础和业务排序参数,并打开显示排序明细:
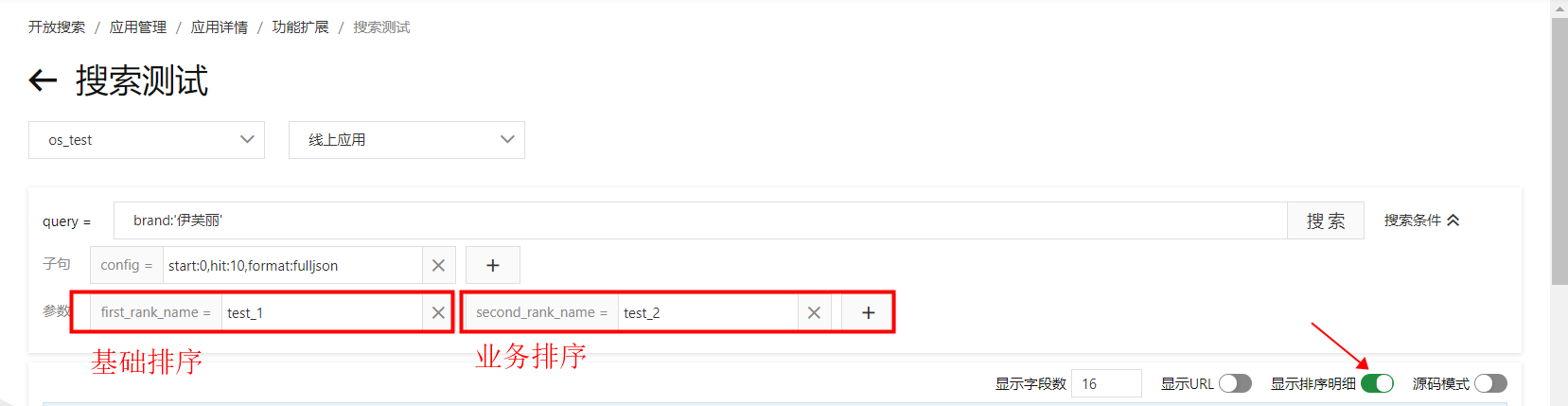 查看各函数算分结果:
查看各函数算分结果: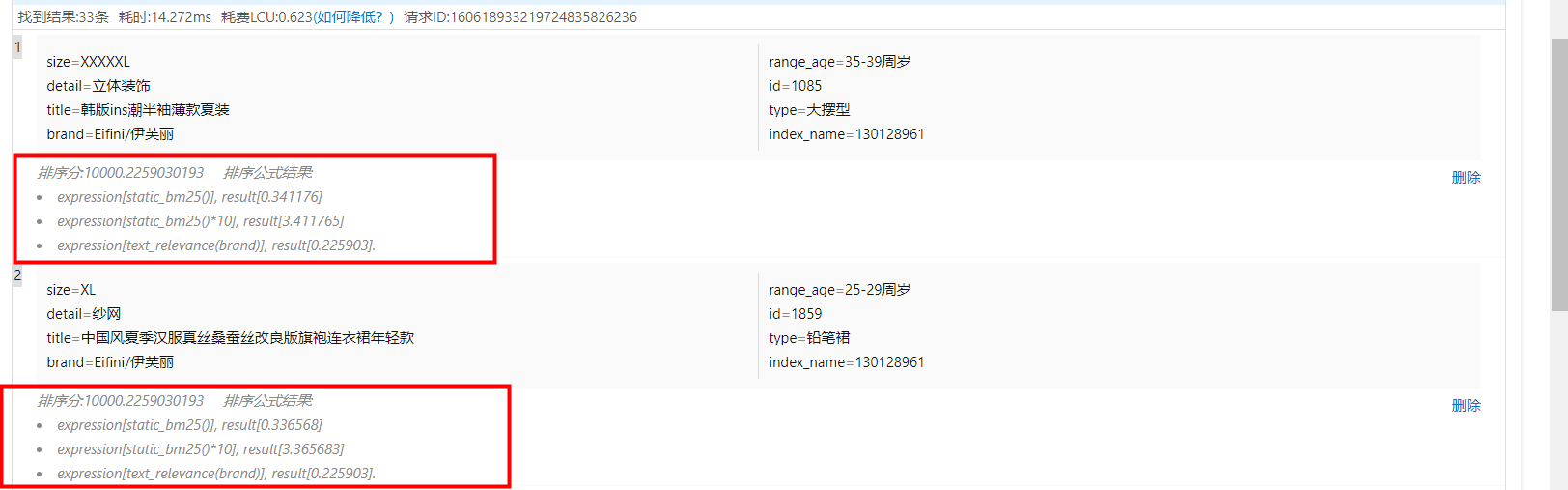 说明
说明文档得分排序分为两个阶段:基础排序和业务排序。通过query召回并filter过滤后的文档先进行基础排序,根据基础排序表达式筛选出得分较高的文档,然后选取TOP N结果再通过业务排序表达式进行精细评分,最终将最佳结果返回给用户。算分逻辑如下:
若只配置了基础排序,则文档得分为(10000+基础排序表达式计算的结果),总分最大为20000,超过20000结果仍为20000。
若只配置了业务排序,则文档得分为(10000+业务排序表达式计算的结果),总分无上限。
若同时配置了基础排序和业务排序,那么进入业务排序的文档最终得分为(10000+业务排序表达式计算的结果),其余文档最终得分为(10000+基础排序表达式计算的结果,总分最大为20000,超过20000结果仍为20000)。
可以创建多个基础排序和业务排序规则,但是查询请求时仅支持同时使用1个基础排序和一个业务排序规则。
重要first_rank_name仅支持填写一个排序表达式名称,不支持多个基础排序表达式同时使用。
second_rank_name仅支持填写一个排序表达式名称,不支持多个业务排序表达式同时使用。
SDK 配置演示
Java SDK 演示:
// 设置粗精排表达式,此处设置为默认
Rank rank =newRank();
rank.setFirstRankName("default");//基础排序策略名称
rank.setSecondRankName("default");//业务排序策略名称
rank.setReRankSize(5);//设置参与精排文档个数PHP SDK 演示:
//指定粗排表达式
$params->setFirstRankName('default');
//指定精排表达式
$params->setSecondRankName('default');注意:
如果在控制台中设置了默认的基础排序和业务排序,而在代码中又重新指定基础排序和业务排序,那么在程序运行时,查询接口以代码中配置的基础排序和业务排序为准。
代码中查看排序明细:
方法:在config子句中添加参数:format:fulljson;
在返回结果中sortExprValues 就是文档得分:
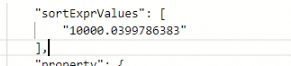
sortExprValues 是个数组,表示sort子句中排序字段的值,例:
sort=-price;-RANK那么sortExprValues 就是[price,文档得分]
如果不设置sort,默认就是文档得分