
简介
TagMatch用于匹配查询请求和文档中的标签,通过匹配结果对文档进行加权。比如查询时优先返回用户点赞过的店铺,可以在查询是请求中传入用户点赞过的店铺和文档中店铺标签进行匹配,匹配成功对文档进行算分加权。TagMatch最基本的功能是在文档的某个ARRAY字段中存储一系列的key-value信息,然后在查询query中通过kvpairs子句传递对应的key-value信息,tag_match就会去文档中寻找查询query中的key, 然后为每个匹配的key计算得到一个分数,再合并所有匹配的key的分数得到一个最终分。这个结果就可以用来做算分加权或者过滤。TagMatch的计算过程如下图所示: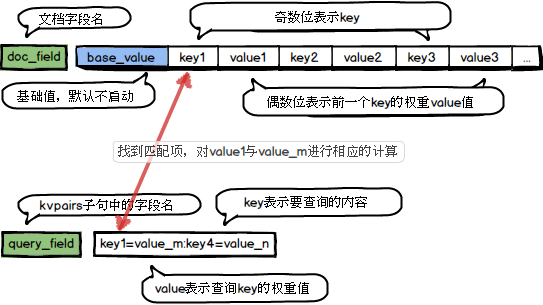
应用场景举例:
函数列表
函数原型 | 函数简介 |
TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, CString kvOperatorName, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv, int maxKvCount) | 创建TagMatch对象,指定文档中字段的详细格式 |
TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, CString kvOperatorName, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv) | 构造TagMatch对象,maxKvCount使用系统默认值 |
TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, CString kvOperatorName, CString mergeOperatorName, boolean hasDefaultValue) | 构造TagMatch对象,文档中字段是kv格式 |
TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, CString kvOperatorName, CString mergeOperatorName) | 构造TagMatch对象,文档中字段没有默认值且是kv格式 |
TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, double kvResult, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv, int maxKvCount) | 构造TagMatch对象,key匹配时结果为常量,并指定文档中字段的详细格式 |
TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, double kvResult, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv) | 构造TagMatch对象,key匹配时结果为常量,并且maxKvCount使用系统默认值 |
TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, double kvResult, CString mergeOperatorName, boolean hasDefaultValue) | 构造TagMatch对象,key匹配时结果为常量,并且文档中字段是kv格式 |
TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, double kvResult, CString mergeOperatorName) | 构造TagMatch对象,key匹配时结果为常量,并且文档中字段没有默认值且是kv格式 |
double evaluate(OpsScoreParams params) | 计算查询词分词词组个数 |
函数详情
TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, CString kvOperatorName, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv, int maxKvCount)
构造TagMatch,并详细指明文档中参与匹配的字段是否有默认值,是否是kv格式,最大的kv个数。
应用场景举例:
一个大型的综合性论坛,帖子可以被打上各种各样的标签(搞笑,体育,新闻,音乐,科普..)。我们在推送给opensearch的文档中,可以为每个标签赋予一个标签id(例如搞笑-1, 体育-5, 新闻-3, 音乐-6..), 然后通过一个tag字段存储这些标签。 如果我们对帖子做过预处理,甚至能得到每个帖子每个标签的权重,例如一个搞笑体育新闻的帖子可以得到搞笑的权重为0.5,体育的权重为0.5,新闻权重为0.1,则这个帖子的tag字段的值为[1 0.5 5 0.5 3 0.1]对会员用户,通过长时间的积累,我们能获知每个用户的兴趣标签。
例如用户nba_fans对体育和搞笑很感兴趣,他对应的体育和搞笑标签的权重分别为0.6和0.3。那么这个用户查询时,我们就可以通过kv_pairs子句把这个信息加到查询请求中。假如这个kv_pairs子句名字为user_tag, 那么nba_fans的user_tag的值5=0.6:1=0.3。这样,我们只要在排序脚本中设置了TagMatch(“user_tag”, “tag”, “mul”, “sum”, false, true, 50), 我们就能够实现对用户感兴趣的帖子加权,把用户更感兴趣的帖子排到前面。
例如nba_fans搜索到上面那个帖子时,搞笑和体育这两个标签能够匹配到。通过指定kvOperatorName参数为”mul”,我们会把查询请求和文档中的值相乘,他们各自的计算分数分别为(体育:0.5 0.6 = 0.3, 搞笑:0.5 0.3 = 0.15)。通过指定mergeOperatorName参数为”sum”,我们会把体育和搞笑的分数加和(0.3+0.15 = 0.45),这个加和的分数会加到最终的排序分数上。这样,我们就能够实现了对这个用户感兴趣帖子的排序加权。
参数列表:
params — 算分输入参数,详情请参考OpsScoreParams手册。
queryKey — 字符串常量,指定查询语句中用于匹配的字段,该字段需要通过kvpairs子句传递,key与value通过英文等号‘=’分隔,多个key-value通过英文冒号‘:’分隔,如:kvpairs=query_tags:10=0.67:960=0.85:1=48//表示参数query_tags中包含3个元素:10、960、1,其对应的value分别是:0.67、0.85、48。其中query也可以只为key的列表,如:kvpairs=cats:10:960:1。fieldName — 字符串常量,指定文档中存储key-value的字段名(必须为属性字段),该字段只支持整型或浮点型数组字段类型(如果是浮点型数组字段类型,则key的值匹配的时强转当int64来处理),数组的奇数位置是key,下一个相邻的偶数位置为key的value,即 [key0 value0 key1 value1 …]。
kvOperatorName — 字符串常量,指定当queryKey中的值与fieldName中的key匹配时对二者的value所采取的操作,目前支持的操作符如下:”max”(最大值)、”min”(最小值)、”sum”(求和)、”avg”(平均数)、”mul”(乘积)、”query_value”(queryKey中该key对应的value值)、”doc_value”(文档中该key对应的value值。
mergeOperatorName — 字符串常量,多个key匹配后会产生多个结果,merge_op指定了将这些结果进行如何操作,目前支持的操作类型如下:”max”(最大值)、”min”(最小值)、”sum”(求和)、”avg”(平均值)、”first_match”(取第一个key匹配时的计算结果,忽略其他结果)。
hasDefaultValue — 布尔型常量,表示fieldName字段的第一个是否为默认值(类似base分值的概念),为false表示不为默认值;为true时说明fieldName字段的第一个值为默认值,字段中数据分布如下:default_score k0 v0 k1 v1…。fieldIsKv — 布尔型常量,表明fieldName字段中的值是以key-value对的形式存在;为false则表示fieldName中只包含key信息,这种场景对doc需要存储标签,但是标签没有权重很方便。
maxKvCount — 整型常量,queryKey中参与匹配的最大kv个数,最大值为5120。
代码示例:
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.framework.OpsRequest;
import com.aliyun.opensearch.cava.framework.OpsDoc;
import com.aliyun.opensearch.cava.features.TagMatch;
class BasicSimilarityScorer {
TagMatch _tagMatch;
boolean init(OpsScorerInitParams params) {
_tagMatch = TagMatch.create(params, "tag_match_key", "multi_int8", "query_value",
"first_match", false, false, 100);
return true;
}
double score(OpsScoreParams params) {
return _tagMatch.evaluate(params);
}
}TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, CString kvOperatorName, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv)
同TagMatch(CString queryKey, CString fieldName, CString kvOperatorName, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv, int maxKvCount),只是其中maxKvCount设置为50。
代码示例:
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.framework.OpsRequest;
import com.aliyun.opensearch.cava.framework.OpsDoc;
import com.aliyun.opensearch.cava.features.TagMatch;
class BasicSimilarityScorer {
TagMatch _tagMatch;
boolean init(OpsScorerInitParams params) {
_tagMatch = TagMatch.create(params, "tag_match_key", "multi_int8", "query_value",
"first_match", false, false);
return true;
}
double score(OpsScoreParams params) {
return _tagMatch.evaluate(params);
}
}TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, CString kvOperatorName, CString mergeOperatorName, boolean hasDefaultValue)
同TagMatch(CString queryKey, CString fieldName, CString kvOperatorName, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv, int maxKvCount),只是其中fieldIsKv设置为true,maxKvCount设置为50。代码示例:
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.framework.OpsRequest;
import com.aliyun.opensearch.cava.framework.OpsDoc;
import com.aliyun.opensearch.cava.features.TagMatch;
class BasicSimilarityScorer {
TagMatch _tagMatch;
boolean init(OpsScorerInitParams params) {
_tagMatch = TagMatch.create(params, "tag_match_key", "multi_int8", "query_value",
"first_match", true);
return true;
}
double score(OpsScoreParams params) {
return _tagMatch.evaluate(params);
}
}TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, CString kvOperatorName, CString mergeOperatorName)
同TagMatch(CString queryKey, CString fieldName, CString kvOperatorName, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv, int maxKvCount),只是其中hasDefaultValue设置为false,fieldIsKv设置为true,maxKvCount设置为50。代码示例:
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.framework.OpsRequest;
import com.aliyun.opensearch.cava.framework.OpsDoc;
import com.aliyun.opensearch.cava.features.TagMatch;
class BasicSimilarityScorer {
TagMatch _tagMatch;
boolean init(OpsScorerInitParams params) {
_tagMatch = TagMatch.create(params, "tag_match_key", "multi_int8", "query_value",
"first_match");
return true;
}
double score(OpsScoreParams params) {
return _tagMatch.evaluate(params);
}
}TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, double kvResult, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv, int maxKvCount)
构造TagMatch,并详细指明文档中参与匹配的字段是否有默认值,是否是kv格式,最大的kv个数。
应用场景举例:
商品可以具有多个属性标签,如1表示年轻人(年龄)、2表示中年人(年龄)、3表示小清新(风格)、4表示时尚(风格)、5表示女性(性别)、6表示男性(性别)等。
假设我们只想表示商品有没有某个标签,不想区分哪个标签更重要。这个标签通过options字段来保存。那么年轻时尚女性的衣服的options字段可以表示为[1 4 5], 注意这里只有标签key,没有value。用户也都有自己的属性标签,和商品标签对应。例如年轻女性用户,历史成交中多购买小清新风格衣服。这该用户的查询可以写为user_options=1:3:5。注意这里kvpair中也是只有标签key,没有value的。
要实现对符合用户标签喜好的商品加权,我们可以在算分脚本中使用TagMatch(“user_options”, “options”, 10F, “sum”, false, false)。这里我们通过user_options和options指定了query和doc的标签信息。kvOperatorName设为常数10,表示只要有标签匹配到,那么匹配的计算结果就是10。hasDefaultValue为false,表示我们不需要初始值。fieldIsKv为false,表示我们doc中只存储了key信息,没有value。
这样,上面的年轻女用户查询到上面的衣服时,女性和年轻两个标签能够匹配上,这两个标签的计算结果都是10。通过”sum”这个merge操作,能够得到这件商品的最终加权分数为20。通过这种方式,即使我们没有标签的权重信息,也能够实现对匹配到的文档做排序加权。
参数列表:
params — 算分输入参数,详情请参考OpsScoreParams手册。
queryKey — 字符串常量,指定查询语句中用于匹配的字段,该字段需要通过kvpairs子句传递,key与value通过英文等号‘=’分隔,多个key-value通过英文冒号‘:’分隔,如:kvpairs=query_tags:10=0.67:960=0.85:1=48//表示参数query_tags中包含3个元素:10、960、1,其对应的value分别是:0.67、0.85、48。其中query也可以只为key的列表,如:kvpairs=cats:10:960:1。fieldName — 字符串常量,指定文档中存储key-value的字段名(必须为属性字段),该字段只支持整型或浮点型数组字段类型(如果是浮点型数组字段类型,则key的值匹配的时强转当int64来处理),数组的奇数位置是key,下一个相邻的偶数位置为key的value,即 [key0 value0 key1 value1 …]。
kvResult — 浮点型常量,当queryKey中的值与fieldName中的key匹配时返回该常量。mergeOperatorName — 字符串常量,多个key匹配后会产生多个结果,merge_op指定了将这些结果进行如何操作,目前支持的操作类型如下:”max”(最大值)、”min”(最小值)、”sum”(求和)、”avg”(平均值)、”first_match”(取第一个kv_op的计算结果,忽略其他结果)。
hasDefaultValue — 布尔型常量,表示fieldName字段的第一个是否为默认值(类似base分值的概念),为false表示不为默认值;为true时说明fieldName字段的第一个值为默认值,字段中数据分布如下:default_score k0 v0 k1 v1…。fieldIsKv — 布尔型常量,表明fieldName字段中的值是以key-value对的形式存在;为false则表示fieldName中只包含key信息,这种场景对doc需要存储标签,但是标签没有权重很方便。
maxKvCount — 整型常量,queryKey中参与匹配的最大kv个数,最大值为5120。
代码示例:
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.framework.OpsRequest;
import com.aliyun.opensearch.cava.framework.OpsDoc;
import com.aliyun.opensearch.cava.features.TagMatch;
class BasicSimilarityScorer {
TagMatch _tagMatch;
boolean init(OpsScorerInitParams params) {
_tagMatch = TagMatch.create(params, "tag_match_key", "multi_int8", 3.3D,
"first_match", false, false, 100);
return true;
}
double score(OpsScoreParams params) {
return _tagMatch.evaluate(params);
}
}TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, double double, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv)
同TagMatch(CString queryKey, CString fieldName, float kvResult, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv, int maxKvCount),只是其中maxKvCount设置为50。代码示例:
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.framework.OpsRequest;
import com.aliyun.opensearch.cava.framework.OpsDoc;
import com.aliyun.opensearch.cava.features.TagMatch;
class BasicSimilarityScorer {
TagMatch _tagMatch;
boolean init(OpsScorerInitParams params) {
_tagMatch = TagMatch.create(params, "tag_match_key", "multi_int8", 3.3D,
"first_match", false, false);
return true;
}
double score(OpsScoreParams params) {
return _tagMatch.evaluate(params);
}
}TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, double kvResult, CString mergeOperatorName, boolean hasDefaultValue)
同TagMatch(CString queryKey, CString fieldName, float kvResult, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv, int maxKvCount),只是其中fieldIsKv设置为true,maxKvCount设置为50。
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.framework.OpsRequest;
import com.aliyun.opensearch.cava.framework.OpsDoc;
import com.aliyun.opensearch.cava.features.TagMatch;
class BasicSimilarityScorer {
TagMatch _tagMatch;
boolean init(OpsScorerInitParams params) {
_tagMatch = TagMatch.create(params, "tag_match_key", "multi_int8", 3.3D,
"first_match", true);
return true;
}
double score(OpsScoreParams params) {
return _tagMatch.evaluate(params);
}
}TagMatch create(OpsScorerInitParams params, CString queryKey, CString fieldName, double kvResult, CString mergeOperatorName)
同TagMatch(CString queryKey, CString fieldName, float kvResult, CString mergeOperatorName, boolean hasDefaultValue, boolean fieldIsKv, int maxKvCount),只是其中hasDefaultValue设置为false,fieldIsKv设置为true,maxKvCount设置为50。代码示例:
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.framework.OpsRequest;
import com.aliyun.opensearch.cava.framework.OpsDoc;
import com.aliyun.opensearch.cava.features.TagMatch;
class BasicSimilarityScorer {
TagMatch _tagMatch;
boolean init(OpsScorerInitParams params) {
_tagMatch = TagMatch.create(params, "tag_match_key", "multi_int8", 3.3D,
"first_match");
return true;
}
double score(OpsScoreParams params) {
return _tagMatch.evaluate(params);
}
}double evaluate(OpsScoreParams params)
匹配查询请求和文档中的标签,通过匹配结果对文档进行加权。参数列表:params — 算分输入参数,详情请参考OpsScoreParams手册。代码示例:
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.framework.OpsRequest;
import com.aliyun.opensearch.cava.framework.OpsDoc;
import com.aliyun.opensearch.cava.features.TagMatch;
class BasicSimilarityScorer {
TagMatch _tagMatch;
boolean init(OpsScorerInitParams params) {
_tagMatch = TagMatch.create(params, "tag_match_key", "multi_int8", "query_value",
"first_match", false, false, 100);
return true;
}
double score(OpsScoreParams params) {
return _tagMatch.evaluate(params);
}
}