
控制台中内置了问答测试页面方便用户进行问答测试,输入问题模型就会匹配到对应的结果进行回答。完成实例配置后,您可针对不同场景和不同期望效果设置相应参数,通过体验问答效果,来选择最优参数。本文以控制台操作为例介绍如何进行问答测试并对可自定义的参数进行说明。
前提条件
已创建OpenSearch-LLM智能版实例,具体请参考:创建LLM智能问答版实例。
已完成数据配置工作,具体请参考:数据配置。
操作步骤
以下操作步骤将以视频文件为例,展示从视频上传到知识库自动解析的完整操作流程,并基于视频内容进行问答测试,最终返回相关结果。
登录OpenSearch控制台选择LLM智能问答版,选择左侧导航栏实例管理,单击对应的实例操作栏下的管理按钮,进入实例详情页面,选择配置中心,进入数据配置,点击文件导入,选择需要上传的文件,单击上传文件导入至知识库。
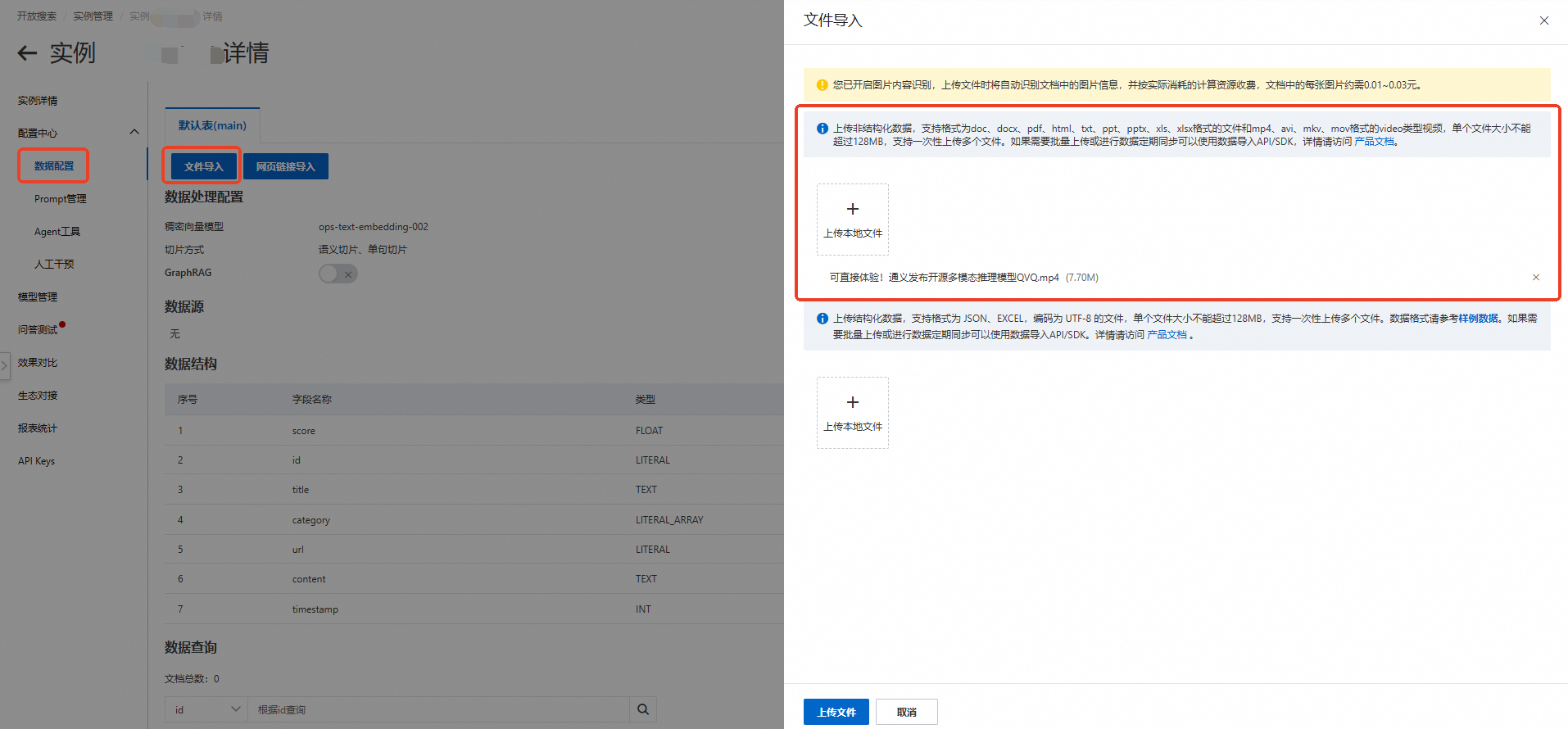
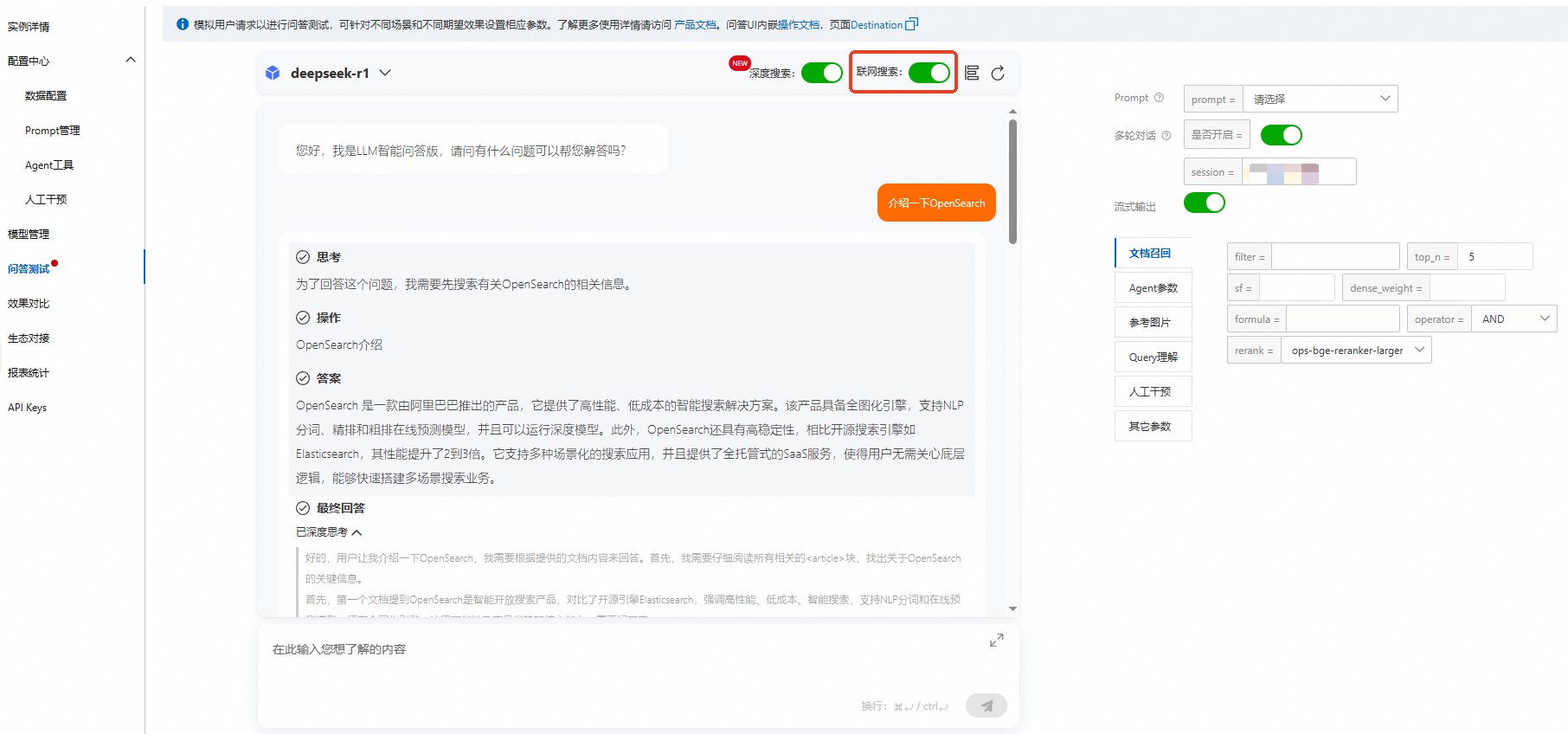
等待文件上传成功,当数据查询状态为完成后,单击左侧导航栏问答测试,即可向模型进行提问。

进入问答测试后,单击右上角模型配置,可根据搜索需求填写对应的问答参数、Prompt参数、文档召回参数、参考图片参数、Query理解参数、人工干预参数及其它参数,然后在对话框输入需要询问的内容,单击发送按钮。
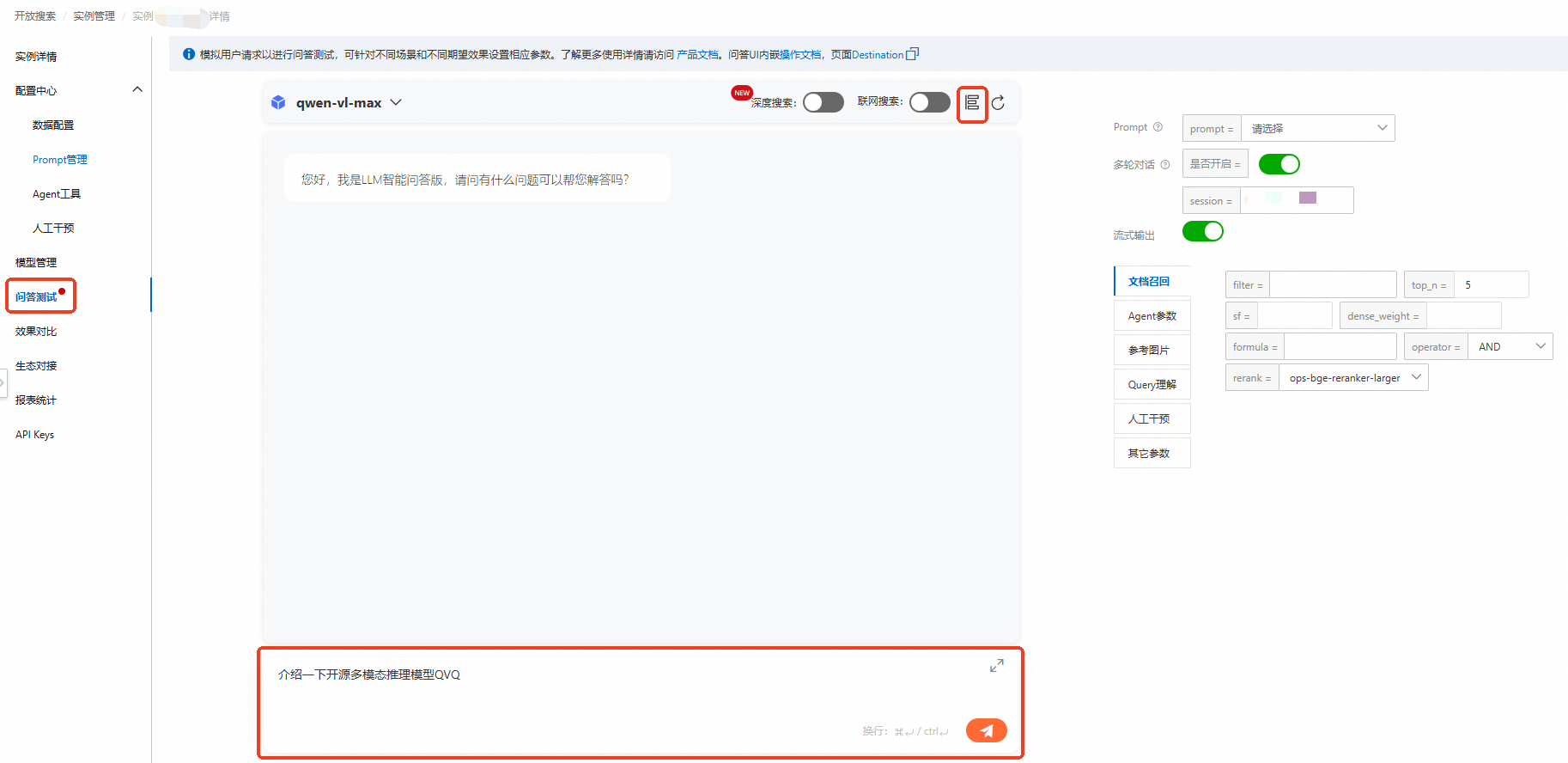
查看问答测试效果,会基于上传的知识库内容返回结果。
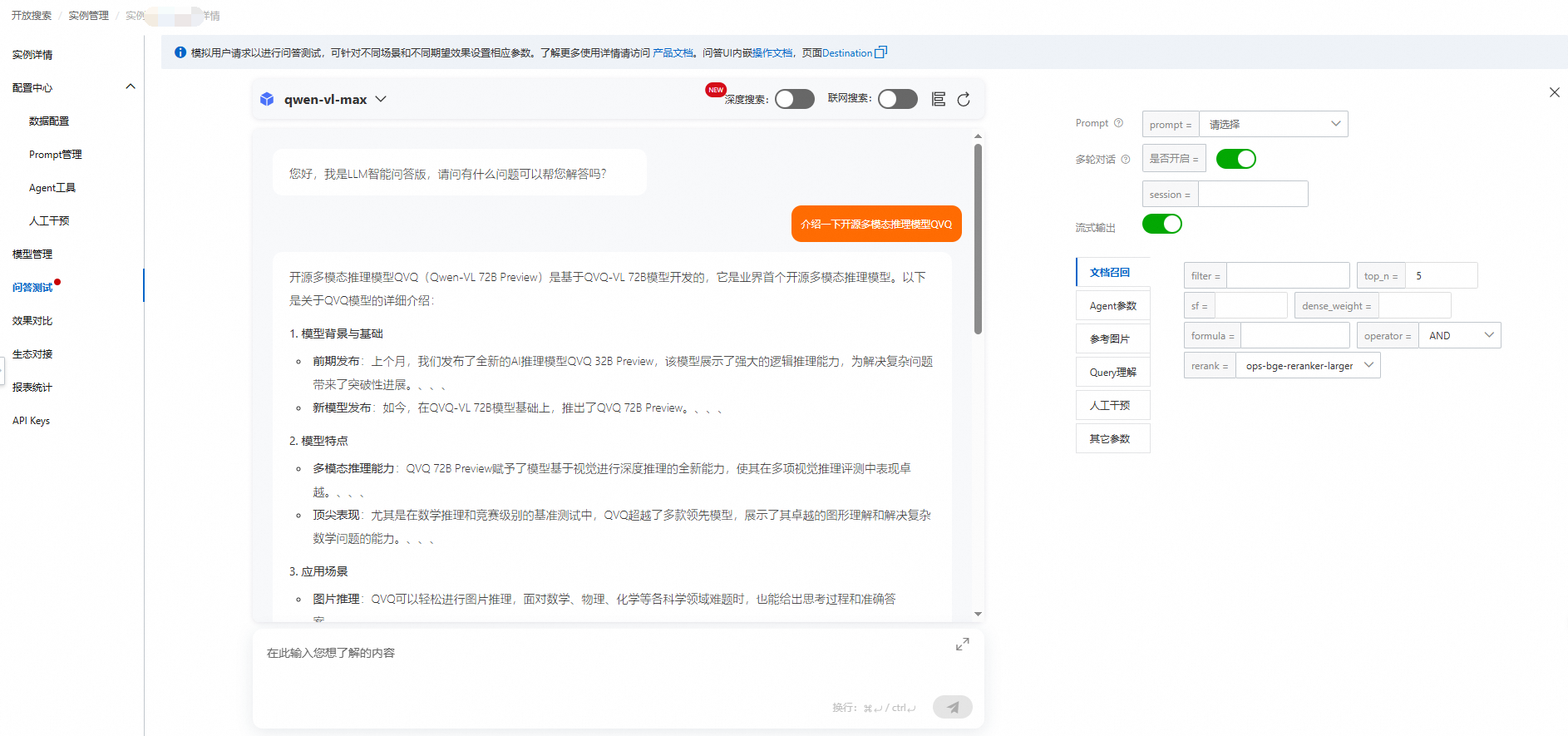
参数说明
问答参数说明 | ||||
参数 | 类型 | 必需 | 默认值 | 描述 |
options.chat.model | String | 是 | opensearch-qwen | 选择的LLM(大语言模型),各个模型在支持的上下文长度以及最大输入、输出Token数有所区别: 上海区域
新加坡区域
|
Prompt | String | 否 | 系统默认模板 | 表示该次搜索使用的Prompt。可选择的Prompt请参考:Prompt管理 |
question.session | Boolean | 否 | true |
|
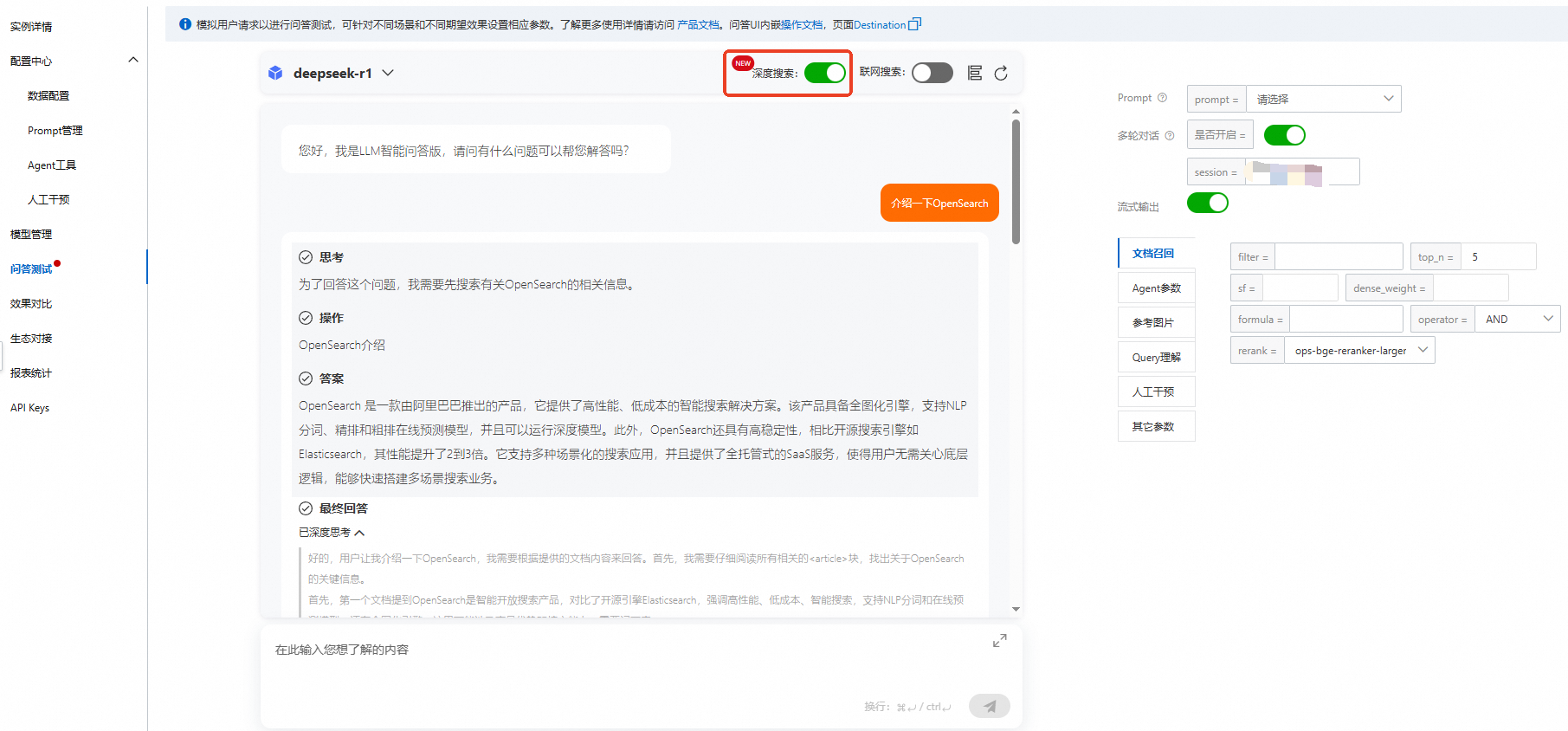
options.chat.enable_deep_search | Boolean | 否 | false | 是否打开深度搜索。
|
options.retrieve.web_search.enable | Boolean | 否 | false | 是否打开全网搜索。
|
options.chat.stream | Boolean | 否 | true | 是否启用流式返回结果。
|
Prompt参数说明 | |||
参数 | 类型 | 必需 | 描述 |
options.chat.prompt_config.attitude | String | 否 |
|
options.chat.prompt_config.rule | String | 否 | 对话内容的详细程度,默认为detailed。
|
options.chat.prompt_config.noanswer | String | 否 | 无法回答问题时的回复,默认为sorry。
|
options.chat.prompt_config.language | String | 否 | 回答问题使用的语言,默认为Chinese
|
options.chat.prompt_config.role | Boolean | 否 | 是否开启回答角色。开启后,将定制回答的角色。 |
options.chat.prompt_config.role_name | String | 否 | 定制回答的角色,例如:AI小助手。 |
options.chat.prompt_config.out_format | String | 否 | 输出内容的形式,默认为text。
|
文档召回参数说明 | |||
参数 | 类型 | 必需 | 描述 |
options.retrieve.doc.filter | String | 否 | 从知识库中召回筛选条件的数据时,需要明确指定相应的字段及满足的条件。默认为空。filter使用示例可参考:filter参数。 支持的字段:
示例格式: |
options.retrieve.doc.top_n | Integer | 否 | 召回的文档数量,默认为5个,取值范围:(0, 50]。 |
options.retrieve.doc.sf | Float | 否 | 控制向量召回的向量分数的阈值。
|
options.retrieve.doc.dense_weight | Float | 开启稀疏向量后,控制文档召回时,稠密向量的权重。取值范围:(0.0, 1.0),默认值为0.7。 | |
options.retrieve.doc.formula | String | 否 | 指定召回时,文档排序的公式。 说明 语法请参考业务排序函数,其中的算法相关性和地理位置相关性的特征不支持。 |
options.retrieve.doc.operator | String | 否 | 在知识库召回时,question.text分词后的term的关系。该参数只有在没有启用稀疏向量时生效。
|
参考图片参数说明 | ||||
参数 | 类型 | 必需 | 默认值 | 描述 |
options.retrieve.image.sf | Float | 否 | 1 | 控制向量召回的向量分数的阈值。
|
options.retrieve.image.dense_weight | Float | 否 | 0.7 | 开启稀疏向量后,控制图片召回时,稠密向量的权重。取值范围:(0.0, 1.0),默认值为0.7。 |
Query理解参数说明 | ||||
参数 | 类型 | 必需 | 取值范围 | 描述 |
options.retrieve.qp.query_extend | Boolean | 否 | - | 是否对用户query进行扩展,扩展query会用来在引擎中召回文档切片。默认为false。
|
options.retrieve.qp.query_extend_num | Integer | 否 | (0,+∞) | 开启相似query扩展时,最多扩展几个query,默认值为5。 |
人工干预参数说明 | |||
参数 | 类型 | 必需 | 描述 |
options.retrieve.entry.sf | Float | 否 | 控制召回人工干预的向量分阈值。取值范围:[0, 2.0],默认值是0.3,该值越小,结果越相关,但结果数量会越少;反之,可能会召回不太相关的结果。 |
其它参数说明 | |||
参数 | 类型 | 必需 | 描述 |
options.retrieve.return_hits | Boolean | 否 | 是否在结果中返回文档召回的结果,即response中的search_hits。 |
options.chat.history_max | Integer | 否 | 多轮对话历史最大轮数,最大20轮,默认是1。 |
options.chat.link | Boolean | 否 | 是否返回链接。控制模型生成的内容是否标识内容引用的来源。取值:
包含内容的返回信息实例如下: 其中被 |
options.chat.rich_text_strategy | String | 否 | 富文本LLM输出后处理方式(如果不存在这个配置或者为空则不开富文本,默认行为):
详情请参见富文本功能。 |
options.retrieve.graph | Boolean | 否 | 根据图关系进行查询联想与召回,需在数据配置中开启GraphRAG后生效。 |
options.chat.enable_llm_knowledge | Boolean | 否 | 开启后,如果搜索无结果,将使用大模型进行兜底回答。 true:打开。 false:关闭。 |