
本文为您介绍在部署和微调大模型时所需显存与哪些因素相关,以及如何估算大模型所需的显存大小。
简易显存估算器
本文根据大模型通用的计算方式,估算大模型部署和微调所需显存,由于不同模型的网络结构和算法存在差异,因此,可能与实际显存占用有差距。
对于MoE模型(混合专家模型),以DeepSeek-R1-671B为例,671B的模型本身参数都需要加载,但在推理时只激活37B的参数,因此在计算激活值所占显存时,需要按照37B的模型参数量计算。
模型微调时通常采用16-bit存储模型参数、激活值、梯度,采用Adam/AdamW优化器,并用32-bit存储优化器状态。
部署
| 场景 | 所需显存(GB) |
|---|---|
| 推理部署(16-bit) | - |
| 推理部署(8-bit) | - |
| 推理部署(4-bit) | - |
微调
| 场景 | 所需显存(GB) |
|---|---|
| 全参微调 | - |
| LoRA微调 | - |
| QLoRA(8-bit)微调 | - |
| QLoRA(4-bit)微调 | - |
模型推理所需显存影响因素
模型推理时所需显存主要由以下部分组成:
模型本身参数
在模型推理时首先需要存储模型本身的参数,其占用的显存计算公式为:参数量 x 参数精度。常用的参数精度有FP32(4字节)、FP16(2字节)、BF16 (2字节)。对于大语言模型,模型参数通常采用FP16或BF16。因此,以参数精度为FP16,参数量为7B的模型为例,其所需显存为:
激活值
在大语言模型推理过程中,需要计算每层神经元的激活值,其占用显存与批量大小、序列长度和模型架构(层数、隐藏层大小)正相关,关系式可以表示为:
其中:
b(batch size):单次请求批量大小,在作为在线服务时通常为1,作为批处理接口时不为1。
s(sequence length):整个序列长度,包括输入输出(token数量)。
h(hidden size):模型隐藏层维度。
L(Layers):模型Transformer层数。
param_bytes:激活值存储的精度,一般为2字节。
结合以上因素和实践经验,为简化显存估算,且留有一定余量,以一个7B模型为例,b为1,s为2048,param_bytes为2字节时,激活值所占显存可以大致按照10%的模型所占显存进行估算,即:
KV缓存
为加速大语言模型的推理效率,通常会缓存每层Transformer已经计算完成的键K(Key)和值V(Value),避免每个时间步重新计算所有历史token的注意力机制参数。引入KV缓存后,其计算量从
其中:
2:表示需要存储K(Key)和V(Value)两个矩阵。
b(batch size):单次请求批量大小,在作为在线服务时通常为1,作为批处理接口时不为1。
s(sequence length):整个序列长度,包括输入输出(token数量)。
h(hidden size):模型隐藏层维度。
L(Layers):模型Transformer层数。
C(Concurrent):服务接口请求的并发度。
param_bytes:激活值存储的精度,一般为2字节 。
结合以上因素和实践经验,为简化显存估算,且留有一定余量,以一个7B模型为例,当C为1,b为1,s为2048,param_bytes为2字节时,KV缓存所占显存也大致按照10%的模型所占显存进行估算,即:
其他
除了以上影响因素外,当前批次的输入数据、CUDA核心、PyTorch/TensorFlow深度学习框架本身等也会占用一些显存,通常为1~2GB。
根据以上因素分析,对于7B的大模型,通常情况下模型推理部署最低需要的显存约为:
模型微调所需显存影响因素
模型微调训练时所需的显存主要由以下部分组成:
模型本身参数
在微调训练时首先需要存储模型本身的参数,其占用的显存计算公式为:参数量 x 参数精度。常用的参数精度有FP32(4字节)、FP16(2字节)、BF16 (2字节),对于大语言模型,在微调时模型参数通常采用FP16或BF16。因此以参数精度为FP16,参数量为7B的模型为例,其所需显存为:
梯度参数
在模型训练的反向传播过程中,需要为模型参数计算梯度,梯度的数量与待训练的参数数量相同。大语言模型中通常采用2字节的精度存储梯度,因此7B的模型根据不同的微调训练方法,所需的显存为:
微调训练方法 | 训练机制 | 适用场景 | 7B模型微调训练梯度所需显存(以1%参数计算、2字节存储) |
全参数微调 | 需要训练的参数与模型本身参数相同 | 算力充足的高精度需求 | 14GB |
LoRA(低秩适配器) | LoRA微调将冻结原始模型参数,仅训练低秩矩阵,其待训练的参数取决于模型结构和低秩矩阵的大小,通常约占模型总参数量的0.1%~1% | 低资源适配特定任务 | 0.14GB |
QLoRA(量化 + LoRA) | 将预训练模型压缩为4-bit或8-bit,使用LoRA微调模型,并引入双重量化与分页优化器,进一步减少显存占用,待训练参数通常约占模型总参数量的0.1%~1% | 超大规模模型微调 | 0.14GB |
优化器状态
在训练过程中还需保存优化器的状态,状态值的数量与待训练参数数量相关,此外,模型通常会采用混合参数精度训练,即模型参数、梯度采用2字节存储,优化器状态采用4字节存储,此做法是为了确保在参数更新过程中保持高精度,避免因FP16/BF16的有限动态范围导致数值不稳定或溢出。同时,如果采用4字节存储状态时,所需的显存将翻倍。常用的优化器情况如下:
优化器类型 | 参数更新机制 | 额外存储需求 (每个待训练参数) | 适用场景 | 7B模型微调训练优化器状态所需显存(4字节存储) | ||
全参数微调 | LoRA微调(以1%参数计算) | QLoRA微调(以1%参数计算) | ||||
SGD | 只用当前梯度 | 0(无额外状态) | 小模型或实验 | 0 | 0 | 0 |
SGD + Momentum | 带动量项 | 1个浮点数(动量) | 稳定性更好 | 28GB | 0.28GB | 0.28GB |
RMSProp | 自适应学习率 | 1个浮点数(二阶矩) | 非凸优化 | 28GB | 0.28GB | 0.28GB |
Adam/AdamW | 动量 + 自适应学习率 | 2个浮点数(一阶+二阶矩) | 大模型常用 | 56GB | 0.56GB | 0.56GB |
激活值
训练时还需存储前向传播过程中产生的中间激活值,以便在反向传播时计算梯度。这部分显存消耗与批量大小 (batch size)、序列长度 (sequence length) 和模型架构(层数、隐藏层大小)正相关,关系式可以表示为:
其中:
b(batch size):批量大小。
s(sequence length):整个序列长度,包括输入输出(token数量)。
h(hidden size):模型隐藏层维度。
L(Layers):模型Transformer层数。
param_bytes:激活值存储的精度一般为2字节。
结合以上因素和实践经验,为简化显存估算,且留有一定余量,以一个7B模型为例,当b为1,s为2048,param_bytes为2字节时,激活值所占显存可以大致按照10%的模型所占显存进行估算,即:
其他
除了以上影响因素外,当前批次的输入数据、CUDA核心、PyTorch/TensorFlow深度学习框架本身等也会占用一些显存,通常为1~2GB。
根据以上因素分析,对于7B的大模型,通常情况下微调训练大约需要的显存为:
微调训练方式 | 模型本身所需显存 | 梯度所需显存 | Adam优化器状态 | 激活值 | 其他 | 总计 |
全参数微调 | 14GB | 14GB | 56GB | 1.4GB | 2GB | 87.4GB |
LoRA(低秩适配器) | 14GB | 0.14GB | 0.56GB | 1.4GB | 2GB | 18.1GB |
QLoRA(8-bit量化 + LoRA) | 7GB | 0.14GB | 0.56GB | 1.4GB | 2GB | 11.1GB |
QLoRA(4-bit量化 + LoRA) | 3.5GB | 0.14GB | 0.56GB | 1.4GB | 2GB | 7.6GB |
大模型通常采用Adam/AdamW优化器。
表中除了QLoRA模型本身采用4-bit或8-bit存储,优化器状态采用32-bit(4字节)存储外,其余参数都采用16-bit(2字节)存储。
常见问题
Q:如何查看大模型参数量?
对于开源大模型,其参数量通常会标注在模型名称上,如:Qwen-7B,其参数量为
Q:如何查看大模型的参数的精度?
如果未加特别说明,大模型通常采用16-bit(2字节)存储。对于量化的模型,其可能采用8-bit/4-bit存储,详细情况您可以查看其说明文档,例如,如果您使用PAI Model Gallery中的模型,其详情页通常会介绍参数的精度:
通义千问2.5-7B-Instruct训练说明:

Q:如何查看大模型微调训练使用的优化器及状态精度?
大模型训练通常采用Adam/AdamW优化器,参数精度为32-bit(4字节),更详细的配置需要查看启动命令或者代码。
Q:如何查看显存占用?
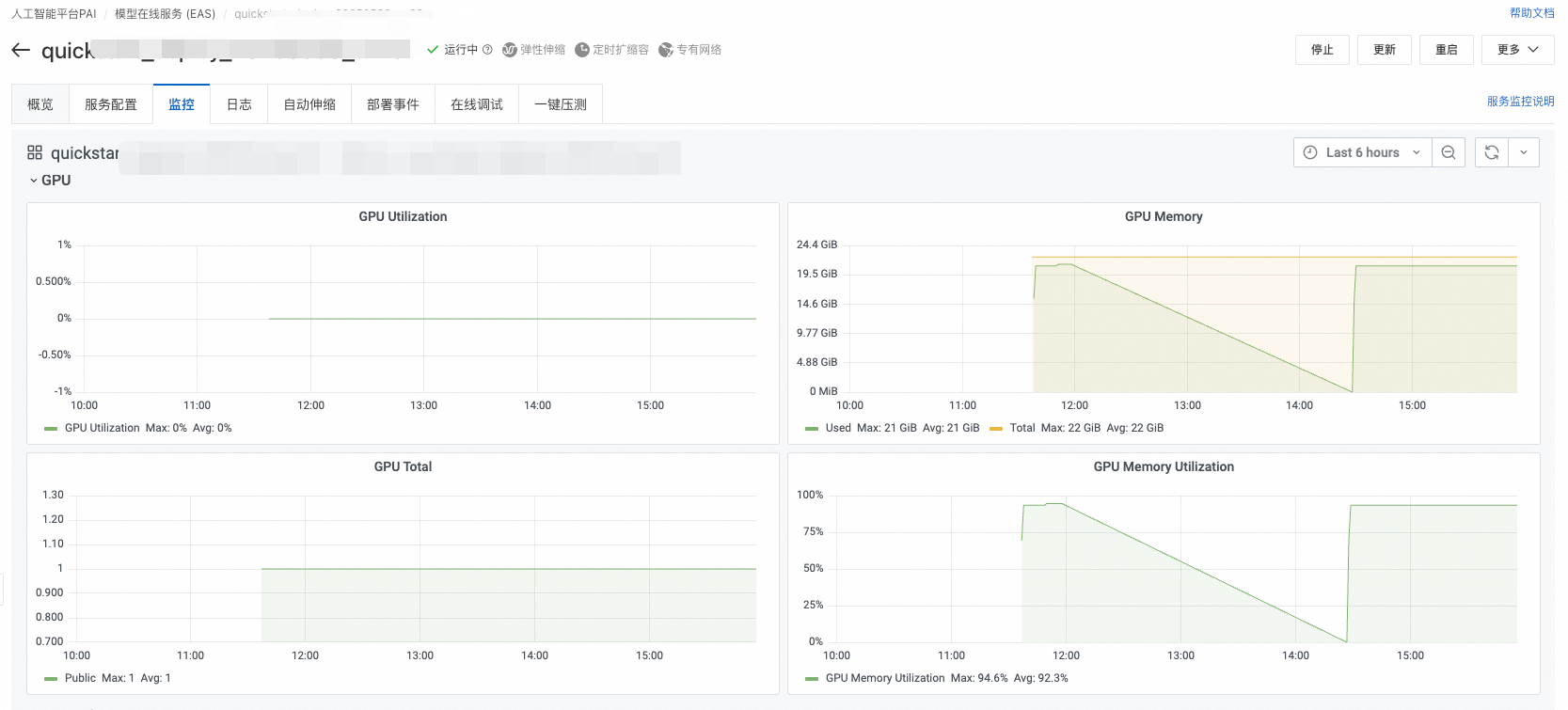
您可以通过PAI-DSW、PAI-EAS、PAI-DLC的图形监控页面查看显存占用情况:
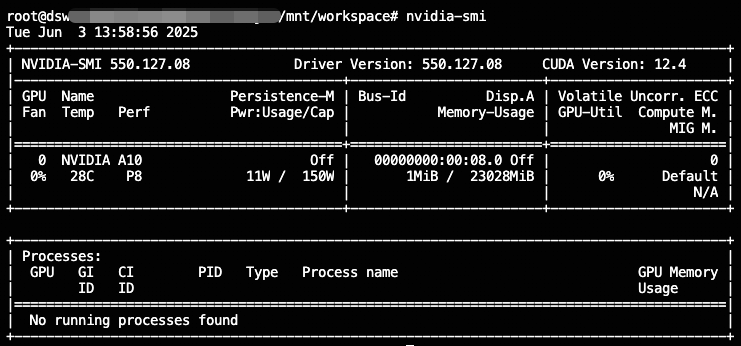
或者在容器的终端中执行nvidia-smi查看GPU使用情况:
Q:显存不足的常见报错有哪些?
使用NVIDIA GPU显存不足时会报CUDA out of memory. Tried to allocate X GB的错误,此时您需要增大显存,或者缩小批量大小(batch size)、序列长度等。