
DLC可以快捷地创建分布式或单机训练任务。其底层基于Kubernetes,省去您手动购买机器并配置运行环境,无需改变使用习惯即可快速使用。本文以 MNIST 手写体识别为例,介绍如何使用DLC进行单机单卡训练,或多机多卡的分布式训练。
MNIST手写体识别是深度学习最经典的入门任务之一,任务目标是通过构建机器学习模型,来识别10个手写数字(0~9)。

前提条件
使用主账号开通PAI并创建工作空间。登录PAI控制台,左上角选择开通区域,然后一键授权和开通产品。
计费说明
本文案例将使用公共资源创建DLC任务,计费方式为按量付费,详细计费规则请参见分布式训练(DLC)计费说明。
单机单卡训练
创建数据集
数据集用于存储模型训练的代码、数据、以及训练结果。本文以对象存储OSS类型数据集为例进行说明。
在PAI控制台左侧菜单栏单击数据集 > 自定义数据集 > 新建数据集。
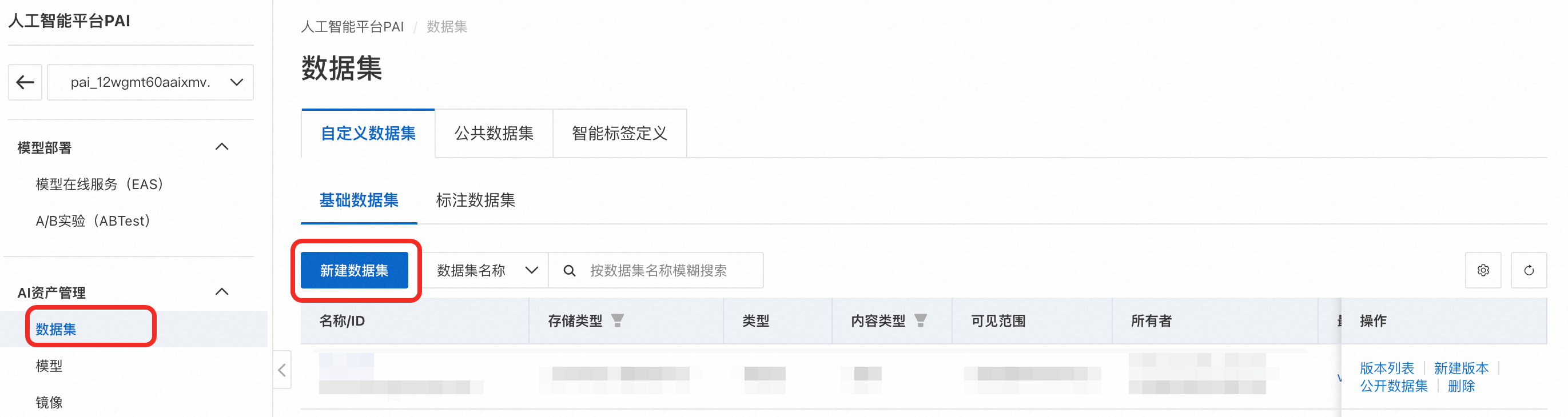
配置数据集参数。关键参数配置如下,其他参数默认即可。
名称:如:
dataset_mnist存储类型:对象存储(OSS)
OSS路径:单击图标
 ,选择bucket并新建目录如:
,选择bucket并新建目录如:dlc_mnist。如果您尚未开通OSS,或在当前地域下没有可选的Bucket,可参考如下步骤开通OSS,并新建Bucket:
单击确定创建数据集。
上传训练代码和数据。
下载代码。本文已经为您准备好了训练代码,单击mnist_train.py下载。为减少您的操作,代码运行时会自动将训练数据下载到数据集的dataSet目录中。
您在后续实际业务使用时,可以预先把代码和训练数据上传到PAI的数据集中。
上传代码。在数据集详情页,单击查看数据跳转至OSS控制台。然后单击上传文件 >扫描文件 > 上传文件,将训练代码上传至OSS中。
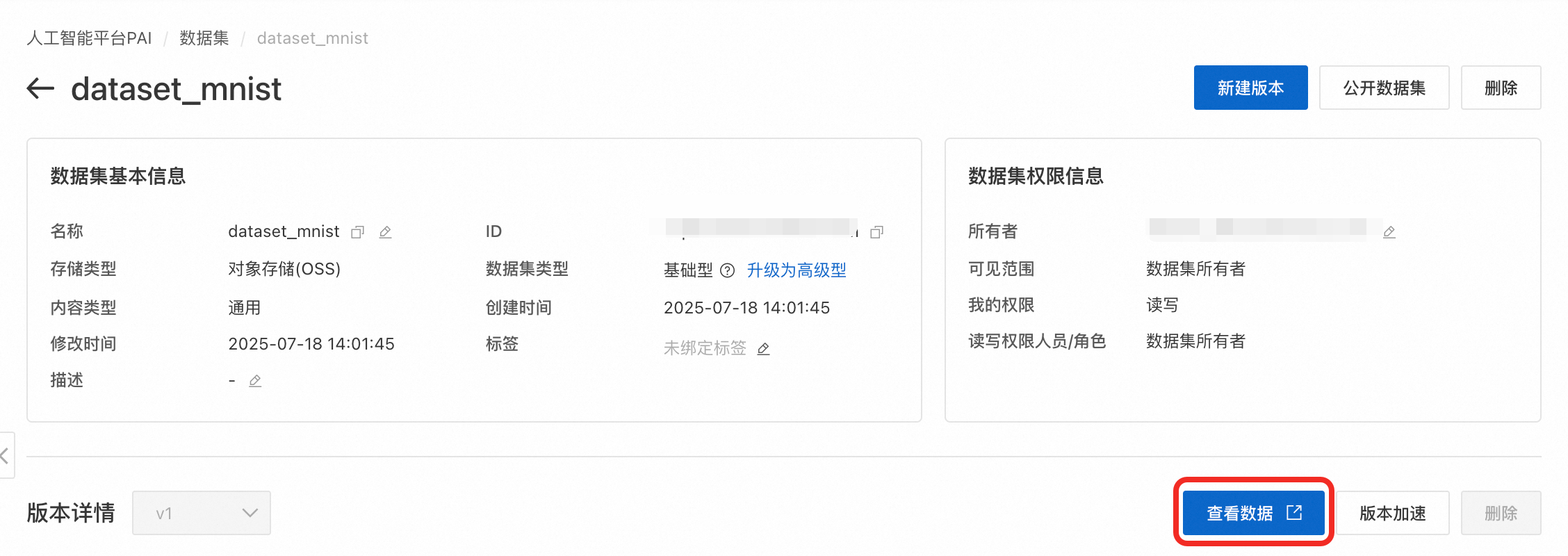
创建DLC任务
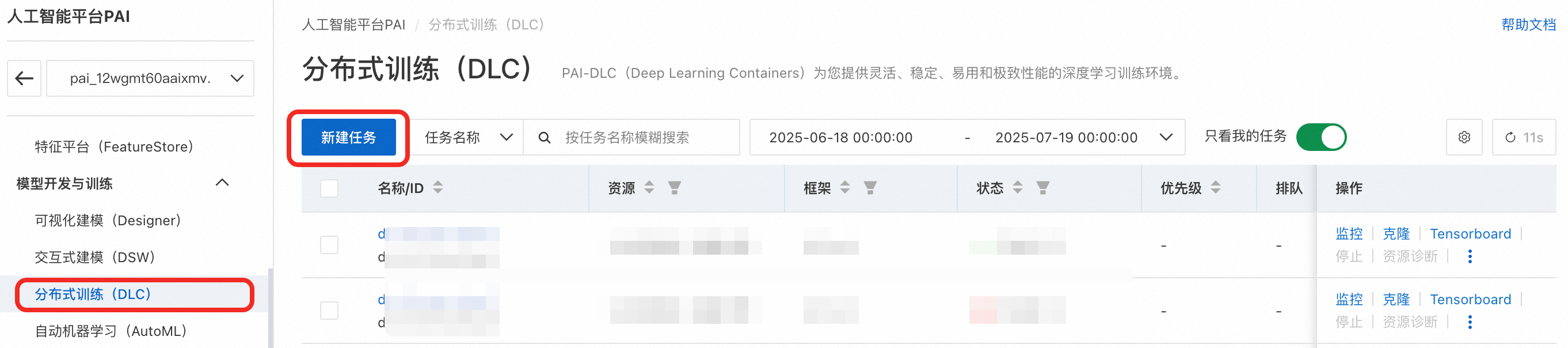
在PAI控制台左侧菜单栏单击分布式训练(DLC) > 新建任务。

配置DLC任务参数。关键参数配置如下,其他参数默认即可。全量参数请参见创建训练任务。
镜像配置:选择镜像地址,然后根据您所在地域填写对应镜像地址。
地域
对应镜像地址
北京
dsw-registry-vpc.cn-beijing.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
上海
dsw-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
杭州
dsw-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
其他
查询地域ID,并替换镜像地址中的<地域ID>获取完整链接:
dsw-registry-vpc.<地域ID>.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
该镜像已在交互式建模 DSW 快速入门中验证没有环境问题。使用PAI建模时,通常先在DSW中验证环境、开发代码,然后再使用DLC训练。
数据集挂载:选择自定义数据集,选择上一步中创建的数据集。挂载路径默认
/mnt/data。启动命令:
python /mnt/data/mnist_train.py该启动命令与在DSW或本地运行时相同。但由于
mnist_train.py现已挂载至/mnt/data/,因此仅需要修改代码的路径为/mnt/data/mnist_train.py。资源来源:选择公共资源,资源规格选择
ecs.gn7i-c8g1.2xlarge即可。如果该规格实例库存不足,您也可以选择其他GPU实例。
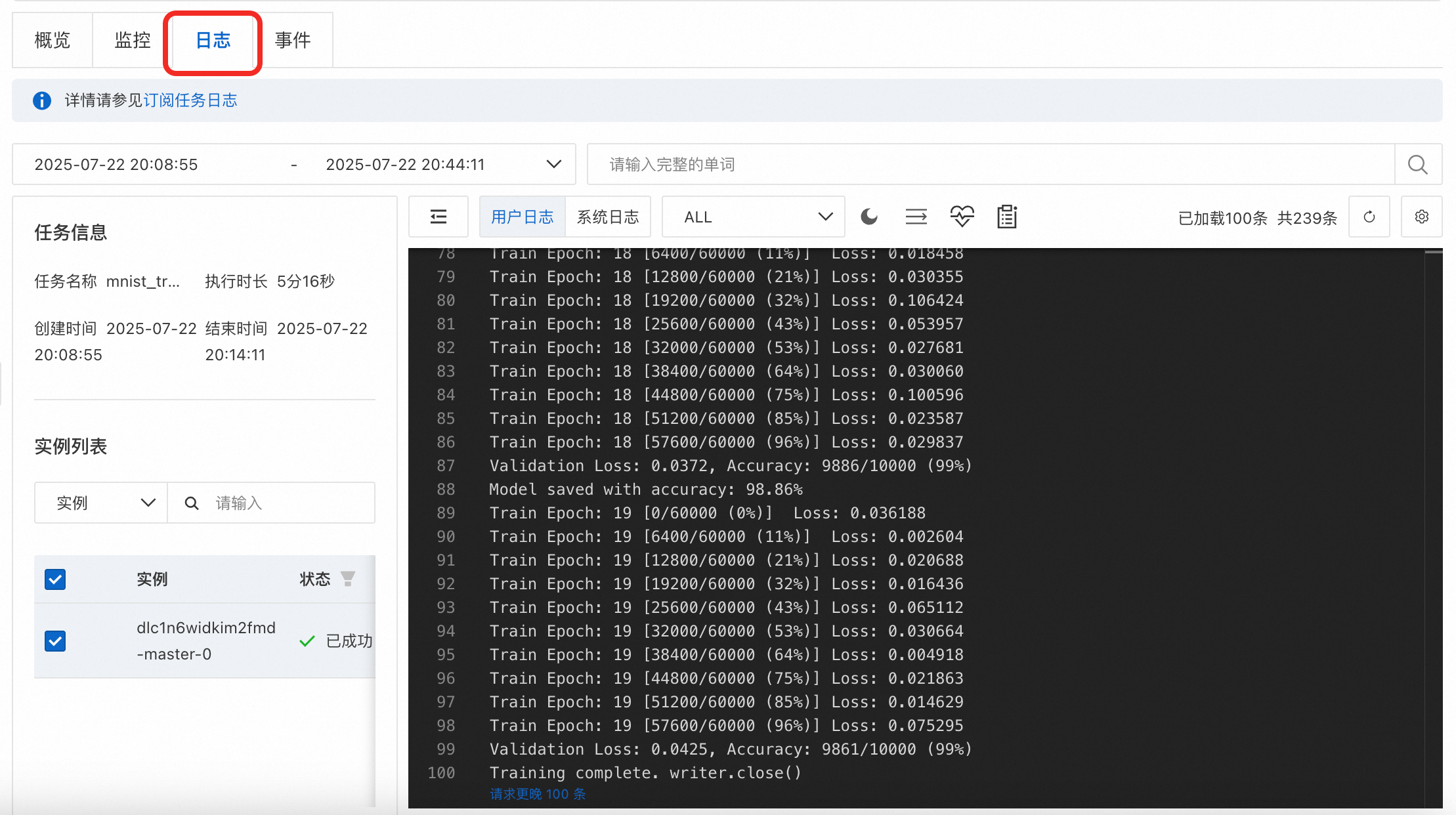
单击确定创建任务,任务大约需要执行15分钟。执行过程中可以单击日志查看训练过程。
执行完成后,会在挂载数据集的
output路径下输出最佳的模型检查点,以及TensorBoard日志。

查看Tensorboard(可选)
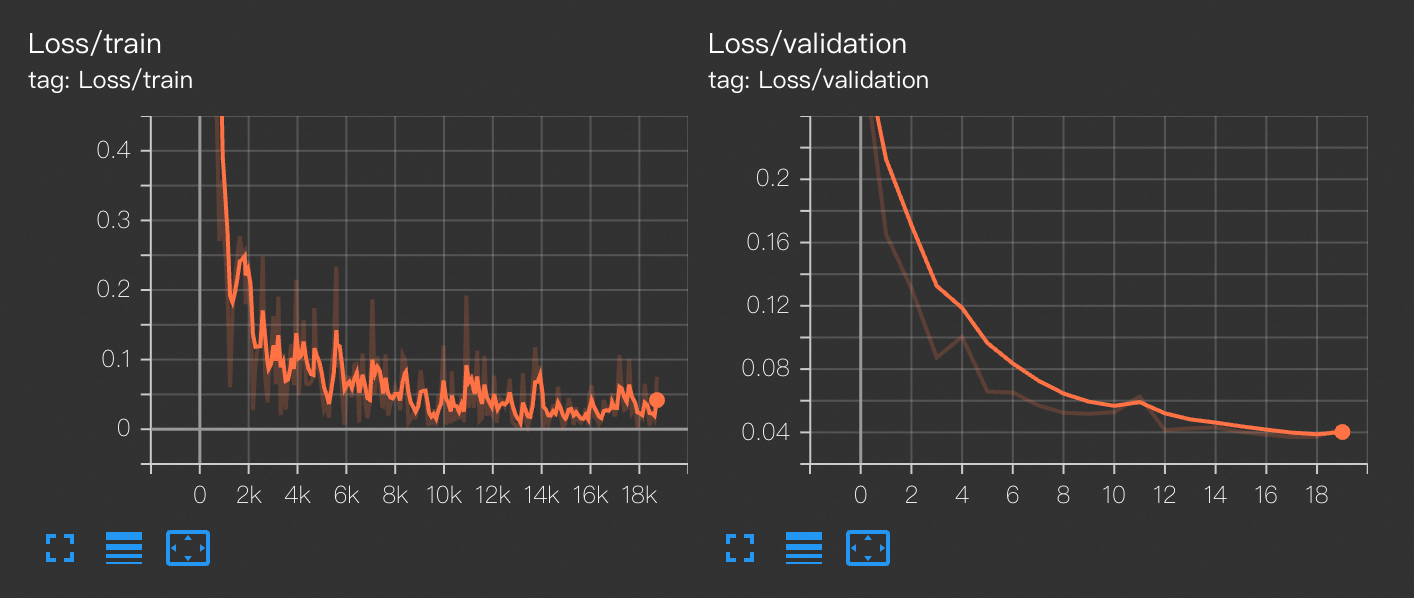
您可以借助可视化工具TensorBoard查看loss曲线,了解训练的具体情况。
DLC任务如果想使用TensorBoard,必须配置数据集。
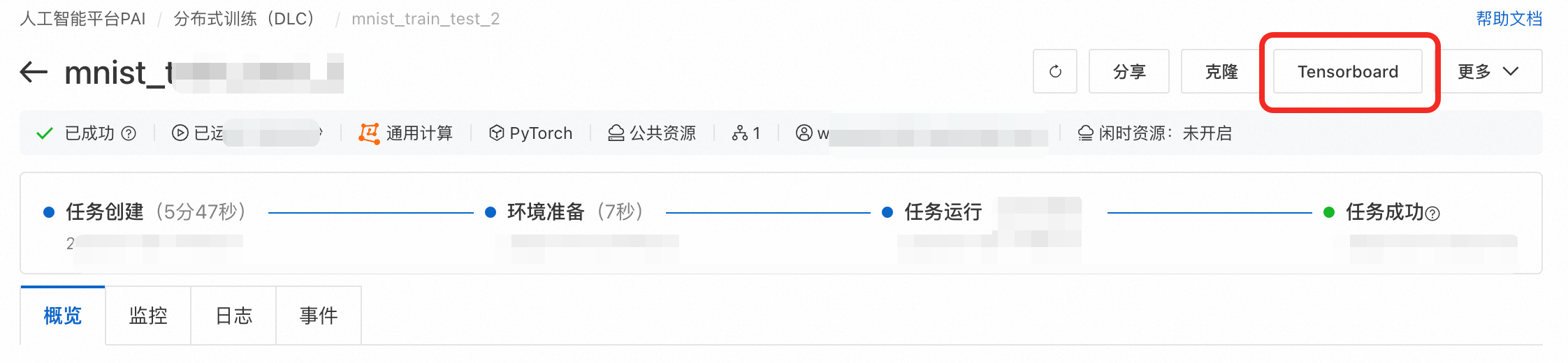
单击DLC任务详情页上方的Tensorboard > 新建Tensorboard。
配置类型选择按任务,在Summary目录处填写训练代码中Summary存储的路径:
/mnt/data/output/runs/,单击确定启动。对应代码片段:
writer = SummaryWriter('/mnt/data/output/runs/mnist_experiment')单击查看Tensorboard查看train_loss曲线(反映训练集损失)与 validation_loss曲线(反映验证集损失)。
部署训练后的模型
详情请参见使用EAS将模型部署为在线服务。
单机多卡或多机多卡分布式训练
当单个GPU的显存无法满足训练需求,或者想要加快训练速度时,您可以创建单机多卡或多机多卡的分布式训练任务。
本文以使用2台各有1个GPU的实例为例进行说明,该示例同样适用于其他配置的单机多卡或多机多卡训练。
创建数据集
如果您在单机单卡训练时已经创建了数据集,只需单击下载代码mnist_train_distributed.py并上传。否则请先创建数据集,再上传该代码。
创建DLC任务
在PAI控制台左侧菜单栏单击分布式训练(DLC) > 新建任务。
配置DLC任务参数。关键参数配置如下,其他参数默认即可。全量参数请参见创建训练任务。
镜像配置:选择镜像地址,然后根据您所在地域填写对应镜像地址。
地域
镜像地址
北京
dsw-registry-vpc.cn-beijing.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
上海
dsw-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
杭州
dsw-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
其他
查询地域ID,并替换镜像地址中的<地域ID>获取完整链接:
dsw-registry-vpc.<地域ID>.cr.aliyuncs.com/pai/modelscope:1.28.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
该镜像已在交互式建模 DSW 快速入门中验证没有环境问题。使用PAI建模时,通常先在DSW中验证环境及代码,然后再使用DLC训练。
数据集挂载:选择自定义数据集,并选择上一步中创建的数据集。挂载路径默认
/mnt/data。启动命令:
torchrun --nproc_per_node=1 --nnodes=${WORLD_SIZE} --node_rank=${RANK} --master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} /mnt/data/mnist_train_distributed.pyDLC会自动注入
MASTER_ADDR、WORLD_SIZE等通用环境变量,通过$环境变量名来获取。资源来源:选择公共资源,节点数量为2,资源规格选择
ecs.gn7i-c8g1.2xlarge。如果该规格实例库存不足,您也可以选择其他GPU实例。
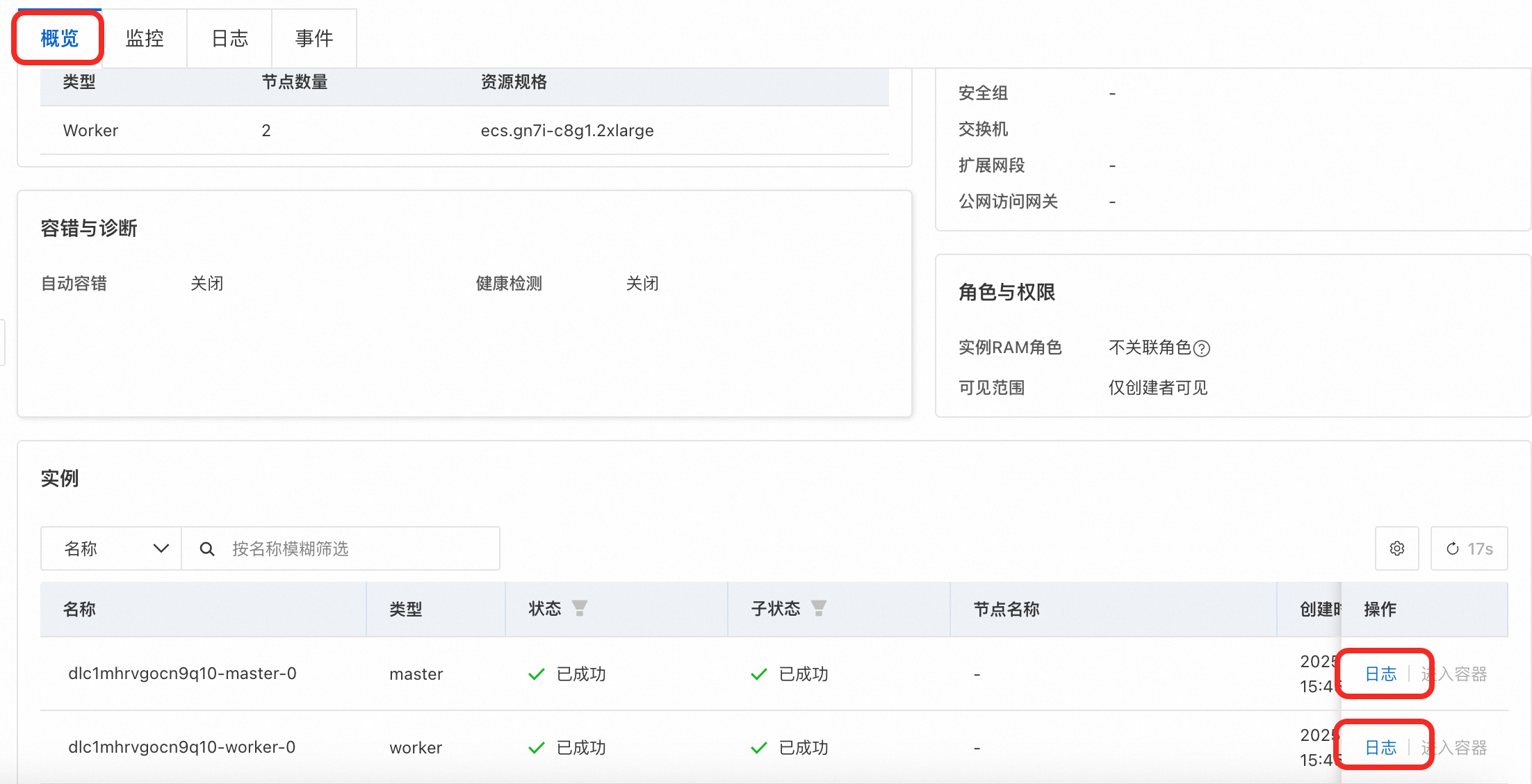
单击确定创建任务,任务大约需要执行10分钟。执行过程中可以在概览页面,查看两台实例的训练日志。
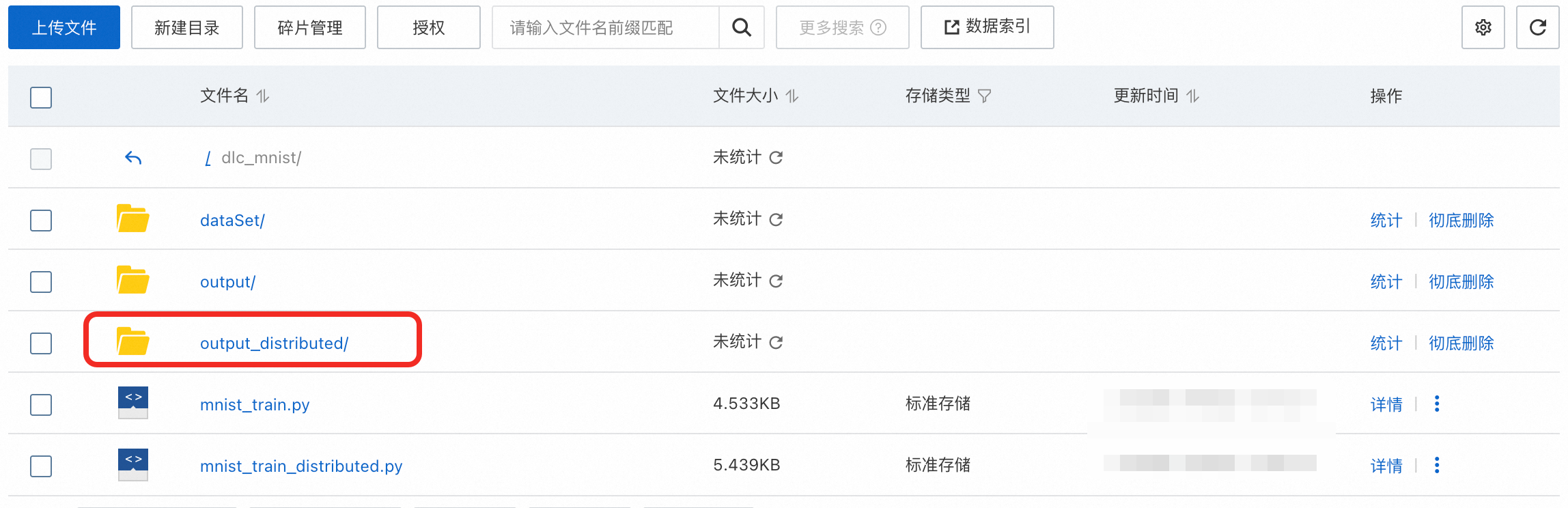
执行完成后,会在挂载数据集的
output_distributed路径下输出最佳的模型检查点,以及TensorBoard日志。
查看Tensorbord(可选)
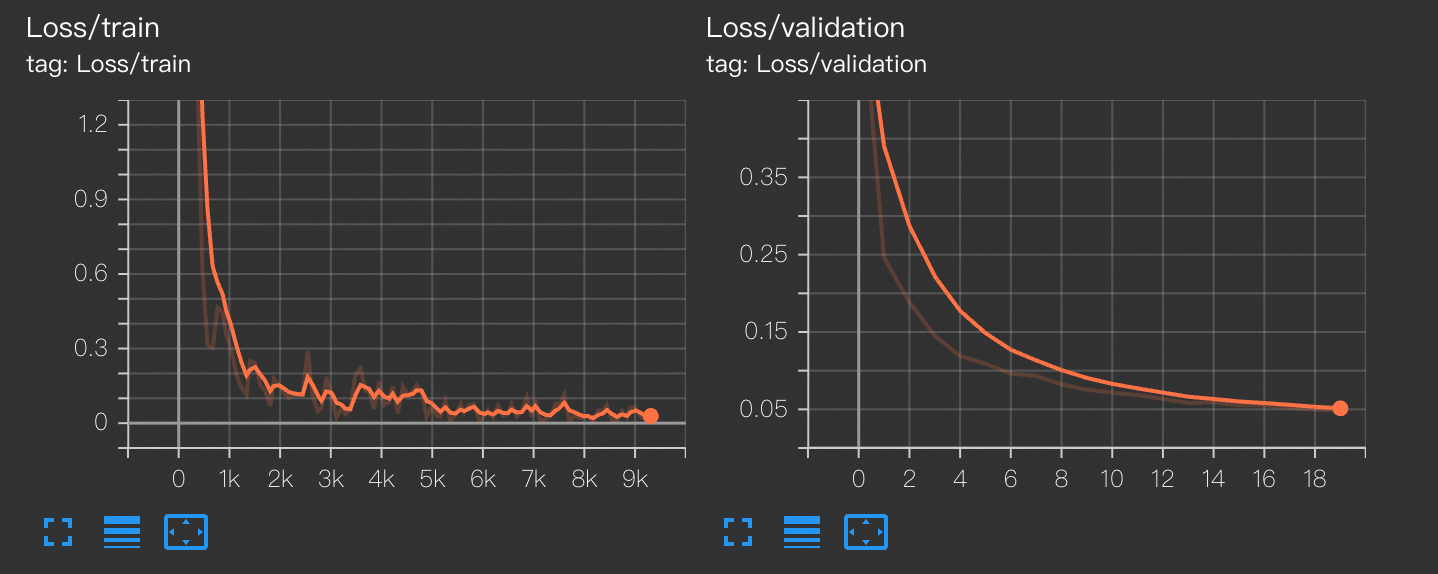
您可以借助可视化工具TensorBoard查看loss曲线,了解训练的具体情况。
DLC任务如果想使用TensorBoard,必须配置数据集。
单击DLC任务详情页上方的Tensorboard > 新建Tensorboard。
配置类型选择按任务,在Summary目录处填写训练代码中Summary存储的路径:
/mnt/data/output_distributed/runs,单击确定启动。对应代码片段:
writer = SummaryWriter('/mnt/data/output_distributed/runs/mnist_experiment')单击查看Tensorboard查看train_loss曲线(反映训练集损失)与 validation_loss曲线(反映验证集损失)。
部署训练后的模型
详情请参见使用EAS将模型部署为在线服务。