本文为您介绍如何在阿里PAI-DSW上微调CosyVoice2.0模型。
步骤一:创建DSW实例
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入DSW。
在开发机实例页签,单击新建实例。
在新建实例页面,配置以下关键参数,其他参数配置说明请参见创建DSW实例。
参数 | 描述 |
基础信息 | 实例名称 | 自定义DSW实例名称。例如cosyvoice-train。 |
资源信息 | 资源类型 | 选择公共资源。 |
资源规格 | 必须选择GPU机型,且建议优先选择双卡机型,例如ecs.gn7i-c32g1.16xlarge(64 vCPU、376 GiB、2 * NVIDIA A10),与训练脚本配置的双卡一致。后续可根据实际需求进行调整。 |
环境信息 | 镜像 | 在官方镜像列表中,选择。 |
存储路径挂载 | 挂载外部存储,用于存放训练生成的模型文件,供CosyVoice-WebUI使用。以挂载通用型NAS为例,您也可以挂载其他数据源。单击通用型NAS,并配置以下参数: 选择文件系统:选择文件系统。如果没有可选的文件系统,可在下拉列表中通过单击新建文件系统进行创建。 文件系统挂载点:选择文件系统挂载点。如果没有可选的文件系统挂载点,可在下拉列表中通过单击新建文件系统挂载点进行创建。 文件系统路径:填写该文件系统下的子路径,例如/。 挂载路径:表示挂载到DSW实例中的目标路径。例如/mnt/data/。
|
网络信息 | 专有网络配置 | 可选配置。具体使用场景,请参见DSW网络访问与配置。 |
安全组 |
交换机 |
参数配置完成后,单击确定。
步骤二:微调CosyVoice2.0模型
在交互式建模(DSW)页面的开发机实例页签,单击目标实例操作列下的打开。
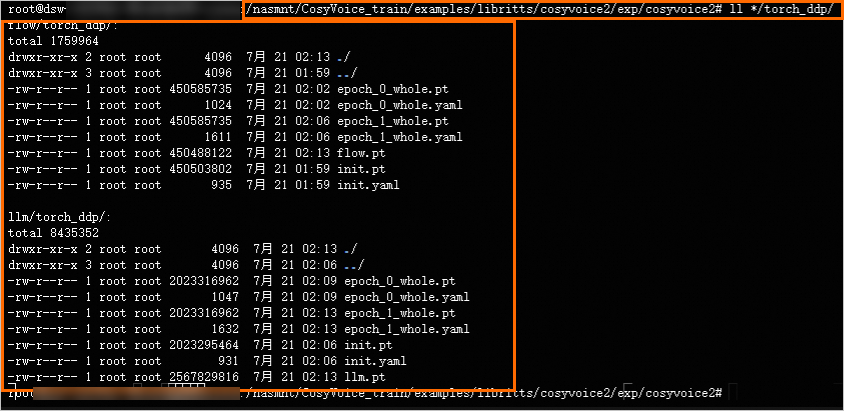
切换到Terminal页签,进入/nasmnt/目录,查看微调CosyVoice2.0模型所需数据,详细的数据结构如下图所示: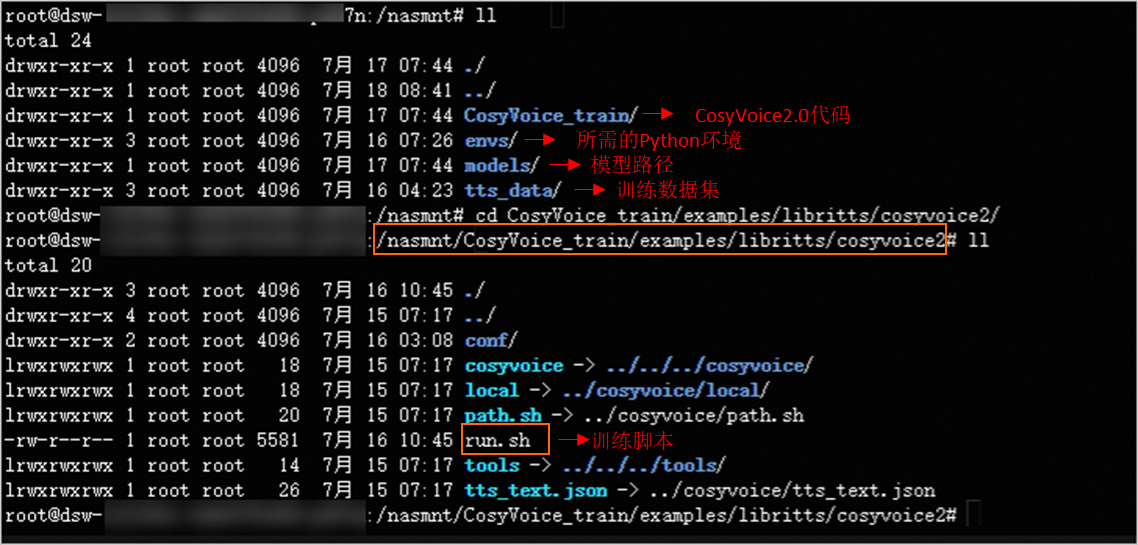
本方案使用预置数据集进行模型训练。您可以参考预置的数据集结构,准备自定义数据集,并使用自定义数据集对模型进行微调,从而生成符合需求的模型文件。
单击此处,查看run.sh脚本代码说明
下载数据集。
echo "Data Download"
for part in dev-clean test-clean train-clean-100; do
local/download_and_untar.sh ${data_dir} ${data_url} ${part}
done
准备训练数据。
echo "Data preparation, prepare wav.scp/text/utt2spk/spk2utt"
for x in train-clean-100 dev-clean test-clean; do
mkdir -p data/$x
/nasmnt/envs/cosyvoice_train/bin/python local/prepare_data.py --src_dir $data_dir/LibriTTS/$x --des_dir data/$x
done
抽取Speaker Embedding。
echo "Extract campplus speaker embedding, you will get spk2embedding.pt and utt2embedding.pt in data/$x dir"
for x in train-clean-100 dev-clean test-clean; do
/nasmnt/envs/cosyvoice_train/bin/python tools/extract_embedding.py --dir data/$x \
--onnx_path $pretrained_model_dir/campplus.onnx
done
抽取Speech Token,并生成utt2speech_token.pt文件。
echo "Extract discrete speech token, you will get utt2speech_token.pt in data/$x dir"
for x in train-clean-100 dev-clean test-clean; do
/nasmnt/envs/cosyvoice_train/bin/python tools/extract_speech_token.py --dir data/$x \
--onnx_path $pretrained_model_dir/speech_tokenizer_v2.onnx
done
准备Parquet格式的数据。
echo "Prepare required parquet format data, you should have prepared wav.scp/text/utt2spk/spk2utt/utt2embedding.pt/spk2embedding.pt/utt2speech_token.pt"
for x in train-clean-100 dev-clean test-clean; do
mkdir -p data/$x/parquet
/nasmnt/envs/cosyvoice_train/bin/python tools/make_parquet_list.py --num_utts_per_parquet 1000 \
--num_processes 32 \
--src_dir data/$x \
--des_dir data/$x/parquet
done
运行推理(Inference)。
echo "Run inference. Please make sure utt in tts_text is in prompt_data"
# TODO consider remove bin/inference.py, or use similar initilization method as in readme
for mode in sft zero_shot; do
/nasmnt/envs/cosyvoice_train/bin/python cosyvoice/bin/inference.py --mode $mode \
--gpu 0 \
--config conf/cosyvoice2.yaml \
--prompt_data data/test-clean/parquet/data.list \
--prompt_utt2data data/test-clean/parquet/utt2data.list \
--tts_text `pwd`/tts_text.json \
--qwen_pretrain_path $pretrained_model_dir/CosyVoice-BlankEN \
--llm_model $pretrained_model_dir/llm.pt \
--flow_model $pretrained_model_dir/flow.pt \
--hifigan_model $pretrained_model_dir/hift.pt \
--result_dir `pwd`/exp/cosyvoice/test-clean/$mode
done
运行训练脚本。
echo "Run train. We only support llm traning for now. If your want to train from scratch, please use conf/cosyvoice.fromscratch.yaml"
if [ $train_engine == 'deepspeed' ]; then
echo "Notice deepspeed has its own optimizer config. Modify conf/ds_stage2.json if necessary"
fi
cat data/train-clean-100/parquet/data.list > data/train.data.list.tmp
head -n 4 data/train.data.list.tmp > data/train.data.list
cat data/dev-clean/parquet/data.list > data/dev.data.list.tmp
head -n 1 data/dev.data.list.tmp > data/dev.data.list
# NOTE will update llm/hift training later
for model in flow llm; do
/nasmnt/envs/cosyvoice_train/bin/python /nasmnt/envs/cosyvoice_train/bin/torchrun --nnodes=1 --nproc_per_node=$num_gpus \
--rdzv_id=$job_id --rdzv_backend="c10d" --rdzv_endpoint="localhost:1234" \
cosyvoice/bin/train.py \
--train_engine $train_engine \
--config conf/cosyvoice2.yaml \
--train_data data/train.data.list \
--cv_data data/dev.data.list \
--qwen_pretrain_path $pretrained_model_dir/CosyVoice-BlankEN \
--model $model \
--checkpoint $pretrained_model_dir/$model.pt \
--model_dir `pwd`/exp/cosyvoice2/$model/$train_engine \
--tensorboard_dir `pwd`/tensorboard/cosyvoice2/$model/$train_engine \
--ddp.dist_backend $dist_backend \
--num_workers ${num_workers} \
--prefetch ${prefetch} \
--pin_memory \
--use_amp \
--deepspeed_config ./conf/ds_stage2.json \
--deepspeed.save_states model+optimizer
done
实现模型平均化,用于提高模型的稳定性和泛化能力。
# for model in llm flow hifigan; do
for model in llm flow; do
decode_checkpoint=`pwd`/exp/cosyvoice2/$model/$train_engine/${model}.pt
echo "do model average and final checkpoint is $decode_checkpoint"
/nasmnt/envs/cosyvoice_train/bin/python cosyvoice/bin/average_model.py \
--dst_model $decode_checkpoint \
--src_path `pwd`/exp/cosyvoice2/$model/$train_engine \
--num ${average_num} \
--val_best
done
导出JIT和ONNX格式的模型。
echo "Export your model for inference speedup. Remember copy your llm or flow model to model_dir"
/nasmnt/envs/cosyvoice_train/bin/python cosyvoice/bin/export_jit.py --model_dir $pretrained_model_dir
/nasmnt/envs/cosyvoice_train/bin/python cosyvoice/bin/export_onnx.py --model_dir $pretrained_model_dir
在Terminal指定目录中,运行run.sh脚本微调CosyVoice2.0模型。
cd /nasmnt/CosyVoice_train/examples/libritts/cosyvoice2
bash run.sh
执行过程大约需要30分钟。代码运行完成后,您可以在脚本所在目录下的/exp/cosyvoice2目录中,查看生成的模型文件(.pt格式)。随后,您可将该模型文件复制到数据源挂载目录,从而将其保存至数据源中。