
数据集加速器(DatasetAccelerator,简称DatasetAcc)依托于阿里云构建的PaaS服务,主要解决云上AI加速-数据集加速的场景。在机器学习训练场景下,通过对客户训练的数据集进行预分析和处理,为各种云原生的训练引擎提供统一的数据集访问加速方案,最终提升整体训练效率。
架构图
数据集加速器的架构图如下: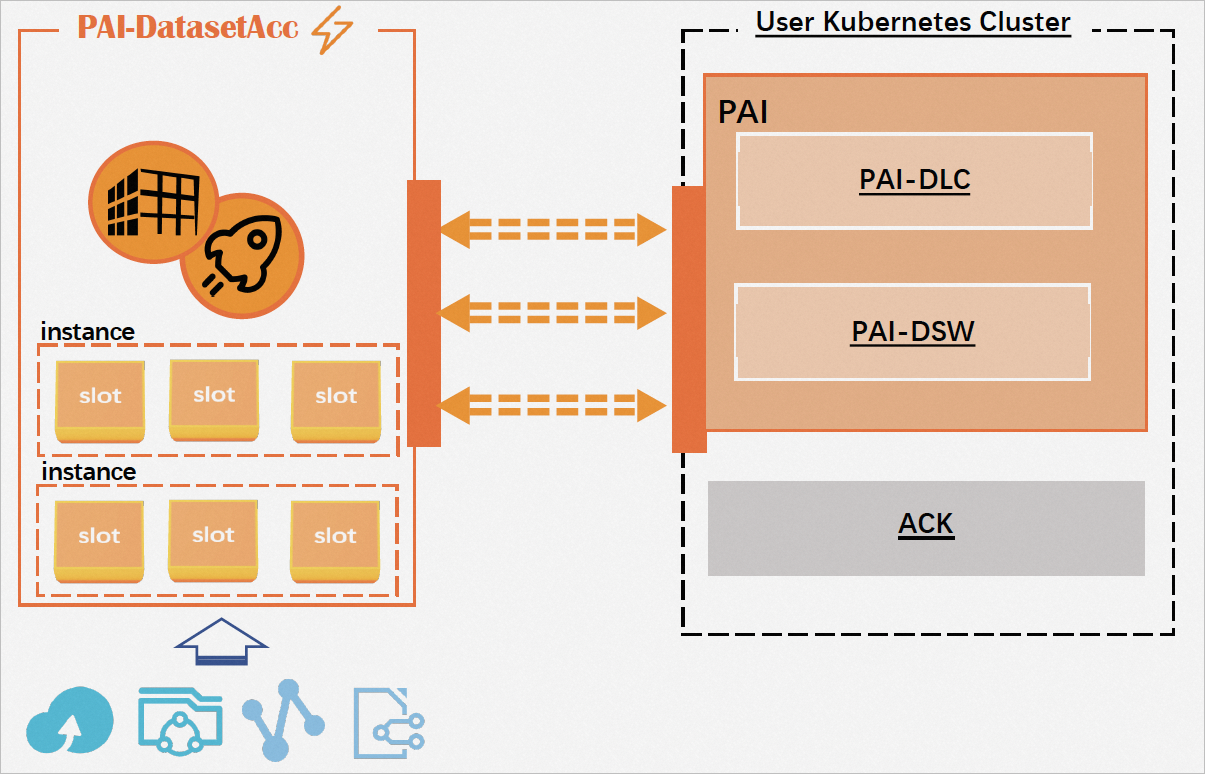
使用限制
在使用数据集加速器之前,请您先了解以下使用限制。
仅支持对存储在阿里云上的数据集进行加速,例如:OSS或CPFS。
仅支持存储在阿里云上的非加密数据集。
数据集加速器内的数据是只读状态,不支持动态写入数据。
单个数据集加速实例支持加速的数据集容量最多为100 TB。
计费说明
数据集加速器按购买容量和时长计费,计费详情请参见数据集加速器(DatasetAccelerator)计费说明。
产品特性
支持图片、文本、视频等海量小文件的训练优化。
通过感知深度学习训练的模型类型、网络结构,对图片、文本、视频等数据进行预先打包和处理,提升海量小文件训练场景的性能。
全托管,开箱即用。
云上全托管服务,操作简单,开通即可使用。
弹性可伸缩。
依托于云上IaaS(Infrastructure-as-a-Service)层能力,实现资源快速扩容、弹性可伸缩。
共享使用。
多个训练集群可以共享使用数据集加速器内的数据集进行训练。
安全多租户,确保数据访问安全。
实现多租户隔离,保障不同用户的数据安全。
基本概念
在使用数据集加速器之前,请您先了解以下基本概念。
数据集加速实例(Instance)
数据集加速产品的计费单位和管理单位。在数据集加速器创建预付费实例时,会预定对应的云上相关资源,所以在创建实例时即开始计费;在后付费场景中,加速实例的收费按照加速槽的用量按需付费。
加速槽(Slot)
单个数据集服务单位。一个数据集加速实例可以创建多个加速槽,一个加速槽用于加速一个数据集,可以实现多个深度学习训练任务使用不同的数据集同时训练的场景。
数据集加速实例和加速槽的关系
一个用户可以开通多个数据集加速实例,每个数据集加速实例可以申请多个不同容量的数据集加速槽,即数据集加速实例:数据集加速槽=1:n,一个数据集加速槽和一个数据集存储绑定。

操作流程
数据集加速器完整的使用流程,主要包括以下步骤。
您可以综合考虑自身业务、团队规模、训练频次及各种训练的数据集大小,来创建数据集加速实例。一个数据集加速实例可以通过创建多个加速槽,来支持多个数据集加速(对应不同的训练任务)。
因数据集加速器需要额外消耗云上资源,如果您需要确保对重要的训练任务的数据进行加速,建议通过预付费模式预先锁定数据集加速实例的空间大小。
在选定的数据集加速实例中,根据训练使用的一个数据集大小,创建数据集加速槽。一个数据集加速实例可以包含多个加速槽,所有加速槽的存储总和不能超过所属的数据集加速实例的容量。
创建加速槽,系统会根据数据类型、数据大小、训练的框架及模型等因素,对关联的数据集数据进行数据预处理。在完成加速初始化工作后,数据集加速器会提供相关接口,供训练任务直接使用。
在PAI平台创建数据集时,支持开启数据集加速功能。您可以在创建DSW实例或提交DLC训练任务时,直接使用已开启加速的数据集,提升数据读取效率。