RAG(Retrieval-Augmented Generation,检索增强生成)技术通过从外部知识库检索相关信息,并与用户输入合并传入大语言模型(LLM),增强模型对私有领域知识的问答能力。EAS提供场景化部署方式,支持灵活选择大语言模型和向量检索库,快速部署RAG对话系统。本文为您介绍如何部署RAG对话系统服务以及如何进行模型推理验证。
步骤一:部署RAG服务
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
在模型在线服务(EAS)页面,单击部署服务,然后在场景化模型部署区域,单击大模型RAG对话系统部署。
在部署大模型RAG对话系统页面,配置参数后单击部署。当服务状态变为运行中时,表示服务部署成功。关键参数说明如下。
基本信息
参数
描述
模型来源
支持以下两种模型来源:
开源公共模型:PAI预置了多种开源公共模型供您选择,包括Qwen、DeepSeek、Llama、ChatGLM、Baichuan、Falcon、Yi、Mistral、Gemma等。您可以直接部署相应参数量的模型。
自持微调模型:PAI也支持部署您自行微调后的模型,来满足特定的场景。
模型类别
当使用开源公共模型时,您可以根据具体使用场景选择相应参数量的开源模型。
使用自持微调模型时,您需要根据您微调的模型,选择相应的模型类别、参数量以及精度。
模型配置
使用自持微调模型时,您需配置微调模型的文件路径。后续部署服务时,系统将从该路径读取模型配置文件。支持以下两种配置类型:
说明建议您在Huggingface的Transformers下运行微调后的模型,确认其输出结果符合预期后,再考虑将其部署为EAS服务。
对象存储(OSS):请选择微调模型文件所在的OSS存储路径。
文件存储(NAS):请选择微调模型文件所在的NAS文件系统、NAS挂载点和NAS源路径。
资源配置
参数
描述
资源配置选择
在选择模型类别后,系统将自动匹配适合的资源规格。更换至其他资源规格,可能会导致模型服务启动失败。
推理加速
目前,部署在A10或GU30系列机型上的Qwen、Llama2、ChatGLM或Baichuan2等系列模型服务,支持启用推理加速功能。加速功能不另外收费。支持以下两种加速类型:
PAI-BladeLLM自动推理加速(推荐)
开源框架vllm推理加速
向量检索库设置
RAG支持通过Faiss(Facebook AI Similarity Search)、Elasticsearch、Milvus、Hologres、OpenSearch或RDS PostgreSQL构建向量检索库。根据您的场景需要,任意选择一种版本类型,作为向量检索库。
FAISS
使用Faiss构建本地向量库,无需购买线上向量库产品,免去了线上开通向量库产品的复杂流程,更轻量易用。
参数
描述
版本类型
选择FAISS。
OSS地址
选择当前地域下已创建的OSS存储路径,用来存储上传的知识库文件。如果没有可选的存储路径,您可以参考控制台快速入门进行创建。
说明如果您选择使用自持微调模型部署服务,请确保所选的OSS存储路径不与自持微调模型所在的路径重复,以避免造成冲突。
ElasticSearch
配置阿里云ElasticSearch实例的连接信息。关于如何创建ElasticSearch实例及准备配置项,请参见准备向量检索库Elasticsearch。
参数
描述
版本类型
选择Elasticsearch。
私网地址/端口
配置Elasticsearch实例的私网地址和端口,格式为
http://<私网地址>:<私网端口>。如何获取Elasticsearch实例的私网地址和端口号,请参见查看实例的基本信息。索引名称
输入新的索引名称或已存在的索引名称。对于已存在的索引名称,索引结构应符合PAI-RAG要求,例如您可以填写之前通过EAS部署RAG服务时自动创建的索引。
账号
配置创建Elasticsearch实例时配置的登录名,默认为elastic。
密码
配置创建Elasticsearch实例时配置的登录密码。如果您忘记了登录密码,可重置实例访问密码。
Milvus
配置Milvus实例的连接信息。关于如何创建Milvus实例及准备配置项,请参见准备向量检索库Milvus。
参数
描述
版本类型
选择Milvus。
访问地址
配置为Milvus实例内网地址。您可以前往阿里云Milvus控制台的实例详情页面的访问地址区域进行查看。
代理端口
配置为Milvus实例的Proxy Port,默认为19530。您可以前往阿里云Milvus控制台的实例详情页面的访问地址区域进行查看。
账号
配置为root。
密码
配置为创建Milvus实例时,您自定义的root用户的密码。
数据库名称
配置为数据库名称,例如default。创建Milvus实例时,系统会默认创建数据库default,您也可以手动创建新的数据库,具体操作,请参见管理Databases。
Collection名称
输入新的Collection名称或已存在的Collection名称。对于已存在的Collection,Collection结构应符合PAI-RAG要求,例如您可以填写之前通过EAS部署RAG服务时自动创建的Collection。
Hologres
配置为Hologres实例的连接信息。如果未开通Hologres实例,可参考购买Hologres进行操作。
参数
描述
版本类型
选择Hologres。
调用信息
配置为指定VPC的host信息。进入Hologres管理控制台的实例详情页,在网络信息区域单击指定VPC后的复制,获取域名
:80前的host信息。数据库名称
配置为Hologres实例的数据库名称。如何创建数据库,详情请参见创建数据库。
账号
配置为已创建的自定义用户账号。具体操作,请参见创建自定义用户,其中选择成员角色选择实例超级管理员(SuperUser)。
密码
配置为已创建的自定义用户的密码。
表名称
输入新的表名称或已存在的表名称。对于已存在的表名称,表结构应符合PAI-RAG要求,例如可以填写之前通过EAS部署RAG服务自动创建的Hologres表。
OpenSearch
配置为OpenSearch向量检索版实例的连接信息。关于如何创建OpenSearch实例及准备配置项,请参见准备向量检索库OpenSearch。
参数
描述
版本类型
选择OpenSearch。
访问地址
配置为OpenSearch向量检索版实例的公网访问地址。您需要为OpenSearch向量检索版实例开通公网访问功能,具体操作,请参见准备向量检索库OpenSearch。
实例id
在OpenSearch向量检索版实例列表中获取实例ID。
用户名
配置为创建OpenSearch向量检索版实例时,输入的用户名和密码。
密码
表名称
配置为准备OpenSearch向量检索版实例时创建的索引表名称。如何准备索引表,请参见准备向量检索库OpenSearch。
RDS PostgreSQL
配置为RDS PostgreSQL实例数据库的连接信息。关于如何创建RDS PostgreSQL实例及准备配置项,请参见准备向量检索库RDS PostgreSQL。
参数
描述
版本类型
选择RDS PostgreSQL。
主机地址
配置为RDS PostgreSQL实例的内网地址,您可以前往云数据库RDS PostgreSQL控制台页面,在RDS PostgreSQL实例的数据库连接页面进行查看。
端口
默认为5432,请根据实际情况填写。
数据库
配置为已创建的数据库名称。如何创建数据库和账号,请参见创建账号和数据库,其中:
创建账号时,账号类型选择高权限账号。
创建数据库时,授权账号选择已创建的高权限账号。
表名称
自定义配置数据库表名称。
账号
配置为已创建的高权限账号和密码。如何创建高权限账号,请参见创建账号和数据库,其中账号类型选择高权限账号。
密码
专有网络配置
参数
描述
VPC
交换机
安全组名称
步骤二:WebUI页面调试
RAG服务部署成功后,单击服务方式列下的查看Web应用,启动WebUI页面。
请按照以下操作步骤,在WebUI页面上传企业知识库文件并对问答效果进行调试。
1、参数配置
在Settings页签,您可以修改Embedding相关参数以及使用的大语言模型。建议直接使用默认配置。
Index相关参数说明:
Index Name:支持对已有Index进行更新。下拉列表选择New可新增Index,详情请参见多知识库索引支持。
EmbeddingType:支持huggingface和dashscope两种模型来源。
huggingface:系统提供内置的Embedding模型供您选择。
dashscope:使用百炼模型,默认使用text-embedding-v2模型,详情请参见Embedding。
Embedding Dimension:输出向量维度。维度的设置对模型的性能有直接影响。在您选择Embedding模型后,系统将自动配置Embedding维度,无需手动操作。
Embedding Batch Size: 批处理大小。
2、上传知识库文件
在Upload页签,您可以上传知识库文件,系统会自动按照PAI-RAG格式将知识库存储到向量检索库中。支持的文件类型为.txt、.pdf、Excel(.xlsx或.xls)、.csv、Word(.docx或.doc)、Markdown或.html,例如rag_chatbot_test_doc.txt。支持的上传方式如下:
从本地上传文件(支持多文件上传)或对应目录(Files或Directory页签)
从OSS上传(Aliyun OSS页签)
您可以在上传之前修改语义分块参数,参数说明如下:
参数 | 描述 |
Chunk Size | 指定每个文本分块的大小,单位为字节,默认为500。 |
Chunk Overlap | 表示相邻分块之间的重叠量,默认为10。 |
Process with MultiModal | 使用多模态模型处理,可以处理pdf、word、md文件的图片。如果您选择了使用多模态LLM,请打开此开关。 |
Process PDF with OCR | 使用OCR模式解析PDF文件。 |
3、模型推理验证
在Chat页签选择使用的知识库索引(Index Name),配置问答策略,并进行问答测试。支持以下4种问答策略:
Retrieval:直接从向量数据库中检索并返回Top K条相似结果。
LLM:直接使用LLM回答。
RAG(Search Web):使用Bing搜索查询Web信息,需要给EAS配置公网连接。联网搜索有以下三个配置选项:
Bing API Key:用于访问Bing搜索。如何获取Bing API Key,请参见Bing Web Search API。
Search Count:搜索的网页数量,默认为10。
Language:搜索语言,支持选择zh-CN(中文)和en-US(英文)。
RAG(Retrieval + LLM):将检索返回的结果与用户问题填充至已选择的Prompt模板中,一并送入EAS-LLM服务进行处理,从中获取问答结果。
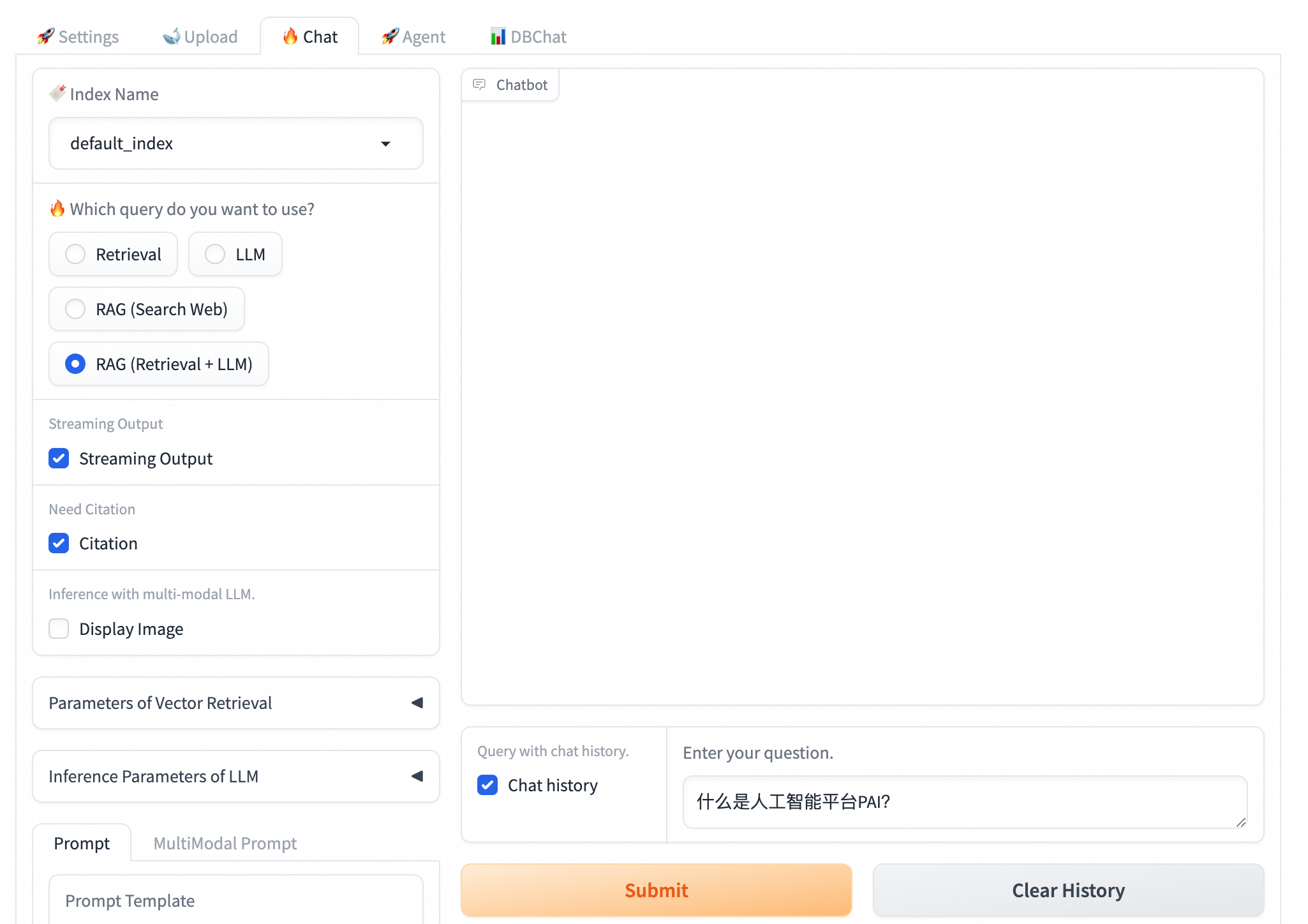
详细参数配置说明如下:
通用参数
参数
说明
Streaming Output
选中Streaming Output后,系统将以流式方式输出结果。
Need Citation
回答中是否需要给出引用。
Inference with multi-modal LLM
使用多模态大语言模型时是否展示图片。
向量检索相关参数
Retrieval Mode:支持以下三种检索方式:
Embedding Only:向量数据库检索召回。
Keyword Only:关键词检索召回。
Hybrid:向量数据库和关键词检索多路召回融合。
说明在大多数复杂场景下,向量数据库检索召回都能有较好的表现。但在某些语料稀缺的垂直领域,或要求准确匹配的场景,向量数据库检索召回方式可能不如传统的稀疏检索召回方式。稀疏检索召回方法通过计算用户查询与知识文档的关键词重叠度来进行检索,因此更为简单和高效。
PAI提供了BM25等关键词检索召回算法来完成稀疏检索召回操作。向量数据库检索召回和关键词检索召回具有各自的优势和不足,因此综合二者的召回结果能够提高整体的检索准确性和效率。
倒数排序融合(Reciprocal Rank Fusion, RRF)算法通过对每个文档在不同召回方法中的排名进行加权求和,以此计算融合后的总分数。当Retrieval选择Hybrid时,PAI将默认使用RRF算法对向量数据库召回结果和关键词检索召回结果进行多路召回融合。
LLM相关
Temperature :控制生成内容的随机性。温度值越低,输出结果也相对固定;而温度越高,输出结果则更具多样性和创造性。
步骤三:API调用
查询和上传API均可以指定index_name来切换知识库,当index_name参数省略时,默认为default_index知识库。详情请参见多知识库索引支持。
获取调用信息
单击RAG服务名称,进入服务详情页面。
在基本信息区域,单击查看调用信息。
在调用信息对话框的公网地址调用页签,获取服务访问地址和Token。
上传知识库文件
支持通过API上传本地的知识库文件。根据上传接口返回的task_id可以查询文件上传任务的状态。
以下示例中,<service_url>替换为RAG服务的访问地址;<service_token>替换为RAG服务的Token。获取方式详情请参见获取调用信息。
上传数据
curl -X 'POST' '<service_url>api/v1/upload_data' -H 'Authorization: <service_token>' -H 'Content-Type: multipart/form-data' -F 'files=@<file_path>' # Return: {"task_id": "****557733764fdb9fefa063538914da"}查询上传任务状态
curl '<service_url>api/v1/get_upload_state?task_id=****557733764fdb9fefa063538914da' -H 'Authorization: <service_token>' # Return: {"task_id":"****557733764fdb9fefa063538914da","status":"completed"}
单轮对话请求
cURL 命令
注意:以下示例中,<service_url>替换为RAG服务的访问地址;<service_token>替换为RAG服务的Token。获取方式详情请参见获取调用信息。
Retrieval:
api/v1/query/retrievalcurl -X 'POST' '<service_url>api/v1/query/retrieval' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是人工智能平台PAI?"}'LLM:
/api/v1/query/llmcurl -X 'POST' '<service_url>api/v1/query/llm' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是人工智能平台PAI?"}'支持添加其他可调推理参数,例如
{"question":"什么是人工智能平台PAI?", "temperature": 0.9}。RAG(Retrieval+LLM):
api/v1/querycurl -X 'POST' '<service_url>api/v1/query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是人工智能平台PAI?"}'支持添加其他可调推理参数,例如
{"question":"什么是人工智能平台PAI?", "temperature": 0.9}。RAG(Search Web):
api/v1/query/searchcurl --location '<service_url>api/v1/query/search' \ --header 'Authorization: <service_token>' \ --header 'Content-Type: application/json' \ --data '{"question":"中国电影票房排名", "stream": true}'
Python脚本
注意:以下示例中,SERVICE_URL配置为RAG服务的访问地址;Authorization配置为RAG服务的Token。获取方式详情请参见获取调用信息。
import requests
SERVICE_URL = 'http://xxxx.****.cn-beijing.pai-eas.aliyuncs.com/'
headers = {
'accept': 'application/json',
'Content-Type': 'application/json',
'Authorization': 'MDA5NmJkNzkyMGM1Zj****YzM4M2YwMDUzZTdiZmI5YzljYjZmNA==',
}
def test_post_api_query(url):
data = {
"question":"什么是人工智能平台PAI?"
}
response = requests.post(url, headers=headers, json=data)
if response.status_code != 200:
raise ValueError(f'Error post to {url}, code: {response.status_code}')
ans = dict(response.json())
print(f"======= Question =======\n {data['question']}")
if 'answer' in ans.keys():
print(f"======= Answer =======\n {ans['answer']}")
if 'docs' in ans.keys():
print(f"======= Retrieved Docs =======\n {ans['docs']}\n\n")
# LLM
test_post_api_query(SERVICE_URL + 'api/v1/query/llm')
# Retrieval
test_post_api_query(SERVICE_URL + 'api/v1/query/retrieval')
# RAG(Retrieval+LLM)
test_post_api_query(SERVICE_URL + 'api/v1/query')多轮对话请求
LLM和RAG(Retrieval+LLM)支持发送多轮对话请求,代码示例如下:
cURL命令
注意:以下示例中,<service_url>替换为RAG服务的访问地址;<service_token>替换为RAG服务的Token。获取方式详情请参见获取调用信息。
以RAG对话为例:
# 发送请求。
curl -X 'POST' '<service_url>api/v1//query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "什么是人工智能平台PAI?"}'
# 传入上述请求返回的session_id(对话历史会话唯一标识),传入session_id后,将对话历史进行记录,调用大模型将自动携带存储的对话历史。
curl -X 'POST' '<service_url>api/v1//query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question": "它有什么优势?","session_id": "ed7a80e2e20442eab****"}'
# 传入chat_history(用户与模型的对话历史),list中的每个元素是形式为{"user":"用户输入","bot":"模型输出"}的一轮对话,多轮对话按时间顺序排列。
curl -X 'POST' '<service_url>api/v1//query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question":"它有哪些功能?", "chat_history": [{"user":"PAI是什么?", "bot":"PAI是阿里云的人工智能平台......"}]}'
# 同时传入session_id和chat_history,会用chat_history对存储的session_id所对应的对话历史进行追加更新。
curl -X 'POST' '<service_url>api/v1//query' -H 'Authorization: <service_token>' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"question":"它有哪些功能?", "chat_history": [{"user":"PAI是什么?", "bot":"PAI是阿里云的人工智能平台......"}], "session_id": "1702ffxxad3xxx6fxxx97daf7c"}'Python
注意:以下示例中,SERVICE_URL配置为RAG服务的访问地址;Authorization配置为RAG服务的Token。获取方式详情请参见获取调用信息。
import requests
SERVICE_URL = 'http://xxxx.****.cn-beijing.pai-eas.aliyuncs.com'
headers = {
'accept': 'application/json',
'Content-Type': 'application/json',
'Authorization': 'MDA5NmJkN****jNlMDgzYzM4M2YwMDUzZTdiZmI5YzljYjZmNA==',
}
def test_post_api_query_with_chat_history(url):
# Round 1 query
data = {
"question": "什么是人工智能平台PAI?"
}
response = requests.post(url, headers=headers, json=data)
if response.status_code != 200:
raise ValueError(f'Error post to {url}, code: {response.status_code}')
ans = dict(response.json())
print(f"=======Round 1: Question =======\n {data['question']}")
if 'answer' in ans.keys():
print(f"=======Round 1: Answer =======\n {ans['answer']} session_id: {ans['session_id']}")
if 'docs' in ans.keys():
print(f"=======Round 1: Retrieved Docs =======\n {ans['docs']}")
# Round 2 query
data_2 = {
"question": "它有什么优势?",
"session_id": ans['session_id']
}
response_2 = requests.post(url, headers=headers, json=data_2)
if response.status_code != 200:
raise ValueError(f'Error post to {url}, code: {response.status_code}')
ans_2 = dict(response_2.json())
print(f"=======Round 2: Question =======\n {data_2['question']}")
if 'answer' in ans.keys():
print(f"=======Round 2: Answer =======\n {ans_2['answer']} session_id: {ans_2['session_id']}")
if 'docs' in ans.keys():
print(f"=======Round 2: Retrieved Docs =======\n {ans['docs']}")
print("\n")
# LLM
test_post_api_query_with_chat_history(SERVICE_URL + "api/v1/query/llm")
# RAG(Retrieval+LLM)
test_post_api_query_with_chat_history(SERVICE_URL + "api/v1/query")注意事项
本实践受制于LLM服务的最大Token数量限制,旨在帮助您体验RAG对话系统的基本检索功能:
该对话系统受制于LLM服务的服务器资源大小以及默认Token数量限制,能支持的对话长度有限。
如果无需进行多轮对话,建议您关闭with chat history功能,这样能有效减少达到限制的可能性。
WebUI操作方式:在RAG服务WebUI页面的Chat页签,去勾选Chat history复选框。

相关文档
通过EAS,您还可以完成以下场景化部署:
部署支持WebUI和API调用的LLM大语言模型,并在部署LLM应用后,利用LangChain框架集成企业知识库,实现智能问答和自动化功能。详情请参见5分钟使用EAS一键部署LLM大语言模型应用。
部署基于ComfyUI和Stable Video Diffusion模型的AI视频生成服务,帮助您完成社交平台短视频内容生成、动画制作等任务。详情请参见AI视频生成-ComfyUI部署。
一键部署基于Stable Diffusion WebUI的服务。详情请参见AI绘画-SDWebUI部署。