
为了增强模型生成答案的准确性和信息丰富度,您可以在大模型RAG服务中集成OpenSearch向量检索版产品。该产品支持多种向量检索算法,高性能支持多种典型场景,并提供图形化界面,您可以查看索引信息并实现简单的数据管理功能。通过集成OpenSearch向量检索版产品,可以提升RAG对话系统的检索效率和用户体验。本文将介绍如何在部署RAG服务时关联OpenSearch向量检索版产品,以及对RAG对话系统的基础功能和OpenSearch向量检索版的特色功能进行说明。
背景信息
EAS简介
EAS(Elastic Algorithm Service)是PAI的模型在线服务平台,支持将模型部署为在线推理服务和AI-Web应用。EAS提供了弹性扩缩容和蓝绿部署等功能,可以支撑您以较低的资源成本获取高并发且稳定的在线算法模型服务。此外,EAS具备资源组管理和版本控制等功能,并且有完整运维监控体系等能力。更详细的内容介绍,请参见EAS概述。
RAG简介
随着AI技术的飞速发展,生成式人工智能在文本生成、图像生成等领域展现出了令人瞩目的成就。然而,在广泛应用大语言模型(LLM)的过程中,一些固有局限性逐渐显现:
领域知识局限:大语言模型通常基于大规模通用数据集训练而成,难以针对专业垂直领域提供深入和针对性处理。
信息更新滞后:由于模型训练所依赖的数据集具有静态特性,大模型无法实时获取和学习最新的信息与知识进展。
模型误导性输出:受制于数据偏差、模型内在缺陷等因素,大语言模型可能会出现看似合理实则错误的输出,即所谓的“大模型幻觉”。
为克服这些挑战,并进一步强化大模型的功能性和准确性,检索增强生成技术RAG(Retrieval-Augmented Generation)应运而生。这一技术通过整合外部知识库,能够显著减少大模型虚构的问题,并提升其获取及应用最新知识的能力,从而实现更个性化和精准化的LLM定制。
OpenSearch简介
阿里云OpenSearch向量检索版,是一款全托管的大规模分布式向量检索产品,支持多种向量检索算法,高精度下性能表现优异,能完成海量数据下的高性价比向量索引构建和相似度检索服务,支持索引水平拓展与合并、索引流式构建,数据能够做到实时动态更新,即增即查。
阿里云OpenSearch向量检索版可以高性能支持多种向量检索典型场景,如:RAG检索增强生成、多模态检索、个性化搜推等。更详细的内容介绍,请参见OpenSearch向量检索版介绍。
使用流程
EAS自建了RAG系统化解决方案,提供了灵活可调的参数配置,您可以通过WebUI或者API调用RAG服务,定制自己专属的对话系统。RAG技术架构的核心为检索和生成:
在检索方面,EAS支持多种向量检索库,包括开源的Faiss和阿里云的Milvus、Elasticsearch、Hologres、OpenSearch以及RDS PostgreSQL。
在生成方面,EAS支持丰富的开源模型,例如通义千问、Llama、Mistral、百川等,同时支持ChatGPT调用。
本方案以OpenSearch为例,为您介绍如何使用EAS与阿里云OpenSearch向量检索版构建一个大模型RAG对话系统。整体流程大约花费20分钟,具体流程如下:
首先创建OpenSearch向量检索版实例,并准备部署RAG服务关联该实例时依赖的配置项。
在EAS模型在线服务平台部署RAG服务,并关联OpenSearch向量检索版实例。
您可以在RAG对话系统中连接OpenSearch,上传业务数据文件,并进行知识问答。
前提条件
已创建专有网络VPC、交换机和安全组。具体操作,请参见搭建IPv4专有网络和创建安全组。
注意事项
本实践受制于LLM服务的服务器资源大小以及默认Token数量限制,能支持的对话长度有限,旨在帮助您体验RAG对话系统的基本检索功能。
准备向量检索库OpenSearch
步骤一:创建OpenSearch向量检索版实例
进入OpenSearch控制台,在左上角切换到OpenSearch-向量检索版:
在实例列表页面,创建OpenSearch向量检索版实例。其中关键参数配置如下,更多配置说明,请参见购买OpenSearch向量检索版实例。
参数
描述
商品版本
选择向量检索版。
专有网络
选择已创建的专有网络和交换机。
虚拟交换机
用户名
OpenSearch向量检索实例的用户名。
用户密码
OpenSearch向量检索实例的密码。
步骤二:准备配置项
1.准备实例ID
在实例列表页面,查看OpenSearch向量检索版的实例ID,并保存到本地。

2.准备索引表
实例创建成功后,会进入待配置状态。您需要为该实例配置表基础信息>数据同步>字段配置>索引结构,之后等待索引重建完成即可正常搜索。具体操作步骤如下:
单击待配置实例操作列下的配置。
进行表基础信息配置,参数配置完成后,单击下一步。
其中关键参数说明如下,其他参数配置说明,请参见通用版快速入门。
表名称:自定义索引表名称。
数据分片数:如果您购买了查询节点,则在分片数设置时,可配置为不超过256的正整数, 用于提升全量构建速度、单次查询性能。如果未购买查询节点,则数据分片数只能配置为1。
数据更新资源数:数据更新所用资源数,每个索引默认免费提供2个4核8G的更新资源,超出免费额度的资源将产生费用,详情可参考向量检索版计费概述
场景模板:选择通用模板。
进行数据同步配置,参数配置完成后,单击下一步。
其中全量数据来源支持三种数据源方式,您可以根据具体业务情况进行选择:
MaxCompute+API:使用MaxCompute进行数据全量写入,实时数据通过API写入。使用该方式时,具体参数配置说明,请参见MaxCompute + API 数据源。
对象存储OSS+API:使用OSS进行数据全量写入,实时数据通过API写入。使用该方式时,具体参数配置说明,请参见OSS + API 数据源。
API:全量与实时数据均通过API写入。
进行字段配置,参数配置完成后,单击下一步。
将以下字段配置文件示例内容保存为JSON文件,然后单击右上角的导入字段索引结构,并按控制台操作指引导入索引文件。导入后,将基于文件内容填写字段配置和索引结构。
进行索引结构配置,参数配置完成后,单击下一步。
其中关键配置说明如下,其他参数配置说明,请参见向量索引通用配置。
向量维度:设置为1024。
距离类型:建议选择InnerProduct。
在确认创建配置向导页面,单击确认创建。
系统将自动跳转至表管理页面,当状态为使用中时,表明索引表创建成功。
3.为OpenSearch向量检索版实例开通公网访问功能
目前,EAS只能通过公网访问OpenSearch,需要具备访问公网的能力。因此,您需要为EAS添加VPC,并为该VPC绑定NAT网关和弹性公网IP(EIP)。同时,为确保OpenSearch实例能够接收来自EAS实例的公网请求,您需要为OpenSearch开通公网访问,并将上述EIP地址加入白名单。以下内容为您介绍如何为EAS的VPC配置公网访问OpenSearch功能,EAS可以使用与OpenSearch相同的VPC,也可以使用其他VPC。
为后续部署RAG服务时绑定的专有网络(VPC)配置公网访问功能。具体操作,请参见使用公网NAT网关SNAT功能访问互联网。
查看已绑定的弹性公网IP地址。
登录专有网络管理控制台。单击专有网络实例ID,并切换到资源管理页签。
单击已绑定的公网NAT网关,进入公网NAT网关页面。
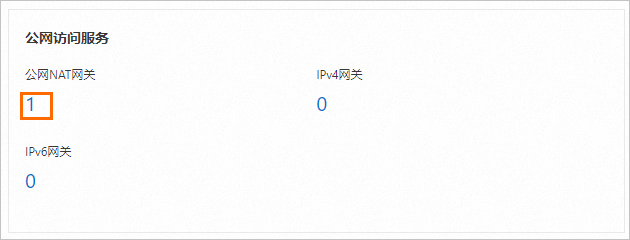
单击公网NAT网关实例ID,进入基本信息页面。
单击绑定的弹性公网IP,查看已绑定的弹性公网IP地址,并保存到本地。

在OpenSearch向量检索版实例列表页面,单击目标实例名称,进入实例详情页面。
在网络信息区域,打开公网访问开关,并在修改公网访问白名单配置面板中,按照控制台操作指引,将上述步骤已查询的弹性公网IP配置为公网访问白名单。
在网络信息区域,将公网域名后的访问地址保存到本地。
4.查看实例用户名和密码
即在创建OpenSearch向量检索版实例时,输入的用户名和密码。您可以在实例详情页面的API入口区域查看。
部署RAG服务并关联OpenSearch
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
在推理服务页签,单击部署服务,然后在场景化模型部署区域,单击大模型RAG对话系统部署。
在部署大模型RAG对话系统页面,配置以下关键参数,其他参数配置说明,请参见步骤一:部署RAG服务。
参数
描述
基本信息
版本选择
选择LLM一体化部署。
RAG版本
选择pai-rag:0.3.4。
模型类别
选择qwen1.5-1.8b。
资源信息
部署资源
系统会根据已选择的模型类别,自动推荐适合的资源规格。更换至其他资源规格,可能会导致模型服务启动失败。
向量检索库设置
版本类型
选择OpenSearch。
访问地址
配置为步骤二中已获取的公网域名,不带http://或https://,例如ha-cn-****.public.ha.aliyuncs.com。
实例id
配置为步骤二中已获取的OpenSearch向量检索版实例的ID。
用户名
配置为创建OpenSearch向量检索版实例时设置的用户名。
密码
配置为创建OpenSearch向量检索版实例时设置的密码。
表名称
配置为步骤二中已创建的索引表名称。
OSS地址
请选择当前地域下已创建的OSS存储目录。通过挂载OSS路径实现知识库管理。
专有网络
专有网络(VPC)
您可以选择与OpenSearch一致的专有网络和交换机。
您也可以使用其他专有网络,但需要确保该专有网络具有公网访问能力,并将绑定的弹性公网IP添加为OpenSearch实例的公网访问白名单。具体操作,请参见使用公网NAT网关SNAT功能访问互联网和公网白名单配置。
交换机
安全组名称
选择安全组。
参数配置完成后,单击部署。
使用RAG对话系统
RAG对话系统的基本使用方法如下,更多详细介绍,请参见大模型RAG对话系统(v0.3.x)。
1、检查向量检索库配置
单击目标RAG服务名称,然后在页面右上角单击查看Web应用。
检查向量检索库OpenSearch配置是否正确。
系统已自动配置知识库default,并自动识别应用了部署RAG服务时配置的向量检索库设置。在向量数据库配置区域,检查OpenSearch配置是否正确,可修改对应配置项为正确配置,然后单击更新知识库。

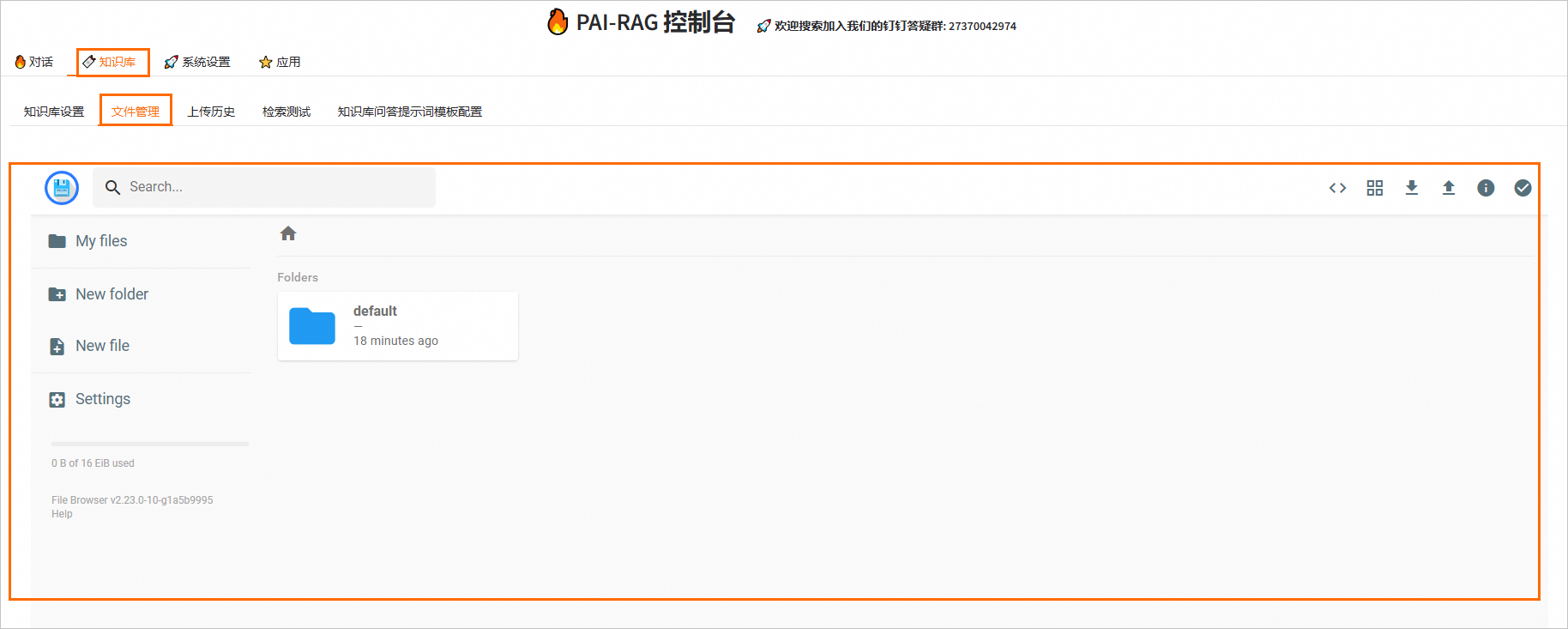
2、上传企业知识库文件
在知识库页签的文件管理Tab页上传知识库文件。上传知识库文件的具体操作方法,请参见RAG知识库管理。
知识库上传完成后,系统会自动按照PAI-RAG格式将文件存储到向量检索库。对于同名知识库文件,除了FAISS外,其他向量检索库将会覆盖原有文件。支持的文件类型为.html、.htm、.txt、.pdf、.pptx、.md、Excel(.xlsx或.xls)、.jsonl、.jpeg、.jpg、.png、.csv或Word(.docx),例如rag_chatbot_test_doc.txt。
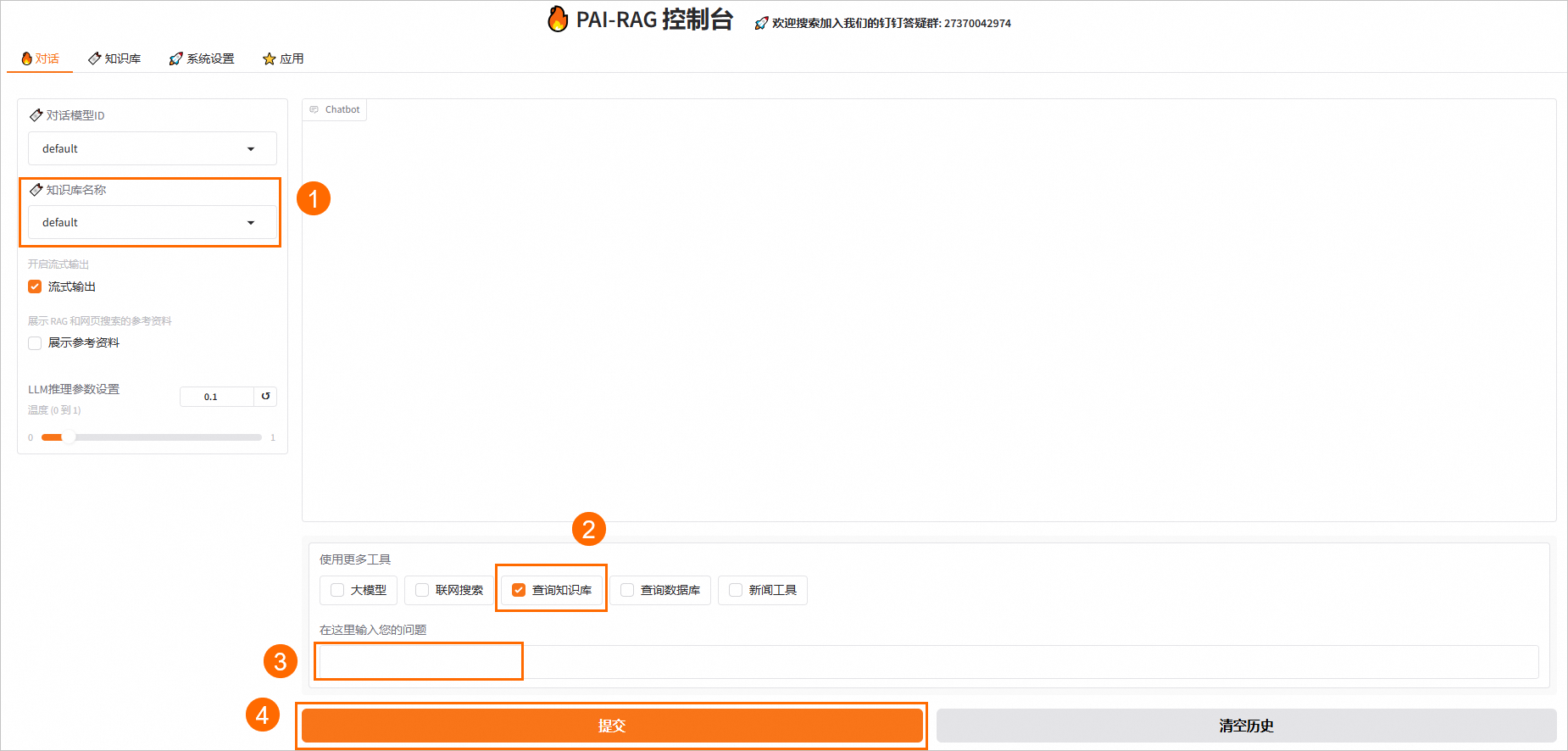
3、进行知识问答
在对话页签,选择知识库名称、使用意图(使用更多工具选择查询知识库)进行知识问答。
OpenSearch特色功能支持
阿里云OpenSearch向量检索版为客户提供了便捷的图形化界面,可以高效管理索引表(Table)以及索引(Index),以下内容将为您介绍,如何使用OpenSearch向量检索版控制台,查看索引信息并实现简单的数据管理。
索引表管理
进入阿里云OpenSearch向量检索版实例详情页面。
单击已创建的实例ID,进入实例详情页面。
进入表管理页面,对索引表进行管理操作。
在左侧导航栏,单击表管理。
页面中展示当前实例下创建的所有表。
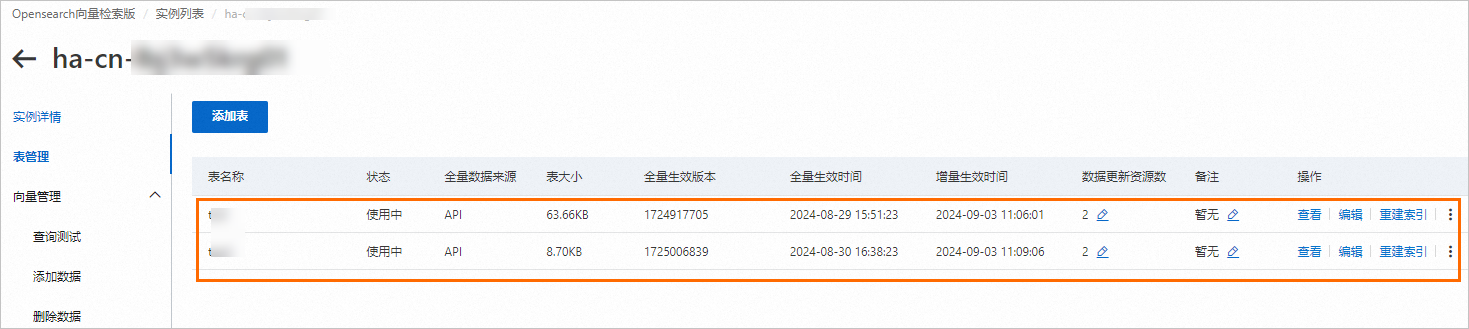
在表管理页面,对索引表进行管理操作,包括查看字段及索引结构、编辑索引、索引重建以及删除索引等。具体操作细节,请参见表管理。
数据管理
进入阿里云OpenSearch向量检索版实例详情页面。
单击已创建的实例ID,进入实例详情页面。
添加数据。
在左侧导航栏,单击 。
在页面右侧下拉列表中,选择表单模式或开发者模式。
选择要添加数据的目标索引表(Table)名称。
按字段输入数据内容或填写数据写入语句,然后单击添加。具体操作请参见:添加数据。
当执行结果出现
"message": "success"时,表示数据上传成功,即可完成单条数据或多条数据的添加。
查看表指标数据。
在左侧导航栏,单击 。
选择要查看数据的目标索引表(Table)名称,即可查看索引内文档个数、每秒请求成功次数等指标。详情请参见表指标。
删除数据。
在左侧导航栏,选择。
在页面右侧下拉列表中,选择表单模式或开发者模式。
选择表名并输入主键,然后单击删除。具体操作请参见:删除数据。
当执行结果出现
"message": "success"时,表示数据删除成功。
相关文档
针对AIGC和LLM的典型前沿场景,EAS提供了简化的部署方式。您可以很方便地一键拉起服务,包括ComfyUI部署、Stable Diffusion WebUI部署、ModelScope模型部署、HuggingFace模型部署、Triton部署以及TFserving部署等。详情请参见EAS场景化部署说明。
RAG服务WebUI界面提供了丰富的推理参数配置选项,以满足多样化需求。此外,RAG服务也支持通过API接口进行调用。具体实现细节以及参数配置说明,请参见大模型RAG对话系统(v0.3.x)。
大模型RAG对话系统还支持与其他向量检索库进行关联,例如Milvus、Elasticsearch或RDS PostgreSQL等。详情请参见基于EAS&Milvus搭建RAG检索增强对话系统、基于EAS&Elasticsearch搭建RAG检索增强对话系统或基于EAS&RDS PostgreSQL搭建RAG检索增强对话系统。