混合专家模型(MoE)通过“稀疏激活”机制,在实现万亿级参数规模的同时降低计算成本,但也给传统推理部署带来挑战。专家并行(EP)是一种专为MoE设计的分布式策略,它将不同专家部署在不同GPU上,通过动态路由请求,有效解决显存瓶颈、提升并行计算性能,并显著降低部署成本。本文介绍在PAI-EAS上,为MoE模型启用专家并行(EP)和Prefill-Decode(PD)分离部署,以实现更高的推理吞吐和成本效益。
方案架构
阿里云人工智能平台PAI的模型在线服务(EAS) 提供生产级EP的部署支持,将PD分离、大规模EP、计算-通信协同优化、MTP等技术融为一体,形成多维度联合优化的新范式。

方案优势:
一键式部署:提供内置镜像、可选资源、运行命令等的EP部署模板,将复杂的分布式部署简化为向导式操作,无需关注底层实现。
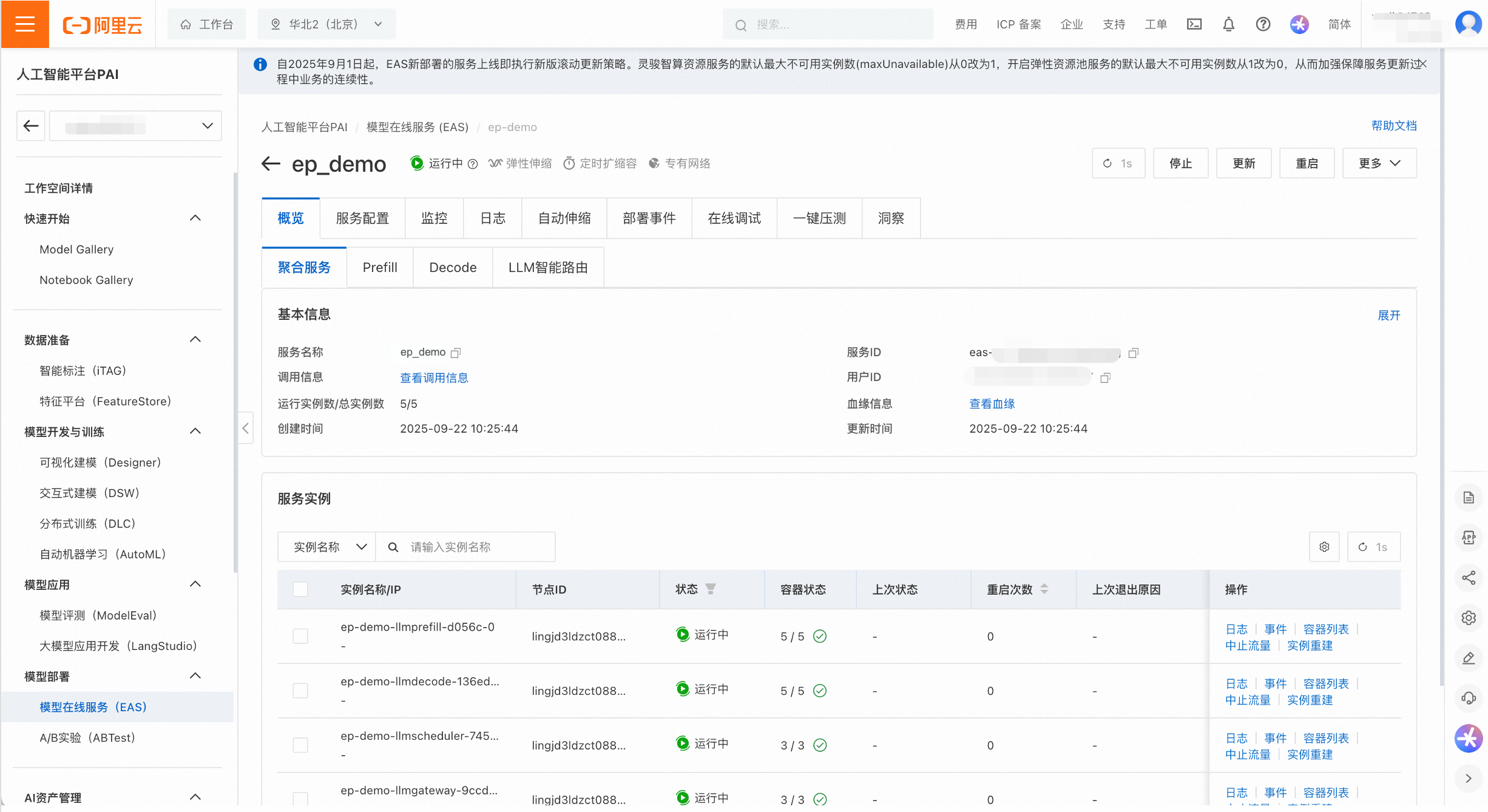
聚合服务管理:在统一视图下对Prefill、Decode和智能路由等子服务进行独立监控、扩缩容和生命周期管理。
部署EP服务
以部署模型DeepSeek-R1-0528-PAI-optimized(PAI优化版模型,能够支持更高的吞吐和更低的时延)为例,操作步骤如下:
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
在推理服务页签,单击部署服务,然后在场景化模型部署区域,单击LLM大语言模型部署。
模型配置选择公共模型DeepSeek-R1-0528-PAI-optimized。
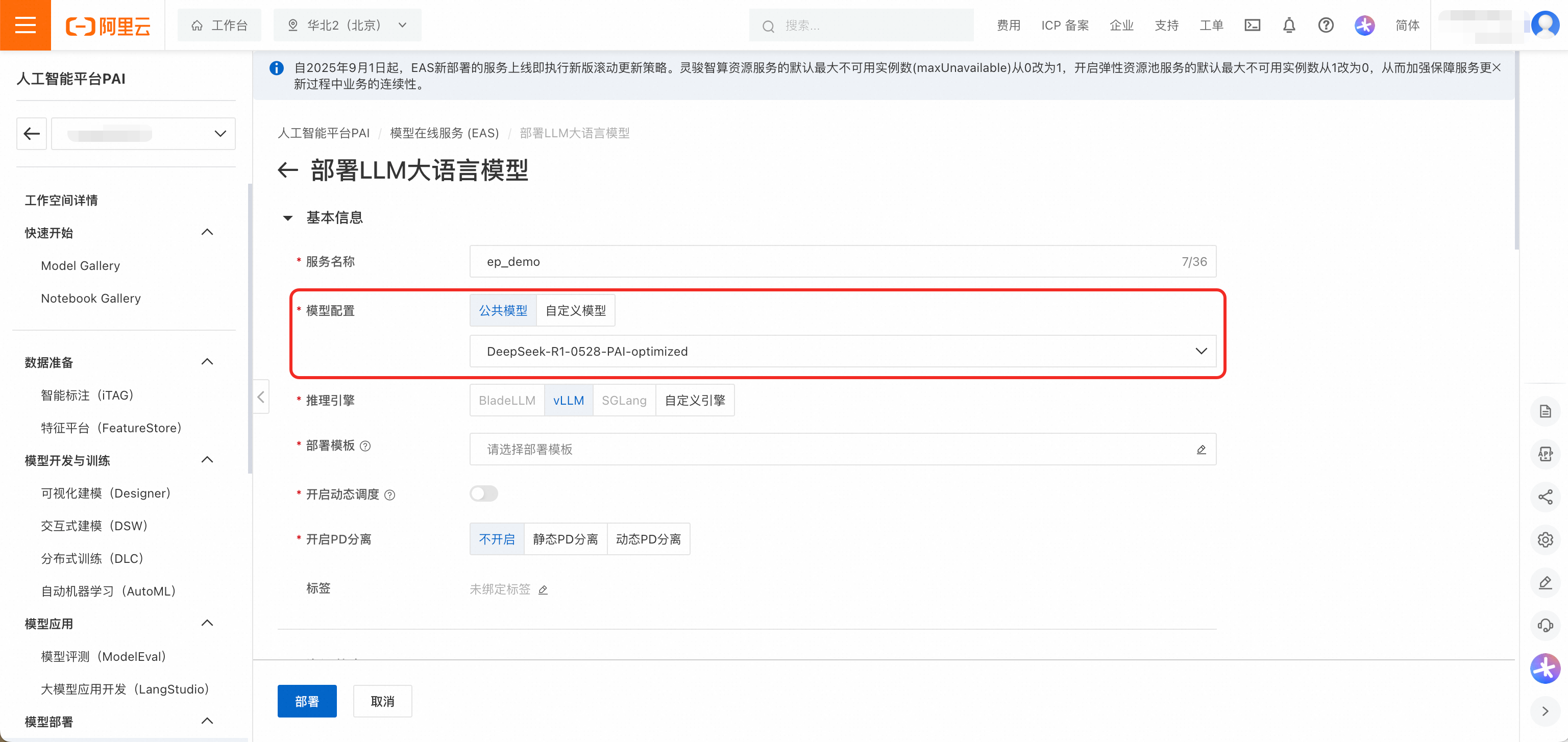
推理引擎选择vLLM,部署模板选择EP+PD分离-PAI优化版。

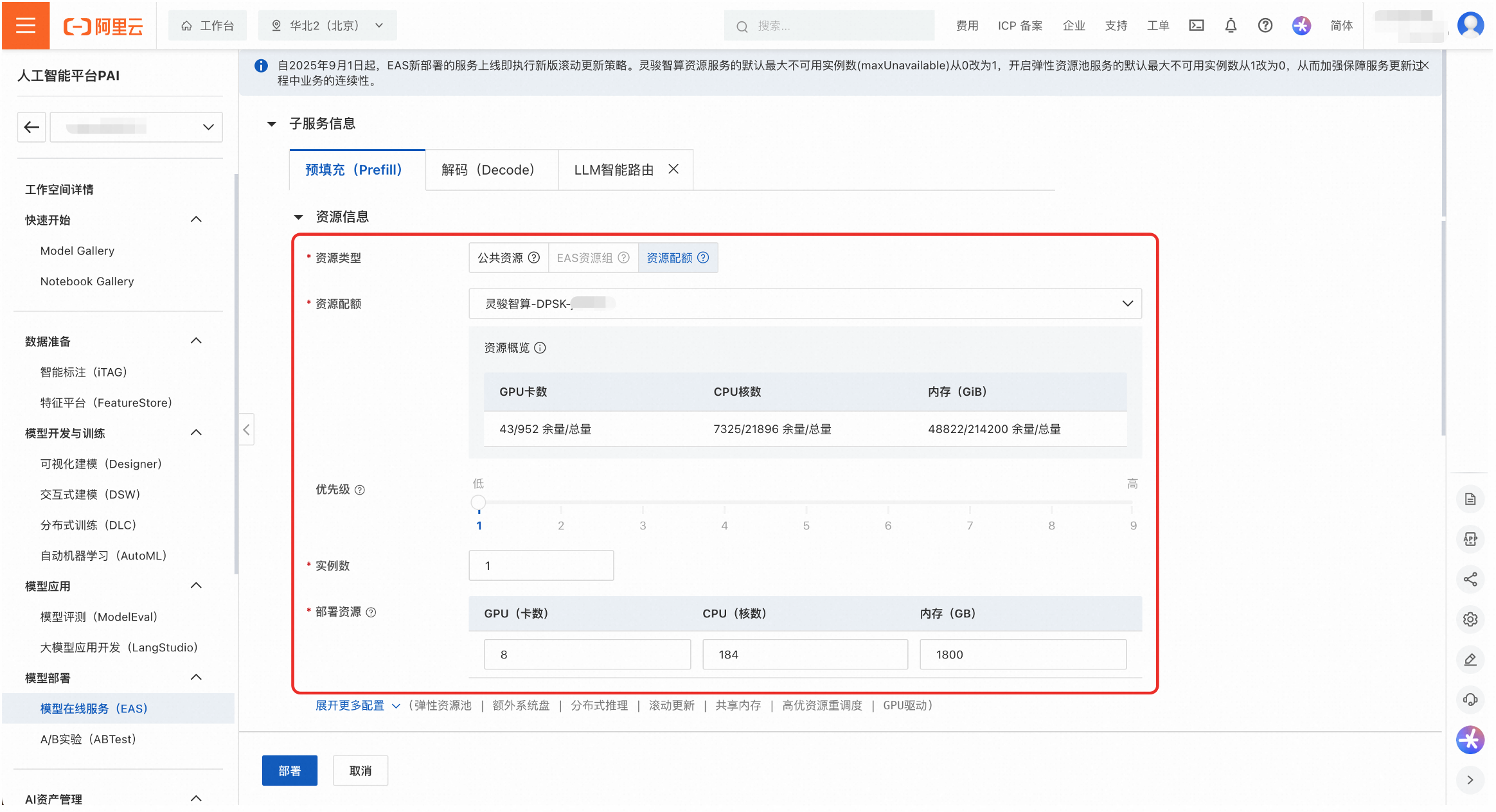
为Prefill和Decode服务配置部署资源。可以选择公共资源或者资源配额。
公共资源:适用于快速体验和开发测试。可用规格有
ml.gu8tea.8.48xlarge或ml.gu8tef.8.46xlarge。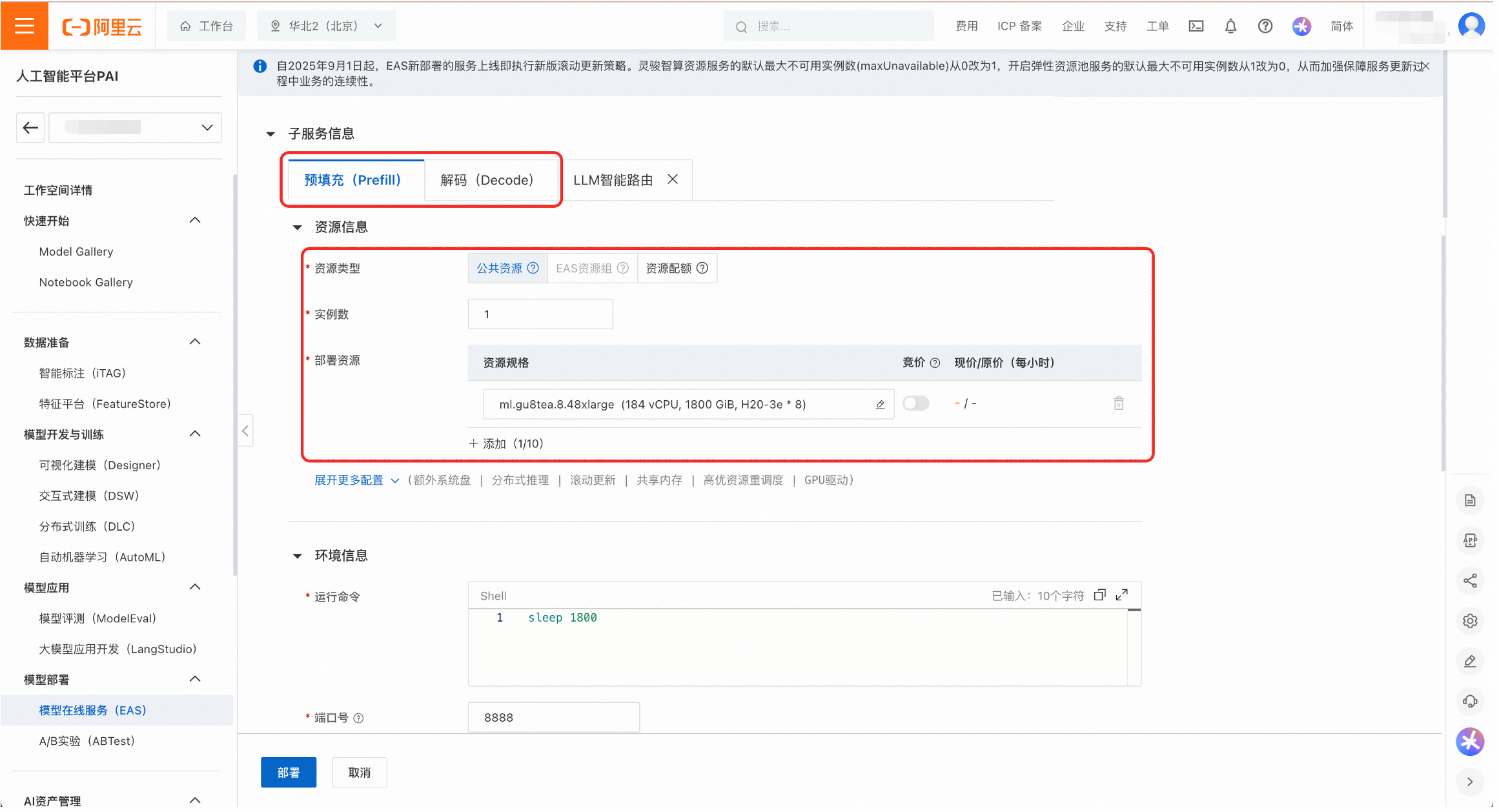
资源配额:推荐用于生产环境,以保证资源稳定性和隔离性。如果没有可用的资源配置,无法选择该类型。
(可选)调整部署参数以优化性能。
实例数:调整Prefill和Decode的实例数量,以改变PD配比。部署模板中实例数的默认设置为1。
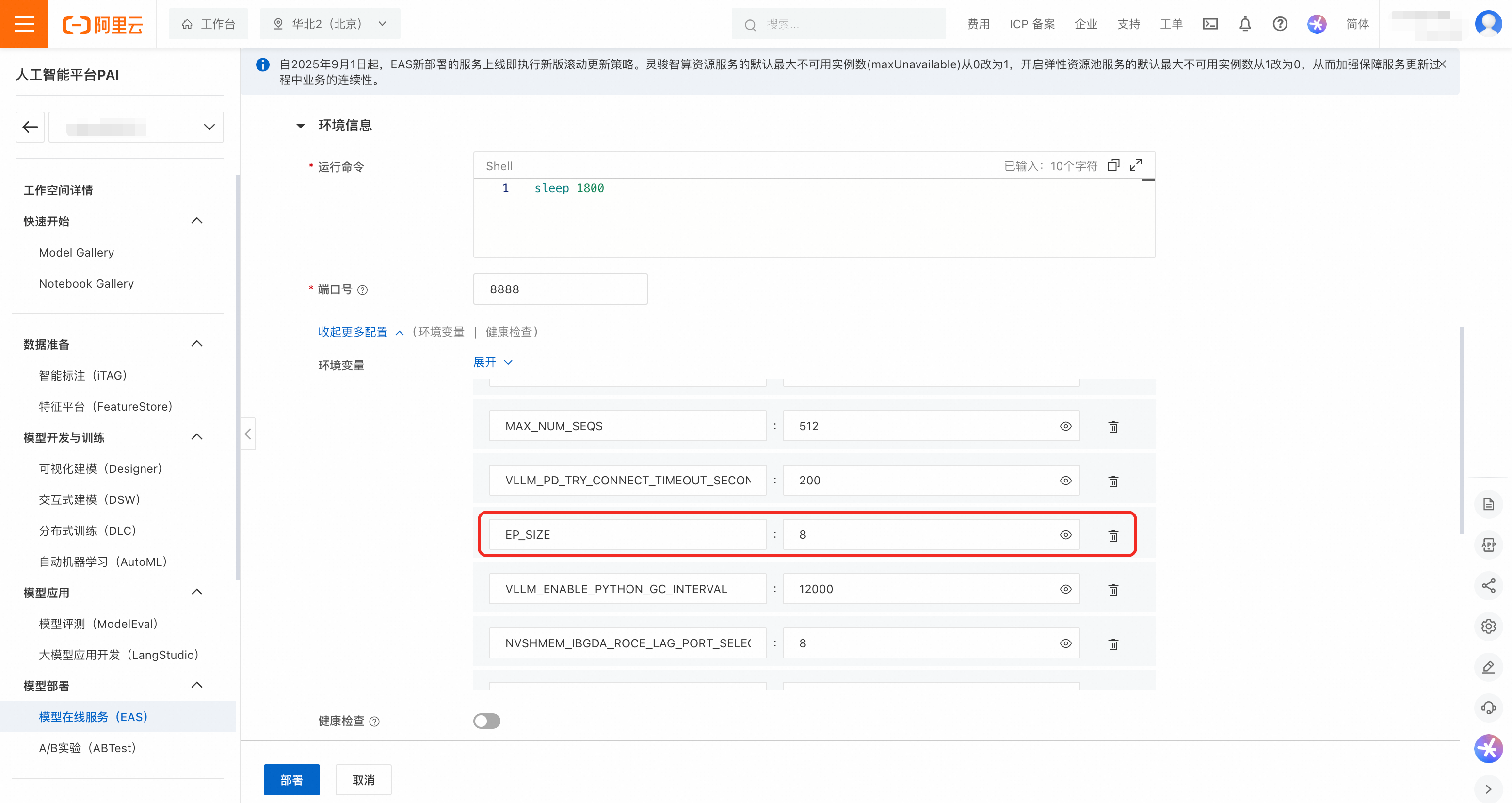
并行参数:在环境变量中调整Prefill和Decode服务的并行策略参数,如
EP_SIZE,DP_SIZE和TP_SIZE。部署模板中的默认值为:Prefill的TP_SIZE为8,Decode的EP_SIZE和DP_SIZE为8。说明为保护DeepSeek-R1-0528-PAI-optimized的模型权重,平台未透出推理引擎的运行命令,用户可以通过环境变量修改重要参数。

单击部署,等待服务启动。此过程约需要40分钟。
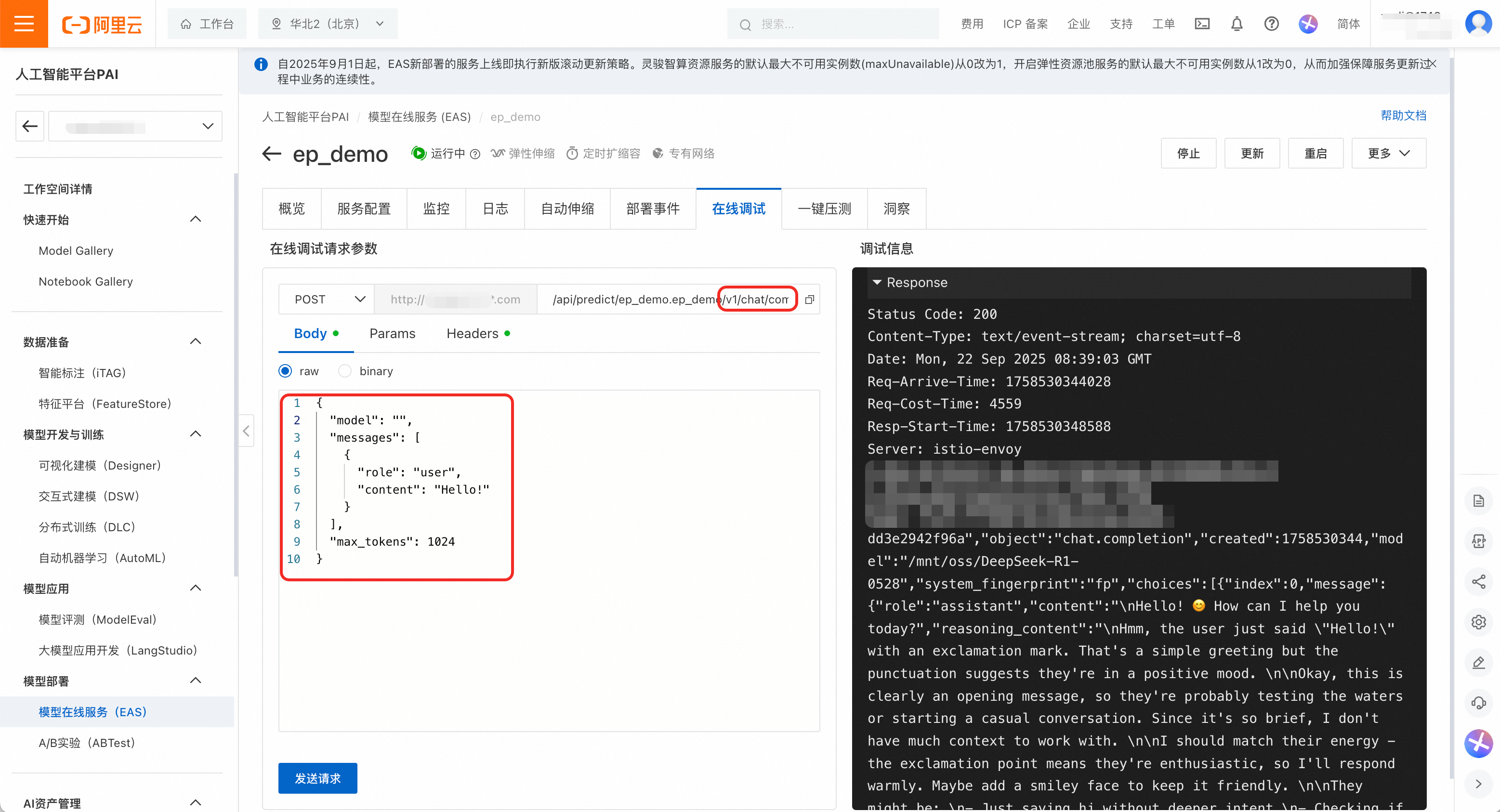
验证服务状态。部署完成后,在服务详情页的在线调试页签中测试服务是否正常运行。
说明API调用及第三方应用集成,可参见调用LLM服务。
构造一个符合OpenAI格式的请求,在URL路径后附加
/v1/chat/completions,请求体为:{ "model": "", "messages": [ { "role": "user", "content": "Hello!" } ], "max_tokens": 1024 }单击发送请求,可以看到响应结果为200,模型成功输出回答,表示服务正常运行。
管理EP服务
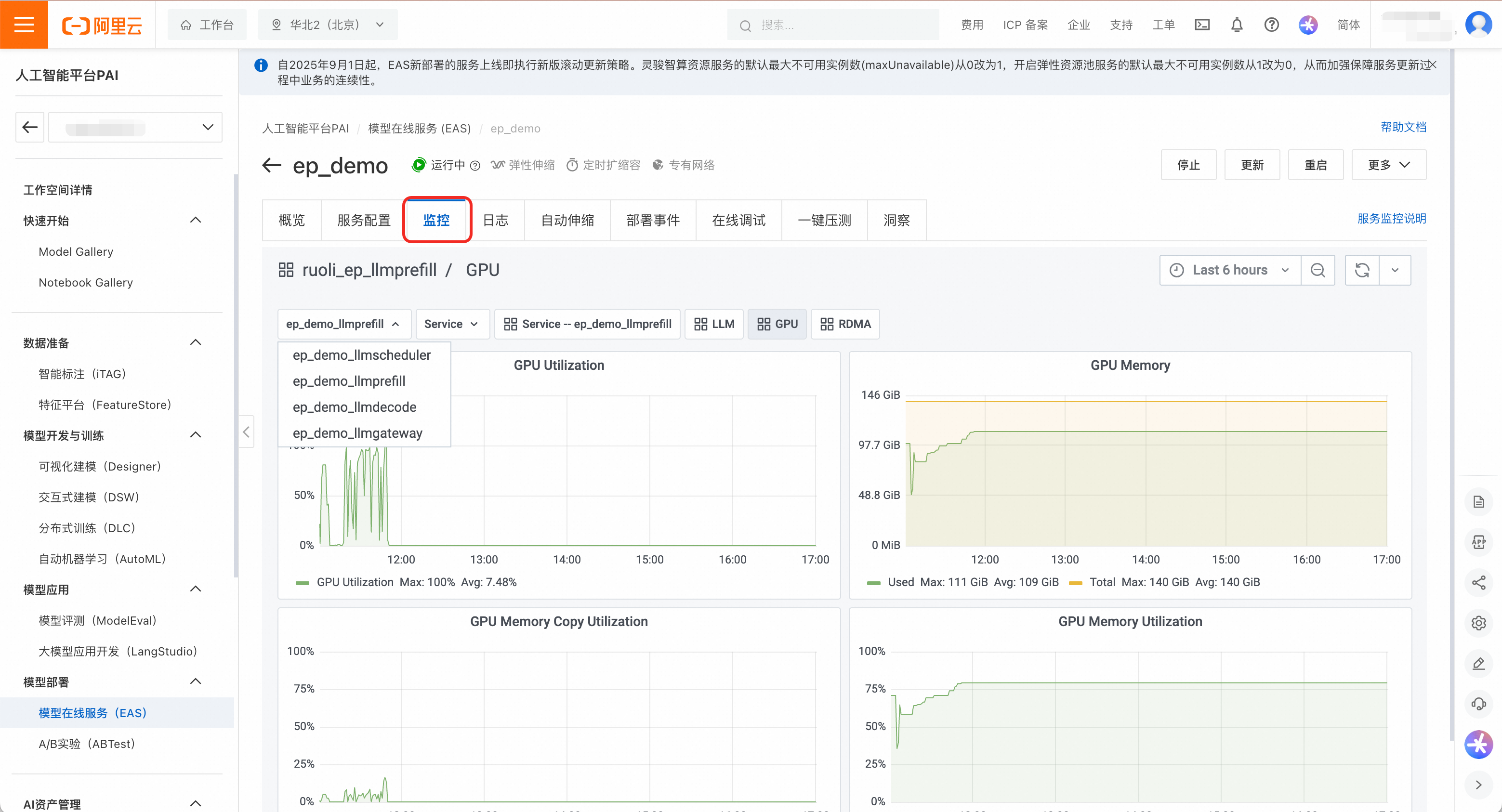
在服务列表页,点击服务名称进入详情页,可以对服务进行精细化管理。查看维度既包含整体服务(即聚合服务),也包含Prefill、Decode和LLM智能路由等子服务。
用户可以查看服务的监控和日志,以及配置自动伸缩策略。