
如果PyTorch大模型训练场景的任务运行失败,您可以使用EasyCkpt保存的最新的Checkpoint来重新运行任务,无需重复计算,减少时间和成本的浪费。EasyCkpt是PAI为PyTorch大模型训练场景而开发的高性能Checkpoint框架,通过实现接近0开销的模型保存机制,提供了大模型训练全过程进度无损的模型保存与恢复的能力。目前EasyCkpt支持当前流行的两种大模型训练框架Megatron和DeepSpeed,本文为您介绍EasyCkpt相关技术原理和接入操作。
背景信息
大模型训练面临的困难在于确保训练任务能够持续进行而不中断。在训练过程中,可能会遇到硬件故障、系统问题、连接错误、以及其他未知的问题。这种频繁中断导致的训练进度的损失对于耗时又耗资源的大模型训练来说是难以承受的。尽管可以通过做Checkpoint来保存和恢复进度,但Checkpoint本身的耗时与模型的大小成正比。对于当前典型的拥有百亿到千亿参数的大模型而言,Checkpoint的时间开销通常在几分钟到十几分钟之间。此时,训练任务需要暂停,使得用户难以频繁进行Checkpoint操作。然而,一旦发生中断,之前损失的迭代次数在恢复时需要重新计算,通常会花费数小时的时间。考虑到大模型使用的GPU规模,以1千卡为例,损失将会是数千个卡的时间。

因此,在发生故障时,迫切需要一种以低成本的方法来保存最新的Checkpoint。这样在重新启动训练时就无需重复计算,从而减少时间和成本的浪费。
功能介绍
针对频繁故障的情况,PAI通过之前的故障失败场景总结出以下GPU和深度学习场景故障的功能特点:
特点1:任务的故障是部分的。
通常,故障的根因是一到两台机器的故障,这只会影响部分Worker。对于大规模分布式训练任务而言,不会所有的Worker都出现故障。

特点2:机器的故障是部分的。
通过对众多故障失败案例的分析,对于训练集群而言:
GPU易损坏,但机器的CPU和内存通常仍可正常使用。
以节点为单位,内存的闲置空间很大(通常远大于模型状态)。
在节点上,通常很难出现所有网卡都损坏的情况,即使节点出现故障,它通常仍然具备通信能力。

特点3:模型的失败是部分的。
在大规模模型训练中通常采用3D并行或ZeRO系列优化,大多数任务的数据并行副本数大于1,这使得模型训练参数在多个副本上都有备份。因此,当某个GPU设备发生故障时,可以通过其他机器的GPU上保留的副本来实现恢复。
针对上述内容提到的大模型场景下Checkpoint的特点, PAI开发了EasyCkpt框架,该框架提供了高性能的Checkpoint功能。通过采用异步化层次化保存、重叠模型拷贝和计算、网络感知异步存储的策略, EasyCkpt实现了近0开销的模型保存机制和大模型训练全过程精度无损的模型保存与恢复的能力。EasyCkpt已经支持当前流行的两种大模型训练框架Megatron和DeepSpeed,您只需修改几行代码即可使用。
操作入口
安装AIMaster SDK
本功能依赖AIMaster SDK,其安装方式如下:
# py36
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp36-cp36m-linux_x86_64.whl
# py38
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp38-cp38-linux_x86_64.whl
# py310
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp310-cp310-linux_x86_64.whlMegatron
改动示例
在Megatron框架下的training.py文件中,只需修改4行代码: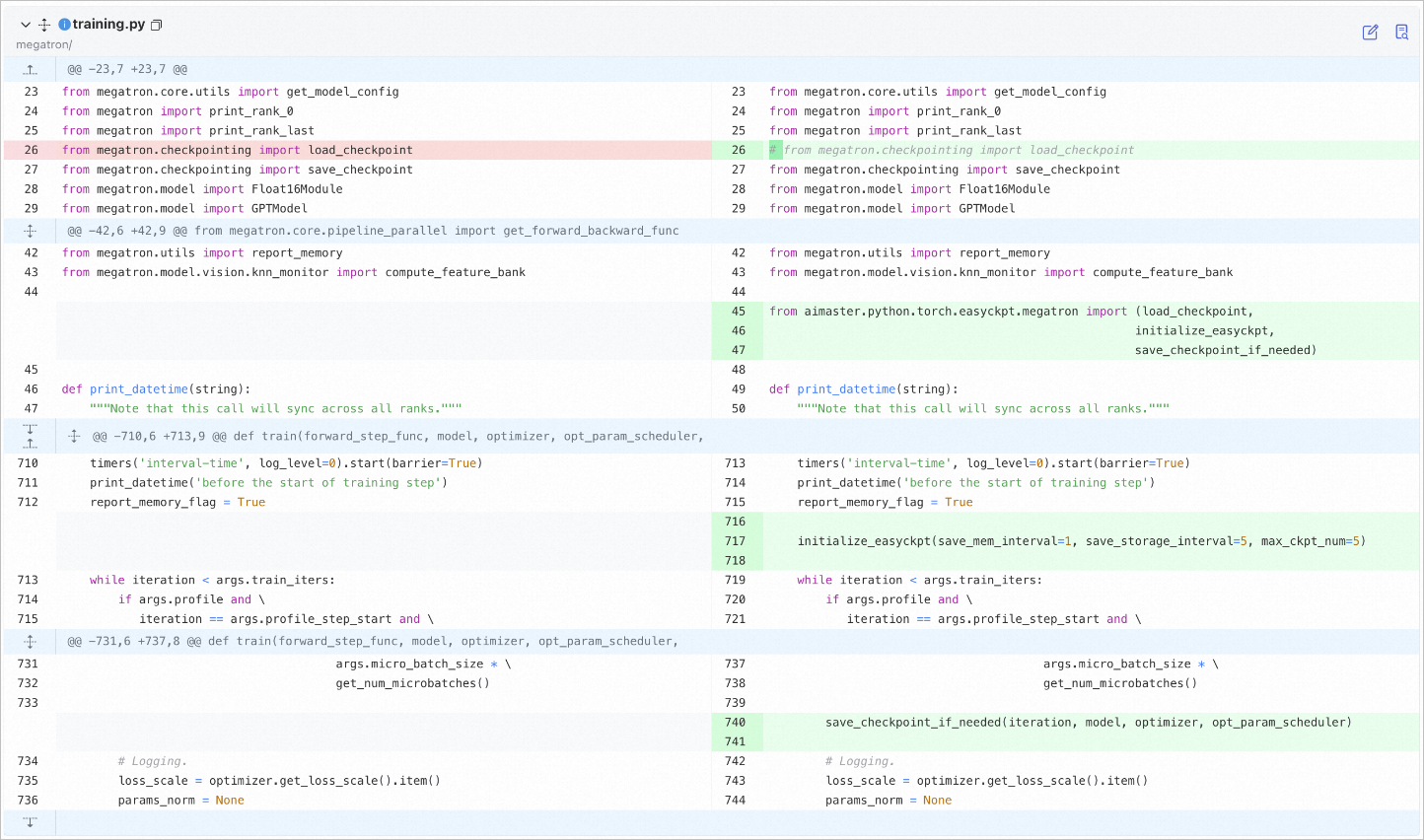
并在您的实际训练代码(以pretrain_gpt.py为例)里,import一行代码即可:

training.py文件修改后的代码如下:
from megatron.core.utils import get_model_config
from megatron import print_rank_0
from megatron import print_rank_last
# from megatron.checkpointing import load_checkpoint
from megatron.checkpointing import save_checkpoint
from megatron.model import Float16Module
from megatron.model import GPTModel
from megatron.utils import report_memory
from megatron.model.vision.knn_monitor import compute_feature_bank
from aimaster.python.torch.easyckpt.megatron import (load_checkpoint,
initialize_easyckpt,
save_checkpoint_if_needed)
def print_datetime(string):
"""Note that this call will sync across all ranks."""
timers('interval-time', log_level=0).start(barrier=True)
print_datetime('before the start of training step')
report_memory_flag = True
initialize_easyckpt(save_mem_interval=1, save_storage_interval=5, max_ckpt_num=5, log_file_path='./test.log')
while iteration < args.train_iters:
if args.profile and \
iteration == args.profile_step_start and \
args.micro_batch_size * \
get_num_microbatches()
save_checkpoint_if_needed(iteration, model, optimizer, opt_param_scheduler)
# Logging.
loss_scale = optimizer.get_loss_scale().item()
params_norm = None实际训练代码(以pretrain_gpt.py为例)修改后的代码如下:
from megatron.utils import average_losses_across_data_parallel_group
from megatron.arguments import core_transformer_config_from_args
import aimaster.python.torch.easyckpt.megatron.hook
def model_provider(pre_process=True, post_process=True):
"""Build the model."""接口详解
适用于Megatron的EasyCkpt框架提供了以下接口,其插入位置如上所示:
load_checkpoint(model, optimizer, opt_param_scheduler, load_arg='load', strict=True, concat=False):该接口在Megatron框架原生
load_checkpoint()函数签名基础上增加了concat参数,若您使用的是Megatron2304版本,只需平替掉Megatron的load_checkpoint即可;如果您使用2305或2306版本,请参考下面注意事项的描述。initialize_easyckpt(save_mem_interval, save_storage_interval, max_ckpt_num, log_file_path=None):该接口用于初始化Easyckpt框架。其中,通过save_mem_interval指定memory copy的频率,通过save_storage_interval指定异步存储到存储设备的频率,通过max_ckpt_num指定存储设备中最多保存的Checkpoints数目。若需要保存详尽log信息可指定log路径到log_file_path里。
save_checkpoint_if_needed(iteration, model, optimizer, opt_param_scheduler):该接口用于调用EasyCkpt框架进行内存中的Checkpoint操作,其中各参数均为Megatron代码内已有的变量名,您无需额外指定。
注意:如果您使用Megatron2305或2306的稳定版本,并且您开启了distributed-optimizer。那么,当您在load的时候需要改变机器数目,或是希望合并分布式优化器参数时,您需要在training.py文件里load_checkpoint()函数被调用处设置concat参数为True。


DeepSpeed
DeepSpeed的大模型用户通常使用Transformer的Trainer来启动DeepSpeed任务,EasyCkpt兼容了这种使用方法,最小化了所需要的改动。
改动示例
启动参数:适用于DeepSpeed的EasyCkpt框架复用了Transformer的Checkpoint参数来传递给DeepSpeed,这些参数的含义与Transformer中定义的一致,并且在接口详解中均有详细解释。当前配置示例表示每2个mini-batch保存一次Checkpoint,最多同时保留最近的两个持久化的Checkpoint副本。

修改后的代码如下(对应上图右侧):
--max_steps=10 \
--block_size=2048 \
--num_train_examples=100000 \
--gradient_checkpointing=false \
--save_strategy="steps" \
--save_steps="2" \
--save_total_limit="2"训练代码改动:Transformer的Trainer需要用EasyCkpt提供的TrainerWrapper进行包装,并打开resume_from_Checkpoint参数。
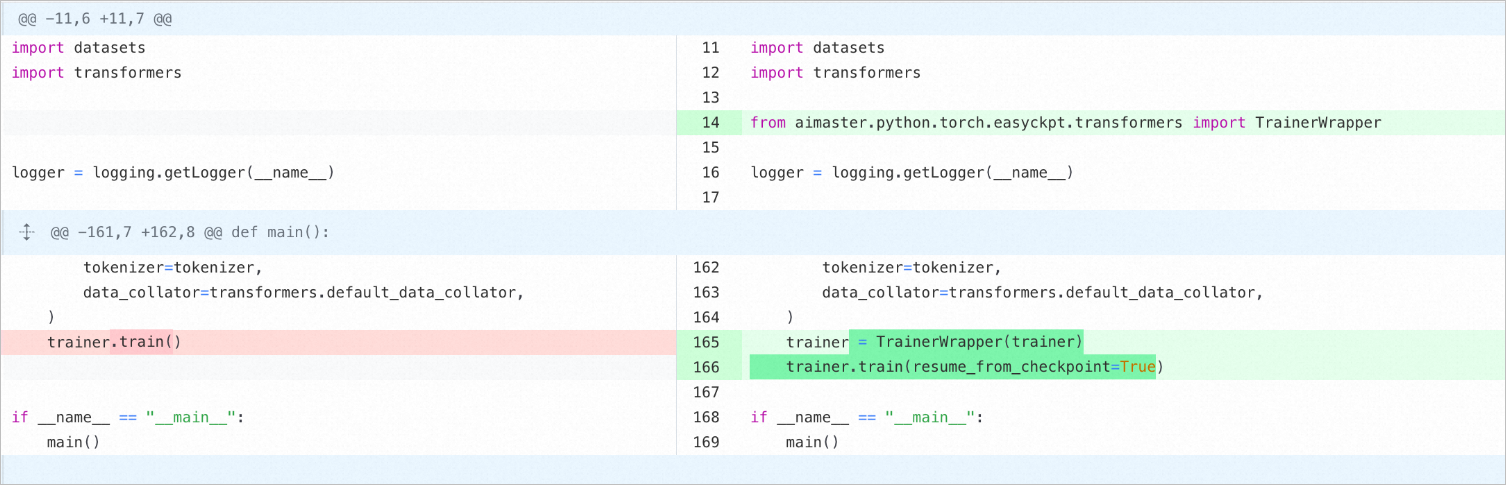
修改后的代码如下(对应上图右侧):
import datasets
import transformers
from aimaster.python.torch.easyckpt.transformers import TrainerWrapper
logger = logging.getLogger(__name__)
tokenizer=tokenizer,
data_collator=transformers.default_data_collator,
)
trainer = TrainerWrapper(trainer)
trainer.train(resume_from_checkpoint=True)
if __name__ = ""__main__":
main()接口详解
适用于DeepSpeed的EasyCkpt框架提供了以下接口,其插入位置如上所示:
save_strategy:训练过程中Checkpoint的保留方式。取值如下:
no: 训练期间不进行保存。
epoch:在每个epoch结束时进行保存。
steps:根据save_steps的设置进行保存。
save_steps:训练过程中每隔多少步保存一次Checkpoint,这里要求save_strategy必须是"steps"。
save_total_limit:最多保留多少个Checkpoint。
注意:按照Transformers官方文档,使用save_total_limit时会将过时的checkpoints文件夹删除掉,请确保过时的checkpoints文件夹是能够安全删除的。
数据安全须知
EasyCkpt需要在您提供的用户存储空间中读写数据,并且需要控制最大Checkpoint数量,可能引入删除数据的动作。为了确保您的数据安全,PAI在此定义了EasyCkpt涉及的所有读写动作,并给出EasyCkpt提供的数据安全保证以及推荐的用户使用方式。
EasyCkpt引入了以下读写动作,使用EasyCkpt即表示默认授权:
从load目录中读取Checkpoint数据,并在需要时将其拼接成新的checkpoint数据。
将checkpoints数据保存到save目录中,并在必要时根据功能设定删除save目录中具有Megatron或Transformers格式的checkpoint文件夹。
在此基础上,EasyCkpt提供以下保证:
不会对save和load目录以外的数据做任何操作。
EasyCkpt会以日志形式记录其进行的所有保存或删除的操作。
强烈建议您不要在模型的save或load文件路径下存放任何其他数据。这种设置不符合EasyCkpt的预期用法,可能影响EasyCkpt的软件能力。由此造成的数据风险和数据损失问题,使用者应自行承担责任。