快速开始预置了中文标题生成模型,您可以直接部署该模型。针对定制化场景,您也可以使用自己的数据集对模型进行微调训练。本文为您介绍如何在快速开始完成中文标题生成任务。
前提条件
已创建OSS Bucket存储空间,具体操作请参见控制台创建存储空间。
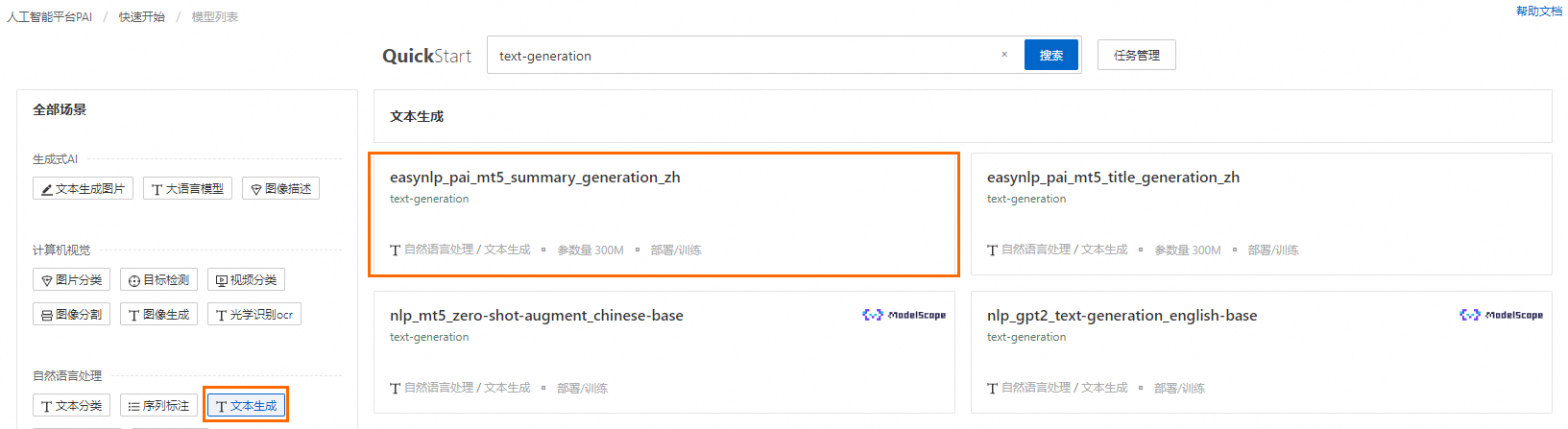
一、进入模型详情页面
进入快速开始页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在左侧导航栏单击快速开始,进入快速开始页面。
在快速开始首页,单击自然语言处理区域下的文本生成。在右侧的模型列表中,单击easynlp_pai_mt5_title_generation_zh模型卡片,进入模型详情页面。
二、直接部署和调试模型
部署模型服务
在模型详情页面,单击模型部署。
在模型部署详情页面,确认部署信息后,单击部署。
在计费提醒对话框中,单击确定。
页面将自动跳转到服务详情页面。您可以在基本信息区域查看服务状态。当状态变为运行中时,表明服务部署成功。
在线调试模型
通过控制台进行在线调试
在服务详情页面的在线预测文本框中输入请求数据,请求数据示例如下。
{ "data": ["在广州第一人民医院,一个上午6名患者做支气管镜检查,5人查出肺癌,且4人是老烟民!专家称,吸烟和被动吸烟是肺癌的主要元凶。"] }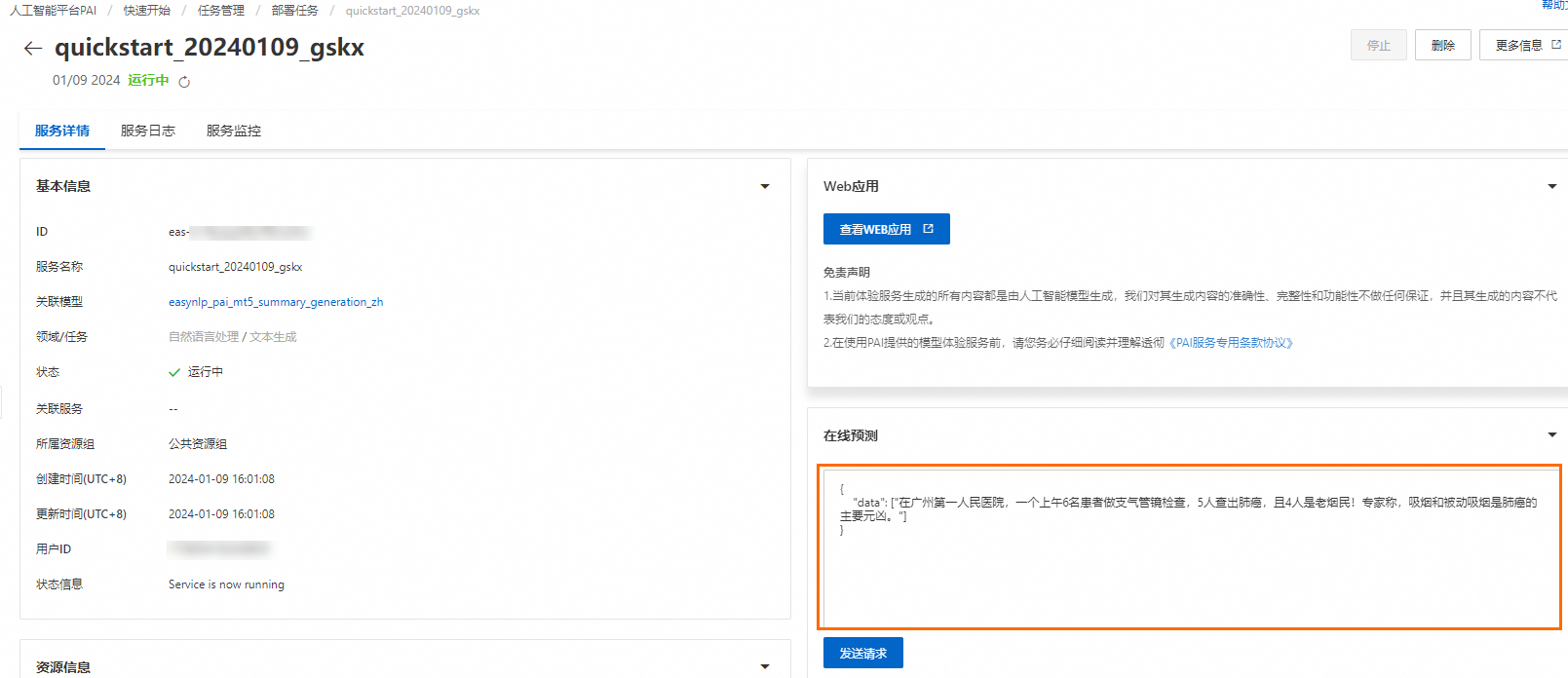
单击发送请求。
您可以在页面下方查看输出结果。
通过Python代码进行在线调试
查看服务的调用信息。
在服务详情页面的资源信息区域,单击查看调用信息。
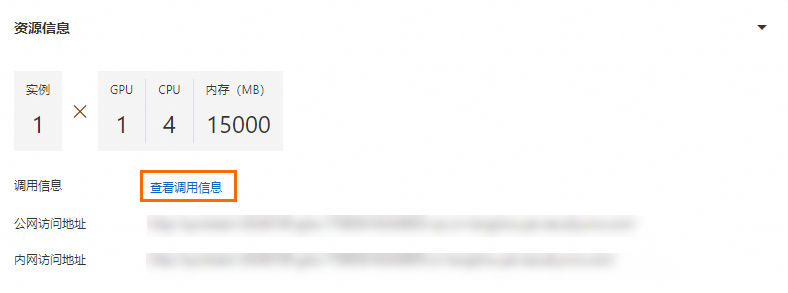
在调用信息对话框的公网地址调用页签中,查看访问地址和Token,并保存到本地。
使用以下示例代码发送服务请求。
import requests url = "<PredictionServiceEndpoint>" token = "<PredictionServiceAccessToken>" request_body = '{"data": ["在广州第一人民医院,一个上午6名患者做支气管镜检查,5人查出肺癌,且4人是老烟民!专家称,吸烟和被动吸烟是肺癌的主要元凶。"]}' request_body = request_body.encode('utf-8') headers = {"Authorization": token} resp = requests.post(url=url, headers=headers, data=request_body) print(resp.content.decode()) print("status code:", resp.status_code)其中:url和token需要分别配置为上述步骤中保存到本地的访问地址和Token。
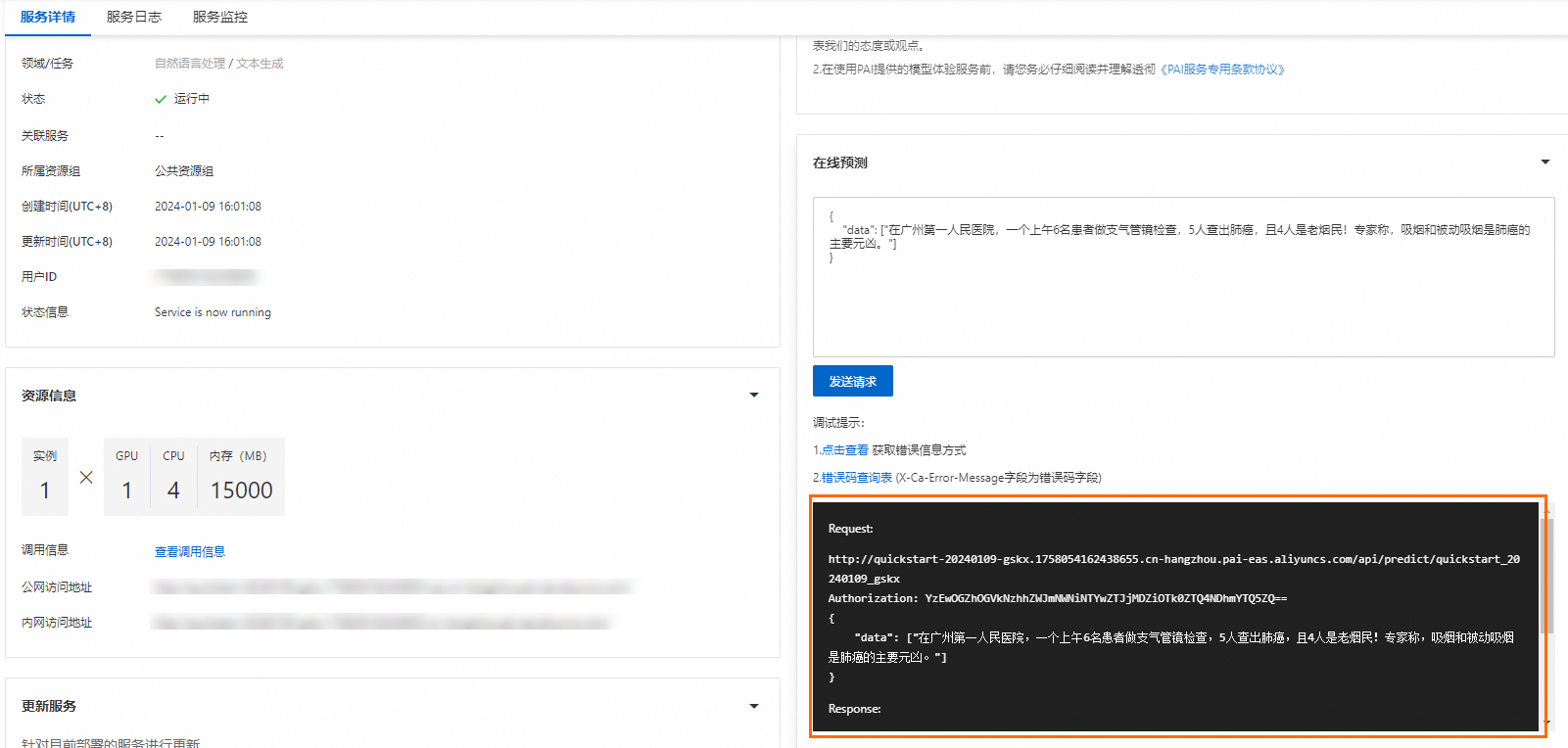
系统返回结果如下图所示。

三、微调训练模型
(可选)准备数据集。
说明如果您希望使用自己的数据来微调训练模型,可以按照以下操作步骤来准备训练数据集。
快速开始提供了训练数据集。您可以使用默认数据集,也可以自己准备数据。训练数据格式为:
{"text": "<text>", "summary": "summary"} {"text": "<text>", "summary": "summary"} {"text": "<text>", "summary": "summary"} ...... {"text": "<text>", "summary": "summary"}将已准备的数据上传到OSS存储空间,具体操作,请参见控制台上传文件。
提交训练作业。
返回模型详情页面,具体操作,请参见一、进入模型详情页面。
在模型训练区域,将训练设置>输出路径配置为OSS Bucket路径,并单击训练。本示例使用默认数据集进行模型微调训练。
说明如果您准备了训练数据集,在模型训练区域,参照微调训练模型操作步骤更新训练数据集后,再单击训练。
页面将自动跳转到任务详情页面。您可以单击任务日志,查看训练过程。
四、部署和调试微调后的模型
在任务详情页面模型部署区域,单击部署。
页面自动跳转到服务详情页面,您可以在基本信息区域查看模型服务部署状态。当状态变为运行中时,表明模型服务已成功部署。
在线调试模型,具体操作,请参见在线调试模型。
- 本页导读 (1)