
DLC支持将对象存储OSS类型的数据集挂载到容器的指定路径,方便您在训练过程中直接读写存储在OSS中的数据。本文为您介绍如何在DLC训练任务中挂载OSS类型的数据集。
前提条件
已开通PAI(DLC)并创建工作空间。具体操作,请参见开通PAI并创建默认工作空间。
已创建OSS存储空间(Bucket),详情请参见控制台快速入门。
当使用SDK实现高级配置时,您需要配置环境变量。具体操作,请参见安装Credentials工具和配置环境变量。
使用限制
当前DLC底层使用JindoFuse来挂载OSS。挂载OSS时,使用DLC的默认配置有如下限制,并不适合所有的场景。您可以通过调整参数,来适配具体的场景,详情请参见附录:高级配置。
为了快速读取OSS文件,挂载OSS时会有元数据(目录与文件列表)的缓存。
在分布式任务中,如果有多个节点需要创建同一个目录并检查目录是否存在,元数据的Cache会导致每个节点都尝试进行创建。实际只有一个节点能成功创建目录,其它节点会报错。
默认使用OSS的MultiPart API来创建文件,在写文件的过程中,在OSS上看不到该对象。当所有写操作完成后,才能在OSS页面上查看。
不支持同时进行文件的写入和读取操作。
不支持对文件进行随机写入操作。
步骤一:创建OSS数据集
在工作空间中创建OSS数据集,其中关键参数配置说明如下,其他参数配置详情,请参见创建及管理数据集。
参数
描述
创建方式
选择从阿里云云产品。
选择数据存储
选择对象存储(OSS)。
属性
选择文件夹。
从阿里云云存储创建
选择OSS Bucket存储目录。
默认挂载路径
数据的默认挂载路径,默认为
/mnt/data/。当执行DLC任务时,系统会按照该存储目录查找所需文件。在数据集页面,单击目标数据集名称,查看数据集详情。
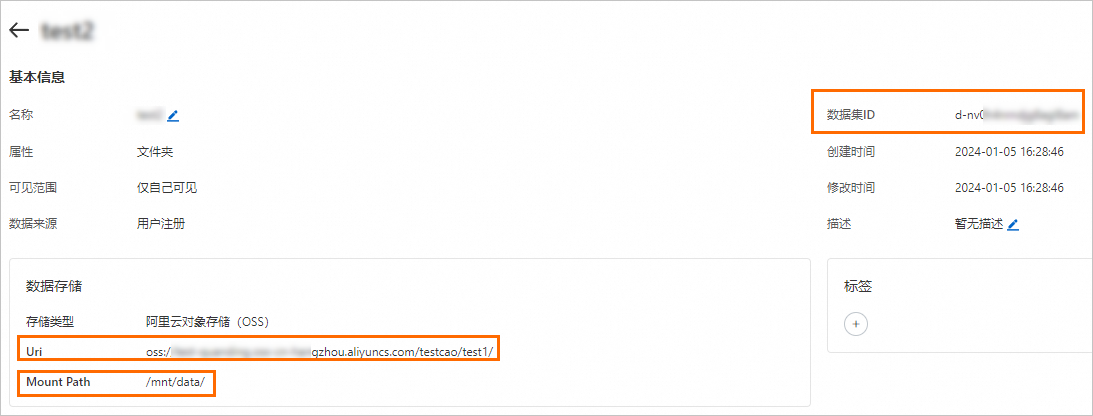
其中:
数据集ID:使用DLC命令行工具或SDK提交训练任务时,需要使用数据集ID来绑定该数据集。详情请参见创建训练任务。
Uri:关联的OSS Bucket存储目录。格式为
oss://<OSS-Bucket>.<OSS-Endpoint>/<OSS-Path>。Mount Path:表示在DLC中挂载的本地路径。
步骤二:创建DLC训练任务
您可以在创建DLC训练任务时,绑定OSS数据集。其中关键参数配置如下,其他参数配置说明,请参见创建训练任务。
在环境信息区域的挂载配置中,挂载类型选择自定义数据集,并配置以下两个参数:
数据集:单击
 ,选择已创建的对象存储OSS类型的数据集。
,选择已创建的对象存储OSS类型的数据集。挂载路径:自动关联对象存储OSS数据集中配置的挂载路径。当执行DLC任务时,系统会按照该路径来访问OSS中的数据。
挂载OSS数据集时,使用DLC的默认配置不适合所有的场景。您可以通过调整参数,来适配具体的场景,详情请参见附录:高级配置。
附录:高级配置
目前,PAI控制台页面不提供对JindoFuse底层参数的配置选项,您需要使用SDK来修改底层参数。以下是修改参数的示例,供您参考。
使用SDK时,您需要配置环境变量。具体操作,请参见安装Credentials工具和配置环境变量。
准备工作:安装工作空间的SDK
!pip install alibabacloud-aiworkspace20210204如何关掉元数据Cache
当执行分布式任务且多个节点同时尝试向同一目录写文件时,Cache可能会引起部分节点的写入操作失败。您可以通过修改fuse的命令行参数,增加-oattr_timeout=0-oentry_timeout=0-onegative_timeout=0来解决该问题。示例代码如下。
import json
from alibabacloud_tea_openapi.models import Config
from alibabacloud_credentials.client import Client as CredClient
from alibabacloud_aiworkspace20210204.client import Client as AIWorkspaceClient
from alibabacloud_aiworkspace20210204.models import UpdateDatasetRequest
def turnOffMetaCache():
region_id = 'cn-hangzhou'
# 阿里云账号AccessKey拥有所有API的访问权限,建议您使用RAM用户进行API访问或日常运维。
# 强烈建议不要把AccessKey ID和AccessKey Secret保存到工程代码里,否则可能导致AccessKey泄露,威胁您账号下所有资源的安全。
# 本示例通过Credentials SDK默认从环境变量中读取AccessKey,来实现身份验证。您需要先安装Credentials工具和配置环境变量。
cred = CredClient()
dataset_id = '** 数据集的ID **'
workspace_client = AIWorkspaceClient(
config=Config(
credential=cred,
region_id=region_id,
endpoint="aiworkspace.{}.aliyuncs.com".format(region_id),
)
)
# 1、get the content of dataset
get_dataset_resp = workspace_client.get_dataset(dataset_id)
options = json.loads(get_dataset_resp.body.options)
options['fs.jindo.args'] = '-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0'
update_request = UpdateDatasetRequest(
options=json.dumps(options)
)
# 2、update options
workspace_client.update_dataset(dataset_id, update_request)
print('new options is: {}'.format(update_request.options))
turnOffMetaCache()
如何调整上传(下载)数据的线程数目
通过配置以下参数来调整线程数据:
fs.oss.upload.thread.concurrency:32fs.oss.download.thread.concurrency:32fs.oss.read.readahead.buffer.count:64fs.oss.read.readahead.buffer.size:4194304
示例代码如下:
import json
from alibabacloud_tea_openapi.models import Config
from alibabacloud_credentials.client import Client as CredClient
from alibabacloud_aiworkspace20210204.client import Client as AIWorkspaceClient
from alibabacloud_aiworkspace20210204.models import UpdateDatasetRequest
def adjustThreadNum():
# 使用DLC任务所在地域。例如华东1(杭州)配置为cn-hangzhou。
region_id = 'cn-hangzhou'
# 阿里云账号AccessKey拥有所有API的访问权限,建议您使用RAM用户进行API访问或日常运维。
# 强烈建议不要把AccessKey ID和AccessKey Secret保存到工程代码里,否则可能导致AccessKey泄露,威胁您账号下所有资源的安全。
# 本示例通过Credentials SDK默认从环境变量中读取AccessKey,来实现身份验证。您需要先安装Credentials工具和配置环境变量。
cred = CredClient()
dataset_id = '** 数据集的ID **'
workspace_client = AIWorkspaceClient(
config=Config(
credential=cred,
region_id=region_id,
endpoint="aiworkspace.{}.aliyuncs.com".format(region_id),
)
)
# 1、get the content of dataset
get_dataset_resp = workspace_client.get_dataset(dataset_id)
options = json.loads(get_dataset_resp.body.options)
options['fs.oss.upload.thread.concurrency'] = 32
options['fs.oss.download.thread.concurrency'] = 32
options['fs.oss.read.readahead.buffer.count'] = 32
update_request = UpdateDatasetRequest(
options=json.dumps(options)
)
# 2、update options
workspace_client.update_dataset(dataset_id, update_request)
print('new options is: {}'.format(update_request.options))
adjustThreadNum()
如何使用AppendObject方式挂载OSS文件
所有在本地创建的文件,都会使用OSS的AppendObject接口来创建Object。通过AppendObject方式最后生成的Object大小不得超过5 GB,关于AppendObject的更多使用限制,请参见AppendObject。示例代码如下:
import json
from alibabacloud_tea_openapi.models import Config
from alibabacloud_credentials.client import Client as CredClient
from alibabacloud_aiworkspace20210204.client import Client as AIWorkspaceClient
from alibabacloud_aiworkspace20210204.models import UpdateDatasetRequest
def useAppendObject():
# 使用DLC任务所在地域。例如华东1(杭州)配置为cn-hangzhou。
region_id = 'cn-hangzhou'
# 阿里云账号AccessKey拥有所有API的访问权限,建议您使用RAM用户进行API访问或日常运维。
# 强烈建议不要把AccessKey ID和AccessKey Secret保存到工程代码里,否则可能导致AccessKey泄露,威胁您账号下所有资源的安全。
# 本示例通过Credentials SDK默认从环境变量中读取AccessKey,来实现身份验证。您需要先安装Credentials工具和配置环境变量。
cred = CredClient()
dataset_id = '** 数据集的ID **'
workspace_client = AIWorkspaceClient(
config=Config(
credential=cred,
region_id=region_id,
endpoint="aiworkspace.{}.aliyuncs.com".format(region_id),
)
)
# 1、get the content of dataset
get_dataset_resp = workspace_client.get_dataset(dataset_id)
options = json.loads(get_dataset_resp.body.options)
options['fs.jindo.args'] = '-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0'
options['fs.oss.append.enable'] = "true"
options['fs.oss.flush.interval.millisecond'] = "1000"
options['fs.oss.read.buffer.size'] = "262144"
options['fs.oss.write.buffer.size'] = "262144"
update_request = UpdateDatasetRequest(
options=json.dumps(options)
)
# 2、update options
workspace_client.update_dataset(dataset_id, update_request)
print('new options is: {}'.format(update_request.options))
useAppendObject()如何挂载OSS-HDFS
如何开通OSS-HDFS,请参见什么是OSS-HDFS服务。使用OSS-HDFS的Endpoint来创建数据集的示例代码如下:
import json
from alibabacloud_tea_openapi.models import Config
from alibabacloud_credentials.client import Client as CredClient
from alibabacloud_aiworkspace20210204.client import Client as AIWorkspaceClient
from alibabacloud_aiworkspace20210204.models import CreateDatasetRequest
def createOssHdfsDataset():
# 使用DLC任务所在地域。例如华东1(杭州)配置为cn-hangzhou。
region_id = 'cn-hangzhou'
# 阿里云账号AccessKey拥有所有API的访问权限,建议您使用RAM用户进行API访问或日常运维。
# 强烈建议不要把AccessKey ID和AccessKey Secret保存到工程代码里,否则可能导致AccessKey泄露,威胁您账号下所有资源的安全。
# 本示例通过Credentials SDK默认从环境变量中读取AccessKey,来实现身份验证。您需要先安装Credentials工具和配置环境变量。
cred = CredClient()
workspace_id = '** DLC任务所在工作空间ID **'
oss_bucket = '** OSS-Bucket **'
# 使用OSS-HDFS的Endpoint。
oss_endpoint = f'{region_id}.oss-dls.aliyuncs.com'
# 需要挂载的OSS-HDFS路径。
oss_path = '/'
# 本地挂载路径。
mount_path = '/mnt/data/'
workspace_client = AIWorkspaceClient(
config=Config(
credential=cred,
region_id=region_id,
endpoint="aiworkspace.{}.aliyuncs.com".format(region_id),
)
)
response = workspace_client.create_dataset(CreateDatasetRequest(
workspace_id=workspace_id,
name="** 数据集的名字 **",
data_type='COMMON',
data_source_type='OSS',
property='DIRECTORY',
uri=f'oss://{oss_bucket}.{oss_endpoint}{oss_path}',
accessibility='PRIVATE',
source_type='USER',
options=json.dumps({
'mountPath': mount_path,
# 在分布式训练的场景下建议增加以下参数。
'fs.jindo.args': '-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0 -ono_symlink -ono_xattr -ono_flock -odirect_io',
'fs.oss.flush.interval.millisecond': "10000",
'fs.oss.randomwrite.sync.interval.millisecond': "10000",
})
))
print(f'datasetId: {response.body.dataset_id}')
createOssHdfsDataset()
如何配置内存资源
通过配置fs.jindo.fuse.pod.mem.limit参数来调整内存资源,示例代码如下:
import json
from alibabacloud_tea_openapi.models import Config
from alibabacloud_credentials.client import Client as CredClient
from alibabacloud_aiworkspace20210204.client import Client as AIWorkspaceClient
from alibabacloud_aiworkspace20210204.models import UpdateDatasetRequest
def adjustResource():
# 使用DLC任务所在地域。例如华东1(杭州)配置为cn-hangzhou。
region_id = 'cn-hangzhou'
# 阿里云账号AccessKey拥有所有API的访问权限,建议您使用RAM用户进行API访问或日常运维。
# 强烈建议不要把AccessKey ID和AccessKey Secret保存到工程代码里,否则可能导致AccessKey泄露,威胁您账号下所有资源的安全。
# 本示例通过Credentials SDK默认从环境变量中读取AccessKey,来实现身份验证。您需要先安装Credentials工具和配置环境变量。
cred = CredClient()
dataset_id = '** 数据集的ID **'
workspace_client = AIWorkspaceClient(
config=Config(
credential=cred,
region_id=region_id,
endpoint="aiworkspace.{}.aliyuncs.com".format(region_id),
)
)
# 1、get the content of dataset
get_dataset_resp = workspace_client.get_dataset(dataset_id)
options = json.loads(get_dataset_resp.body.options)
# 需要配置的内存资源。
options['fs.jindo.fuse.pod.mem.limit'] = "10Gi"
update_request = UpdateDatasetRequest(
options=json.dumps(options)
)
# 2、update options
workspace_client.update_dataset(dataset_id, update_request)
print('new options is: {}'.format(update_request.options))
adjustResource()