
1. 概述
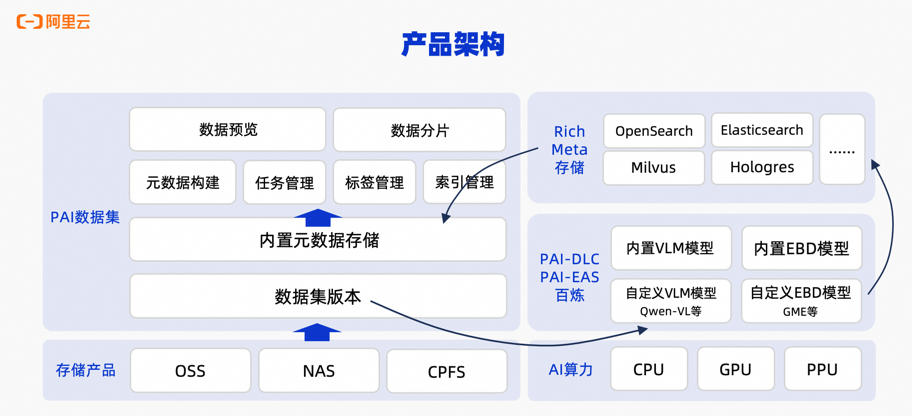
多模态数据管理针对图片等多模态数据,可通过多模态大模型、Embedding模型等进行预处理(智能打标、语义索引),形成丰富的元数据。借助这些元数据,支持对多模态数据进行搜索、筛选等操作,便于快速挖掘特定场景的数据子集,用于进一步的数据标注、训练等流程。同时,PAI数据集还开放了全套OpenAPI,便于在自建平台中集成。产品架构如下图所示:
2. 使用限制
当前PAI多模态数据管理有如下使用限制:
-
使用地域:当前支持杭州、上海、深圳、乌兰察布、北京、广州、新加坡、德国、美国(弗吉尼亚)、中国香港、东京、雅加达、广州、美国(硅谷)、吉隆坡、首尔地域。
-
存储类型:当前仅支持在OSS对象存储中使用PAI多模态数据管理。
-
文件类型:当前仅支持图片类型文件,支持文件格式:jpg、 jpeg、png、gif、bmp、tiff、webp。
-
文件数量:支持单个数据集版本最大1,000,000个文件,如有特殊需求可联系PAI PDSA扩容。
-
使用模型:
-
打标模型:支持使用百炼平台-Qwen VL Max/Plus模型。
-
索引模型:支持使用百炼多模态Embedding模型(如tongyi-embedding-vision-plus),以及PAI Model Gallery的GME模型作为索引模型,部署至PAI-EAS使用。
-
-
元信息存储:
-
元数据:元数据安全存储于PAI内置的元数据库。
-
Embedding向量:支持存储于下列自定义向量数据库中:
-
Elasticsearch(向量增强版,8.17.0版本及以上)
-
OpenSearch(向量检索版)
-
Milvus(2.4及以上版本)
-
Hologres(4.0.9以上版本)
-
Lindorm(向量引擎版本)
-
-
-
数据集处理模式:目前支持全量模式和增量模式运行智能打标任务及语义索引任务。
3. 使用流程
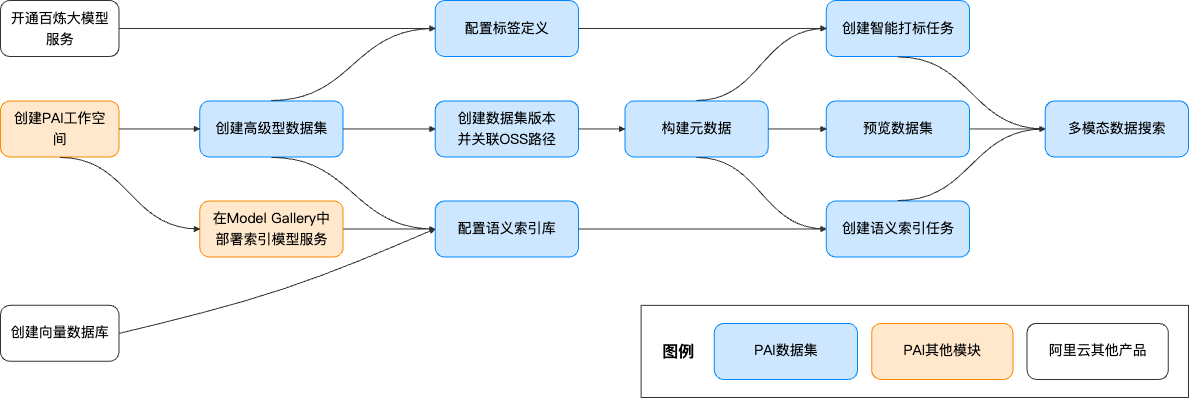
3.1 前置准备
3.1.1 开通PAI,创建默认工作空间并获取空间管理员权限
3.1.2 开通百炼并创建API-KEY
开通阿里云百炼并创建API-KEY,请参考获取API-KEY。
3.1.3 创建向量数据库
创建向量数据库实例
多模态数据集管理目前支持以下几种阿里云向量数据库:
-
Elasticsearch(向量增强版,8.17.0版本及以上)
-
OpenSearch(向量检索版)
-
Milvus(2.4及以上版本)
-
Hologres(4.0.9以上版本)
-
Lindorm(向量引擎版本)
各个云向量数据库实例创建请参考对应云产品文档。
网络配置以及白名单配置
-
公网方式
若向量库实例开通了公网地址,将下面的IP列表添加到实例的公网访问白名单地址列表后,多模态数据管理服务即可通过公网访问此实例。Elasticsearch白名单设置请参见配置实例公网或私网访问白名单。
地域
IP列表
杭州
47.110.230.142、47.98.189.92
上海
47.117.86.159、106.14.192.90
深圳
47.106.88.217、39.108.12.110
乌兰察布
8.130.24.177、8.130.82.15
北京
39.107.234.20、182.92.58.94
-
私网方式
请提交工单申请。
创建向量索引表(可选)
系统提供自动创建索引表功能,如果您无需自定义创建索引表,可跳过此步骤。
在某些向量数据库中,向量索引表也称为Collection或Index。
索引表结构定义(表结构必须遵循如下定义):
本文中以Elasticsearch为例通过Python创建语义索引表(其他类型向量数据库索引表的创建请参考对应云产品使用文档)。示例代码如下:
3.2 创建数据集
-
进入PAI工作空间,在左侧菜单栏单击AI资产管理 > 数据集 > 新建数据集,进入数据集配置页面。

-
配置数据集参数,关键参数如下,其他参数默认即可。
-
存储类型:对象存储(OSS);
-
类型:高级型;
-
内容类型:图片;
-
OSS路径:选择数据集的OSS存储路径。如果您没有准备数据集,可以下载示例数据集retrieval_demo_data,并上传至OSS,体验多模态数据管理功能。
说明此处导入文件/文件夹,仅在系统记录中设置了路径,不会复制数据。
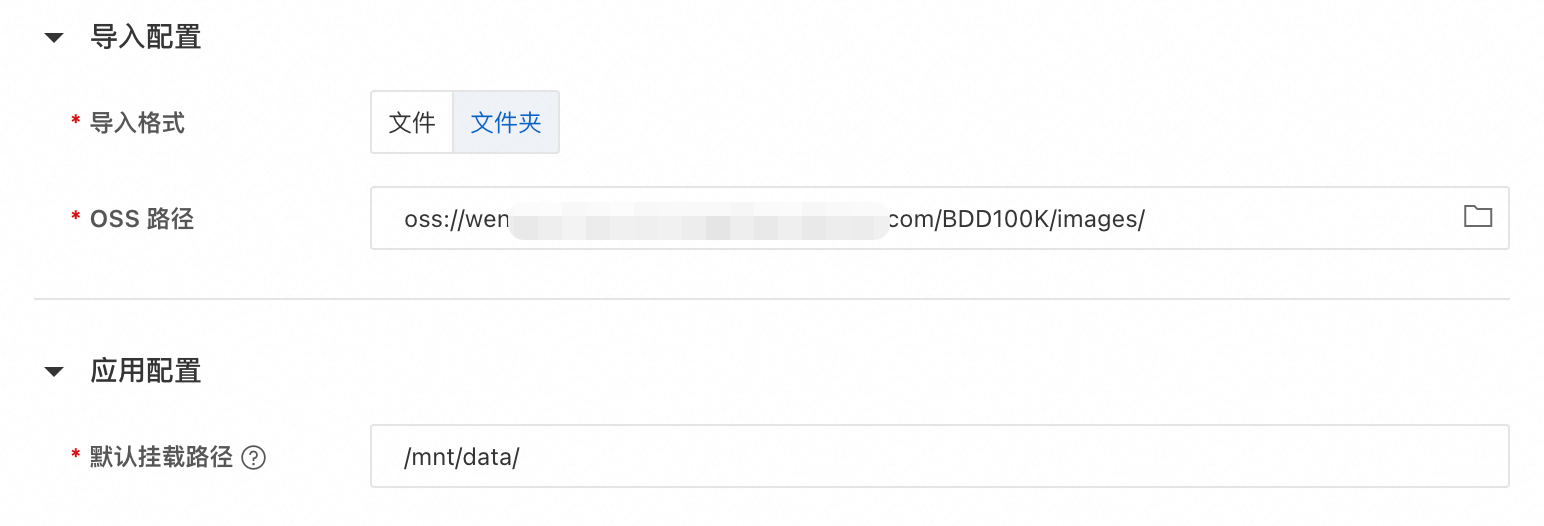
然后单击确定,创建数据集。
-
3.3 创建连接
3.3.1 创建智能打标模型连接
-
进入PAI工作空间,在左侧菜单栏单击AI资产管理 > 连接 > 模型服务 > 新建连接,打开新建连接页面。

-
选择百炼大模型服务,并配置百炼api_key。

-
创建成功后,在列表页可以看到创建的百炼大模型服务。


3.3.2 创建语义索引模型连接
-
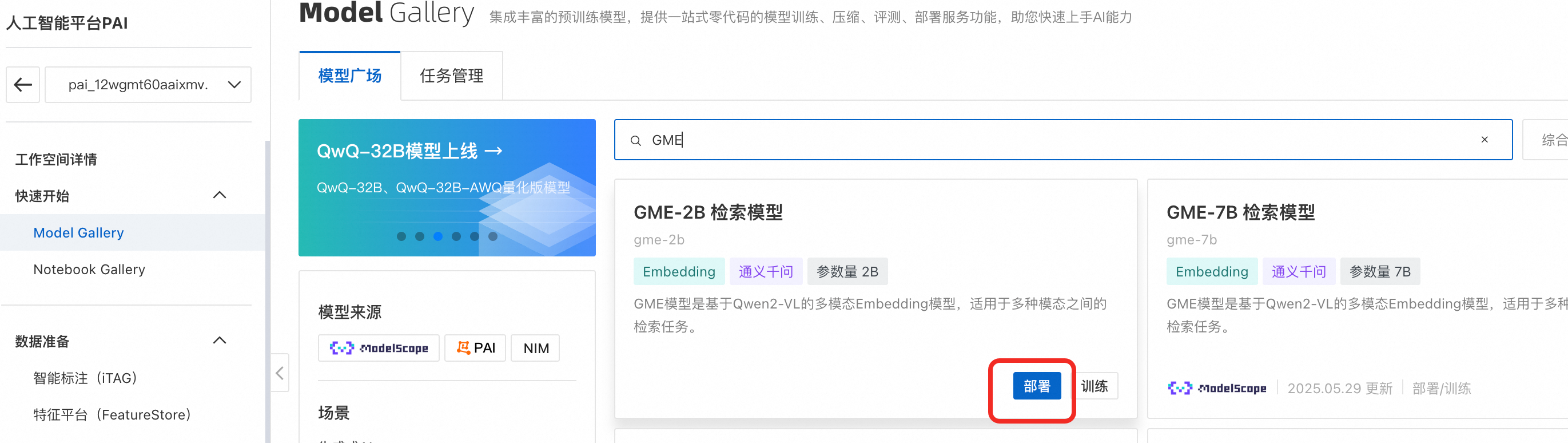
如果您需要使用百炼语义索引模型服务可跳过此步骤。在左侧菜单栏单击Model Gallery,找到并部署GME多模态检索模型,得到一个EAS服务。部署大约需要5分钟,当处于运行中时,代表部署成功。
重要当您不需要使用该索引模型时,可停止和删除该服务,以免继续产生费用。
-
进入PAI工作空间,在左侧菜单栏单击AI资产管理 > 连接 > 模型服务 > 新建连接,打开新建连接页面。
-
根据您选择百炼的语义索引模型还是自定义部署的EAS语义索引模型,配置模型连接信息。
使用百炼语义索引模型
-
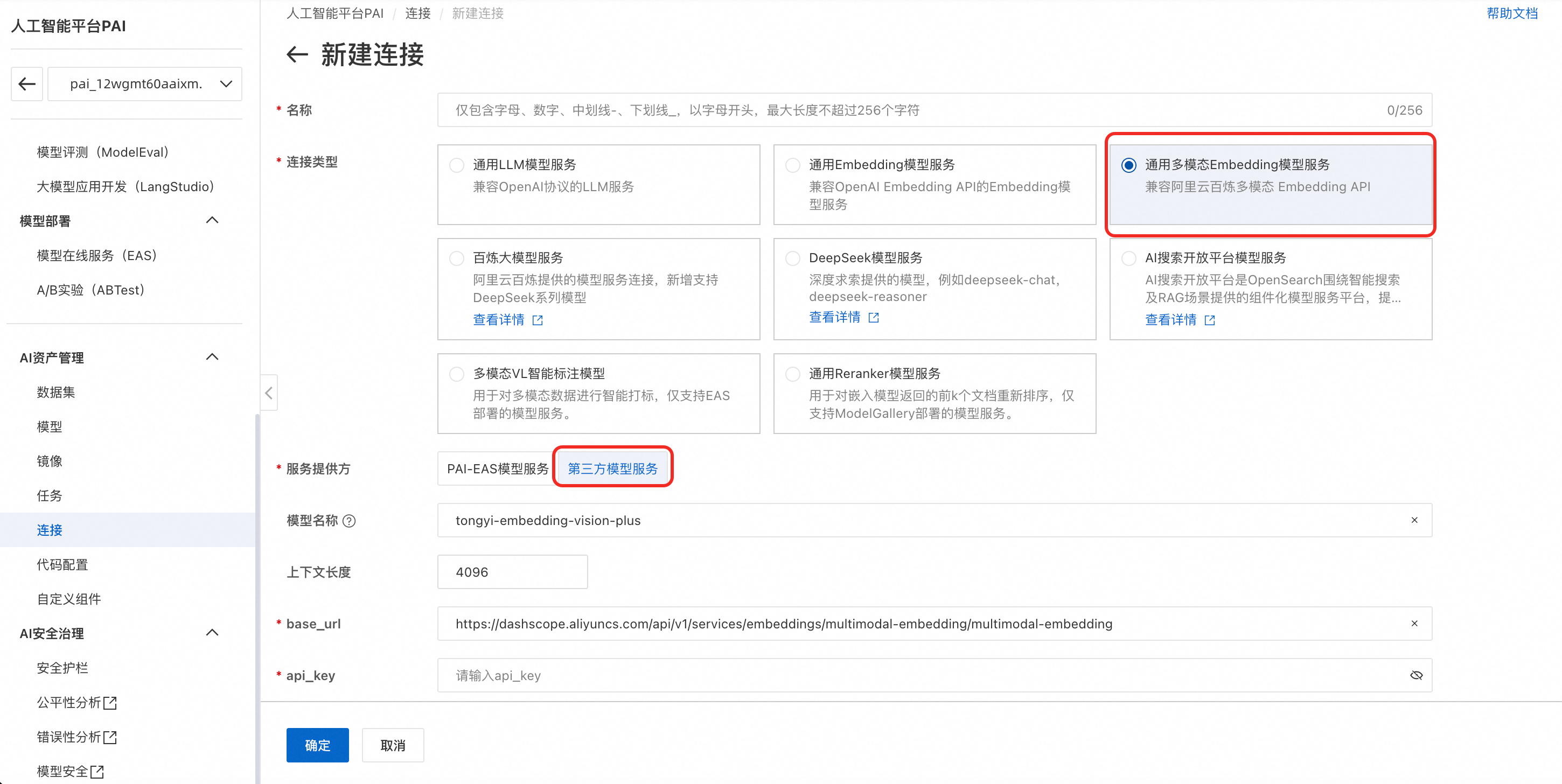
连接类型:选择通用多模态Embedding模型服务。
-
服务提供方:选择第三方服务模型。
-
模型名称:tongyi-embedding-vision-plus。
-
base_url:
https://dashscope.aliyuncs.com/api/v1/services/embeddings/multimodal-embedding/multimodal-embedding -
api_key:获取API-KEY并填写。
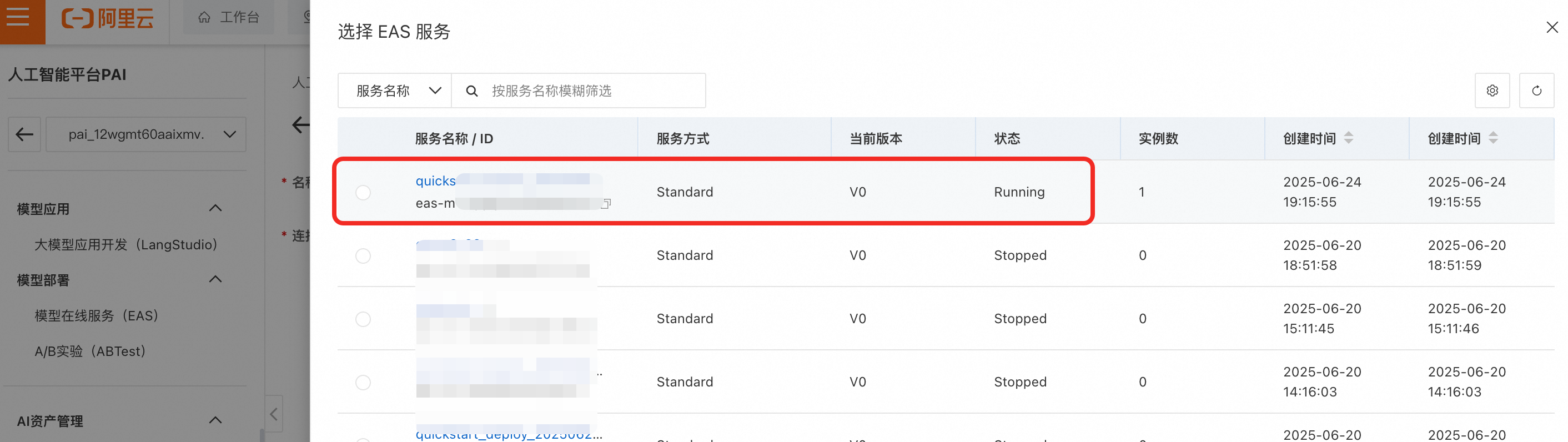
使用自定义部署的EAS语义索引模型
-
连接类型:选择通用多模态Embedding模型服务。
-
服务提供方:选择PAI-EAS模型服务。
-
EAS服务:选择刚部署的GME多模态检索模型。服务提供方如果不在当前账号下,可选择第三方模型服务。
-
-
创建成功后,在列表页可以看到创建的模型连接服务。


3.3.3 创建向量数据库连接
-
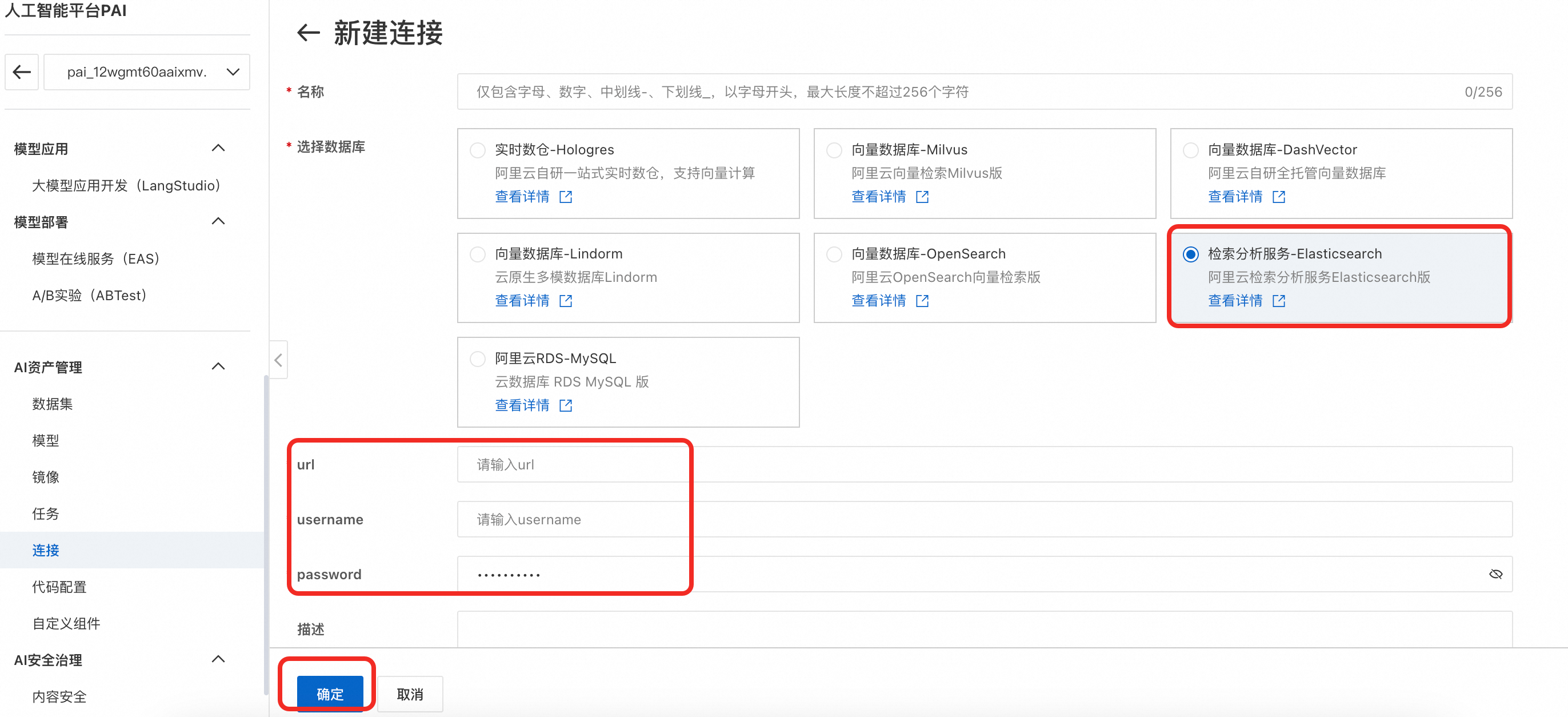
在左侧菜单栏单击AI资产管理 > 连接 > 数据库 > 新建连接,打开新建连接页面。
-
多模态检索服务支持 Milvus/Lindorm/OpenSearch/Elasticsearch/Hogress 向量数据库,这里以Elasticsearch为例创建连接。选择检索分析服务-Elasticsearch,配置uri、username、password等信息,详细配置请参见创建数据库连接。
各向量数据库链接格式参考:
Milvus
uri: http://xxx.milvus.aliyuncs.com:19530 database: {your_data_base} token: root:{password}OpenSearch
uri: http://xxxx.ha.aliyuncs.com username: {username} password: {password}Hologres
host: xxxx.hologres.aliyuncs.com database: {your_data_base} port: {port} access_key_id={password}Elasticsearch
uri: http://xxxx.elasticsearch.aliyuncs.com:9200 username: {username} password: {password}Lindorm
uri: xxxx.lindorm.aliyuncs.com:{port} username: {username} password: root:{password} -
创建成功后,在列表页可以看到创建的向量数据库连接。


3.4 创建智能打标任务
3.4.1 创建智能标签定义
在左侧菜单栏单击AI资产管理 > 数据集 > 智能标签定义 > 新建智能标签定义,打开标签配置页面,配置示例如下:
-
引导提示词:作为一个拥有多年驾驶经验的老司机,你有着非常丰富的高速以及城市道路驾驶经验。
-
标签定义:
3.4.2 创建智能打标离线任务
-
单击自定义数据集,单击数据集名称进入详情页面,然后再单击数据集任务。
-
进入任务页面,单击新建任务 > 智能打标,并配置任务参数。
-
数据集版本:选择需要打标的版本如v1。
-
智能打标模型连接:选择创建的百炼模型连接。
-
智能打标模型:支持千问VL-MAX和千问VL-Plus。
-
最大并发数:最大并发数根据EAS模型服务规格配置,单卡建议最大并发为5。
-
智能标签定义:选择刚创建的智能标签定义。
-
打标模式:支持增量打标和全量打标。
-
-
智能打标任务创建成功后,在任务列表可以看到创建的打标任务。观察启动的智能打标任务,可点击列表右侧链接查看日志或停止打标任务。
说明首次启动智能打标任务,将进行元数据的构建,所需时间可能较长,请耐心等待。


3.5 创建语义索引任务
-
单击数据集名称进入详情页面,在索引库配置区域,单击编辑按钮。
-
配置索引库。
-
索引模型连接:选择3.3.2中创建的索引模型连接;
-
索引数据库连接:选择3.3.3中创建的索引库连接;
-
索引数据库表:输入创建向量索引表(可选)中创建的索引表名称,即:dataset_embed_test;
单击保存 > 立即刷新。然后会创建一个所选数据集版本的语义索引任务,对版本中全量文件更新语义索引。可单击数据集详情页面右上角语义索引任务查看任务详情。
说明首次启动语义索引任务,将进行元数据的构建,所需时间可能较长,请耐心等待。
如果没有单击立即刷新,而是取消,您可以手动创建任务。详细操作如下:
在数据集详情页面单击数据集任务进入任务页面。
单击新建任务 > 语义索引,配置数据集版本,最大并发数根据EAS模型服务规格配置,单卡建议最大并发为5。然后单击确认创建语义索引任务。
-



3.6 数据预览
-
待智能打标和语义索引任务完成后,在数据集详情页面,单击查看数据可预览该数据集版本内的图片。
-
在查看数据页面,可对该数据集版本内的图片进行预览,可切换“画廊视图”和“列表视图”查看。
-
点击具体图片,可查看大图,并查看图片中包含的标签。
-
点击缩略图左上角的Checkbox,可进行多选。或按住Shift键点击Checkbox可一次性选择多行数据。





3.7 基础数据搜索(组合检索)
-
在“查看数据”界面的左侧工具栏内,可进行索引检索和标签搜索,按下Enter或单击搜索即可开始搜索。
-
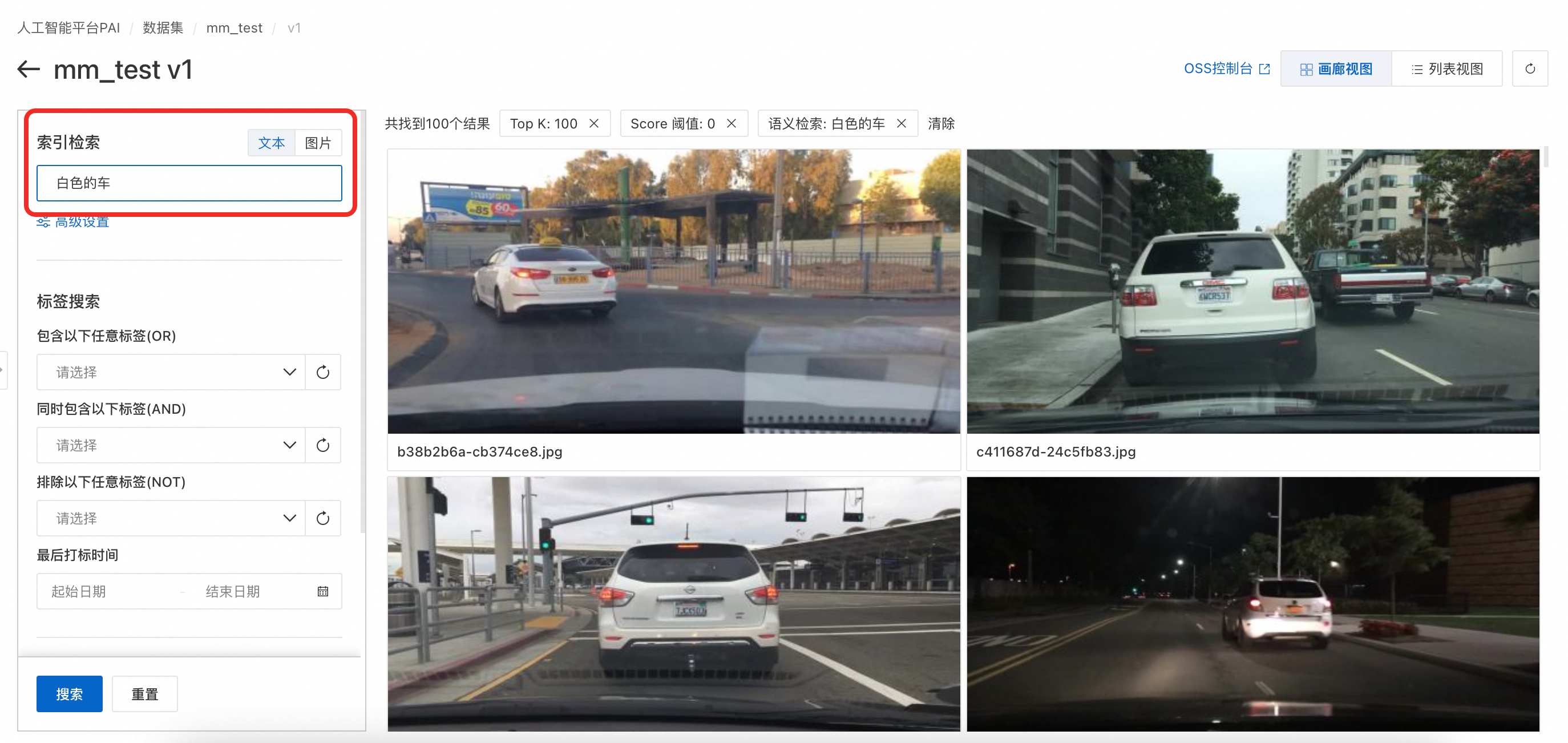
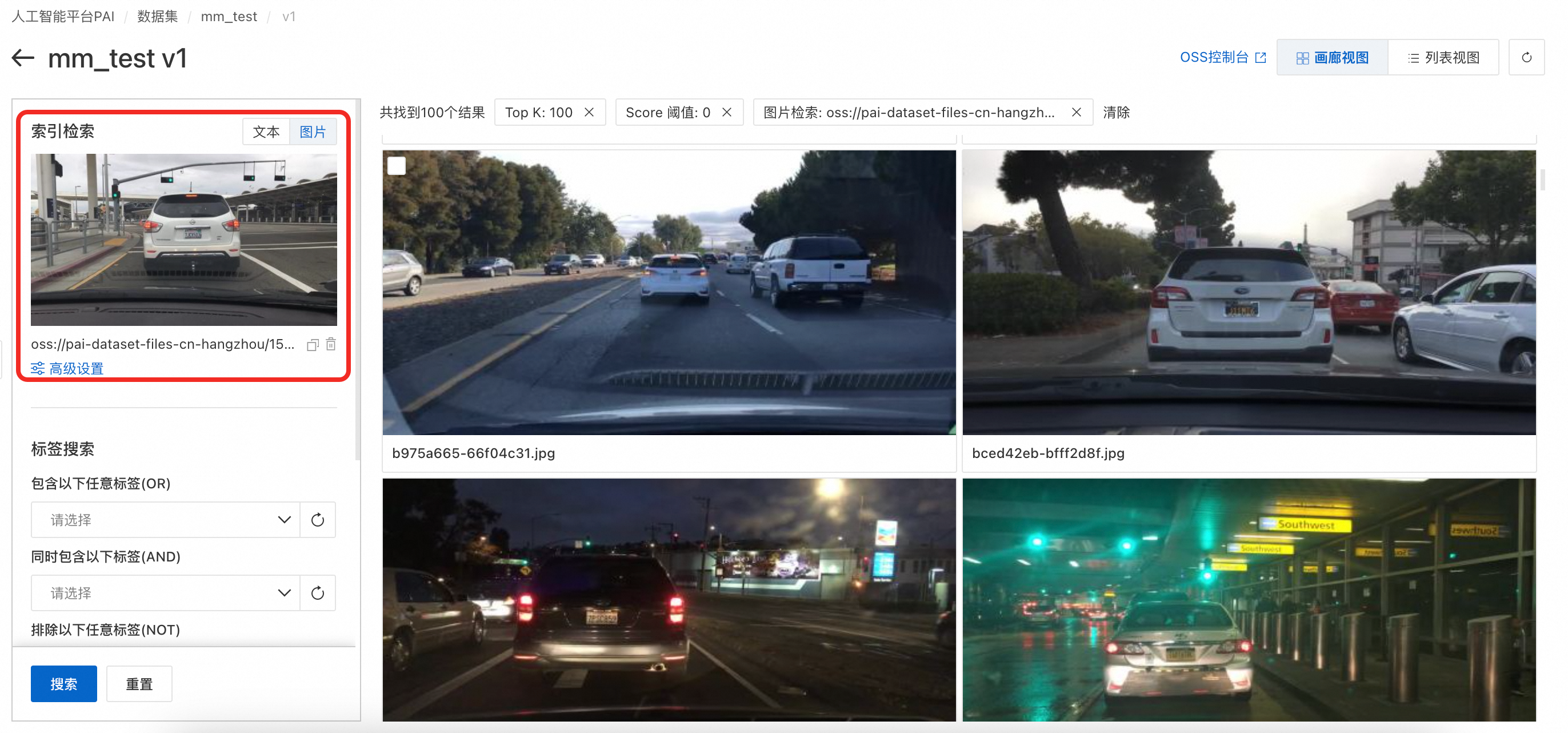
索引检索,文本关键词搜索:基于“语义索引”的结果,通过关键词与图片索引结果的向量匹配进行搜索。在“高级设置”中可以设置topk、Score 阈值等参数。
-
索引检索,以图搜图:基于“语义索引”的结果,用户可以从本地上传图片或者选择OSS中的图片,与数据集图片索引结果的向量匹配进行搜索。在“高级设置”中可以设置topk、Score阈值等参数。
-
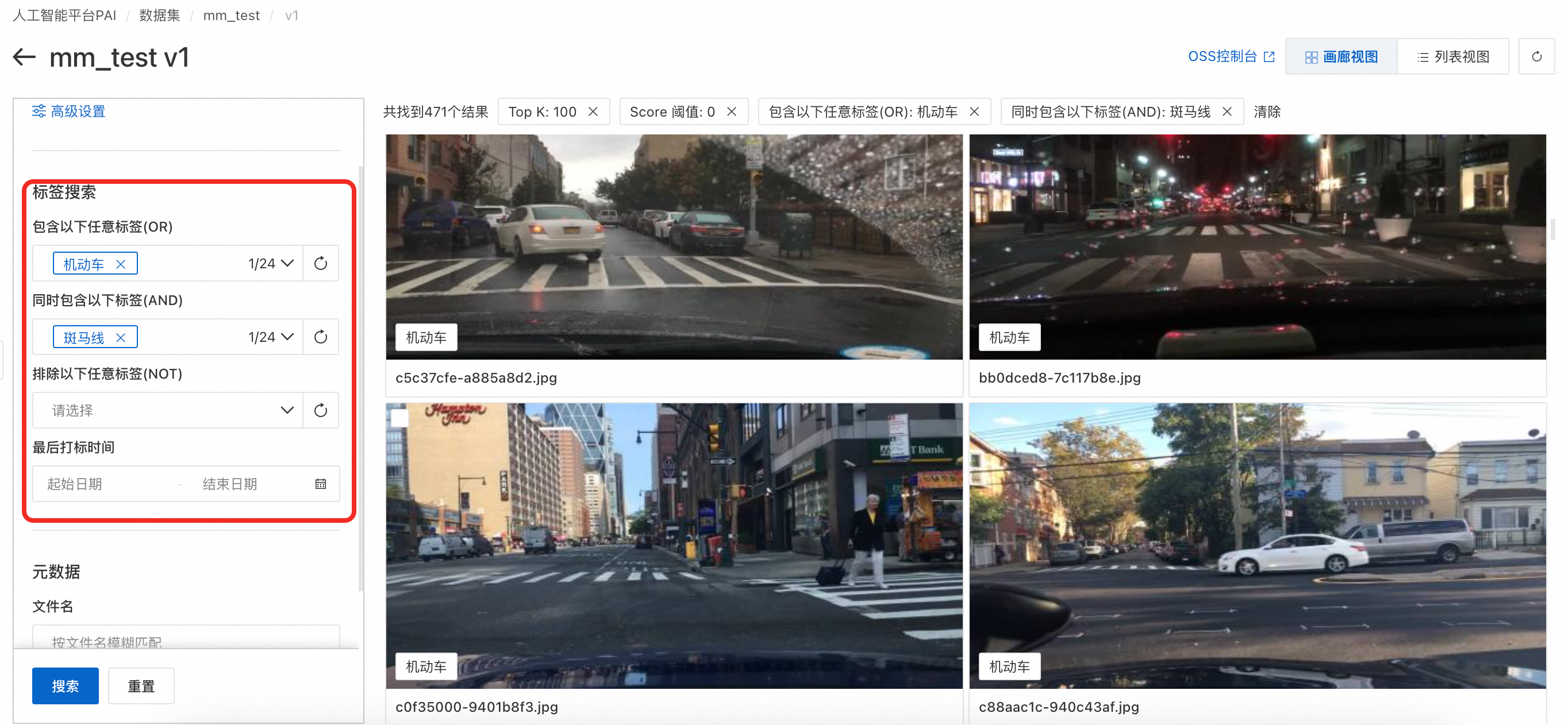
标签搜索:基于“智能打标”的结果,通过关键词与图片标签的匹配进行搜索。可同时按照包含以下任意标签(OR)、同时包含以下标签(AND)和排除以下任意标签(NOT)的逻辑进行搜索。
-
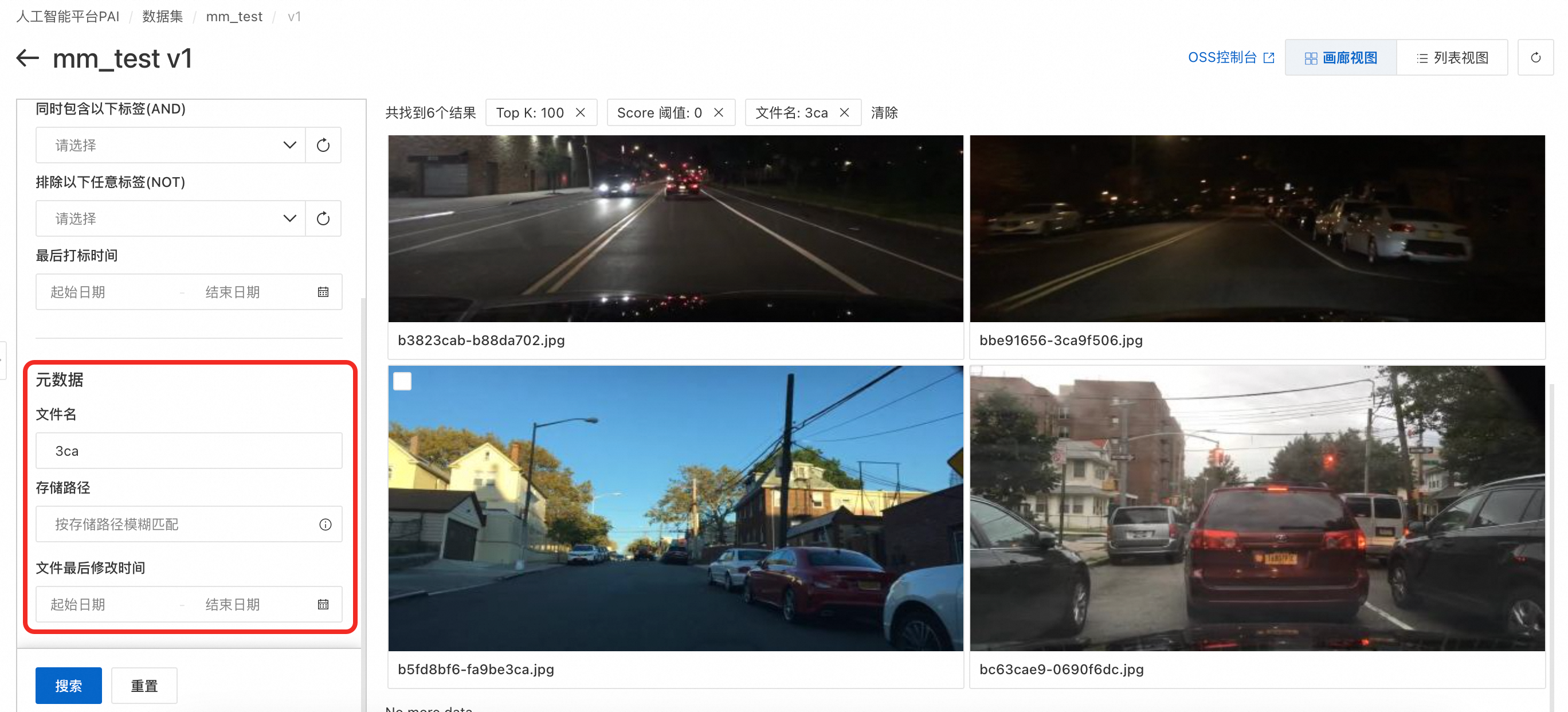
元数据搜索:可以按照文件名、存储路径、文件最后修改时间进行搜索。
以上所有搜索条件为AND关系。
3.8 高级数据搜索(DSL)
高级检索可以使用DSL检索。DSL是一种用于表达复杂检索条件的领域特定语言。它支持分组、布尔逻辑(AND/OR/NOT)、范围比较(>, >=, <, <=)、属性存在性(HAS/NOT HAS)、分词匹配(:)与精确匹配(=)等,适用于高级检索场景。语法说明详见:获取数据集文件元数据列表。

3.9 搜索结果集的导出
此步骤的目的,是将搜索结果导出为文件列表索引,用于后续的模型训练或数据分析。
检索完成后,可以单击页面下方导出搜索结果按钮,支持两种导出模式:

3.9.1 导出为文件
-
单击导出为文件,在配置页设置导出内容及目标OSS目录,单击确定。
-
查看导出进度可通过在左侧菜单栏单击AI资产管理 > 任务 > 数据集任务查看。
-
使用导出结果。导出后,可将导出结果文件与原数据集挂载至对应的训练环境(如DLC或DSW实例),通过代码实现读取导出结果文件索引,并从原数据集中加载目标文件进行模型训练或分析。

3.9.2 导出至逻辑型数据集版本
可以将高级型数据集的某次检索结果导入到另一个逻辑型数据集的版本中,后续可通过数据集的SDK来使用该逻辑型数据集的版本数据。
-
单击导出至逻辑型数据集版本,选择目标逻辑型数据集,单击确认。
如无可选逻辑型数据集,可参考如下内容:
-
使用逻辑型数据集。导入任务完成后,目标逻辑型数据集内已包含了本次导出的元数据,可通过SDK来加载和使用。可在数据集的详情页查看SDK的使用方法。
SDK的安装命令为:
pip install https://pai-sdk.oss-cn-shanghai.aliyuncs.com/dataset/pai_dataset_sdk-1.0.0-py3-none-any.whl



4. 自定义语义索引模型(可选)
您可以通过微调自定义语义检索模型,在EAS部署成功后,可以按照3.3.2中的步骤创建模型连接,在后续的多模态数据管理中使用。
4.1 数据准备
本文提供了示例数据retrieval_demo_data,您可以单击下载。
4.1.1 数据格式要求
每个数据样本以一行JSON格式保存到dataset.jsonl文件中,必须包含以下字段:
-
image_id: 图像唯一标识符(如图片名称或唯一ID)。
-
tags: 与该图像关联的文本标签列表,标签为字符串数组。
示例格式:
{
"image_id": "c909f3df-ac4074ed",
"tags": ["银色的轿车", "白色的SUV", "城市街道", "下雪", "夜晚"],
}4.1.2 文件组织结构
将所有图像文件放入一个文件夹(images),并将dataset.jsonl文件放在与图像文件夹同级的目录中。
目录示例:
├── images
│ ├── image1.jpg
│ ├── image2.jpg
│ └── image3.jpg
└── dataset.jsonl 务必使用原始文件名dataset.jsonl,文件夹名images不可更改。
4.2 模型训练
-
在 Model Gallery 中找到检索相关的模型,根据所需的模型大小和计算资源,选择合适的模型来进行微调和部署。
微调 VRAM bs=4
微调(4*A800)train_samples/second
部署 VRAM
向量维度
GME-2B
14G
16.331
5G
1536
GME-7B
35G
13.868
16G
3584
-
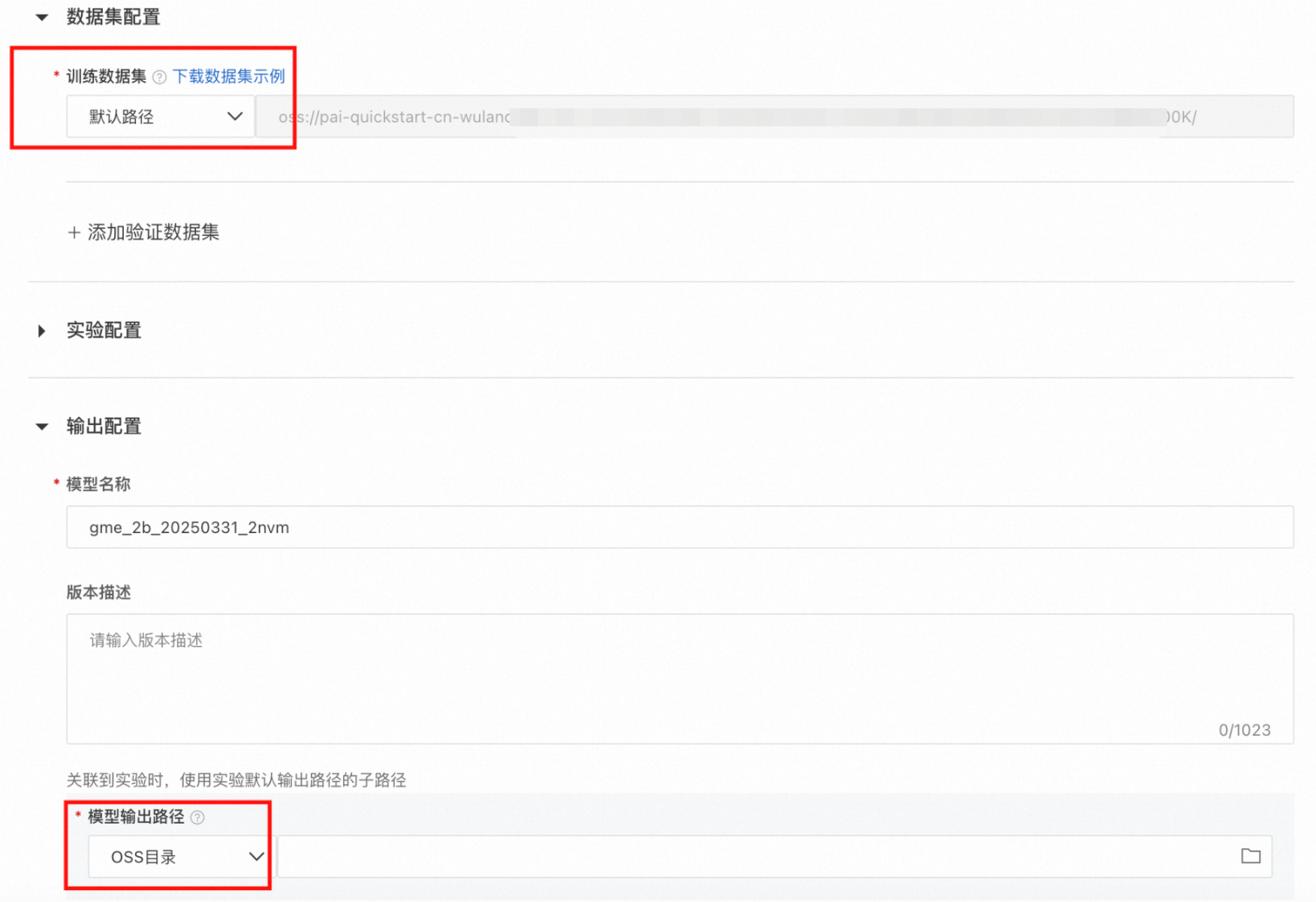
以训练GME-2B模型为例,单击训练,填入数据地址 (默认地址即为示例数据地址),填写模型输出路径,即可开始训练模型。
4.3 模型部署
训练完的模型可以训练任务中,点击部署来部署微调后的模型
点击Model Gallery模型选项卡的部署按钮,即可部署原始的GME模型。

部署完成后,可在页面中获得对应的 EAS 访问地址 及 Token。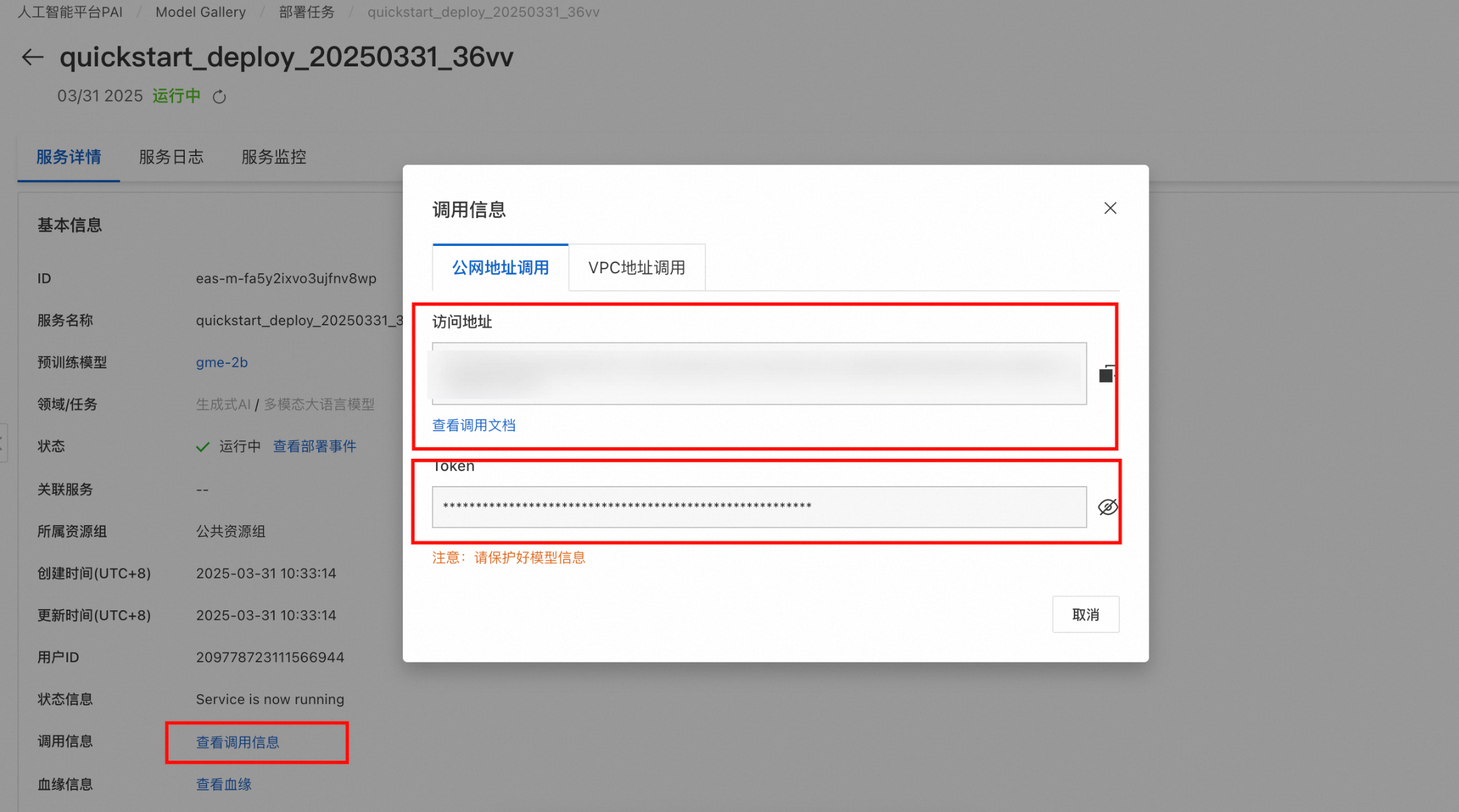
4.4 模型服务调用
输入参数
|
名称 |
类型 |
是否必填 |
示例值 |
描述 |
|
model |
String |
是 |
pai-multimodal-embedding-v1 |
模型类型,后续可以添加用户自定义模型的支持 / 进行基模型的版本迭代 |
|
contents.input |
list(dict) or list(str) |
否 |
input = [{'text': text}] input=[xxx,xxx,xxx,...] input = [{'text': text},{'image', f"data:image/{image_format};base64,{image64}"}] |
待embedding的内容。 当前只支持 text, image |
输出参数
|
名称 |
类型 |
示例值 |
描述 |
|
status_code |
Integer |
200 |
http状态码。 200 请求成功 204 请求部分成功 400 请求失败 |
|
message |
list(str) |
['Invalid input data: must be a list of strings or dict'] |
报错信息 |
|
output |
dict |
见下表 |
embedding结果 |
dashscope 返回结果是一个 {'output', {'embeddings': list(dict), 'usage': xxx, 'request_id':xxx}}(暂时不用 'usage', 'request_id')
embeddings 的元素包含以下key (失败的index 会把错误原因加在message中)
|
名称 |
类型 |
示例值 |
描述 |
|
index |
数据id |
0 |
http状态码。 200、400、500等 |
|
embedding |
List[Float] |
[0.0391846,0.0518188,.....,-0.0329895, 0.0251465] 1536 |
embedding后的向量 |
|
type |
String |
"Internal execute error." |
错误信息 |
输出示例:
{
"status_code": 200,
"message": "",
"output": {
"embeddings": [
{
"index": 0,
"embedding": [
-0.020782470703125,
-0.01399993896484375,
-0.0229949951171875,
...
],
"type": "text"
}
]
}
}4.5 模型评测
在我们的示例数据上的评测效果如下(所使用的评测文件):
|
原始模型Precision |
微调1个epoch的模型Precision |
|
|
gme2b |
Precision@1 0.3542 Precision@5 0.5280 Precision@10 0.5923 Precision@50 0.5800 Precision@100 0.5792 |
Precision@1 0.4271 Precision@5 0.6480 Precision@10 0.7308 Precision@50 0.7331 Precision@100 0.7404 |
|
gme7b |
Precision@1 0.3958 Precision@5 0.5920 Precision@10 0.6667 Precision@50 0.6517 Precision@100 0.6415 |
Precision@1 0.4375 Precision@5 0.6680 Precision@10 0.7590 Precision@50 0.7683 Precision@100 0.7723 |
4.6 模型使用
微调后的Embedding模型,部署在EAS成功后,可以通过3.3.2中的步骤创建模型连接,用于后续的多模态数据管理中使用。