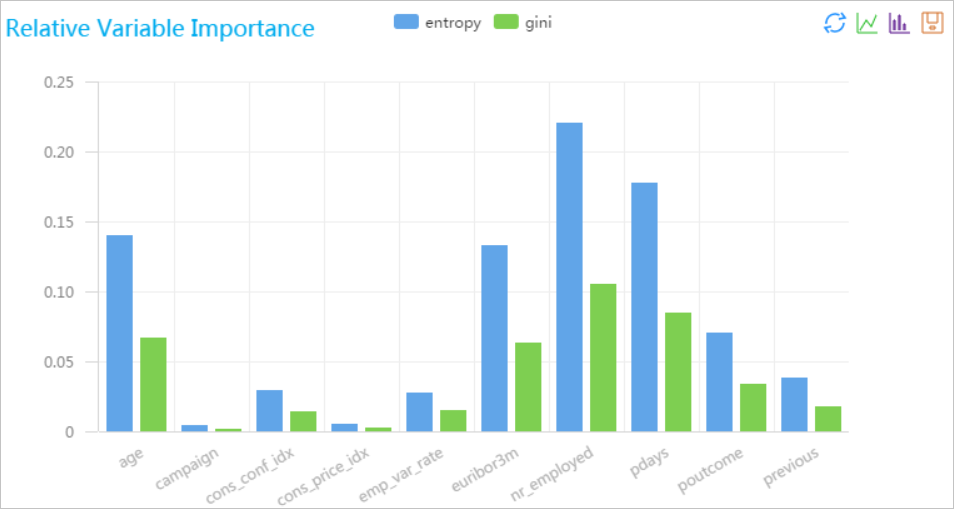
随机森林特征重要性评估是一种通过分析随机森林模型中各个特征对预测结果贡献程度的方法。通常通过计算每个特征在所有决策树中的平均不纯度减少或基于置换重要性的方法来确定特征的重要性,从而帮助识别对模型性能影响最大的特征。
组件配置
方式一:可视化方式
在Designer工作流页面添加随机森林特征重要性评估组件,并在界面右侧配置相关参数:
参数类型 | 参数 | 描述 |
字段设置 | 选择特征列 | 输入表中,用于训练的特征列。默认选中除Label外的所有列,为可选项。 |
选择目标列 | 该参数为必选项。 | |
参数设置 | 并行计算核数 | 并行计算的核心数。 |
每个核内存大小 | 每个核的内存大小,单位为MB。 |
方式二:PAI命令方式
使用PAI命令配置随机森林特征重要性评估组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见场景4:在SQL脚本组件中执行PAI命令。
pai -name feature_importance -project algo_public
-DinputTableName=pai_dense_10_10
-DmodelName=xlab_m_random_forests_1_20318_v0
-DoutputTableName=erkang_test_dev.pai_temp_2252_20319_1
-DlabelColName=y
-DfeatureColNames="pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign,poutcome"
-Dlifecycle=28 ;参数名称 | 是否必选 | 默认值 | 描述 |
inputTableName | 是 | 无 | 输入表的名称。 |
outputTableName | 是 | 无 | 输出表的名称。 |
labelColName | 是 | 无 | 输入表的标签列名。 |
modelName | 是 | 无 | 输入的模型名称。 |
featureColNames | 否 | 除Label外的所有列 | 输入表选择的特征列。 |
inputTablePartitions | 否 | 选择全表 | 输入表选择的分区名称。 |
lifecycle | 否 | 不设置 | 输出表的生命周期。 |
coreNum | 否 | 自动计算 | 核心数。 |
memSizePerCore | 否 | 自动计算 | 内存数,单位为MB。 |
使用示例
使用SQL语句,生成训练数据。
本文以从bank_data表中选择指定的列和前10条记录创建pai_dense_10_10表为例说明,您可根据实际情况建表。
drop table if exists pai_dense_10_10; create table pai_dense_10_10 as select age,campaign,pdays, previous, poutcome, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, y from bank_data limit 10;构建如下实验,详情请参见自定义工作流。
y为随机森林的标签列,其它列为特征列。强制转换列选择age和campaign,表示将这两列作为枚举特征处理,其它使用默认参数。
运行实验,查看预测结果。
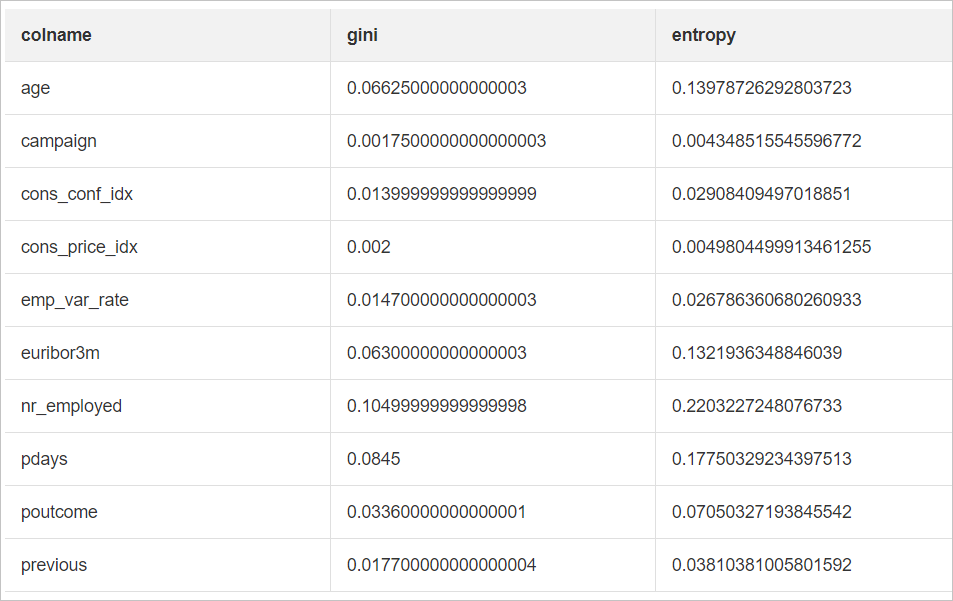
运行完成后,右键单击随机森林特征重要性评估组件,选择可视化分析,查看结果。