
拒绝推断(Reject Inference,RI)是一种在金融风控中常用的技术,主要用于弥补样本选择偏差,提高信用评估模型的准确性和可靠性。拒绝推断的核心思想是利用已知的接受客户(通过审批的客户)信息来推断被拒绝客户(未通过审批的客户)的风险特征,从而更全面地评估信贷风险。
算法说明
以信贷场景为例,用评分卡模型对用户的偿还、违约情况进行建模时只用到了被放贷的用户数据,而缺少未得到贷款的用户数据,导致模型对全量数据的风险估计不准确,往往过于乐观。拒绝推断可以解决此类样本偏差问题。
拒绝推断方法需要根据输入的包含真实标签和预测结果的训练数据(又称为授信数据),给缺少真实标签但包含预测结果的数据加上合适的标签,没有真实标签的数据又称为拒绝数据。该算法提供以下四种拒绝推断方法。
模糊法
模糊法(fuzzy)通过给拒绝样本加上正例和负例两种标签的方法增强数据集,每种标签对应的样本权重计算公式如下:



 是前置评分卡组件预测的正例概率值,您可以指定
是前置评分卡组件预测的正例概率值,您可以指定 和
和 参数:
参数:- :给出全部数据的拒绝率。
- :拒绝样本的负例概率,相比接受样本的负例概率增加到倍。
硬截断法
硬截断法(hard cutoff)需要您基于前置评分卡模型的打分,根据对拒绝用户的风险容忍度来设定一个阈值分数。对低于这个阈值的添加负样本标签;对高于这个阈值的添加正样本标签。
分配法
分配法 (parcelling)对接受样本基于前置评分卡模型的预测结果进行分组,计算各分组的违约率。然后对拒绝样本进行同样的分组,以该组违约率为抽样比例,随机抽取该分组下的违约样本,指定其为负样本,剩下的则是正样本。
两阶段法
两阶段法 (Two-Stage)除了需要前置评分卡模型的预测分值(AcceptRejectScore),还需要一个前置模型预测样本被接受或拒绝的概率(GoodBadScore),两阶段法通过拟合AcceptRejectScore和GoodBadScore的线性关系,修正前置评分卡模型对无标签样本的预测结果,然后按照分配法的步骤为样本添加标签。
 参数:
参数: :给出全部数据的拒绝率。
:给出全部数据的拒绝率。 :拒绝样本的负例概率,相比接受样本的负例概率增加到
:拒绝样本的负例概率,相比接受样本的负例概率增加到 倍。
倍。输入/输出
输入桩
输出桩
配置组件
参数类型 | 参数 | 是否必选 | 描述 | 默认值 |
字段设置 | 履约/违约预测结果列 | 是 | 评分卡组件的预测结果列。一般是在授信数据集上以样本的好坏情况作为标签,用同一个评分卡模型训练、预测后prediction_score列的输出结果。 | 无 |
授信数据的真实标签列 | 是 | 授信数据的真实标签列的列名。 真实标签的类别必须为0和1,其中1代表正样本或好样本。 | 无 | |
样本权重列 | 否 | 样本权重列的列名。 | 无 | |
授信/拒绝预测结果列 | 否 | 预测的样本接受概率,一般是在全量数据上以接受或拒绝作为标签,用同一个评分卡或线性模型训练、预测后的输出结果。 拒绝推断方法选择Two-Stage方法时,需要配置该字段。 | 无 | |
参数设置 | 拒绝推断方法 | 否 | 拒绝推断使用的方法,取值如下,具体含义请参见算法原理介绍。
| fuzzy模糊法 |
拒绝样本的比例 | 是 | 拒绝率,代表在真实环境里一个样本被拒绝的概率。 | 0.3 | |
分桶数量 | 否 | 仅拒绝推断方法选择parceling分配法和two stage两阶段法时,支持配置该参数。 训练分箱模型步骤的分箱个数。 | 25 | |
截断分值 | 否 | 仅拒绝推断方法选择hard-cutoff硬截断法时,支持配置该参数。 截断阈值。使用截断法时,大于等于截断分值的样本被预测为正样本,其余为负样本。 | 无 | |
坏样本比例增长系数 | 否 | 仅拒绝推断方法选择fuzzy模糊法、parceling分配法或two stage两阶段法时支持配置该参数。
| 1.0 | |
随机数种子 | 否 | 仅拒绝推断方法选择parceling分配法时支持配置该参数。 随机指定标签时使用的随机数种子。 | 0 | |
区间选择方法 | 否 | 仅拒绝推断方法选择parceling分配法和two stage两阶段法时支持配置该参数。 有以下三种分箱区间选择方法
| 全量数据集 | |
分数转换 | 否 | 选中分数转换,支持配置scaledValue、odds和pdo,关于参数配置方法,详情请参见评分卡训练。 | false | |
scaledValue | 否 | 无 | ||
odds | 否 | 无 | ||
pdo | 否 | 无 | ||
执行调优 | 底层作业使用的计算资源 | 是 | 执行作业的资源类型。 | MaxCompute |
节点个数 | 否 | 执行作业的节点数,正整数,取值范围为[1,9999]。 | 无 | |
单个节点内存大小 | 否 | 节点所使用的内存数,单位为MB,取值范围为[1024,64*1024]。 | 无 |
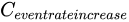 参数。
参数。