
评分卡训练是一种用于信用风险评估的机器学习方法,它通过将原始变量进行分箱处理以离散化数据,然后应用线性模型(如逻辑回归或线性回归)进行训练。该方法不仅包括特征选择和分数转换功能,还允许在训练过程中对变量施加约束条件,以提高模型的解释性和性能。如果未进行分箱处理,评分卡训练与传统的逻辑回归或线性回归无异。
使用限制
使用评分卡训练组件生成的临时模型仅支持使用MaxCompute临时表进行存储,该临时表在Studio中的默认生命周期为369天,在Designer中的默认生命周期为当前所在工作空间配置的临时表保存时长,具体配置方法请参见管理工作空间。如果您需要长期使用该临时模型,需要通过写数据表进行固化,操作详情请参见算法组件常见问题。
基本概念
以下介绍评分卡训练过程中的相关概念:
-
特征工程
评分卡与普通线性模型的最大区别在于进行线性模型训练之前会对数据进行一定的特征工程处理。本文中,评分卡提供了如下两种特征工程方法:
-
先通过分箱组件将特征离散化,再将每个变量根据分箱结果进行One-Hot编码,分别生成N个Dummy变量(N为变量的分箱数量)。
说明使用Dummy变量变换时,每个原始变量的Dummy变量之间可以设置相关的约束,详情请参见分箱。
-
先通过分箱组件将特征离散化,再进行WOE转换,即使用变量落入的分箱所对应的WOE值替换变量的原始值。
-
-
分数转换
评分卡的信用评分等场景中,需要通过线性变换将预测得到的样本odds转换成分数,通常通过如下的线性变换实现。
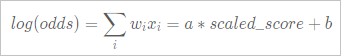 您可以通过如下三个参数指定线性变换关系:
您可以通过如下三个参数指定线性变换关系:-
scaledValue:给出一个分数的基准点。
-
odds:在给定的分数基准点处的odds值。
-
pdo(Point Double Odds):表示分数增长多少分时,odds值增长到双倍。
例如,scaledValue=800,odds=50,pdo=25,则表示指定了直线中的如下两点。
log(50)=a×800+b log(100)=a×825+b解出a和b,对模型中的分数进行线性变换即可得到变换后的变量分。
Scaling信息由参数
-Dscale指定,格式为JSON,示例如下。{"scaledValue":800,"odds":50,"pdo":25}当
-Dscale参数不为空时,需要同时配置scaledValue、odds及pdo的值。 -
-
训练过程中增加约束
评分卡训练过程支持对变量添加约束。例如指定某个bin所对应的分数为固定值,两个bin的分数满足一定比例,对bin之间的分数进行大小限制,或设置bin的分数按照bin的WOE值排序等。约束的实现依赖于底层带约束的优化算法,可以在分箱组件中通过可视化方式设置约束,设置完成后分箱组件会生成一个JSON格式的约束条件,并将其自动传递给下游连接的训练组件。在评分卡实验的分箱节点参数设置面板中,设置特征列(支持string、bigint、double类型)、标签列(值为class)、正例值为1,并勾选自定义Json文件分箱选项上传约束文件(如binning.txt)。约束JSON以字符串形式存储在单行单列的表中。系统支持如下六种JSON约束:
-
“<”:变量权重按照顺序满足升序的约束。
-
“>”:变量权重按照顺序满足降序的约束。
-
“=”:变量权重等于固定值。
-
“%”:变量之间的权重符定一定的比例关系。
-
“UP”:变量的权重约束上限。例如,0.5表示训练获得的权重值不大于0.5。
-
“LO”:变量的权重约束下限。例如,0.5表示训练获得的权重值不小于0.5。
JSON约束以字符串的形式存储在单行单列(字符串类型)的表中,存储的JSON字符串示例如下。
{ "name": "feature0", "<": [ [0,1,2,3] ], ">": [ [4,5,6] ], "=": [ "3:0","4:0.25" ], "%": [ ["6:1.0","7:1.0"] ] } -
-
内置约束
每个原始变量都有一个隐含约束,无需用户指定,即单个变量人群的分数平均值为0。通过该约束,模型截距项的scaled_weight即为整个人群的平均分。
-
优化算法
在高级选项中可以配置训练过程中使用的优化算法,系统支持如下四种优化算法:
-
L-BFGS:是一阶的优化算法,支持较大规模的特征数据集。该算法属于无约束的优化算法,会自动忽略约束条件。
-
Newton's Method:牛顿法是经典的二阶算法,收敛速度快,准确度高。但是由于需要计算二阶Hessian Matrix,因此不适用于较大特征规模。该算法属于无约束的优化算法,会自动忽略约束条件。
-
Barrier Method:二阶的优化算法,在没有约束条件的情况下完全等价于牛顿法。该算法的计算性能和准确性与SQP差别不大,通常建议选择SQP。
-
SQP
二阶的优化算法,在没有约束条件的情况下完全等价于牛顿法。该算法的计算性能和准确性与Barrier Method差别不大,通常建议选择SQP。
说明-
L-BFGS和Newton's Method均属于无约束的优化算法,Barrier Method和SQP属于带约束的优化算法。
-
如果不了解优化算法,建议将优化算法配置为”自动选择“,系统会自动根据用户任务的数据规模和约束情况选择最合适的优化算法。
-
-
特征选择
训练模块支持Stepwise特征选择功能。Stepwise是一种前向选择和后向选择的融合,即每次进行前向特征选择将一个新变量加入模型后,需要对已经进入模型的变量进行一次后向选择,以移除显著性不满足需求的变量。由于同时支持多种目标函数和多种特征变换方法,因此Stepwise特征选择过程支持如下多种选择标准:
-
边缘贡献(Marginal Contribution):适用于所有目标函数和特征工程方法。
模型A中不包含变量X,模型B包含所有A的变量,且包含变量X。两个训练模型最终收敛时所对应目标函数的差值,即为变量X在模型B中所有变量之间的边缘贡献度。在特征工程为Dummy变换的场景中,原始变量的X边缘贡献度定义为两个模型分别包含和不包含该变量的所有Dummy变量的目标函数之差。因此,使用边缘贡献度进行特征选择支持所有的特征工程方法。
该方法的优点是比较灵活,不局限于某一种模型,直接选择使得目标函数更优的变量进入模型。缺点是边缘贡献度不同于统计显著性,统计显著性通常选择0.05为阈值,而边缘贡献度新用户没有一个绝对的概念阈值,建议将其设置为10E-5。
-
评分检验(Score Test):仅支持WOE转换或无特征工程的逻辑回归选择。
前向选择过程中,首先训练一个仅有截距项的模型,在之后的每一步迭代中,分别对未进入模型的变量计算其评分卡方统计量(Score Chi-Square),然后将评分卡方统计量最大的变量选入模型。同时,根据卡方分布计算该统计量所对应的显著性P Value。如果评分卡方统计量最大的变量其P Value大于用户指定的进入模型的最大显著性阈值(slentry),则不会将该变量纳入模型,并停止选择过程。
完成一轮前向选择后,将对已经选中进入模型的变量进行一轮后向选择。后向选择过程中,对于已经进入模型中的变量分别计算其对应的沃尔德卡方统计量(Wald Chi-Square),并计算其对应的显著性P Value。如果P Value大于用户指定的移除模型的最大显著性阈值(slstay),则从模型中移除该变量,并继续进行下一轮迭代选择。
-
F检验(F Test):仅支持WOE转换或无特征工程的线性回归选择。
前向选择过程中,首先训练一个仅有截距项的变量,在之后的每一步迭代中,分别对未进入模型的变量计算其F Value。F Value的计算与边缘贡献度的计算类似,需要训练两个模型以计算一个变量的F Value。F Value符合F分布,可以根据其F分布的概率密度函数求得其对应的显著性P Value。如果P Value大于用户指定的进入模型的最大显著性阈值(slentry),则不会将变量纳入模型,并停止选择过程。
后向选择过程也是使用F Value计算显著性,其过程与评分检验类似。
-
-
强制选择加入模型的变量
进行特征选择之前,可以设置强制进入模型的变量,被选中的变量不参与前向和后向的特征选择过程。无论选中的变量其显著性取值如何,都会直接进入模型。您可以在命令行中通过-Dselected参数指定迭代次数和显著性阈值,格式为JSON,示例如下。
{"max_step":2, "slentry": 0.0001, "slstay": 0.0001}如果-Dselected参数为空或max_step为0,则表示正常的训练流程,不进行特征选择。
组件配置
Designer支持通过可视化(详见评分卡训练示例)或PAI命令的方式配置评分卡训练组件的参数,使用PAI命令的方式如下。
pai -name=linear_model -project=algo_public
-DinputTableName=input_data_table
-DinputBinTableName=input_bin_table
-DinputConstraintTableName=input_constraint_table
-DoutputTableName=output_model_table
-DlabelColName=label
-DfeatureColNames=feaname1,feaname2
-Doptimization=barrier_method
-Dloss=logistic_regression
-Dlifecycle=8|
参数 |
是否必选 |
默认值 |
描述 |
|
inputTableName |
是 |
无 |
输入特征数据表。 |
|
inputTablePartitions |
否 |
全表 |
输入特征表选择的分区。 |
|
inputBinTableName |
否 |
无 |
输入分箱结果表。如果该表指定,则先自动根据该表的分箱规则对原始特征进行离散化,再进行训练。 |
|
featureColNames |
否 |
选择全部,自动排除Label列。 |
输入表选择的特征列。 |
|
labelColName |
是 |
无 |
目标列。 |
|
outputTableName |
是 |
无 |
输出模型表。 |
|
inputConstraintTableName |
否 |
无 |
输入的JSON格式约束条件,存储在表的一个单元中。 |
|
optimization |
否 |
auto |
优化类型,支持的类型包括:
仅sqp和barrier_method支持约束,auto即为根据用户数据和相关参数自动选择合适的优化算法。如果您对优化算法不太了解,建议使用auto。 |
|
loss |
否 |
logistic_regression |
Loss类型,支持logistic_regression和least_square类型。 |
|
iterations |
否 |
100 |
优化的最大迭代次数。 |
|
l1Weight |
否 |
0 |
L1正则的参数权重,仅lbfgs优化算法支持L1 Weight。 |
|
l2Weight |
否 |
0 |
L2正则的参数权重。 |
|
m |
否 |
10 |
lbfgs优化过程中的历史长度,仅对lbfgs优化算法有效。 |
|
scale |
否 |
空 |
评分卡对Weight进行Scale的信息。 |
|
selected |
否 |
空 |
评分卡特征选择功能。 |
|
convergenceTolerance |
否 |
1e-6 |
收敛条件。 |
|
positiveLabel |
否 |
1 |
正样本的分类。 |
|
lifecycle |
否 |
无 |
输出表的生命周期。 |
|
coreNum |
否 |
系统自动计算 |
核心数。 |
|
memSizePerCore |
否 |
系统自动计算 |
内存数,单位为MB。 |
组件输出
评分卡模型的输出为一个Model Report,其中包含了变量的分箱信息、分箱的约束信息、WOE及Marginal Contribution等基本的统计指标。PAI Web端展示的评分卡模型评估报告的相关列描述如下所示。
|
列名 |
列类型 |
描述 |
|
feaname |
STRING |
特征名称。 |
|
binid |
BIGINT |
分箱ID。 |
|
bin |
STRING |
分箱描述,用于表明该分箱的值域。 |
|
constraint |
STRING |
训练时增加到该分箱的约束条件。 |
|
weight |
DOUBLE |
训练完成后所对应的分箱变量权重,或未指定分箱输入的非评分卡模型,该项直接对应模型变量权重。 |
|
scaled_weight |
DOUBLE |
评分卡模型训练过程中指定分数转换信息后,将分箱变量权重经过线性变换得到的分数值。 |
|
woe |
DOUBLE |
统计指标:训练集上该分箱的WOE值。 |
|
contribution |
DOUBLE |
统计指标:训练集上该分箱的Marginal Contribution值。 |
|
total |
BIGINT |
统计指标:训练集上该分箱的总样本数。 |
|
positive |
BIGINT |
统计指标:训练集上该分箱的正样本数。 |
|
negative |
BIGINT |
统计指标:训练集上该分箱的负样本数。 |
|
percentage_pos |
DOUBLE |
统计指标:训练集上该分箱的正样本数占总正样本的比例。 |
|
percentage_neg |
DOUBLE |
统计指标:训练集上该分箱的负样本数占总负样本的比例。 |
|
test_woe |
DOUBLE |
统计指标:测试集上该分箱的WOE值。 |
|
test_contribution |
DOUBLE |
统计指标:测试集上该分箱的Marginal Contribution值。 |
|
test_total |
BIGINT |
统计指标:测试集上该分箱的总样本数。 |
|
test_positive |
BIGINT |
统计指标:测试集上该分箱的正样本数。 |
|
test_negative |
BIGINT |
统计指标:测试集上该分箱的负样本数。 |
|
test_percentage_pos |
DOUBLE |
统计指标:测试集上该分箱的正样本数占总正样本的比例。 |
|
test_percentage_neg |
DOUBLE |
统计指标:测试集上该分箱的负样本数占总负样本的比例。 |
示例
推荐使用Designer提交评分卡训练任务,如下是一个简单的评分卡Stepwise特征选择、特征WOE变换及逻辑回归Stepwise特征选择的对比演示。实验名称为评分卡功能(German数据),完整工作流自上而下依次为:数据源节点(germany_credit_...)连接分箱节点,分箱节点分支连接评分卡训练-1和数据转换模块-1,数据转换模块-1连接评分卡训练-2,两条训练分支分别连接评分卡预测和评分卡预测-2,底部为评分卡评估结果和WOE逻辑回归评估节点,所有节点均运行成功。评分卡训练-1节点的字段设置中,特征列默认选择全部(除label列),标签列为class,正例值为2。左侧组件面板的金融板块(beta)分类下可见评分卡训练、评分卡预测、分箱、数据转换模块等组件。如下是一个简单的评分卡训练、特征WOE变换及逻辑回归的对比演示。在PAI平台中创建名为评分卡功能(German数据)的实验,工作流拓扑为:germany_credit数据源依次连接分箱、评分卡训练-1与数据转换模块-1、评分卡训练-2、评分卡预测与评分卡预测-2、评分卡评估结果与WOE逻辑回归评估,所有节点运行完成。实验属性中创建日期为 2016-04-18 18:01:31,描述为"采用评分卡建模分析信用问题",部署状态为未部署。如果输入训练组件中连接测试集,则输出的模型报告中会同时输出模型在测试集上的统计指标,例如WOE及MC等。如下是一个简单的带测试集的训练演示。实验名称为评分卡测试集功能测试,工作流搭建如下:数据源节点连接拆分节点,拆分节点的两路输出分别连接分箱节点和评分卡训练节点,同时分箱节点输出也连接到评分卡训练节点。左侧金融板块(beta)组件面板中包含评分卡训练、评分卡预测、分箱、数据转换模块、分数转换模块、广义线性回归等组件可供拖拽使用。