
PAI-EasyVision提供端到端文字识别模型的训练及预测功能,本文为您介绍如何通过PAI命令进行端到端文字识别模型训练。
PAI-EasyVision对配置进行了简化,您通过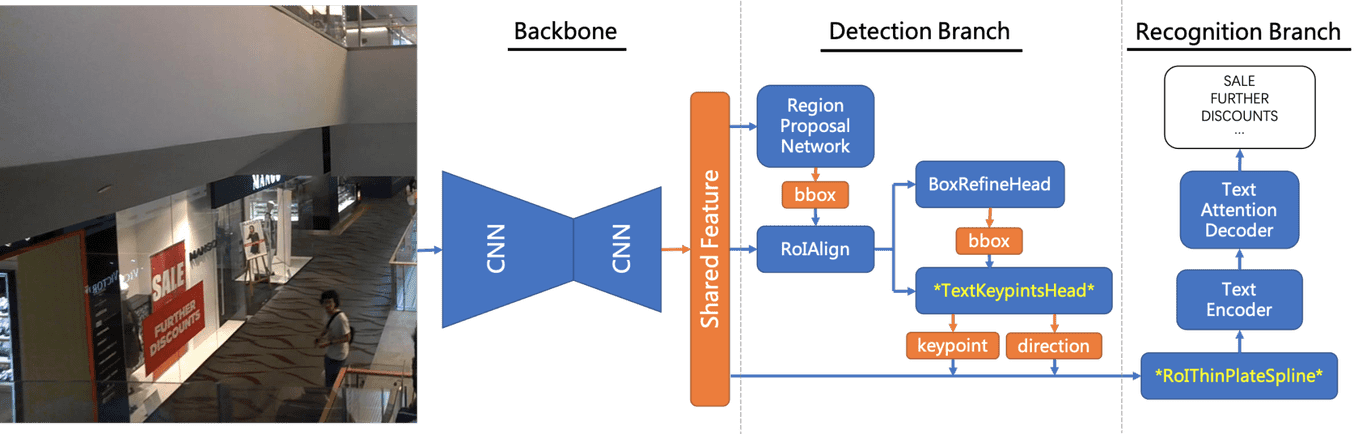
-Dparam_config即可配置常用参数,无需了解PAI-EasyVision的配置文件规则和逻辑。 如果需要尝试更复杂的模型配置,您可以通过PAI-EasyVision命令中的-Dconfig直接传递配置文件进行端到端文字识别模型训练。端到端文字识别模型的主要算法框架如下图所示。端到端文字识别训练
pai -name easy_vision_ext
-Dbuckets='oss://{bucket_name}.{oss_host}/{path}'
-Darn='acs:ram::*********:role/aliyunodpspaidefaultrole'
-DgpuRequired=100
-Dcmd train
-Dparam_config '
--model_type TextEnd2End
--backbone resnet_v1_50
--num_classes 1
--use_pretrained_model true
--train_batch_size 1
--test_batch_size 1
--image_min_sizes 960
--image_max_sizes 1440
--initial_learning_rate 0.0001
--optimizer adam
--lr_type exponential_decay
--decay_epochs 40
--decay_factor 0.5
--num_epochs 10
--staircase true
--predict_text_direction true
--text_direction_trainable true
--text_direction_type smart_unified
--feature_gather_type fixed_height_pyramid
--train_data oss://pai-vision-data-sh/data/recipt_text/end2end_tfrecords/train_*.tfrecord
--test_data oss://pai-vision-data-sh/data/recipt_text/end2end_tfrecords/test.tfrecord
--model_dir oss://pai-vision-data-sh/test/recipt_text/text_end2end_krcnn_resnet50_attn
'参数说明
| 参数 | 是否必选 | 描述 | 参数值格式 | 默认值 |
|---|---|---|---|---|
| buckets | 是 | OSS Bucket地址。 | oss://{bucket_name}.{oss_host}/{path} | 无 |
| arn | 是 | 访问OSS的授权,其获取方式请参见PAI-TF任务参数介绍的IO相关参数说明部分。 | acs:ram::*:role/aliyunodpspaidefaultrole | 无 |
| cluster | 否 | 分布式训练参数相关配置。 | JSON格式字符串 | “” |
| gpuRequired | 否 | 标识是否使用GPU,默认使用一张卡。如果取值200,则一个Worker申请2张卡 | 100 | 100 |
| cmd | 是 | EasyVision任务类型。模型训练时,该参数应取值为train。 | train | 无 |
| param_config | 是 | 模型训练参数,其格式与Python Argparser参数格式一致,详情请参见param_config说明。 | STRING | 无 |
param_config说明
param_config包含若干模型配置相关参数,格式为Python Argparser,示例如下。
-Dparam_config = '
--backbone resnet_v1_50
--model_dir oss://your/bucket/exp_dir
'说明 所有字符串类型的参数,其取值均不加引号。
| 参数 | 是否必选 | 描述 | 参数值格式 | 默认值 |
|---|---|---|---|---|
| model_type | 是 | 训练模型类型。进行端到端文字识别训练时,该参数的取值为TextEnd2End。 | STRING | 无 |
| backbone | 是 | 端到端文字识别模型使用的Backbone,取值包括:
|
STRING | 无 |
| weight_decay | 否 | L2 Regularization的大小。 | FLOAT | 1e-4 |
| num_classes | 否 | 检测类别数量,默认通过分析数据集获得该参数值。 | 21 | -1 |
| anchor_scales | 否 | Anchor框大小,与Resize后的输入图片尺度相同。仅支持为该参数指定一个值,表示分辨率最高Layer的Anchor大小,共5个Layer,后面每个Layer的Anchor大小为前一Layer的2倍。例如32,64,128,256,512。 | 浮点列表,例如32(单一尺度)。 | 24 |
| anchor_ratios | 否 | Anchor宽高比。 | 浮点列表 | 0.2 0.5 1 2 5 |
| predict_text_direction | 否 | 是否预测文字行朝向。 | BOOL | false |
| text_direction_trainable | 否 | 是否训练文字行朝向预测。 | BOOL | false |
| text_direction_type | 否 | 文字朝向预测的类型,取值包括:
|
STRING | normal |
| feature_gather_type | 否 | 文字行特征抽取器类型,取值包括:
|
STRING | fixed_height |
| feature_gather_aspect_ratio | 否 | 文字行的宽高比。当feature_gather_type取值为fixed_size时,该参数表示特征被Resize后的宽高比。当feature_gather_type取值为fixed_height时,该参数表示特征Resize的最大宽高比约束。 | FLOAT | 40 |
| feature_gather_batch_size | 否 | 用于训练的文字行Batch_size。 | INT | 160 |
| recognition_norm_type | 否 | 编码器和文字行特征抽取器的Norm类型,取值包括:
|
STRING | group_norm |
| recognition_bn_trainable | 否 | 编码器和文字行特征抽取器的Batch norm是否可以训练。当norm_type取值为batch_norm时,该参数生效。 | BOOL | false |
| encoder_type | 否 | 编码器类型,取值包括:
|
STRING | crnn |
| encoder_cnn_name | 否 | 编码器中使用的CNN类型,取值包括:
|
STRING | senet5_encoder |
| encoder_num_layers | 否 | 编码器层数(通常指RNN层数,CNN不计算在内)。 | INT | 2 |
| encoder_rnn_type | 否 | 编码器中使用的RNN类型,取值包括:
|
STRING | uni |
| encoder_hidden_size | 否 | 编码器中的隐藏层神经元数量。 | INT | 512 |
| encoder_cell_type | 否 | 编码器中的RNN Cell类型,取值包括:
|
STRING | basic_lstm |
| decoder_type | 否 | 解码器类型,取值包括:
|
STRING | attention |
| decoder_num_layers | 否 | 解码器层数。 | INT | 2 |
| decoder_hidden_size | 否 | 解码器中的隐藏层神经元数量。 | INT | 512 |
| decoder_cell_type | 否 | 解码器中的RNN Cell类型,取值包括:
|
STRING | basic_lstm |
| embedding_size | 否 | 字典的Embedding大小。 | INT | 64 |
| beam_width | 否 | Beam Search中的Beam Width。 | INT | 0 |
| length_penalty_weight | 否 | Beam Search中的Length Penalty,用于避免短序列倾向。 | FLOAT | 0.0 |
| attention_mechanism | 否 | 解码器中的Attention类型,取值包括:
|
STRING | normed_bahdanau |
| aspect_ratio_min_jitter_coef | 否 | 训练时随机扰动图像宽高比的最小比例。如果取值为0,则表示关闭随机扰动图像宽高比。 | FLOAT | 0.8 |
| aspect_ratio_max_jitter_coef | 否 | 训练时随机扰动图像宽高比的最大比例。如果取值为0,则表示关闭随机扰动图像宽高比。 | FLOAT | 1.2 |
| random_rotation_angle | 否 | 训练时随机旋转图像的角度,其取值为(-angle, angle)范围内的随机值。如果取值为0,则表示关闭随机旋转图像。 | FLOAT | 10 |
| random_crop_min_area | 否 | 训练时随机裁切图像的最小面积占比约束。如果取值为0,则表示关闭随机裁切图像。 | FLOAT | 0.1 |
| random_crop_max_area | 否 | 训练时随机裁切图像的最大面积占比约束。如果取值为0,则表示关闭随机裁切图像。 | FLOAT | 1.0 |
| random_crop_min_aspect_ratio | 否 | 训练时随机裁切图像的最小宽高比约束。如果取值为0,则表示关闭随机裁切图像。 | FLOAT | 0.2 |
| random_crop_max_aspect_ratio | 否 | 训练时随机裁切图像的最大宽高比约束。如果取值为0,则表示关闭随机裁切图像。 | FLOAT | 5 |
| image_min_sizes | 否 | 图片缩放大小最短边。为支持Multi-scale Training,如果输入多个Size,则前N-1个作为训练配置,最后一个作为评估测试配置。否则,训练与评估使用相同配置。 | 浮点列表 | 800 |
| image_max_sizes | 否 | 图片缩放大小最长边。为支持Multi-scale Training,如果输入多个Size,则前N-1个作为训练配置,最后一个作为评估测试配置。否则,训练与评估使用相同配置。 | 浮点列表 | 1200 |
| random_distort_color | 否 | 是否在训练时随机扰动图片的亮度、对比度及饱和度。 | BOOL | true |
| optimizer | 否 | 优化方法,取值包括:
|
STRING | momentum |
| lr_type | 否 | 学习率调整策略,取值包括:
|
STRING | exponential_decay |
| initial_learning_rate | 否 | 初始学习率。 | FLOAT | 0.01 |
| decay_epochs | 否 | 如果使用exponential_decay,该参数对应tf.train.exponential.decay中的decay_steps,系统会自动根据训练数据总数将decay_epochs转换为decay_steps。例如,取值为10,通常是总Epoch数的1/2。 如果使用manual_step,该参数表示需要调整学习率的迭代轮数。例如16 18表示在16 Epoch和18 Epoch对学习率进行调整。通常将这两个值配置为总Epoch的8/10和9/10。 | 整数列表,例如20 20 40 60。 | 20 |
| decay_factor | 否 | tf.train.exponential.decay中的decay_factor。 | FLOAT | 0.95 |
| staircase | 否 | tf.train.exponential.decay中的staircase。 | BOOL | true |
| power | 否 | tf.train.polynomial.decay 中的power。 | FLOAT | 0.9 |
| learning_rates | 否 | manual_step学习率调整策略中使用的参数,表示在指定Epoch中学习率的取值。 如果您指定的调整Epoch有两个,则需要在此指定两个Epoch对应的学习率。例如,如果decay_epoches为20 40,则该将参数配置为0.001 0.0001,表示在20 Epoch学习率调整为0.001,40 Epoch学习率调整为0.0001。建议几次调整的学习率依次为初始学习率的1/10、1/100及1/1000。 | 浮点列表 | 无 |
| lr_warmup | 否 | 是否对学习率进行Warmup。 | BOOL | false |
| lr_warm_up_epochs | 否 | 学习率Warmup的轮数。 | FLOAT | 1 |
| train_data | 是 | 训练数据文件的OSS路径。 | oss://path/to/train_*.tfrecord | 无 |
| test_data | 是 | 训练过程中评估数据的OSS路径。 | oss://path/to/test_*.tfrecord | 无 |
| train_batch_size | 是 | 训练的Batch_size。 | INT,例如32。 | 无 |
| test_batch_size | 是 | 评估的Batch_size。 | INT,例如32。 | 无 |
| train_num_readers | 否 | 训练数据并发读取线程数。 | INT | 4 |
| model_dir | 是 | 训练使用的OSS目录。 | oss://path/to/model | 无 |
| pretrained_model | 否 | 预训练模型的OSS路径。如果指定该参数值,则在此模型基础上Finetune。 | oss://pai-vision-data-sh/pretrained_models/inception_v4.ckpt | “” |
| use_pretrained_model | 否 | 是否使用预训练模型。 | BOOL | true |
| num_epochs | 是 | 训练迭代轮数。取值1表示对所有训练数据都进行一次迭代。 | INT,例如40。 | 无 |
| num_test_example | 否 | 训练过程中评估数据条目数。取值 -1表示使用所有测试数据作为评估数据。 | INT,例如2000。 | -1 |
| num_visualizations | 否 | 评估过程可视化显示的样本数量。 | INT | 10 |
| save_checkpoint_epochs | 否 | 保存Checkpoint的频率,以Epoch为单位。取值为1表示每完成一次训练就保存一次Checkpoint。 | INT | 1 |
| save_summary_epochs | 否 | 保存Summary的频率,以Epoch为单位。 取值为0.01表示每迭代1%的训练数据就保存一次Summary。 | FLOAT | 0.01 |
| num_train_images | 否 | 总的训练样本数。如果使用自己生成的TFRecord,则需要指定该参数。 | INT | 0 |
| label_map_path | 否 | 类别映射文件。如果使用自己生成的TFRecord,则需要指定该参数。 | STRING | ”” |