
本文主要介绍了利用DAS的锁分析功能与SQL洞察功能进行死锁定位的方法。
背景信息
死锁是关系型数据库系统中最为常见的错误,出现在不同事务中同时对某些数据访问加锁时,都要等待对方请求中的数据而无法获取锁。数据库系统会自动牺牲回滚代价最小的事务,从而导致对应的写请求失败。更严重的情况是在大量死锁发生时,会导致数据库系统效率低下,大量进程堆积进而引发性能问题。正常情况下,死锁都是由于逻辑加锁的顺序导致的,也就是我们常说的ABA死锁。如下图所示: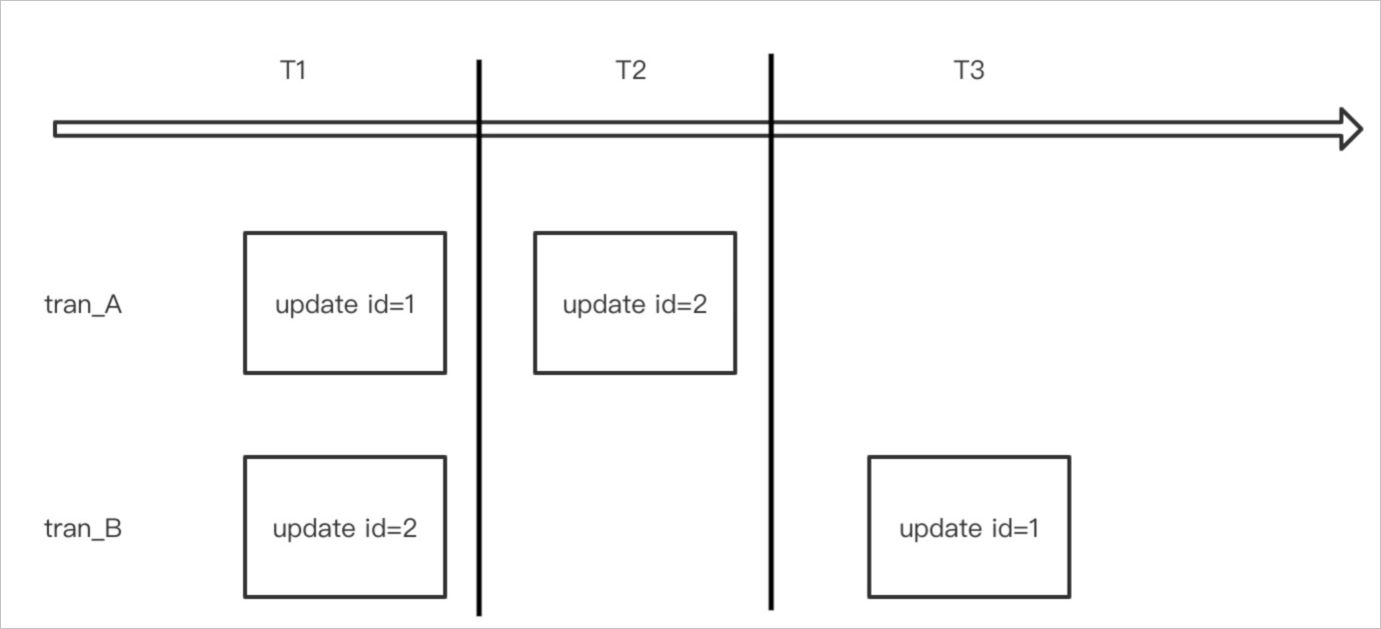 上图中tran_A与tran_B两个请求分别持有对方所需要的第二次update的行锁,就形成了死锁。如下图所示:
上图中tran_A与tran_B两个请求分别持有对方所需要的第二次update的行锁,就形成了死锁。如下图所示: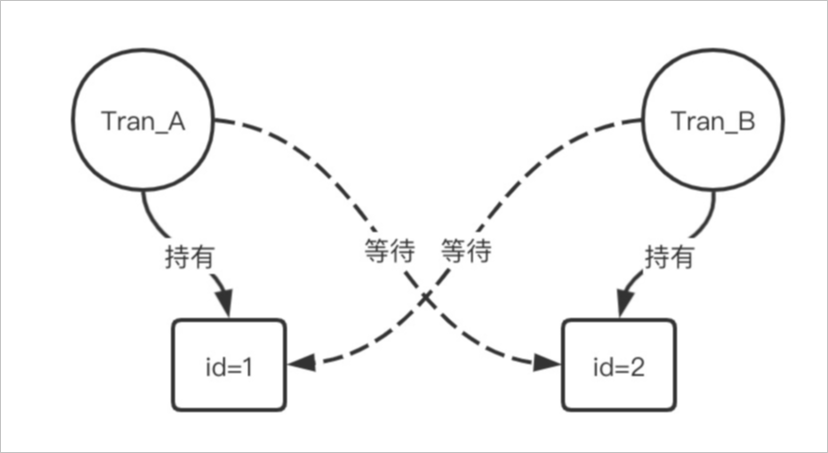 此时您的业务系统会收到如下报错信息:
此时您的业务系统会收到如下报错信息:
Error : Deadlock found when trying to get lock; try restarting transaction本文所说的死锁是指deadlock,而非事务锁造成的阻塞(block)。
死锁定位
您可以登录PolarDB控制台,在菜单中选择锁分析,单击创建分析。如果集群存在死锁,会在发现死锁列出现是。 目前诊断功能只能拉取最后一次死锁,同样是从innodb status中获取的。如果集群不重启,死锁信息会一直保留最后一组日志,所以需要确认诊断后的日志是不是存量死锁问题,也就是说发现的死锁不一定是新出现的死锁。
目前诊断功能只能拉取最后一次死锁,同样是从innodb status中获取的。如果集群不重启,死锁信息会一直保留最后一组日志,所以需要确认诊断后的日志是不是存量死锁问题,也就是说发现的死锁不一定是新出现的死锁。
发现死锁后,单击查看详情,会显示格式化后的死锁信息。如下: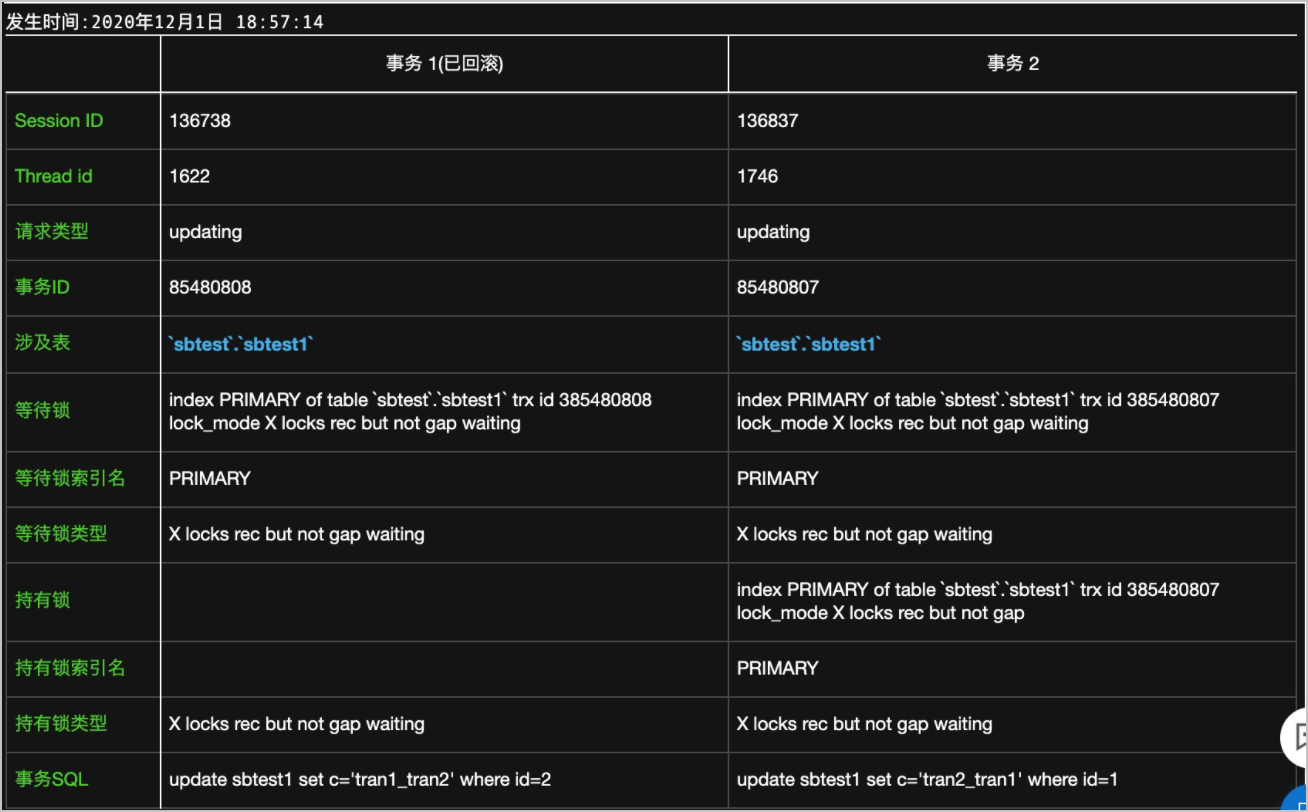
Thread id:线程ID,和SQL洞察中的线程ID对应。
涉及表:死锁出现的表。有时可能左右表不一致,是因为事务中请求的表不一致。
等待锁索引名:DML语句会将锁加在索引行上,所以获取不到的锁一定是在某个索引上。
事务SQL:引发死锁的SQL语句。
异常会话定位
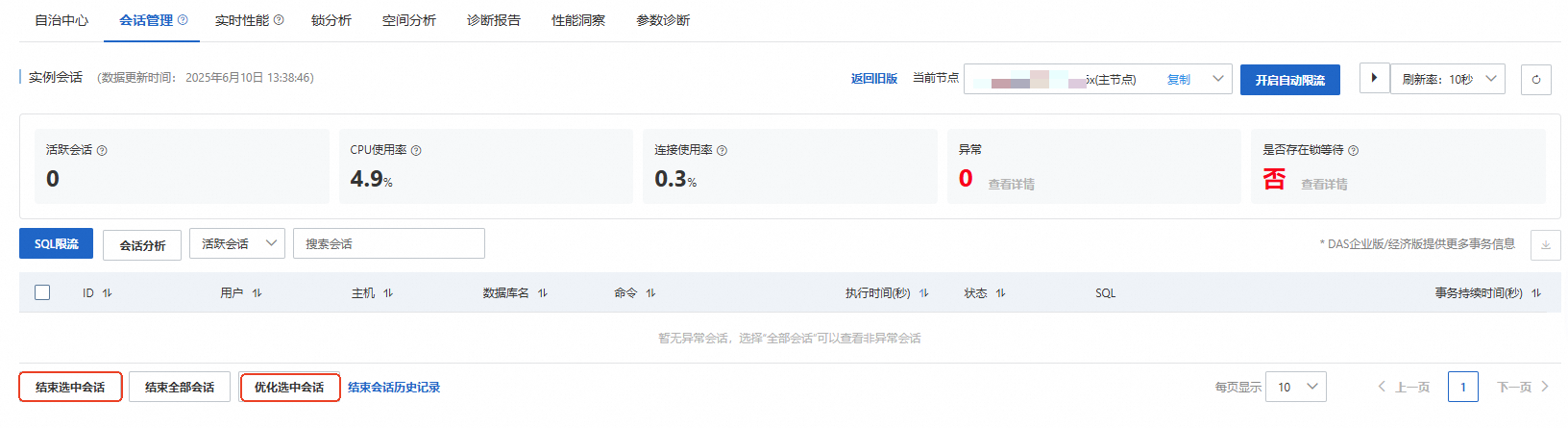
您可以在PolarDB控制台,菜单中选择会话管理。查看实例会话和会话统计的详细情况。执行SQL请求时,出现异常参数会话,您可点击选中当前异常会话,选择结束选中会话或选择优化选中会话来进行异常会话的分析设置。
事务流定位
事务流定位的前提条件是在死锁发生前,PolarDB控制台已经开启了SQL洞察功能,才能对执行过的语句进行定位。
通过死锁定位,可以获取到回滚的事务、发生死锁的语句、thread_id。同时也可以发现死锁的牺牲事务thread_id为1622,成功事务thread id为1746。登录PolarDB控制台,在菜单中的搜索页面先对牺牲事务进行查询定位: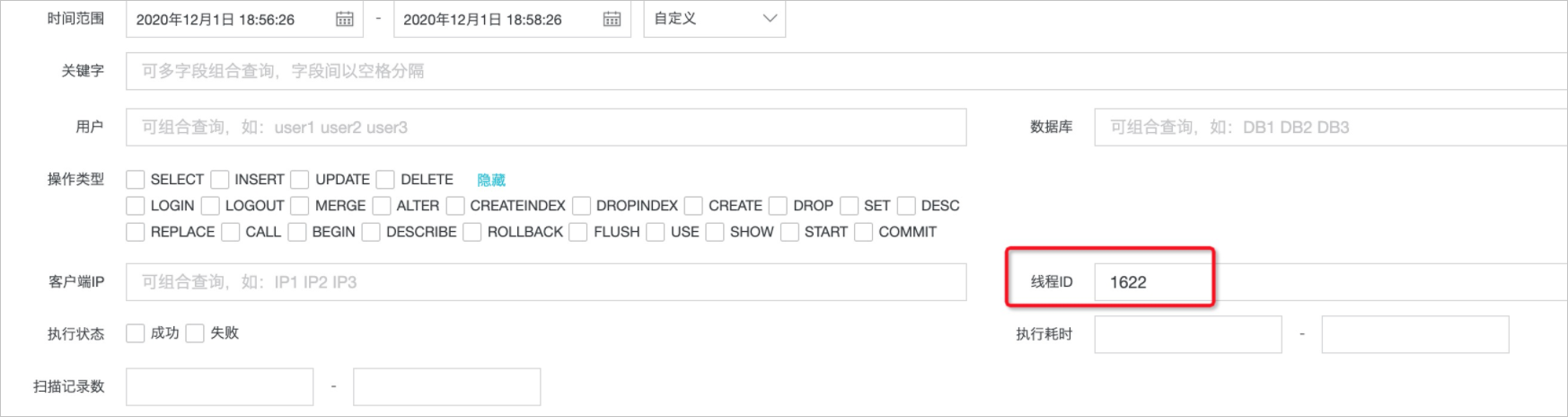 在日志列表中状态列显示为
在日志列表中状态列显示为失败(1213),error 1213就是死锁回滚的编码,可以用来定位发生回滚的事务。 日志列表默认按照秒级排序,如果要获取时序的事务流,需要通过执行时间(毫秒)进行排序。
日志列表默认按照秒级排序,如果要获取时序的事务流,需要通过执行时间(毫秒)进行排序。
日志列表中的SQL语句太多,将无法通过执行时间(毫秒)进行排序。需要继续缩小搜索的时间范围,减小返回的SQL数据。
然后再对执行成功的事务thread id为1746进行查询定位: 通过分析日志可获取事务时间线:
通过分析日志可获取事务时间线: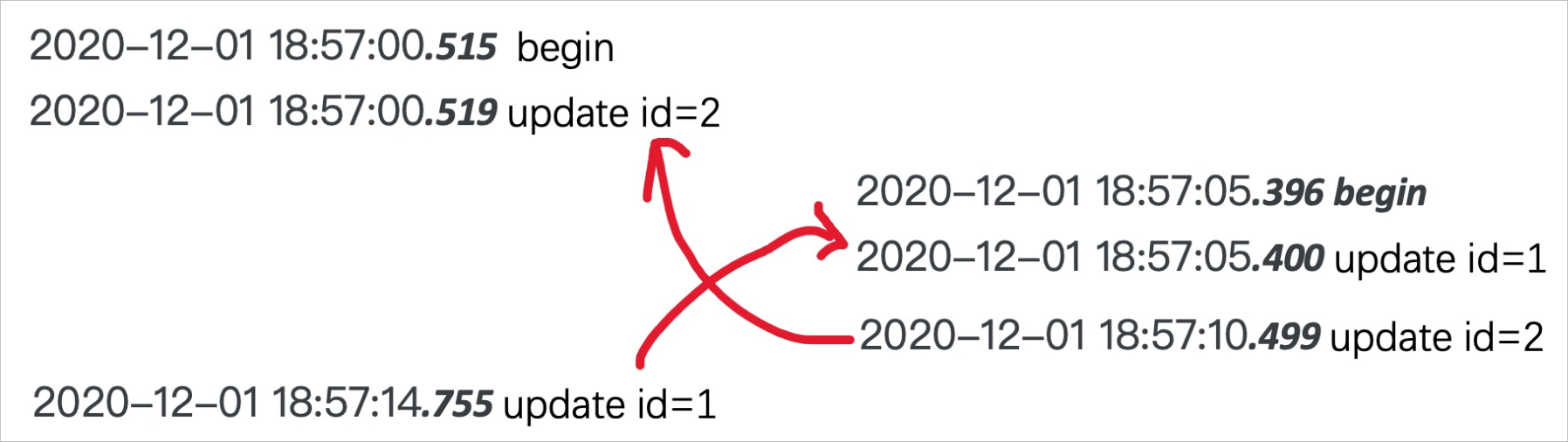
如果业务系统没有开启事务,则可能是在框架中配置的。正常情况下开始语句都是set autocommit=0,有begin开始事务的场景比较少。
至此死锁的事务流已经分析出来了,可以交由产品研发人员进行定位了。