本文介绍如何基于列存索引(IMCI)的实时分析能力快速搭建知识问答系统(RAG应用)。同时,结合PolarDB for AI归纳生成能力,有效解决大语言模型(LLM)在准确性和实时性方面的局限。通过提升问答场景下回复内容的实时性和准确性,构建出高效、精准且可靠的知识问答系统。
方案预览
RAG系统搭建流程架构图
PolarDB MySQL版已完全支持MySQL 9.0(The Vector Type,Vector Functions)原生向量检索语法。基于PolarDB IMCI作为信息检索组件,以及PolarDB for AI内置的通义千问大模型所提供的归纳生成能力,RAG系统的搭建流程图如下:

准备工作
PolarDB MySQL版集群要求如下:
产品版本为企业版且系列为集群版。
内核版本为MySQL 8.0.2,且修订版本为8.0.2.2.27及以上。
增加列存索引只读节点(IMCI)和增加AI节点,并设置AI节点的连接数据库账号。创建流程请参见添加只读列存节点和开启PolarDB for AI功能。
说明若您在购买集群时已添加列存索引只读节点与AI节点,则可以直接为AI节点设置连接数据库的账号。
RAG系统搭建流程
构建离线向量索引数据
创建文档知识库
您需要先将文档上传到数据库,并解析文档内容,再做文本向量化的工作。
上传文档数据
说明如需批量上传并解析文档至数据库,可以采用多次上传的方式实现。以下示例仅展示单条文档的解析过程。
上传文档至数据库存储的SQL语句如下:
/*polar4ai*/UPLOAD FILE docfile WITH ( file_id = 'Polar4AI', file_type = '.docx', src_file_location = 'https://xxx.aliyuncs.com/Polar4AI-Introduction.docx', dest_file_name = 'Polar4AI-Introduction', metadata = '{}', overwritten = 1 );重要src_file_location:URL地址替换为您实际的存储的文档地址。
file_type:目前仅支持Microsoft Word.docx格式。
WITH()中的参数说明如下:参数
说明
示例值
file_id
文件主键(不可重复)。
'Polar4AI'
file_type
文件类型。
'.docx'
src_file_location
文件URL地址。
'https://xxx.aliyuncs.com/Polar4AI-Introduction.docx'
dest_file_name
目标文件名(文章名称可重复,暂不支持存储路径/),支持自定义设置名称。
'Polar4AI-Introduction'
metadata
元数据,暂时保留。
说明后续会扩展,暂时无需关注。
'{}'
创建文档元数据表
在数据库中创建元数据表SQL语句如下:
CREATE TABLE file_id_list_rag ( file_id varchar(256) PRIMARY KEY );更新元数据表SQL语句如下:
INSERT INTO file_id_list_rag(file_id) VALUES ('Polar4AI');文档元数据表中参数说明如下:
参数
说明
示例值
file_id
UPLOAD FILE中指定的文件主键。
'Polar4AI'
文档切片和向量化
创建临时表
存储文本转向量模型生成的切片和向量的临时表使用固定的参数名称和类型,SQL语句如下:
说明文本向量化后生成的临时表由于不具备列存索引特性,无法直接利用列存索引实现加速功能。因此,在实际业务处理中,需要将文本数据构建至具有列存索引功能的表中,以达到向量索引加速的目的,详见后续步骤构建PolarDB IMCI向量索引。
/*polar4ai*/CREATE TABLE file_index_table_rag( chunk_id varchar(265), chunk_content text_ik_smart, file_id varchar(256), file_name varchar(256), vecs vector_768, PRIMARY KEY(chunk_id) );临时表中参数说明如下:
参数
说明
示例值
file_id
文件主键,用于溯源文本内容。
'Polar4AI'
file_name
文件名、文件标题与内容相关的语句。
'Polar4AI-Introduction'
chunk_content
切片文本,使用分词器进行分词,此处可使用
text_ik_smart(粗粒度拆分的词) /text_ik_max_word(细粒度拆分的词)等分词器进行分词。文档文本内容
vecs
切片向量,使用
_polar4ai_text2vec模型将切片文本转为向量。[0.1, 0.2, ...]
chunk_id
{file_id}-{chunk_order},对每一个chunk设置的主键id,在同一文件内按序递增。
'Polar4AI-1'
文本转向量
从文档元数据表中选取需要进行分词和向量化的
file_id,解析文档内容并使用_polar4ai_text2vec模型的predict方法将文档切片转为向量:/*polar4ai*/SELECT chunk_id, file_id, file_name, chunk_content FROM predict(model _polar4ai_text2vec, SELECT file_id FROM file_id_list_rag) WITH ( x_cols='chunk_content', primary_key='file_id', resource='file', mode='async', to_chunk=1, headers_to_split_on=2, chunk_size=1024, chunk_overlap=64, separator='' ) INTO file_index_table_rag;_polar4ai_text2vec为文本转向量模型,目前仅支持输出768维向量。WITH()中的参数说明如下:参数
说明
示例值或范围
x_cols
用于存储文本的字段。
chunk_content
primary_key
文件列表的主键,文档ID。
id
mode
文档数据的写入模式,目前仅支持async(异步)模式。
async
resource
在文件解析流程中为file模型。
file
to_chunk
文件中的文本是否进行切片。
0或1
headers_to_split_on
to_chunk=1时按照指定标题层级进行切分
当
headers_to_split_on值为-1时,对文件中所有层级标题进行分块。当
headers_to_split_on值为x时,对文件中小于等于x层级的标题进行分块。
-1 ≤ x ≤6为整数值
chunk_size
文本切分的最大长度。
chunk_size ≥ 50
chunk_overlap
相邻两个切片之间的重叠字符数量。
chunk_overlap ≤ chunk_size
separator
分块内切片之间的分隔符。
'' /','/','等
构建PolarDB IMCI向量索引
创建向量索引表
使用MySQL原生的向量类型和语法创建向量索引表,同时构建列存索引:
CREATE TABLE vector_index ( chunk_id varchar(265), chunk_content text, file_id varchar(256), file_name varchar(256), vecs vector(768), PRIMARY KEY(chunk_id) ) COMMENT 'columnar=1';构建向量索引
首先需要从上一节的临时表中查询切片和向量的中间结果:
/*polar4ai*/SELECT * FROM file_index_table_rag;将中间结果通过string_to_vector表达式写入向量索引表:
INSERT INTO vector_index (file_name,file_id,vecs,chunk_content,chunk_id)VALUES ("file_name","file_id",string_to_vector("[...]"),'chunk_content',"chunk_id");
在线RAG查询
问题向量化
将问题文本进行在线向量化的SQL语句如下:
/*polar4ai*/SELECT * FROM predict(model _polar4ai_text2vec, SELECT 'question') with();PolarDB IMCI向量召回
使用
distance表达式并借助IMCI加速KNN向量检索,召回相似度最高的K个向量和文本切片SELECT /*+ SET_VAR(use_imci_engine=forced) */ file_name,chunk_content, distance(string_to_vector("[...]"), vecs, "COSINE") AS d FROM vector_index ORDER BY d limit 5;说明为确保业务有效请在
distance(string_to_vector("[...]")中填写问题向量化后的合法值。LLM基于Prompt生成回答
将问题和召回的文本切片组成Prompt,调用PolarDB for AI内置的通义千问模型进行在线推理,生成回答:
说明问题文本切片和召回文本切片通过累加的方式组成Prompt,实现在线推理。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_tongyi, SELECT 'prompt') with ();示例
输入Prompt问题:你是谁,完成在线推理。

RAG系统示例
参照上述流程,您可以借助PolarDB IMCI和PolarDB for AI快速搭建一个RAG(Retrieval-Augmented Generation)系统。本文中提供一个简单的示例代码rag_service_demo-master.zip,该示例展示了如何利用IMCI的一些官方文档创建文档知识库,并在PolarDB IMCI上构建向量索引。随后,通过集成PolarDB for AI的通义千问模型,搭建出一个RAG系统,并提供一个简单的Web服务以支持问答交互。通过这个RAG系统,您可以使大语言模型(LLM)在IMCI相关领域内准确回答问题。
运行环境
要运行该示例,您需要具备以下资源配置:
PolarDB MySQL企业版集群:包含列存节点(IMCI)和AI节点,集群版本8.0.2.2.27。
ECS实例:系统镜像为Alibaba Cloud Linux 3.2104 LTS 64位,Python版本为3.9.20。
OSS存储服务。
上述系统架构中,列存节点(IMCI)负责向量索引的构建,AI节点提供文本向量化和大语言模型(LLM)能力,ECS实例用于运行RAG系统和Web服务的部署,OSS则用于上传和存储知识库文档。其中,PolarDB集群和OSS作为系统运行的必要组件,您也可以根据实际需求选择其他合适的环境来运行RAG系统和部署Web服务。
您需要将上述资源的相关访问配置更新到1_upload_file.py、2_vectorization.py和3_rag.py中,然后参见RAG系统搭建流程这一章节,部署和运行完成正确配置的系统。
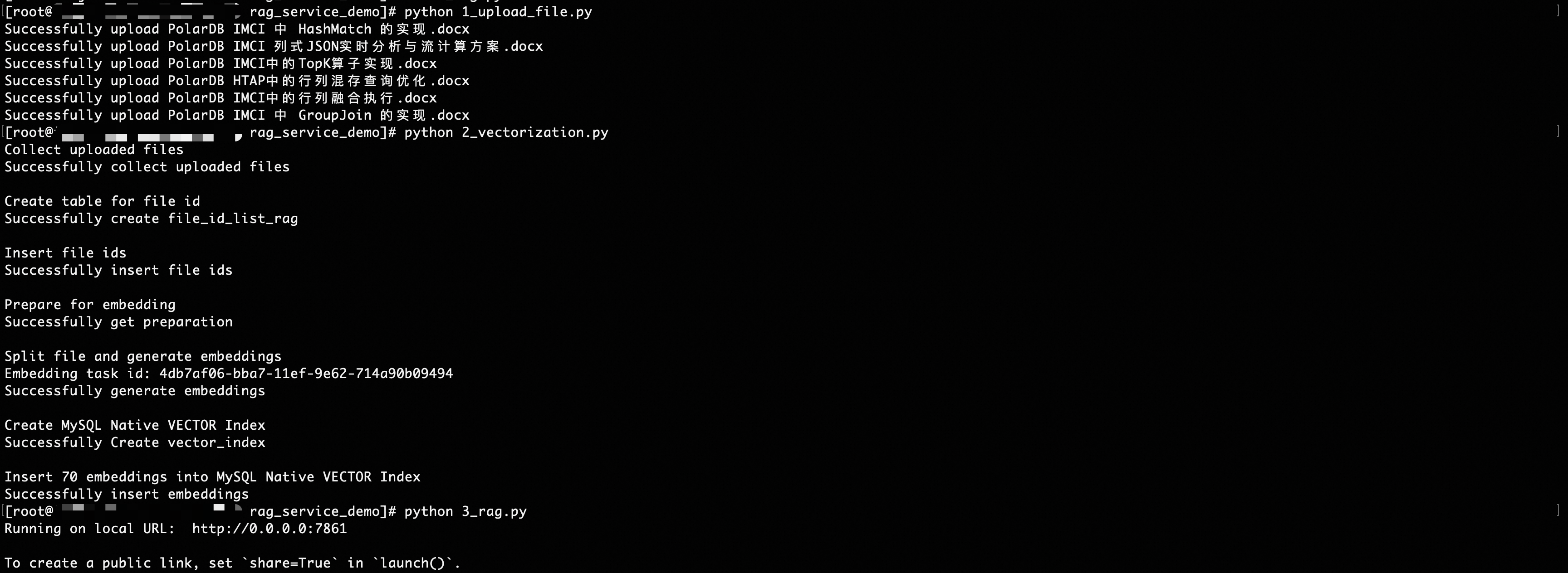
运行RAG系统
在ECS上根据requirements.txt正确安装python环境后,如下图所示依次运行:
下载对应驱动包。
pip install -r requirements.txt1_upload_file.py创建文档知识库2_vectorization.py对文档切片并向量化,并在PolarDB IMCI上构建向量索引。3_rag.py启动RAG系统的Web服务。
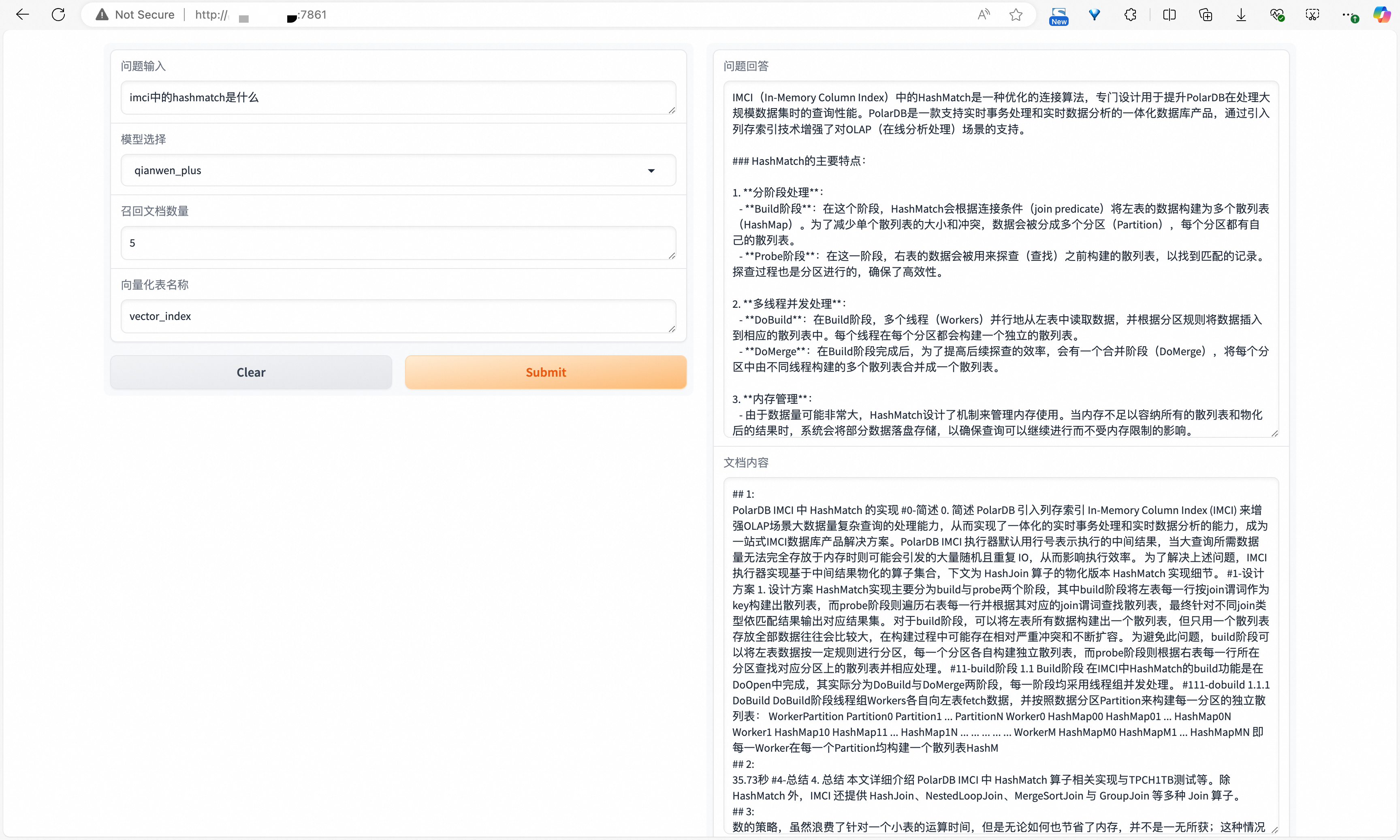
示例
HashMatch是IMCI专有的一个算子,对于问题IMCI中的hashmatch是什么,RAG系统可以从PolarDB IMCI中召回相似文档切片,并作为Prompt提供给LLM,使LLM也能正确回答有关HashMatch的问题。