
随着业务数据量的激增,海量数据的存储成本与分析效率成为许多企业面临的核心挑战。为应对这一场景,PolarDB MySQL版提供了X-Engine列存表功能。该功能基于列式存储、高效压缩和并行计算技术,可将您的数据存储成本降低至原始数据的10%,同时将分析查询性能提升一个数量级,帮助您在完全兼容MySQL生态的同时,实现海量数据的低成本归档与高性能实时分析。
功能简介
X-Engine列存表采用计算存储分离架构,计算资源和存储资源可以独立弹性扩展,为您提供PB级的海量数据处理能力。其存储层基于分布式文件系统和对象存储(OSS)实现,计算层则通过对查询优化器、执行算子和存储引擎的深度优化,实现高性能分析。
技术架构
PolarDB整体架构
PolarDB采用存算分离的架构,其底层为分布式存储层。通过ParallelRaft协议,系统确保多副本的一致性,并且透明地支持OSS对象存储。计算节点由一个读写节点(RW)和一个或多个只读节点(RO)组成,同时支持InnoDB和X-Engine两种引擎。数据库代理充当应用程序与计算节点之间的桥梁,提供读写分离及负载均衡的功能。

列存表架构
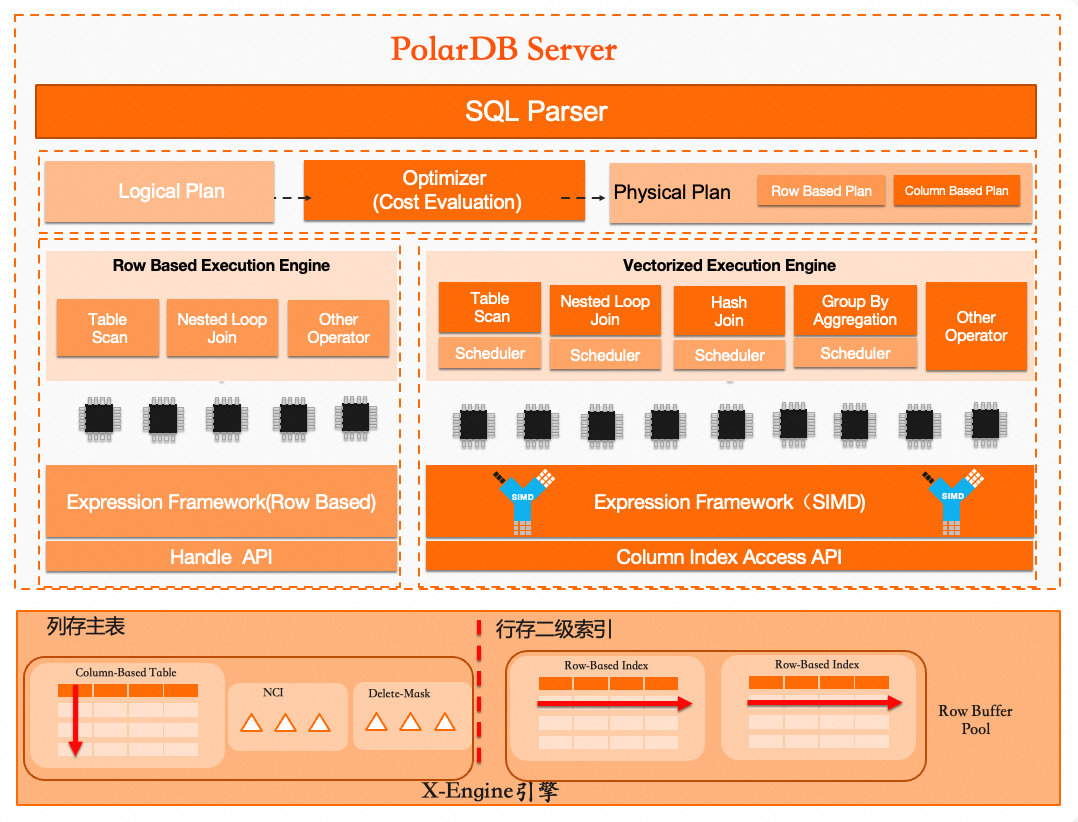
其核心技术组件包括:
查询优化器:内置面向行列混合存储的代价优化器(CBO),能够根据查询请求的代价,智能判断并自动选择最优的执行计划(选择行存或列存)。
执行算子:采用面向列存的向量化和并行执行技术,通过批处理模式大幅度提升单表和多表关联的分析查询速度。
存储引擎:支持实时的事务更新。主表采用列式存储,并通过NCI(Non-Clustered Index)组件保障快速更新能力。通过Delete-mask机制标记删除数据,在不影响实时写入的同时提供高效的并行查询。同时,其行存二级索引可以快速过滤无效数据,进一步提升查询效率。
方案对比
为帮助您理解并选择合适的表类型,下表对比了传统行存表(如InnoDB)与PolarDB列存表的核心差异:
对比维度 | 行存表(X-Engine引擎) | 列存表 |
数据组织方式 | 以行为单位连续存储,一行数据的所有列存储在一起。 | 以列为单位连续存储,一列数据的所有值存储在一起。 |
数据压缩率 | 中。相较于InnoDB最高可将数据压缩至原始大小的3/10。 | 高。通过列式存储和专用编码(如字典编码),相较于InnoDB可将数据压缩至原始大小的1/10。 |
查询性能 | 点查性能高。适用于根据主键或索引快速读取单行或少数行数据的场景(OLTP)。 | 分析性能强。仅需读取查询涉及的列,有效减少I/O。同时配合向量化并行计算,聚合分析性能比行存表提升一个数量级。 |
更新与删除性能 | 高。直接定位到行进行修改。 | 相对较低。具备实时更新能力,借助于NCI组件,可以快速定位到需要修改的记录。 |
适用场景 | 联机事务处理(OLTP),如高并发的增、删、改、查操作。 | 联机分析处理(OLAP),如数据归档、报表生成、即席查询、海量数据聚合分析。 |
功能优势
高成本效益:通过列式存储、高效编码和高压缩比算法,并结合OSS的低成本存储介质,可将海量数据存储处理成本降低90%。
高性能实时分析:数据写入后可立即用于分析查询。利用多核并行、向量化及MPP技术,查询性能媲美专用分析型数据库,可满足严苛的实时分析需求。
100%兼容MySQL:提供与MySQL一致的数据类型系统和协议,支持灵活的类型转换,您现有的应用和工具无需改造即可接入。
独立的弹性伸缩:计算与存储分离的架构允许计算节点和存储空间独立按需扩展,从容应对业务峰值和数据增长。
强大的宽表支持:单表最多可支持10000列,满足大宽表存储和高并发写入的业务需求。
出色的易用性:在单一数据库引擎内同时支持高压缩比存储和高性能分析,并提供完整的DDL和DML操作支持,简化了您的技术栈和运维管理。
应用场景
海量历史数据低成本归档
业务痛点:随着业务增长,核心数据库中的历史订单、日志、流水等数据急剧膨胀,占据了大量昂贵的存储空间。传统的数据迁移方案虽然能降低成本,但会导致数据离线,无法直接在线查询,增加了数据使用的复杂度。
解决方案:推荐使用列存表进行在线数据归档。您可以将行存表(InnoDB)中的冷数据或整个历史数据表迁移至同一PolarDB集群内的列存表中。
核心价值:
成本骤降:得益于高达10:1的压缩率和对低成本存储介质(如OSS)的利用,存储成本可降低90%。
数据在线:归档数据始终保持在线可用,您可以随时通过标准SQL对其进行查询和分析,无需复杂的数据回迁过程。
业务无感:对于应用层而言,只是操作一张普通的MySQL表,无需改造。
构建专用数据仓库
业务痛点:企业在搭建专用数据仓库时,常面临高昂的硬件成本、复杂的数据同步链路(ETL)以及较高的运维门槛,尤其是在引入新的技术栈(如ClickHouse)时。
解决方案:依托于PolarStore的海量数据存储能力,可将来自多个上游数据源的数据汇聚于此,并统一使用X-Engine列存表进行存储,您可以在享受海量、低成本存储能力的同时,获得实时的聚合分析性能。
核心价值:
成本与复杂度显著降低:无需采购昂贵的专用硬件或引入异构分析系统,在熟悉的MySQL生态内即可构建数据仓库,有效简化了技术栈和运维管理。
实时数据分析:支持将上游数据实时汇聚至列存表中进行分析,避免了传统ETL方案带来的T+1数据延迟。
海量数据处理能力:依托于X-Engine的存储架构和高效压缩,能够以低成本存储和处理PB级海量数据。
联邦查询分析
业务痛点:企业的业务数据通常分散存储,一部分在PolarDB等在线数据库中,另一部分以Parquet、ORC等开放格式存储在对象存储OSS上。要对这两部分数据进行联合分析,通常需要复杂的ETL过程将OSS数据导入数据库。
解决方案:利用PolarDB的外表功能,直接关联OSS上的数据。
核心价值:
原地分析:无需移动或导入数据,直接在PolarDB中为OSS上的文件创建外表,即可用SQL进行查询。
联邦查询:可以轻松地将PolarDB内的本地表(行存或列存)与OSS外表进行
JOIN操作,实现对在线数据和离线数据的统一分析。
性能测试报告
以下性能数据均在特定测试环境下得出,为评估列存表的收益提供参考。
本文的TPC-H的实现基于TPC-H的基准测试,并不能与已发布的TPC-H基准测试结果相比较,本文中的测试并不完全符合TPC-H的所有要求。
数据装载性能
以下数据基于32核256 GB规格的测试环境,使用TPC-H和Airline数据集,对比了列存表与ClickHouse、Doris在数据装载和存储方面的表现。
装载速度
TPC-H数据集:列存表装载速度达571万行/秒,写入吞吐50 GB/min,约为ClickHouse的2.7倍。
Airline数据集:列存表装载速度达430万行/秒,写入吞吐27 GB/min,约为ClickHouse的2倍。
数据集 | ClickHouse(万行/秒) | Doris(万行/秒) | 列存表(万行/秒) |
TPC-H | 210 | 454 | 571 |
Airline | 140 | 215 | 430 |
存储空间
TPC-H数据集:原始数据100 GB,列存表压缩比达4倍。
Airline数据集:原始数据75 GB,列存表压缩比达18倍。
以下为Airline数据集(原始数据75 GB)的存储空间对比:
类型/产品 | ClickHouse | Doris | 列存表 |
存储空间(GB) | 9.29 | 4.49 | 3.97 |
压缩比 | 约8倍 | 约16倍 | 约18倍 |
TPC-H查询性能
TPC-H 100 GB数据集性能测试,列存表22条查询的总耗时为17.994秒,ClickHouse为76.9秒,列存表整体性能约为ClickHouse的4.3倍。
查询
列存表(秒)
ClickHouse(秒)
Q1
1.175
2.2
Q2
0.178
0.9
Q3
0.577
1.6
Q4
0.433
1.3
Q5
0.522
3.3
Q6
0.366
0.32
Q7
0.633
1.7
Q8
0.528
1.8
Q9
2.817
12
Q10
0.935
2.3
Q11
0.218
0.66
Q12
0.535
1.4
Q13
1.255
4.4
Q14
0.442
0.3
Q15
0.889
0.42
Q16
0.553
0.6
Q17
0.738
4.2
Q18
2.381
4.3
Q19
0.759
2
Q20
0.453
0.6
Q21
1.308
29.6
Q22
0.299
1
合计
17.994
76.9
多节点并行分析:在TPC-H 1 TB数据集的性能测试中,列存表通过多节点并行加速,查询总耗时从单节点的1420.551秒降至6节点的167.948秒。
查询
1台(秒)
2台(秒)
4台(秒)
6台(秒)
Q1
76.849
36.831
23.031
20.022
Q2
5.841
2.805
1.527
1.09
Q3
133.69
26.131
15.833
4.75
Q4
51.466
19.02
3.353
2.362
Q5
52.965
26.844
13.715
4.269
Q6
34.577
21.831
35.17
11.274
Q7
75.996
29.659
17.279
5.717
Q8
54.989
28.922
15.651
3.375
Q9
155.33
78.216
40.38
25.983
Q10
72.222
31.659
17.177
4.594
Q11
4.149
2.049
1.351
1.069
Q12
50.997
27.79
16.207
2.977
Q13
73.009
31.742
17.605
16.255
Q14
36.887
22.093
4.475
3.778
Q15
66.217
38.628
7.583
6.451
Q16
11.493
4.49
2.528
1.758
Q17
59.225
37.101
11.434
8.767
Q18
132.604
53.578
17.164
10.797
Q19
72.794
38.416
23.759
16.651
Q20
42.621
22.432
5.62
4.768
Q21
149.245
54.803
12.758
8.793
Q22
7.385
5.684
2.972
2.448
合计
1420.551
640.724
306.572
167.948