
PolarDB MySQL版集群的每种集群规格都有对应的最大存储容量,存储空间会因数据、日志及临时文件的持续增长而趋于饱和,这可能导致集群被锁定为只读状态,影响业务正常运行。为了帮助您有效管理存储资源并保障集群的稳定性,本文将详细介绍存储空间的构成,并提供查看用量、清理各类文件及回收空间的具体方法。
存储空间构成
通过了解PolarDB MySQL版存储空间的构成,您可以进行有效的管理,从而准确地定位问题并采取恰当的优化措施。

数据文件:存储您的数据表和索引等业务数据。
日志文件:主要包括Binlog日志、Redo日志和Undo日志,在执行大事务或高并发的写入操作时会使这些日志文件快速增长。
说明PolarDB MySQL版集群的Binlog日志默认关闭,使用更高效的物理日志(Redo Log)作为替代。若您的集群未开启Binlog,可无需关注。
临时文件:在执行排序(ORDER BY)、分组(GROUP BY)或关联查询等操作时,会生成临时表文件。此外,未提交的大事务也会产生临时的Binlog缓存文件。
系统文件:存储数据库运行所必需的核心组件,如数据字典、事务信息、双写缓冲区等。这部分文件是InnoDB引擎自我管理的基础,对保障数据一致性和集群恢复至关重要,您无法直接操作。
查看存储空间使用情况
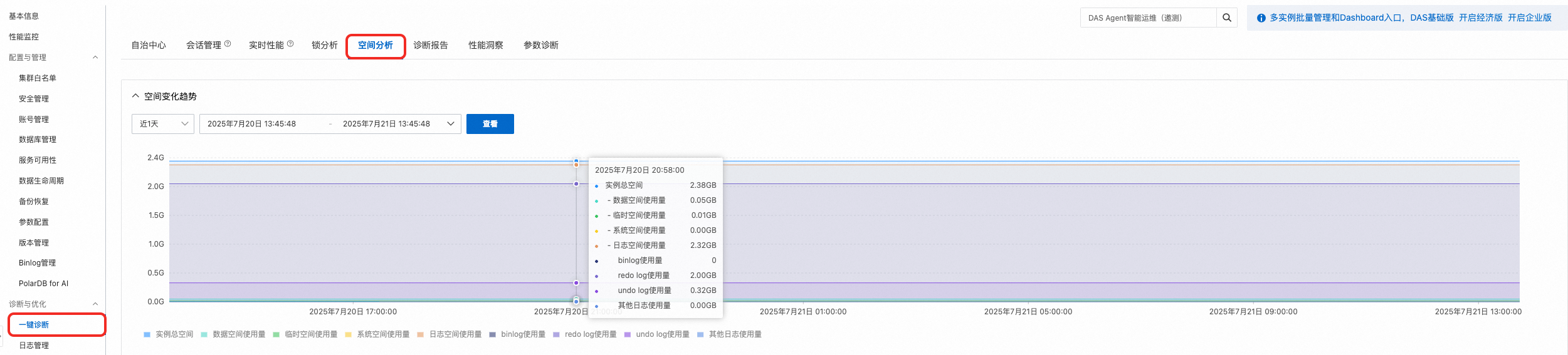
您可以通过以下两种方式查看集群的存储空间使用情况:
前往PolarDB控制台,在目标集群的基本信息页面的数据库分布式存储区域,查看当前集群的存储容量。

前往PolarDB控制台,在目标集群的页面的空间分析页签中,查看指定时间点的存储空间使用情况。
清理数据文件与回收表空间
PolarDB MySQL版可能因数据文件长时间未进行整理而导致存储空间占用过多。此外,在使用DELETE命令删除数据后,系统仅会将记录的位置或数据页标记为可复用,并不会直接缩小表文件的大小,这将导致大量空间碎片的产生,从而使存储空间持续被占用。
在进行清理数据文件时,控制台界面更新有延迟,请您耐心等待。
清理文件
对于不再需要的表,使用TRUNCATE TABLE或DROP TABLE命令可以迅速释放其占用的全部空间。
操作前请确保数据已备份,以免造成数据丢失。
回收表空间
对于存在大量碎片且需要保留的表,可以在业务低峰期执行OPTIMIZE TABLE命令。该操作会重建表,消除碎片并回收空闲空间。您也可以通过DMS工具执行此优化,DMS支持限流,对业务负载的影响更小,但执行速度相对较慢。
注意事项
当目标表的碎片率较低时,执行
OPTIMIZE TABLE命令不能显著降低表空间大小。您可以在information_schema.tables视图中的DATA_FREE字段来查看目标表的碎片率。执行
OPTIMIZE TABLE命令时,表数据会复制到新建的临时表中,这会临时增加集群的存储空间使用率。对于不包含全文索引的表,
OPTIMIZE TABLE语句使用Online DDL方式执行,支持并发读写。对大表执行
OPTIMIZE TABLE操作会带来突发的IO和Buffer使用量,可能会导致锁表和抢占资源,在业务高峰期执行该操作可能会导致集群不可用以及监控断点,建议在业务低峰期执行该操作。
方案对比
您可以根据实际业务场景选择适合您的回收方式。
回收表空间的方式 | 是否允许并发读写 | 执行速度 | 是否支持限流 | 适用场景 |
| 是 | 快 | 否 | 在业务负载较轻、对执行效率要求较高的情况下, |
DMS回收表空间 | 是 | 慢 | 是 | 在对集群负载敏感、对执行效率不敏感的情况下,DMS工具能够以对业务影响较低的方式对表空间进行回收,降低空间回收操作对集群性能的影响。 |
操作流程
OPTIMIZE TABLE命令回收表空间
您可以通过以下命令来回收表空间
OPTIMIZE TABLE [Database1].[Table1],[Database2].[Table2][Database1]和[Database2]为数据库名称,[Table1]和[Table2]为表名。在InnoDB引擎中执行
OPTIMIZE TABLE命令时,会出现提示信息Table does not support optimize, doing recreate + analyze instead,该信息是正常返回的结果,您可以忽略该信息,确认返回ok即可。关于更多OPTIMIZE TABLE语句的详细信息,请参见OPTIMIZE TABLE Statement。
DMS回收表空间
登录数据库:您可以前往PolarDB控制台,单击目标集群基本信息页面右上角的登录数据库按钮,在数据管理DMS平台中登录PolarDB MySQL版集群。
回收表空间:在左侧选择目标集群ID,双击目标库,右键单击任意表名,然后选择批量操作表。在批量操作表页面,勾选需要释放空间的表名,并单击表维护>优化表。
清理日志文件
PolarDB MySQL版集群可能由于大事务的处理而快速生成Binlog日志、Redo日志或Undo日志,从而导致存储空间被大量占用或占满的情况。在此情况下,建议您优先考虑扩展存储空间容量,随后再排查快速生成日志文件的原因。
在进行清理Binlog日志、Undo日志或Redo日志时,控制台界面更新有延迟,请您耐心等待。
Binlog日志
PolarDB MySQL版集群的Binlog日志默认关闭,使用更高级别的物理日志(Redo Log)作为替代。若您的集群未开启Binlog日志,请参考Redo日志与Undo日志的清理方案。
保留策略
Binlog文件有如下两种保存策略:
开启Binlog后,文件默认保存3天,超过3天的文件会被自动删除。
说明在2023年11月23日前购买的PolarDB MySQL版集群,其Binlog文件默认保存两周(14天)。
在2024年1月17日前购买的PolarDB MySQL版集群,其Binlog文件默认保存一周(7天)。
关闭Binlog后,已有的Binlog日志文件会一直保留,不会自动删除。
说明若需要删除Binlog文件,您需要在开始Binlog的状态下,将Binlog的保存时长参数(
loose_expire_logs_hours或binlog_expire_logs_seconds)设置为一个较小的值,等文件超过保存时长自动删除后再关闭Binlog。
修改保存时长
修改Binlog文件的保存时长不会造成连接闪断,也不需要重启集群。
如果修改保存时长而导致大量Binlog文件需要被清除(如10 TB),则在清除时可能会造成短时间的数据库写入异常。因此,在Binlog文件较大的情况下,建议在业务低峰期进行操作,并分多次缩短Binlog的保存时长,每次清除一部分Binlog数据。
已被清除的Binlog文件被删除后无法进行恢复。
您可以通过如下方式修改Binlog文件保存时长:
MySQL 5.6:您可以通过修改
loose_expire_logs_hours(取值范围为0~2376,单位为小时,默认值为72)的参数值来设置Binlog的保存时长。0表示不自动删除Binlog文件。MySQL 5.7或MySQL 8.0:您可以通过修改
binlog_expire_logs_seconds(取值范围为0~4294967295,单位为秒,默认值为259200)的参数值来设置Binlog的保存时长。0表示不自动删除Binlog文件。
清理历史文件
修改Binlog保存时长参数(loose_expire_logs_hours或binlog_expire_logs_seconds)后,集群中的历史Binlog文件不会立即自动清除。在此情况下,如需清除历史文件,您可以通过以下三种方法之一进行操作:
等待自动清除:当集群中最后一个Binlog文件达到最大存储大小(参数
max_binlog_size)时,切换至新的Binlog文件后,这些历史Binlog文件将会被自动清除。手动清除:使用高权限账号执行
flush binary logs命令可以立即触发Binlog文件切换并清除过期的Binlog文件。重启集群:重启集群后,系统将自动清除历史的Binlog文件。
Undo日志
PolarDB MySQL版集群的Undo日志承担着多版本并发控制(MVCC)中历史版本的作用。因此,当存在未提交的事务(无论在只读节点还是读写节点)持有旧的读视图(Read View)时,将会阻碍Undo日志的清理过程,从而导致空间的持续积累。
识别并终止未提交的事务
登录数据库:您可以前往PolarDB控制台,单击目标集群基本信息页面右上角的登录数据库按钮,在数据管理DMS平台中登录PolarDB MySQL版集群。
查找未提交的事务:执行如下命令,检查当前是否存在长时间未提交的事务。
SELECT * FROM INFORMATION_SCHEMA.innodb_trx;需重点关注
trx_started(事务开始时间)时间很早,或trx_state(事务状态)长时间处于RUNNING状态的事务,并记录其trx_mysql_thread_id(线程ID)的值。终止事务:在确认不影响业务的前提下,执行KILL命令终止目标事务。
kill [线程ID];
查看后台清理进展
在清理完成事务所对应的线程后,您需要确认当前Undo history的推进情况。如果发现Undo history长度依然持续快速增长,则需要调优后台清理(Purge)的性能。
当写入压力大时,PolarDB的策略是优先保证当前的写入性能。此时,可能会导致Undo日志的清理滞后。
监控清理进度:执行以下命令,观察
Undo history的长度。SELECT COUNT FROM INFORMATION_SCHEMA.innodb_metrics WHERE name = 'trx_rseg_history_len';如果该值大于100万,或者几分钟的时间内,该值还在不断地上升,并且当前压力确实比较大,说明清理速度跟不上写入速度。
调整清理参数:提升清理效率。
将参数
innodb_purge_batch_size的值调大,使每次清理的批次更大。将参数
innodb_purge_threads的值调大,增加清理线程数,建议跟集群规格中的CPU核数保持一致。说明该操作会重启集群,建议在业务低峰期操作。
回收占用空间
当Undo history长度下降并稳定后,若您希望清理Undo日志所占用的空间,可以开启Undo truncate功能。
Redo日志
PolarDB MySQL版集群使用Redo日志替代Binlog日志,以实现主节点与只读节点之间的数据同步。
在不考虑日志备份的情况下,本地Redo日志会占用范围为2 GB至11 GB的存储空间,最高可达11 GB。其中包括缓冲池中的8个Redo日志(占用8 GB)、正在写入的Redo日志(占用1 GB)、提前创建的Redo日志(占用1 GB)以及最后一个Redo日志(占用1 GB)。
在考虑日志备份的情况下,本地Redo日志会在备份完成后保留约一个小时。如果写入速度较快(例如超过35 MB/s),则可能导致本地Redo日志的暂时性堆积。
清理规则
Redo日志不支持手动清理,通常在日志备份完成后会自动进行清理,无需手动干预。
您可以在PolarDB控制台调整集群的日志备份策略(默认为7天)。
清理临时文件
PolarDB MySQL版集群可能因复杂查询或大事务而生成大量的临时文件,从而导致存储空间被大量占用或占满的情况。此时,可能会出现错误提示,例如:error: 1114 The table '/home/mysql/log/tmp/#sqlxxx_xxx_xxx' is full。
您可以通过以下两种方式来进行处理:
终止会话
终止包含大量的Copy to tmp table或Sending data等信息的会话。
登录数据库:您可以前往PolarDB控制台,单击目标集群基本信息页面右上角的登录数据库按钮,在数据管理DMS平台中登录PolarDB MySQL版集群。
查看会话情况:执行如下命令查看数据库内的会话情况。
SHOW PROCESSLIST;找到目标会话:在DMS中,您可以单击查询结果的
State列,对该列的数据进行排序,查看是否有大量的Copy to tmp table或Sending data等信息,并记录该会话的ID值。终止会话:执行如下命令以终止目标会话。
kill [会话ID];重要执行终止会话操作前,请确保该会话不会影响正常运行的业务。
若通过以上步骤仍然不能释放存储空间,您可以重启集群中的各个节点,来释放临时文件占用的存储空间。
调整参数
前往PolarDB控制台,在目标集群的页面中,修改参数tmp_table_size和max_heap_table_size,以增加临时表空间大小。