
本文为您介绍PolarDB的X-Engine引擎如何在成本方面支撑钉钉业务,帮助企业快速实现在线协同办公。
背景信息
钉钉作为中国领先的企业IM工具,在中国有数以亿计用户,从钉钉项目群、钉钉视频通话、钉钉视频会议、钉钉日报等基础功能,再到钉钉平台上演化出来的各种办公室自动化(Office Automation)应用,方便了人与人之间的交流,可以帮助企业快速实现在线协同办公。
2020年新型冠状病毒肺炎疫情爆发,为了规避集中办公带来的感染风险,大量企业员工选择了在家办公,企业办公协同工具需求瞬间爆发。钉钉迅速冲上了AppStore下载榜单的第一位,导致钉钉访问流量迅速增长,借助于阿里云提供的弹性基础设施,钉钉平稳地渡过了每一次流量洪峰。
如此庞大用户量,钉钉的消息系统除了要保证消息及时正确传递,还要保证已读、未读等特有功能,而且不同于微信这样的用户级IM工具,企业IM需要实现聊天记录永久保存,并且提供多端漫游功能。由于用户量持续爆炸性增长,聊天记录永久保存给钉钉业务带来巨大成本压力,同时还要保证聊天记录的读写性能不会降低。
面对这些挑战,钉钉业务选用了X-Engine作为钉钉消息的最终存储引擎,实现了性能和成本平衡。使用X-Engine有如下优势:
存储空间比InnoDB引擎减少了约62%。
保留对事务以及二级索引等数据库特性的支持。
业务代码不需要修改就可以迁移到X-Engine引擎实例上。
X-Engine的冷热分离能力能够对最新消息有着最快的处理速度,而对历史消息有着最高压缩比。
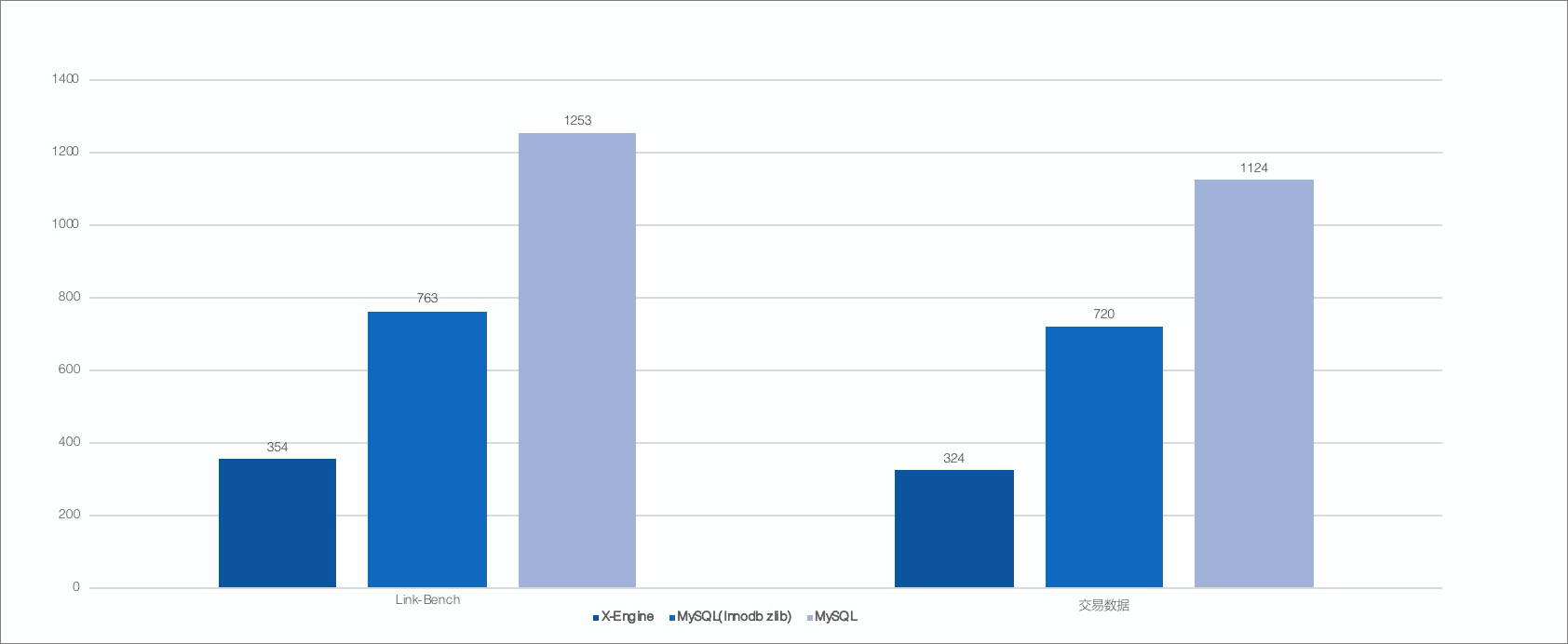
在Link-Bench和阿里巴巴内部交易业务两个数据集上测试了X-Engine的存储空间效率。在测试中,对比开启压缩的InnoDB引擎,X-Engine有着2倍空间优势;对比未开启压缩的InnoDB,X-Engine则有着3~5倍空间优势。
X-Engine如何实现低成本
X-Engine可以实现低成本是因为有以下几个特殊技术:
紧凑数据页格式
X-Engine使用Copy-on-write技术,避免原地更新数据页,新数据会写入到新数据页中。由于既有数据不可更新,可以对只读数据页进行紧凑存储并使用前缀编码等方式进行数据压缩,提升页面空间使用效率。而已经失效的历史记录版本则由Compaction操作清理,保证有效记录都紧凑排列。相对于传统存储引擎(例如InnoDB),使用X-Engine可以将存储空间降低至10%~50%。
数据压缩及无效记录清理
编码之后的数据页,可以使用通用压缩算法(zlib、zstd、snappy等)进行压缩,所有处在LSM-tree低层次的数据都会默认压缩。
数据压缩是以计算资源换存储空间的技术,因此选用一个压缩率小及压缩/解压速度快的压缩算法也非常关键,经过大量对比测试,X-Engine默认选用ZSTD压缩算法,但同时也支持其他算法。
除了使用压缩之外,Compaction操作会对无效记录进行删除,只保留有效记录,Compaction执行越频繁则无效记录占比越低,空间使用效率越高,因此保证合适的Compaction频率也是提升空间使用效率的关键。
为了减少Compaction操作对计算资源的消耗,X-Engine团队研发了FPGA Compaction技术,使用异构计算硬件来加速Compaction过程,实现了在一个FPGA硬件流水线内同时完成Compaction和压缩操作。即使在没有FPGA硬件的主机上,借助合理调度算法,X-Engine也能以较小的性能代价节省存储空间。
智能冷热分离
通常存储系统访问数据都有局部性,大量访问都集中在少部分数据上,这也是缓存系统能有效工作的基本前提。在LSM存储结构中,如果把访问频率高的数据尽可能放在较高层次上,存放在快速存储设备中(例如NVM、DRAM),而把访问频率低的数据放在较低层次中,存放在廉价慢速存储设备中,这就是X-Engine冷热分层概念。
X-Engine中冷热分离算法主要完成如下几个任务:
在Compaction操作中,挑选出未来最不可能被访问到的数据页和记录,移动到LSM-tree底层。
挑选当前热点数据,在Compaction或者转储过程中回填到内存中(BlockCache/RowCache),避免缓存命中率抖动导致的性能影响。
AI算法会识别出未来可能被访问到的数据,并提前预读到内存中,减少首次访问缓存未命中率。
准确识别出数据冷热,可以避免无效压缩或解压带来的计算资源浪费,提升系统吞吐。
更多详细说明请参见原理剖析。