
PolarDB MySQL版基于列存索引(IMCI)推出原生列存全文检索功能,支持在现有表上直接创建全文索引,通过MATCH函数及优化的LIKE加速能力,实现毫秒级模糊查询。相比Elasticsearch等外部搜索引擎方案,IMCI实现了数据与索引的事务一致性,在避免数据同步延迟的同时,降低了整体架构的复杂度。
核心概念
理解PolarDB IMCI全文检索,需掌握以下核心概念:
概念 | 描述 |
文档(Document) | 进行索引的原始数据单元,在PolarDB IMCI中特指列存中的一行数据。 |
词项(Term) | 从文档中经过分词器处理后提取出的基本语言单位,是索引和查询的最小单元。 |
分词器(Tokenizer) | 将原始文本切分为词项序列的组件。PolarDB IMCI提供多种分词器(如 |
倒排索引(Inverted Index) | 全文检索的核心数据结构,用于记录每个词项与包含它的文档列表之间的映射关系。它由词项字典和倒排表两部分组成,可加速文本查询。 |
词项字典(Term Dictionary) | 存储所有词项的集合,并提供快速查找能力。PolarDB IMCI采用FST(Finite State Transducer)算法构建词典,查询时间复杂度为O(len(词项)),空间占用少。 |
倒排表(Posting List) | 记录了包含某个特定词项的所有文档ID(在IMCI中为64位行号)的列表。PolarDB IMCI采用RBM(Roaring Bitmap)算法对倒排表进行压缩和计算,在稀疏和稠密数据场景下均表现良好。 |
PolarDB IMCI内置方案与“数据库+Elasticsearch”外部方案的对比如下:
对比维度 | PolarDB IMCI 全文检索 | “数据库 + Elasticsearch” 方案 |
数据一致性 | 强一致性。索引更新与数据写入在同一事务内完成,遵循ACID原则,无数据延迟或不一致风险。 | 最终一致性。数据需从数据库同步至ES,存在同步延迟,无法保证数据的实时性与事务原子性。 |
架构复杂度 | 简单。功能内置于数据库,无需引入新组件,架构清晰。 | 复杂。需要额外部署、维护一套独立的ES集群及数据同步链路,增加了系统异构性。 |
查询方式 | 统一。所有数据(结构化、非结构化)均通过标准SQL进行查询。 | 割裂。需要同时使用SQL和ES的DSL进行查询,常导致“先查ES再查DB”的两段式查询,增加延迟和代码复杂度。 |
运维成本 | 低。复用PolarDB的运维和高可用体系,无需额外的专业运维技能和服务器资源。 | 高。需要独立的服务器资源和专业的ES运维能力,存储双份数据也增加了存储成本。 |
工作原理
PolarDB IMCI的全文检索基于倒排索引技术实现,通过将非结构化的文本数据转化为结构化的索引结构,显著提升关键词查询性能。其核心流程如下图所示:
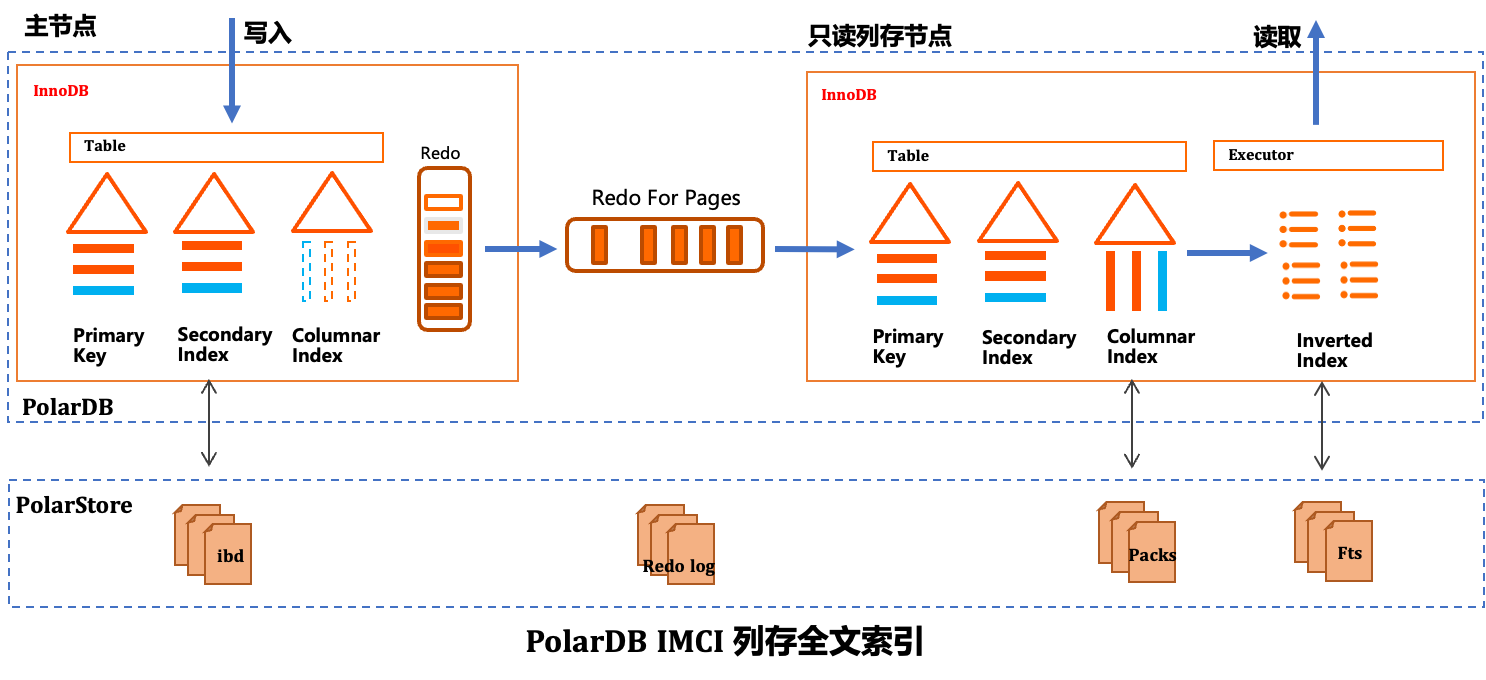
数据写入时,InnoDB表中的内容经由列存索引同步至PolarStore的Pack文件;在查询阶段,执行器基于列存数据构建倒排索引,并利用Fts文件高效完成全文匹配。该架构实现了行存与列存的协同,兼顾写入性能与复杂查询能力。
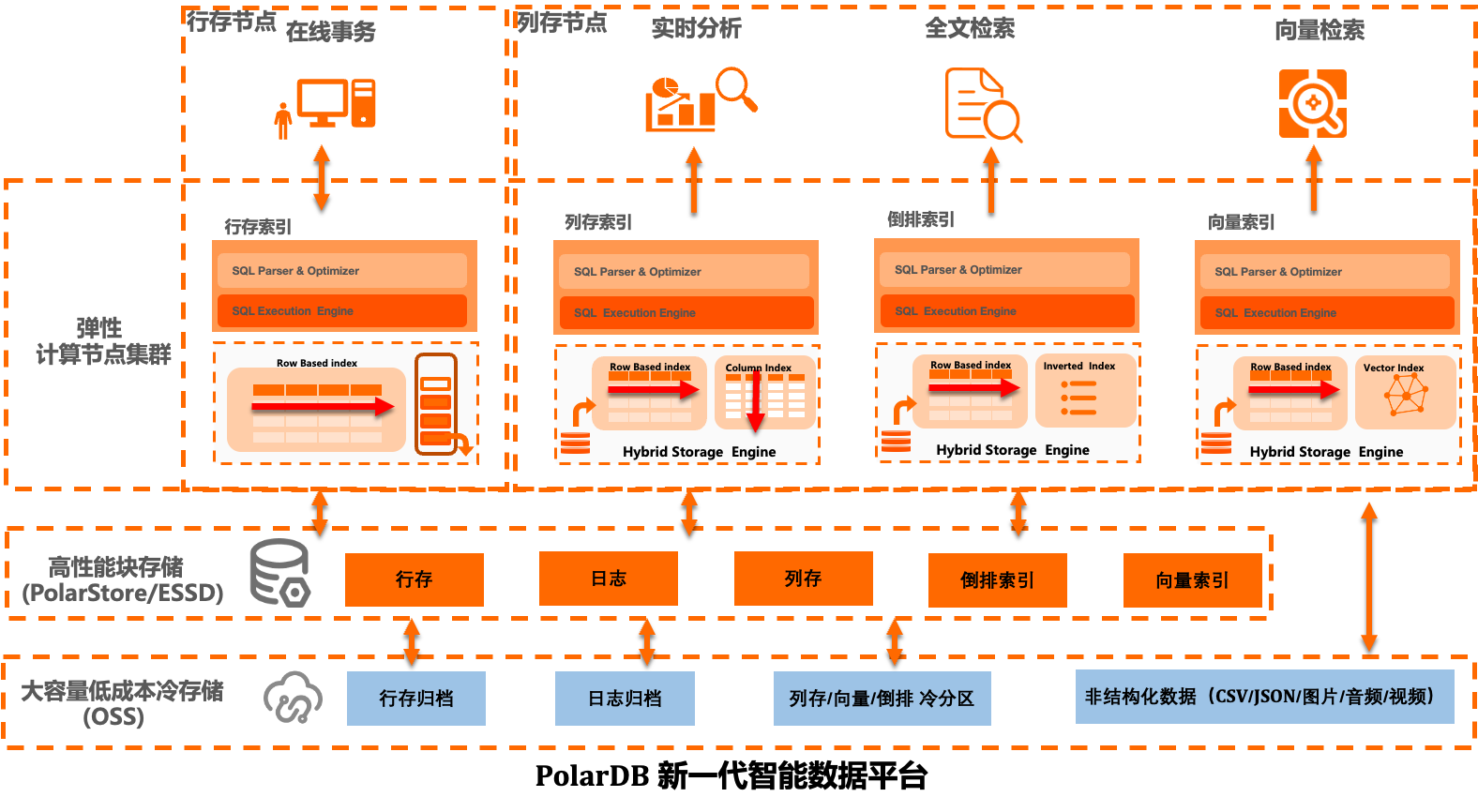
PolarDB IMCI采用统一的混合存储架构,支持多种查询模式。如图所示,全文检索依托Hybrid Storage Engine构建并维护倒排索引,实现高效的文本搜索;同时结合弹性计算节点与分层存储,兼顾高吞吐写入与低延迟查询。在此基础上,集成内置向量索引能力,进一步支持文本与向量的多模态联合检索。该架构广泛适用于电商商品搜索、日志分析、知识库检索等场景,为用户提供集OLTP、实时分析、全文检索与向量搜索于一体的一站式数据服务平台。
分词器
分词是将文本拆解为词项的过程,是全文检索的基础。选择合适的分词器对检索的准确性和性能至关重要。IMCI支持以下分词器:
分词器 | 描述 |
token | 基于空格、标点符号等非字母数字字符进行分词,适用于英文等以空格为分隔符的语言。 |
ngram | 将文本按预设的字符长度(n)切分成连续的词项。 |
jieba | 基于 |
ik | 基于 |
json | 通过JSONPath表达式提取JSON对象中的特定键值或数组元素作为词项,用于对JSON数据进行深度检索。 |
此外,PolarDB IMCI还提供dbms_imci.fts_tokenize分词工具函数来测试分词效果,其支持所有分词器与对应属性。不同分词结果可能会导致全文索引的查询结果不符合预期或MATCH与LIKE不一致等,此时可以通过该分词工具函数来验证分词结果。
倒排列表
倒排表(Postings List)直观点来说就是文档ID集合,其关键技术点在于高效压缩存储与高性能计算(如交集)。
在PolarDB IMCI全文索引中,倒排表存储的是包含某个词项的所有列存索引的行号集合与其对应的词频(可选)及文档频率(可选),每一词项对应一个倒排表。
IMCI使用RBM(Roaring Bitmaps)算法对倒排表(即文档ID集合)进行压缩和计算。

RBM实现基于CRoaring库,并根据数据密度动态选择存储策略:
当倒排表中文档ID数量小于预设阈值时,使用
std::array存储。当数量超过阈值时,切换为
roaring::Roaring64Map类型,以应对大规模稀疏或稠密数据,并保持高压缩率。
性能特性:
支持在构建索引时进行O(logN) 复杂度的查找。
支持在进行交集、并集等集合运算时使用SIMD指令加速。
支持在数据落盘时进行空间整理,减少碎片。
支持在查询时利用
minimum/maximum值进行快速过滤和迭代器优化。
词项字典
倒排索引的核心思想是利用词典来快速查找词项所对应的倒排表,如何设计词项到倒排表映射关系的词典就显得尤为重要,如字典树、B+树与FST等。
IMCI 采用 FST(Finite State Transducer)算法构建词项字典,以实现时间和空间效率的平衡。
空间效率:通过共享词项的公共前缀和后缀,有效压缩了存储空间。
时间效率:查询词项的时间复杂度为 O(L),其中 L 是词项的长度。
例如,对于按序输入的词项 China、Chinese、love,假设其倒排表地址偏移分别为 5、10、15,构建出词典如下图所示,从图可以看出 FST 不仅可以共同前缀和后缀以节省空间,而且保证不同的转移有唯一的关联值。查询则从初始状态0开始依次按词项中字符查找是否有该字符的出边,存在则累计关联值,否则判断是否为结束状态,如 Chinese 得到关联值为 15 且最后字符为结束状态,即表示词典中存在该词项;此外 FST 的前缀计算基于字节而不是字符,因此也是支持 utf8 等编码。

倒排构建
PolarDB IMCI采用SPIMI算法构建倒排索引,通过单次扫描、分词并批量生成词典与倒排表,支持高效、内存可控的局部索引构建。
PolarDB IMCI全文索引使用SPIMI构建时会不断读取对应列的列存数据,接着对每一行数据进行分词得到词项集合,然后将每一词项和对应行号添加到散列表中,同时会累加内存统计值,当超过段大小阈值时则会将散列表中词项和倒排表构建出词典和重置内存继续处理一下行,直到处理完所有列存数据。而散列表(std::unordered_map)构建词典(FST)主要流程是首先对散列表按词项(键)进行排序,接着按序将散列表中所有倒排表序列化到磁盘中并记录其磁盘相对偏移地址,然后按序将词项和该词项的倒排表偏移地址依次添加 FST 算法构建出词典,最后将词典压缩后落盘并记录当段信息(包括词典大小、词典起始地址、倒排表起始地址、行号范围等)到元数据中。
PolarDB 不追求构建全局词典以避免外排(全局词典还需要按前缀切分并构建出词项索引),而是考虑到列存存储追加写模型则采用轻量级构建方式,根据内存阈值构建出多个局部词典,如下图所示。当然在内存充足情况下尽量可能放大内存阈值,这样会让同一词项尽可能多落到同一倒排段中,有助于节省空间和提高查询性能。

除上述正常构建倒排外,PolarDB IMCI全文索引还支持后台空闲时异步合并倒排索引。 PolarDB IMCI列存索引作为普通表的二级索引,insert时数据总是以插入序按列追加到列存存储引擎中,delete时采用标记删除方式,update则转换为delete + insert,其使用 array InsertMask标记列存数据中每一行的插入版本作为可见性判断,lsm DeleteMask 则对已存在的某行进行标记删除,同时异步Compaction与Recycle等后台操作进行数据重整和空间回收等。PolarDB IMCI全文索引作为列存引擎的一部分,同样也会通过后台异步倒排Compaction任务来不定时清理被标记为删除的数据,有效节省空间和提高查询性能。倒排合并是按倒排段为单元,将多个倒排段合并为新倒排段,同时不会修改原倒排段,避免用于查询的倒排快照对象失效,合并完成时会重新生成新倒排快照,新查询时则使用新快照。 PolarDB IMCI全文索引得益于局部构建方式与标记删除设计方案,大批量插入并不会触发全局重建,仅需构建增量部分,同时更新成本也非常低,仅需要标记删除,即使在频繁更新场景下也不会影响写入性能。此外,后台不定时异步合并能够有效合并出更紧凑的倒排索引以提高查询性能,结合列存的并发查询能力,即使在海量数据场景下也能够满足毫秒级响应要求。
倒排检索
PolarDB IMCI 全文索引支持mysql官方MATCH函数和LIKE操作等。
MATCH函数PolarDB IMCI支持统一使用
MATCH函数进行全文检索,无论行存是否创建全文索引:若行存未建索引,查询将直接路由至列存节点;若已存在,则根据代价评估进行智能分流。为避免MySQL原生全文索引在优化阶段触发的辅助表同步、缓存加载等耗时操作影响列存性能,PolarDB在查询分流初期即跳过此类处理。执行阶段,IMCI提供两种检索方式:
FtsTableScan算子和MATCH表达式。前者通过倒排索引直接获取命中行,适用于高筛选率场景;后者则基于行号回查索引,适合前置条件已大幅过滤数据的情形。两者的执行效率取决于其他谓词的过滤效果,因此列存优化器结合统计信息估算过滤率,动态选择最优策略。当选用算子方式时,系统自动将MATCH函数重写为FtsTableScan + Filter算子。全文索引采用异步构建机制,可能短暂延迟新增数据的可见性。默认情况下,列存执行器通过全表扫描补全未索引数据,确保查询结果完整;同时提供参数控制是否跳过该步骤,以在高并发、大数据量场景下实现性能与一致性的灵活权衡。用户亦可调整索引构建参数,加快数据同步频率,减少全扫描范围,进一步提升查询效率。
LIKE加速PolarDB IMCI 在特定条件下支持
LIKE与MATCH的相互转换,其中将LIKE转换为MATCH主要用于查询加速,以减少全表扫描中大量字符串逐行比较的开销。当前,该转换仅在列存全文索引使用
ngram分词器,且ngram分词长度小于或等于LIKE模式字符串长度时生效。在此条件下,优化器可将形如LIKE '%abc%'的谓词重写为FtsTableScan + Filter算子,利用倒排索引快速筛选候选行。然而,由于
ngram分词的匹配机制与LIKE的语义存在差异(例如"abbc"分词为ab、bb、bc,与"abc"的ab和bc重叠,可能被误判为匹配),倒排索引仅用于粗粒度过滤。因此,原始LIKE表达式仍作为后续过滤条件保留,用于精确验证,确保结果正确性。该机制在显著提升查询性能的同时,有效兼顾了语义准确性与执行效率。
PolarDB IMCI的倒排索引由多个倒排段组成,每个倒排段包含独立的元数据、一个词典和一系列倒排表,其中每个词项唯一对应一个倒排表。元数据记录词典和倒排表的起始地址等信息,体积较小,默认常驻内存,以加速索引访问。
倒排检索以倒排段为单位进行,主要流程包括:读取词典数据、构建FST(有限状态转换器)词典对象、在词典中查找目标词项、读取对应的倒排表并构建RBM(Roaring Bitmap)倒排表对象。
具体查询分为两种模式:
算子查询:遍历所有倒排段的元数据,获取词典起始地址并加载词典数据,构建词典对象后查找目标词项;若命中,则结合词项的倒排表偏移地址与段内起始地址,读取完整的倒排表对象。
表达式查询:根据行号确定所属的倒排段集合,并利用元数据中的行号范围进一步过滤,随后对匹配的倒排段执行与算子查询类似的词典查找和倒排表读取流程。
为提升性能,IMCI支持词典缓存功能,采用独立的LRU缓存机制,并由调度模块动态调整内存配额。由于单个倒排表通常较小(多数仅需一次 4KB IO),且数量庞大,缓存命中率和收益有限,因此倒排表缓存默认不启用,以避免内存资源浪费。
该设计在保证查询效率的同时,合理权衡了内存使用与 I/O 开销。
应用场景
PolarDB IMCI全文检索功能适用于多种需要对文本内容进行快速搜索的业务场景。
电商商品搜索与站内查询
在电商平台中,用户常通过关键词快速查找商品。传统基于
LIKE的模糊匹配性能差,难以满足高并发下的响应要求;而依赖外部Elasticsearch的方案虽能提速,却常因数据同步延迟导致搜索结果包含已下架、已调价或库存为零的商品,影响用户体验。PolarDB IMCI提供原生全文检索能力,可对商品标题、描述、属性等文本字段建立高效倒排索引。查询时直接在数据库内完成关键词匹配,避免跨系统延迟,确保搜索结果与商品实时状态(如价格、库存)强一致,真正实现“搜得到、买得到”。
日志分析与可观测性
运维和排障过程中,开发与运维人员需要从海量日志中快速定位错误堆栈、追踪请求链路或分析异常行为。传统ELK架构虽功能强大,但组件繁多、部署复杂、维护成本高,且数据写入到可查之间存在明显延迟。
借助 PolarDB IMCI,可直接在日志表的
message或content字段上创建全文索引,利用标准SQL实现毫秒级日志检索。无需额外搭建日志分析平台,即可完成交互式查询与上下文追溯,显著简化技术栈,降低存储与运维负担,让问题定位更高效。文档与知识库检索
企业内部的知识库、产品手册、FAQ或帮助中心,核心诉求是让用户快速找到所需信息。若依赖外部搜索引擎,不仅需要维护双写逻辑,还容易出现内容更新不同步的问题。
通过PolarDB IMCI对文档正文建立全文索引,并结合
jieba或ik等中文分词器提升切词准确性,可在同一数据库内实现内容存储与检索一体化。内容更新后立即可搜,权限模型复用现有系统,无需额外同步机制,真正实现“发布即可见、修改即生效”。用户画像与行为分析
精准的用户运营依赖对非结构化文本的深度挖掘,例如从用户评论、标签、动态中提取兴趣偏好。传统做法需将数据导出至数仓或分析系统,流程复杂且时效性差。
PolarDB IMCI支持对JSON字段使用
json分词器,或对长文本字段使用jieba分词器建立索引,使得在单条SQL中即可融合结构化属性(如年龄、地域)与文本语义(如“喜欢户外运动”“关注性价比”)进行联合分析。无需数据迁移,实时完成用户圈选与行为洞察,助力精细化运营与个性化推荐。
性能测试
ESRally是Elastic官方推出的Elasticsearch基准测试工具。本文将使用其内置的http_logs数据集,对PolarDB IMCI列存全文索引的检索性能进行测试评估。您也可参考解决方案PolarDB 列存索引加速复杂查询进行操作演示,进一步了解其在实际场景中的性能表现。
数据集准备
获取数据集 数据集详情请参见 Elasticsearch Rally Hub,获取数据集方法如下所示,获取到大约 1.7G 压缩包rally-track-data-http_logs.tar,解压后约32G,总行数为2.47亿。
git clone https://github.com/elastic/rally-tracks.git cd rally-tracks ./download.sh http_logs创建表 由于数据集存在少数行的json数据和mysql json类型不兼容,因此使用varchar(512)来存储json数据,导完数据后再通过虚拟列来解析出json的request字段。
CREATE TABLE http_logs( logs varchar(4096) );导入数据 使用LOAD DATA导入数据集到数据库。
LOAD DATA INFILE '/home/xxx/http_logs/documents-181998.json' INTO TABLE http_logs COLUMNS TERMINATED BY '\n'; ... ...添加字段 通过虚拟列来解析出json的request字段用于全文索引测试。
ALTER TABLE http_logs ADD COLUMN request varchar(1024) AS (CASE WHEN json_valid(logs) THEN (json_unquote(json_extract(logs, '$.request'))) ELSE NULL END);创建列存索引 列存倒排索引属于列存索引一部分,需要先创建列存索引。
ALTER TABLE http_logs comment 'columnar=1';创建倒排索引
通过ddl来修改列comment方式来列存倒排索引,ddl会秒级完成,而倒排索引会在后台异步构建。
ALTER TABLE http_logs modify COLUMN request varchar(1024) AS (CASE WHEN json_valid(logs) THEN (json_unquote(json_extract(logs, '$.request'))) ELSE NULL END) comment 'imci_fts(type=2 mode=1)';查看倒排索引
创建后可以通过下面命令行分别查看NUM_PACKS和NEXT_PACK_ID,其中 NUM_PACKS表示列存数据块数目,NEXT_PACK_ID表示倒排索引已构建到数据块编号,两者接近则表示倒排索引已经构建完成。
SHOW imci indexes; SHOW imci indexes fulltext;
性能测试
倒排索引构建完成后,即可通过MATCH函数测试从高频到低频词元的检索性能表现。下图展示了 LIKE、MATCH 与 Doris MATCH_ANY 在相同数据集下的查询性能对比。
在热数据情况下单线程测试结果如下:
查询 | 高频词元 | 较高频词元 | 较低频词元 | 低频词元 |
LIKE | 1 min 21.96 sec | 1 min 18.44 sec | 1 min 24.59 sec | 1 min 31.19 sec |
SMID LIKE | 25.46 sec | 22.80 sec | 21.98 sec | 21.60 sec |
MATCH (自研 FTS库) | 2.43 sec | 0.25 sec | 0.01 sec | 0.00 sec |
Doris MATCH_ANY (CLucene库) | 3.49 sec | 0.24 sec | 0.03 sec | 0.03 sec |
如上表所见,MATCH 比 LIKE 有数据量提升,且基本不受冷热数据影响。
常见问题
Q1:PolarDB IMCI全文检索相比传统数据库(如MySQL InnoDB)自带的全文索引,有哪些优势?
PolarDB IMCI在性能、功能和扩展性上均有优势:
性能:基于列存和向量化执行引擎,结合FST、RBM等算法,查询性能优于传统行存索引,在高并发、海量数据场景下可实现快速响应。
功能:内置
jieba、ik等中文分词器和json分词器,满足复杂业务场景的需求。写入性能影响:优化的索引构建和更新机制,对高频写入(INSERT/UPDATE)场景的性能影响远小于传统数据库的全文索引。
水平扩展能力:受益于PolarDB存算分离架构,具备良好的水平扩展能力。
Q2:如何为业务数据选择合适的分词器?
根据数据类型和查询需求来选择:
处理中文文本:使用
jieba或ik分词器,它们能进行语义分词,提升中文检索的准确率。处理英文或符号分割的文本:使用
token分词器,它通过空格和标点符号进行分词。实现模糊匹配或任意子串搜索:使用
ngram分词器,它将文本切分为固定长度的短语(如二元、三元),适合替代低效的LIKE '%keyword%'查询。检索JSON字段内的特定内容:使用
json分词器,目前支持对JSON数组的值或JSON对象的键建立倒排索引。
如果不确定哪种分词器最适合,可使用dbms_imci.fts_tokenize函数预览不同分词器对示例文本的处理效果,以选择最符合业务预期的分词策略。