
本文介绍了PolarDB IMCI中GroupJoin算子的一些限制条件和实现方式,以及其他数据的一些相关实现。阅读本文前请先了解基础的HASH JOIN与HASH GROUP BY算法。
背景
SELECT
key1,
SUM(sales) as total_sales
FROM
fact_table LEFT JOIN dimension_table ON fact_table.key1 = dimension_table.key1
GROUP BY
fact_table.key1
ORDER BY
total_sales
LIMIT 100;在PolarDB IMCI中,类似以上查询语句的执行计划是先执行一遍HASH JOIN,再执行HASH GROUP BY key1。在这两个操作中,都会使用key1创建哈希表(注意fact_table.key1 = dimension_table.key1),执行计划说明如下:
HASH JOIN:使用dimension_table.key1建哈希表,使用fact_table.key1查哈希表并输出数据;
HASH GROUP BY:使用fact_table.key1建哈希表,写入哈希表的过程中做聚合运算。
从执行效率的角度来看,这两个操作可以合并成一个,使用dimension_table.key1建哈希表以及做聚合运算,使用fact_table.key1查哈希表以及做聚合运算,因此节省了使用fact_table.key1建哈希表的时间。这种将HASH JOIN与HASH GROUP BY两个算子合并成一个的操作,就是GroupJoin。
从执行效率的角度来看,将这两个操作合并成一个操作,不仅可以减少一次建哈希表的操作,还可以减小中间结果大小。因为JOIN是一个可能使“结果集膨胀”的运算,一张表的一行可能会匹配上另一张表的多行,最坏情况下便是笛卡儿积:N行的表与M行的表JOIN的结果最大可能是N×M的结果集。因此在HASH JOIN+HASH GROUP BY的执行方式中,一张N行的哈希表可能会输出N×M×S行结果(S代表selectivity,0≤S≤1),然后在HASH GROUP BY的grouping操作中再被聚合成一张新的哈希表,这会造成资源浪费。即使是上面例子中“事实表”(大表,大小为M)与“维度表”(小表,大小为N)的LEFT OUTER JOIN,且key1都是unique key,也是从一张N行的哈希表, 经过HASH JOIN输出M行结果,然后聚合成M行的哈希表。相对而言,GroupJoin只需要在N行的哈希表中完成join&aggr运算,不仅中间结果变少了,同时内存占用也变小了。
基于以上考虑,PolarDB MySQL版在PolarDB IMCI中增加了GroupJoin算子。
算法设计
概述
IMCI里的GroupJoin实现,是HashJoin与HashGroupby两个算子的融合:
先使用左表(小表)建立哈希表,涉及左表的aggr函数会在建哈希表的时候直接运算掉。这个过程与对左表聚合(i.e., HashGroupby left_table)的操作是相同的。
使用右表(大表)查哈希表,查询命中则在hash table entry上运算涉及右表的aggr函数,否则丢弃或者直接输出。
以上介绍了IMCI GroupJoin算法的基本思路,下文会对算法进行详细的描述以及介绍简化的方法。
限制条件
出于实现的复杂度考虑,相对于理论上最完备的GroupJoin实现,PolarDB MySQL版做了如下几点限制:
group by key要完全匹配某一边,且只能是某一边的join key,虽然某些情况下join key的一部分,也能唯一定义这个key(i.e., functional dependency);
RIGHT JOIN、GROUP BY RIGHT的场景,要求right keys是unique keys。否则可能会转成LEFT JOIN、GROUP BY LEFT的方式,或者不使用GroupJoin;
任意一个aggr函数只能单独引用左表,或者单独引用右表;如果原GROUP BY算子中的aggr函数同时引用了左右两个表(e.g., SUN(t1.a+t2.a)),则不适用GroupJoin。
算法
INNER JOIN/GROUP BY LEFT
此场景如下SQL所示:
l_table INNER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY l_table.key1假设实际执行顺序与SQL描述一样,且Join过程中不会动态换边。
使用左表建哈希表,并且创建哈希表的过程中直接运算涉及左表的aggr函数;涉及右表的aggr函数,对应设一个“repeat count”,这等同于一个hash table entry对应的payload的数量;
在join过程中,使用右表查哈希表,如果不匹配,则右表的行直接被丢弃;如果匹配,左表的aggr context的“repeat count”会增加1,右表的aggr函数直接进行运算;
join完成后,只输出曾经被匹配上的hash table entry的aggr结果,没有被匹配上的hash table entry全部忽略;
输出aggr结果时,要考虑“repeat count”,例如如果一个SUM(expr)的结果是200,“repeat count”是5,则最终结果是1000。
INNER JOIN/GROUP BY RIGHT
此场景如下SQL所示:
l_table INNER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY r_table.key1考虑到l_table.key1=r_table.key1,这种情况被归到“INNER JOIN, GROUP BY LEFT”里。
LEFT OUTER JOIN/GROUP BY LEFT
此场景如下SQL所示:
l_table LEFT OUTER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY l_table.key1使用左表建哈希表,建哈希表的过程中运算左表的aggr函数;涉及右表的aggr函数,对应设一个“repeat count”;
在join过程中,使用右表查哈希表,如果不匹配,则右表的行直接被丢弃;如果匹配,左表的aggr context的“repeat count”会增加1,右表的aggr函数直接进行运算;
与INNER JOIN不同,此场景中join完成后,被匹配上的hash table entry的aggr结果直接输出,没有被匹配上的每个hash table entry单独成为一个GROUP,对应的右表的aggr函数的输入都是NULL。
LEFT OUTER JOIN/GROUP BY RIGHT
此场景如下SQL所示:
l_table LEFT OUTER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY r_table.key1使用左表建哈希表,建哈希表的过程中运算左表的aggr函数;涉及右表的aggr函数,对应设一个 “repeat count”;
在join过程中,使用右表查哈希表,如果不匹配,则右表的行直接被丢弃;如果匹配,左表的aggr context的“repeat count”会增加1,右表的aggr函数直接进行运算;
与其他场景不同,此场景中join完成后,被匹配上的hash table entry的aggr结果直接输出,没有被匹配上的所有hash table entry成为一个GROUP,对应的右表的aggr函数的输入都是NULL。
RIGHT OUTER JOIN/GROUP BY LEFT
此场景如下SQL所示:
l_table RIGHT OUTER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY l_table.key1使用左表建哈希表,创建哈希表的过程中运算左表的aggr函数;涉及右表的aggr函数,对应设一个“repeat count”;
与其他场景不同,此场景在join过程中,使用右表查哈希表,如果匹配,左表的aggr context的“repeat count”会增加1,右表的aggr函数直接进行运算;如果不匹配,则右表的所有不匹配的行成为一个GROUP,对应的左表的aggr函数结果都是NULL;
与其他场景不同,此场景在join完成后,被匹配上的hash table entry的aggr结果直接输出,没有被匹配上的所有hash table entry全都忽略。
RIGHT OUTER JOIN/GROUP BY RIGHT
此场景如下SQL所示:
l_table RIGHT OUTER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY r_table.key1限制条件
要求r_table.key1必须是distinct的,否则这种join是不合法的;如果不能确定r_table.key1是distinct的,则需要在优化器里将这种join+groupby转成LEFT OUTER JOIN、GROUP BY LEFT。
执行步骤
使用左表建哈希表,建哈希表的过程中运算左表的aggr函数;涉及右表的aggr函数,对应设一个“repeat count”;
与其他场景不同,此场景在join过程中,使用右表查哈希表,如果匹配,直接输出左右表的aggr结果;如果不匹配,也输出aggr结果,此时左表的aggr结果都是NULL;
与其他场景不同,此场景在join完成后,GroupJoin即完成,不需要处理任何hash table entry。
运行时落盘(spilling)处理
GroupJoin的落盘处理,类似于partition-style的HashJoin&HashGroupby的落盘处理,方法如下:
GroupJoin的整体算法采用分区(partition)的方式;
使用左表构建哈希表时,内存中的partition,构建hash table的算法与算法一节描述一致;
使用左表构建哈希表时,不在内存中的partition,刷到磁盘中对应的临时文件,后续新写入这个partition 的数据也会直接刷到磁盘中对应的临时文件;落盘的partition会建立一个bloomfilter,方便后续查找的时候快速过滤掉不可能匹配的右表数据;
完成左表的哈希表构建后,使用右表数据查哈希表:
相关实现
2011年的一篇论文Accelerating Queries with Group-By and Join by Groupjoin(简称 paper_1)从理论角度阐述了GroupJoin在不同查询计划中的可行性,但是不涉及太多实现的细节。论文描述了GroupJoin运算时的约束,以及适用GroupJoin的场景,比如不同aggr函数如何处理等,描述得比较抽象,整体可读性不是很好。
2021年有一篇论文A Practical Approach to Groupjoin and Nested Aggregates (简称 paper_2)描述了如何在(内存)数据库中高效地实现GroupJoin算子。这篇论文的几个重点是:
1. 解关联子查询的算法中使用GroupJoin
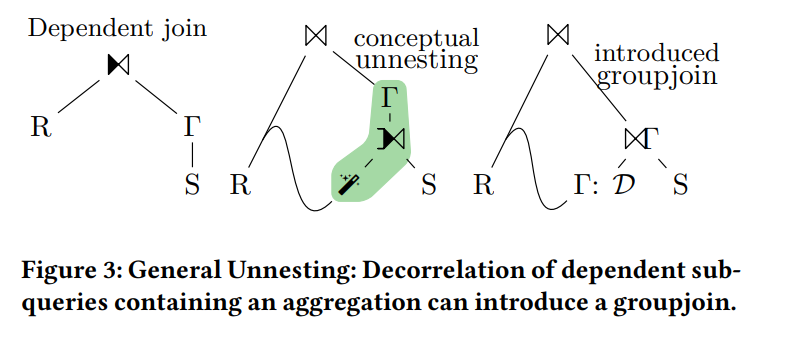
在解决“关联项上方有 GROUP BY”这种关联子查询时,有一种方式是引入“MagicSet”操作(也就是 table distinct)并在上方增加一个JOIN+GROUP BY,从而完成子查询的去关联。这种模样的执行计划,恰好符合GroupJoin的适用场景。由于IMCI目前也使用了类似的解关联算法,但是目前暂时不能生成此类shared children的执行计划。
2. Eager aggregation
简单来说,就是在hash build的过程中,把hash build那一边的aggr函数直接计算掉,而不是为每个hash table entry保留完整的payload,最后再运算aggr函数。这与IMCI的实现思路是一样的。
3. 使用memoizing的方式解决并发查哈希表做聚合运算时的冲突
举个极端的例子:hash probe的过程中,所有数据都命中hash table的同一个entry,因此要在此entry进行聚合运算(比如SUM(2 * col)),因此需要使用同一个“aggr context”运行aggr函数;例如,对于 SUM() 聚合函数来说,就是不断使用同一个sum_value进行加法操作。即使是原子变量的加法操作,遇到contention也是有性能问题的,更何况是通用的聚合函数运算。这篇论文的思路是为所有“没有抢到entry所有权”的线程建立各自的local hash table进行运算,对于每个entry,利用CAS指令设置一个owner thread id,除了owner thread外,后续到来的thread都使用自己的local hash table进行运算,最后再将这些local hash table合并到global hash table里。
4. 并不是所有场景都适用于GroupJoin
有些场景更适用于Join+Groupby。举个例子,假设hash build一边的selectivity很低,hash probe完成后,这一边的大多数行都不会被选中,那么就会遇到了一个两难的境地了:
如果在hash build的时候,同时把这一边的聚合运算做掉(i.e.,eager aggregation),则不需要保留hash table的payload,节省了内存,但是因为join的selectivity很低,大多数行最后都不会被选中,因此这些提前运算的agg运算都浪费掉了;
如果不提前做aggr运算,则需要多花一些内存;但是在join的selectivity很高(大多数行都被选中)的情况下,这些内存本可以通过提前进行的aggr运算节省掉。
所以,如果join的selectivity很低,那么更好的方式或许是:join完后,得到非常少的group,然后在HashGroupby中做局部性很强的聚合操作。因此,这篇论文提出了几种场景下不同的实现。而为了知道一个查询适用于哪种场景,需要优化器提供selectivity和cardinality的估算,因此论文后面配套提供了一些优化器里用到的估算方法。
从实现者的角度看来,上面所说的“两难的境地”其实并不是太大的问题,这是因为:
PolarDB IMCI几乎总是用小的一边(小表)建哈希表;
即使JOIN的selectivity很低,使用eager aggregation提前运算聚合函数的策略,虽然浪费了针对一个小表的运算时间,但是无论如何也节省了内存,并不是一无所获;这种情况下,相对于HashJoin+HashGroupby,也算是时间换空间。
在IMCI的实现里面,除了上文说的RIGHT JOIN+GROUP BY RIGHT场景,PolarDB IMCI几乎总是认为GroupJoin的执行效率是优于HashJoin+HashGroupby。
从作者以及论文里面的测试情况来看,上述的两篇论文应该都来自慕尼黑大学的hyper数据库团队。除hyper外,目前还没有见到其他数据库实现GroupJoin算子,但是应该有“shared hash table”操作的其他实现方式,后续再进一步讨论。
GroupJoin在TPCH中的应用
TPCH是一个常用的测试一个AP系统的分析查询能力的benchmark。在TPCH的22条查询中,有不少都是适用GroupJoin算子的。不过,除了TPCH Q13,其他的查询语句都需要经过一定改造才能适用GroupJoin算子。
Q13
TPCH Q13,可以直接适用GroupJoin算子:
select
c_count,
count(*) as custdist
from
(
select
c_custkey,
count(o_orderkey) as c_count
from
customer
left outer join orders on c_custkey = o_custkey
and o_comment not like '%pending%deposits%'
group by
c_custkey
) c_orders
group by
c_count
order by
custdist desc,
c_count desc;在IMCI中,如果不使用GroupJoin,则执行计划如下:

如果使用GroupJoin,执行计划如下:

Q3
对TPCH的Q3而言,GroupJoin的优化需要经过一系列等价变换:
select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer,
orders,
lineitem
where
c_mktsegment = 'BUILDING'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < date '1995-03-15'
and l_shipdate > date '1995-03-15'
group by
l_orderkey,
o_orderdate,
o_shippriority
order by
revenue desc,
o_orderdate
limit
10;Q3的一种可行的执行计划如下(IMCI中的执行计划): DERKEY,TEMPTABLE

由于此SQL的grouping keys是l_orderkey、o_orderdate、o_shippriority,与任何一个join keys都不相同,因此并不能直接适用GroupJoin。通过一些等价推导,可得出以下结论:
由于lineitem与orders表的join predicate是l_orderkey=o_orderkey,而且是INNER JOIN,因此可以判断出,这个join的结果集里面,l_orderkey=o_orderkey;
由于l_orderkey=o_orderkey,因此 GROUP BY l_orderkey、o_orderdate、o_shippriority 等价于 GROUP BY o_orderkey、o_orderdate、o_shippriority;
由于o_orderkey是orders表的PRIMARY KEY,因此每一个o_orderkey都能直接确定唯一的o_orderdate和o_shippriority (i.e.,o_orderdate and o_shippriority functionally depend on o_orderkey);
由于o_orderkey能唯一确定o_orderdate和o_shippriority,因此GROUP BY o_orderkey、o_orderdate、o_shippriority等价于GROUP BY o_orderkey;
由上面的推导,可以将Q3的group by clause等价变换成GROUP BY o_orderkey,如此可适用于GroupJoin了:KEY,TEMPTABLE3.SUM(LINETTEM.EXTENDEDPRTCE*1.00-LUNETEM._DLSCOL

这种“functional dependency”的推导,对优化器有一定要求。目前MySQL优化器中,实现了部分functional dependency的推导,但是依然无法推导出上面的GROUP BY o_orderkey变换。经过尝试,发现SQL SERVER是可以推导出GROUP BY o_orderkey变换的,这方面有比较完备的理论,但是IMCI目前在这方面还没有完全实现。在TPCH里面,Q3/Q4/Q10/Q13/Q18/Q20/Q21都有这种特征,如果能做这种等价推导,将可以缩短GROUP BY的grouping keys,提高聚合操作的速度。
Q10
TPCH的Q10也不能直接适用GroupJoin:
select
c_custkey,
c_name,
sum(l_extendedprice * (1 - l_discount)) as revenue,
c_acctbal,
n_name,
c_address,
c_phone,
c_comment
from
customer,
orders,
lineitem,
nation
where
c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate >= date '1993-10-01'
and o_orderdate < date '1993-10-01' + interval '3' month
and l_returnflag = 'R'
and c_nationkey = n_nationkey
group by
c_custkey,
c_name,
c_acctbal,
c_phone,
n_name,
c_address,
c_comment
order by
revenue desc
limit
20;如果要使用GroupJoin,需要做以下两个变换:
通过等价变换把grouping keys变成c_custkey(customer表的PRIMARY KEY),这个变换与上文的Q3类似;
Join order要调整,使得customer表的JOIN在最外层。
其中1总是有益的,但是2中join order的调整,不一定是有益的。
Q17
TPCH的Q17包含一条关联子查询:
select
sum(l_extendedprice) / 7.0 as avg_yearly
from
lineitem,
part
where
p_partkey = l_partkey
and p_brand = 'Brand#44'
and p_container = 'WRAP PKG'
and l_quantity < (
select
0.2 * avg(l_quantity)
from
lineitem
where
l_partkey = p_partkey
);其去关联的方式有几种,目前IMCI针对scalar aggr实现的两种去关联算法得到的执行计划分别是:
 RE
RE

这些执行计划都不适用GroupJoin算子。如果采用MagicSet算子的去关联方式,在移除MagicSet算子之前,会得到一个适合GroupJoin的中间态:
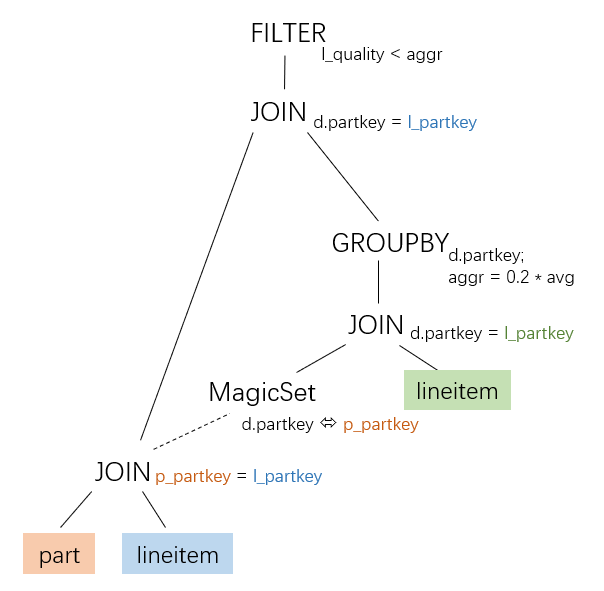
也就是paper_2中所描述的过程: NERALNESTING:DEEORRELATIONOFDEPENDENTSUB-
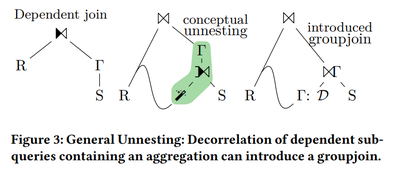
因此可以适用GroupJoin。目前IMCI部分实现了采用MagicSet算子的去关联方式,但是不会生成hared children的执行计划,因此IMCI里面无法对TPCH Q17适用GroupJoin。
Q18
TPCH Q18也是可以适用GroupJoin的,不过依然要利用等价变换转换执行计划,才能得到适用GroupJoin的执行计划。为了方便描述,不失一般性,此处把Q18里的IN子查询以及最后的ORDER BY去掉:
select
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice,
sum(l_quantity)
from
customer,
orders,
lineitem
where
c_custkey = o_custkey
and o_orderkey = l_orderkey
group by
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice对于这个查询,做如下等价推导:
因为c_custkey是customer表的PRIMARY KEY,因此c_name可以由c_custkey唯一确定(functional dependency);同理o_orderkey是orders表的PRIMARY KEY,o_orderdate与o_totalprice都可以由o_orderkey唯一确定。因此,group by clause可以被等价转换为GROUP BY c_custkey, o_orderkey;
由于customer表与orders表的join predicate是c_custkey=o_custkey,因此可以断言,join的结果集中,c_custkey=o_custkey;
由于c_custkey=o_custkey,因此group by clause可以被等价转换为GROUP BY o_custkey, o_orderkey;
由于o_orderkey唯一确定o_custkey (o_orderkey是orders表的主键),因此group by clause可以被等价改写为GROUP BY o_orderkey。
经过以上等价推导,整个查询可以被等价改成类似如下一个SQL:
select
ANY_VALUE(c_name),
ANY_VALUE(c_custkey),
o_orderkey,
ANY_VALUE(o_orderdate),
ANY_VALUE(o_totalprice),
sum(l_quantity)
from
customer,
orders,
lineitem
where
c_custkey = o_custkey
and o_orderkey = l_orderkey
group by
o_orderkey不带GroupJoin的执行计划

带GroupJoin的执行计划

上面的等价推导,因为能减少GROUP BY的grouping keys的长度,因此针对常规的执行计划,也是有用的。
Q20
TPCH Q20的关联子查询的pattern与Q17是类似的:采用MagicSet算子的去关联方式,在移除MagicSet算子之前,会得到一个适合GroupJoin的中间态。
select
...
and ps_availqty > (
select
0.5 * sum(l_quantity) < ! --- scalar aggr --->
from
lineitem
where
l_partkey = ps_partkey < ! --- 关联项 1 --->
and l_suppkey = ps_suppkey < ! --- 关联项 2 --->
and l_shipdate >= '1993-01-01'
and l_shipdate < date_add('1993-01-01', interval '1' year)
)其他
按论文paper_1和paper_2所述,Q5/Q9/Q16/Q21这4条SQL都适用GroupJoin算子,但是暂时还没找到合适的转换路径;通过查询hyper数据库的执行计划(https://hyper-db.de/interface.html#),它的优化器也没有为这几条SQL生成带有GroupJoin的执行计划。
相关实现
TPCH benchmark里面的许多query都是JOIN+GROUP BY的模式,因此TPCH里有不少的query都能通过GroupJoin优化掉。在论文paper_1里,作者列出Q3/Q5/Q9/Q10/Q13/Q16/Q17/Q20/Q21这些query在使用GroupJoin与不使用GroupJoin两种情况下的性能:
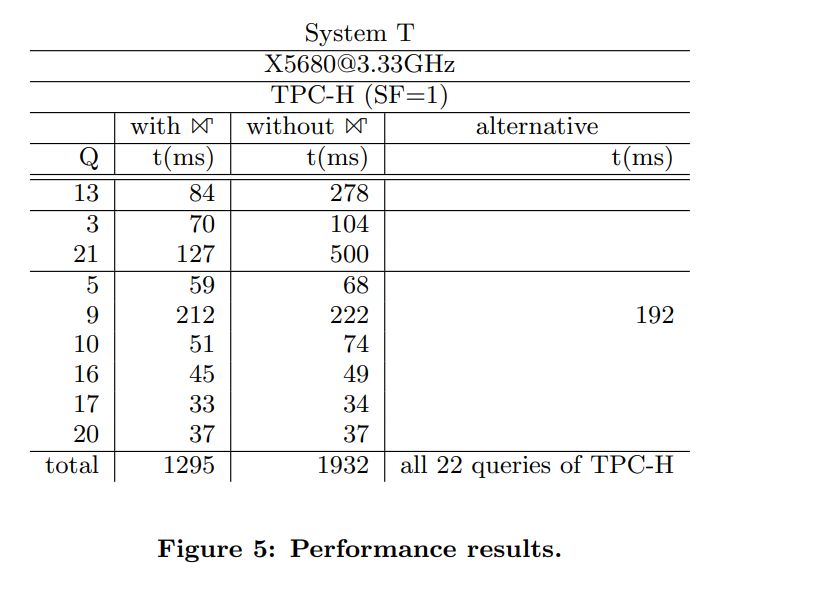
此处使用的是TPCH 1 GB的数据量。可以看出GroupJoin对优化TPCH类型query有一定的作用(总体时延1932ms降到1295ms)。
在论文paper_2中,则是分别列出了Q3/Q13/Q17/Q18这些query在使用GroupJoin与不使用GroupJoin几种情况下的性能(TPCH 10 GB数据量):
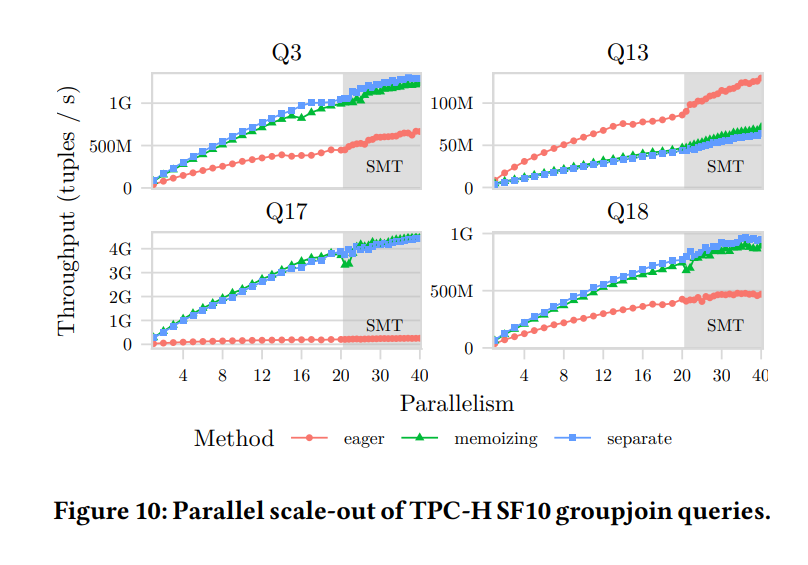
图中的几组线条含义如下:
图中 “seperate”这一组线条代表“分别做JOIN和GROUP BY”,也就是不使用GroupJoin;
图中“eager”代表上文所说的“eager aggregation”这一优化;
图中“memoizing”代表上文所说的“如何处理并发查哈希表做aggr运算时的冲突”这一优化。 可以看到,在 Q3/Q13/Q17/Q18 这4条query中:
"memoizing" 的方式几乎总是与一般的HASH JOIN+HASH GROUP BY的方式有着类似的性能;
eaegr aggregation的方式只在Q13这一条query中占有优势,其余都不占优势。
按照图中的数据可得:不同的处理方法,在不同场景中差别很大。因此这个数据呼应了作者提出的 “GroupJoin 的执行方式,需要优化器提供更准确的统计信息,以选择最优的执行方式”这一观点,而不是无差别地选择某一种GroupJoin算法,甚至无差别地选择使用GroupJoin。
虽然如此,对于这个结论,PolarDB有不同的观点:
文章中使用tuples per second这个指标来衡量算法的好坏,但是与PolarDB IMCI中得到的结论却不太一样。使用IMCI在并发度=32的情况下测试Q3/Q13/Q18这3条query的GroupJoin算子的throughput(单位tuples/s),结果如下:
Query
HashJoin+HashGroupby
GroupJoin
Q3
130 MB
152 MB
Q13
11 MB
33 MB
Q18
315 MB
1 GB
说明Q17在IMCI里暂时无法使用GroupJoin。
这个测试数据与上图中的数据在量级上是相似的,但是每条query都稍有不同。也许是实现方式的不同,从PolarDB的测试数据中可以观察到,除了上文说的right join+groupby right情况外,GroupJoin几乎总是优于HashJoin+HashGroupby的。
对于上面3.a的结论,即“memoizing”的方式几乎总是与一般的HASH JOIN+HASH GROUP BY的方式有着类似的性能,根据我们的观察,TPCH的这几条query只有非常少量的contention,因此memoizing的方式所用的local hash table等,在实际运行时基本不会用到,因此在这几条query里面,这个算法得到的性能与HASH JOIN+HASH GROUP BY是类似的;论文里引用这几条query的性能作为对比,其实不说明问题。PolarDB是通过直接加锁的方式来测试运行时的contention的。
总结
从效果来讲,因为GroupJoin在运行时能避免的重复的工作,因此在某些场景能得到比较大的性能提升。这个效果已经在实际应用中得到验证。因此从结果的角度,GroupJoin是值得实现的。
从通用性来讲,GroupJoin并不通用。GroupJoin只适用于equal join+group by且要求grouping keys与任意一边join keys相同,而且对aggr函数、实现方式等有诸多限制;这是一种特化,而随之而来的是比较大的实现和维护代价。从开发的角度来说,应该花更大力气去优化“通用路径”,利用通用路径的性能提升来达到优化SQL查询效率的目的,而不是通过为某个场景寻求定制性的解法。因此从这个角度来说,GroupJoin不是一个好方法。
因此在实现的时候,应该做一定的裁剪或简化,不追求在一个特化实现里面实现最完备的功能,但是追求最常见场景的效用(性能)最大化。